前言
最近一直在看CVPR关于ReID的文章,前两天接连看了两篇基于数据增广提高模型accuracy的方法,感觉都是百变不离其宗差不多,有点看腻歪了的感觉,看到这篇文章,正如我刚刚对我郭师叔所说,换了一个角度,针对一个更小更具体的问题,提出了一种很有创意的想法。看的我很新奇也很开心。下面言归正传,介绍一下这篇文章。
摘要
关于行人重检测(person re-identification)前面已经介绍了很多,本文介绍的是Partial person re-identification(基于部分身体的行人重检测)。这是一个很有挑战性的问题,因为只有完整行人的一部分可以获得用来进行匹配。但是它具有很高的现实意义,因为在真实的场景中,我们很难直接获得一个行人完整的图片,大多数的行人都是partial的,比如被建筑物,车辆,其他行人所遮挡,如下图所示。

文章中,作者提出了一种快速准确的方法用来解决这个问题,主要依靠FCN生成固定大小的特征图,同时为了对不同大小的图片进行匹配,文章中还提出了Deep Spatial feature Reconstruction(DSR)的方法来避免这个问题。他把从模型中比较图片的相似度变成了模型提取特征,DSR计算spatial相似度。
当然对于这个问题,也存在一些现行的解决方法,比如将图片resize之后进行比较,然而因为resize之后图片变形,会丢失空间信息,对于模型的performance会有较大的影响。利用固定大小的滑窗对图片进行搜索与检索图片进行比较,但是这个方法也存在弊端,当检测图片的大小大于数据集中图片的大小的时候,这个方法就没有办法进行。将图片分为固定大小的part,然后计算part与part之间的相似度,这个办法可行,但是所需要的计算量太大。上述三种方法的简单示意图,可以见下图,如果你能够不看其他资料就能够明白三种方法的原理,那么感谢原作者吧,是他的功劳。

模型介绍
(1)FCN without fully-connected layers
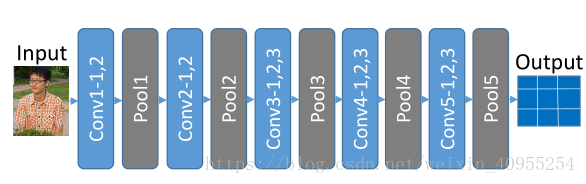
当人们使用CNN网络作为检测器在视觉检测任务重来提取特征的时候,通常需要一个固定大小的图片来进行输入。然而在partial ReID中,因为行人的图片是partial的,他们有着不同的尺寸,而resize有不可避免会导致性能的下降。文中作者提出,之所以需要固定大小的输入,是因为全连接层最后需要输出固定大小的特征向量。因此,在本文的模型中,作者删掉了所有的全连接层只保留了卷基层和池化层。这样FCN就能接收任意尺寸的partial图片作为输入了。模型中最后采取的FCN包含了13个卷基层和五个池化层,最后的输入是跟随输入大小可变的特征图。
(2)Deep Spatial Feature Reconstruction
这部分主要是介绍如何匹配不同大小图片之间的相似度。假定现在给定一对图像,一个是完整的行人图像j,另一个是任意partial的行人图像I。通过FCN提取相应尺寸的特征图 x = conv(I,θ) 和 y = conv(J,θ),θ 是FCN中的参数。x是一个w*h*d的张量,这三个参数分别代表了图像的高度宽度以及通道数。相应的,如下图所示,将x分为N个块Xn,n从1到N,N=w*h,每个块的大小是1*1。相应的Y也是这样分,于是x和y分别服从下列分布。
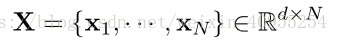
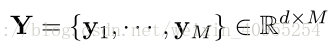
然后,每个Xn都可以用Y的现行组合来表示。那就是说,我们尝试在Y中搜索相似的块来重建Xn.因此,我们希望获得Xn的系数Wn和Y相关, w n ∈ R M×1 。又因为Y中只有很少的一部分和X重建相关,所以Wn使用了L1-norm。然后就有了下面这个表达式:

其中β固定取0.4,控制Wn的稀疏度。 ||x n − Yw n || 2这个范数用来表示xn和y之间的相似度。对于x中的n个模块,匹配距离定义如下:

下面给大家展示一下DSR的整个运算过程,懒得敲了,直接上原文,大致是先提出特征图X和Y,然后将他们分块生成模块集合X和Y,利用方程三来计算出系数矩阵,利用方程四来计算相似度:

3、 Fine-tuning on Pre-trained FCN with DSR
有了上面两个之后,将他们整合到一起,利用DSR基于FCN建立模型,这是加了DSR与没有加DSR的对比图,相比较于之前的方法,行的方法增加了FCN提取深度特征的判别度以及能力。
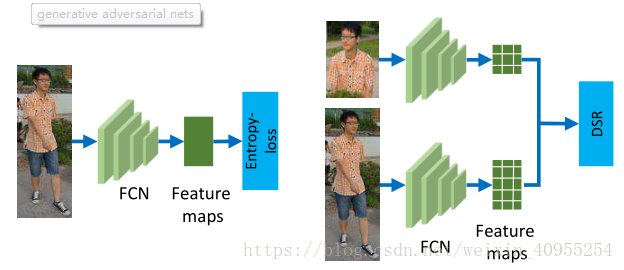
DSR能够相同图片产生的特征图有很高的相似度,不同的图片产生的特征图则相似度距离很远。整个框架的损失函数定义为:
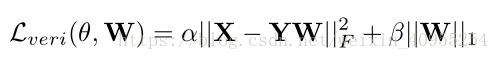
其中α = 1意味着两个图片来自同一个人,α =- 1意味着他们来自不同的人,模型的优化目标主要是模型的参数θ以及系数矩阵W。训练主要分为两步进行:
步骤一:固定θ,优化W。这一步的目的是求解重建矩阵系数W。
步骤二:固定w,优化θ,为了优化FCN里的参数,我们计算损失函数对于X和Y的梯度:
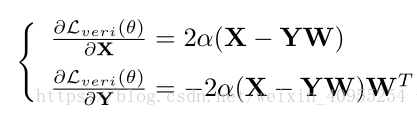
显然,基于DSR的FCN是可以训练的,并且可以通过随机梯度下降进行优化,在算法二中具体讲解了他的优化过程:

总结:
整个文章的主体部分就到此结束了,我认为它主要是提出了解决尺度输入问题的FCN,以及基于像素级的相似度分析方法DSR。当然在后续中,作者还分析了基于多尺寸的DSR过程,并且发现多尺寸的这个过程对于模型的性能又会有新的提高。同时本篇文章我认为比较有意义的一点就是,学习到了在数据输入部分,如果进行resize会由于图片变形造成一定的信息丢失,这个在很多文章里面是没有提到的。在结论部分,作者进行了大量的分析对比工作,我认真地看完了,这里没有继续说是因为我要去吃午饭了,饿了,并不是将那部分没有意义,相反他们是文章的精髓部分,有兴趣的读者可以自行阅读文章。最后,本博客是自己学习所用,如有错误,欢迎交流指正。