1. 摘要
第一篇用深度学习做Reid的文章,提出的FPNN采用端到端的训练方式,解决行人再识别的不对齐,光照,姿态等问题。
建立了一个新的带benchmark的数据集CUHK03,表现性能良好。
2.介绍
作者在文章中提到,目前做Reid的大致框架如下

目前的工作主要集中在优化上述框架中的一项或者同时优化几项。
作者在本文的贡献总结:
(1)解决不对齐、光照变换、几何变换、遮挡等问题
(2)使用一些有用的训练技巧;如dropout、数据增强、数据平衡、自助法等,使用端到端的训练
(3)建立发布了一个带benchmark的大规模行人再识别数据集CUHK03,该数据集包含1360个id,13164张图像
3. 模型,方法
模型分为6层,大致框架
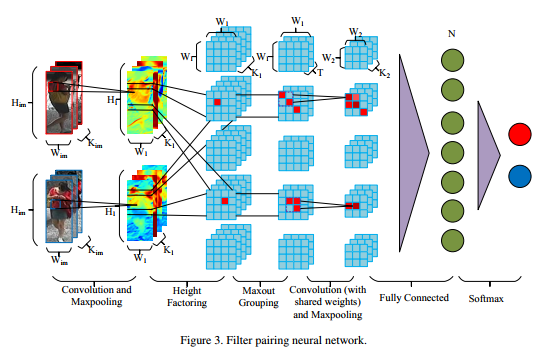
(1)Feature extraction
使用卷积核对\((W_k,V_k)\)对输入的图像对进行卷积提取特征,然后最大池化成 $ H_1 $ x $ W_1 $ x \(K_1\)的特征图
\[ f_{ij}^k = \sigma((W_k*I)_{ij}+b_k^I)\]
\[ g_{ij}^k = \sigma((V_k*I)_{ij}+b_k^J)\]
(2)Patch matching
对特征图尽行分条处理,垂直方向分成M条,每条的宽度为\(W_1\),在条内对图像进行匹配,输出为\(K_1MW_1\) x \(W_1\)的块位移矩阵
\[ S_{(i,j) (i',j')}^k = f_{ij}^k g_{i'j'}^k \]
$ S_{(i,j) (i',j')}^k $ 的值越大,响应匹配越好。
(3)Modeling mixture of photometric transforms
maxout-grouping layer 把\(K_1\)通道数分成T组,每组内的最大响应才往下一层传播,输出为\(TMW_1\) x \(W_1\)
(4)Modeling part displacement
这一层卷积池化,输出为\(MW_2\) x \(W_2\) x $K_2 $
(5)Modeling pose and viewpoint transforms
这一层为全连接层
(6)Identity Recognition
这一层为softmax层,使用softmax函数
4. 训练策略
dropout 、data augmentation、data balancing 、bootstrapping
5. 结论

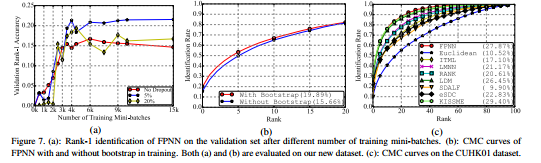
6. 评价
模型性能良好,能够解决一些遮挡、不对齐、光照变化、几何变换、姿态等问题。这是一篇良好的开篇之作,这个提供了一种深度学习解决行人再识别问题的思路。