打算整理一个关于Person Re-identification的系列论文笔记,主要记录近年CNN快速发展中的部分有亮点和借鉴意义的论文。
论文笔记流程采用contributions->algorithm pipeline>experiments->个人评价
Scalable Person Re-identification: A Benchmark
Zheng L, Shen L, Tian L, et al. Scalable Person Re-identification: A Benchmark[C]// IEEE International Conference on Computer Vision. IEEE Computer Society, 2015:1116-1124.
本篇论文主要有two contributions:1.提供了一个大规模的行人重识别数据集Market-1501(包含326423标定框和50w的干扰集且单个目标多摄像头多真值),并提出使用mAP替代CMC作为性能评价指标。
2.基于最新的图片搜索系统,提出基于BoW的特征表达方法。
首先是Market-1501与其他数据集的比较,优势明显目标数多,多cam,且包含万量级的干扰集。在当时是一个极具挑战力的数据集了。

这里注意几个概念:
1.mAP和CMC区别。CMC是排序中计算匹配度的指标,它考虑的第一个真值的匹配。而对应行人重识别任务来说,往往会存在multiple ground truths,因此需要使用同时考虑precision和recall的mAP。
2.multiple query。实现方式是将查询目标的多图以pooling的方式融合成一张查询图(其实还有种是融合距离),这样操作的好处是增强算法对类内的变化的鲁棒性。(实验结果证明是一个刷性能的策略)
3.rerank同样是刷性能的利器。
算法流程主要是经典的BoW。
a.提取local feature,文章使用Color Names。——>b.用k-means训练codebook——>c.量化(特征向量用visual words表示)和编码(TF-IDF)——>相似度计算
实验结果如下,在BoW的基础上逐条的添加tricks(可以看到在深度学习之前的性能是有多惨):
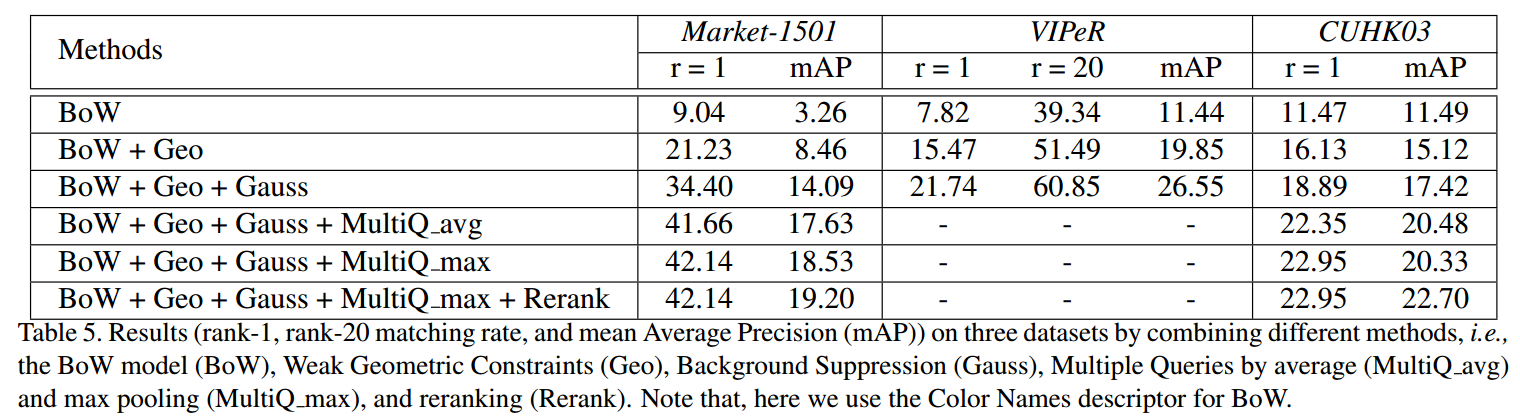
文章还有利用kd-trees实现ANN,从而成倍的提高检索效率的实验,具体不详述。
本篇主要贡献点在一个较大规模的Re-id训练集Market-1501,这是在该方向利用深度学习的前提条件。其次使用一组具有代表性的传统方法提供了一个Re-id的benchmark。
研究person re-id的主要力量是国人,感兴趣的可以重点关注清华郑梁和悉尼科技大的杨易老师组的paper。