说句题外话,刚刚写博客一个星期左右,刚刚一个朋友回复我说谢谢我的翻译。特别激动,这说明我的博客终于有人在看了,虽然可能理解包括表达都还有很大的不足,谢谢鼓励。还有我决定接下来的博客,不直接翻译了,我要尽量用自己的理解表达出来,或许这样对我以及对看我博客的朋友都会有更大的帮助吧,加油,钱多多。
不错,这还是一篇基于RelD的文章,他的关键点是Multi-Level Similarity。对比与之前的方法,他们可能更多的利用一个网络去学习一种空间的表达来表示输入的图片(通常的视觉任务中,输入部分都是图片),然后通过距离表达,或者相似度计算来实现分类的任务。但是呢,本文提出了这样一个观点,这些方法只考虑了卷积网络输出部分的特征。按照在卷积网络中的一些常识,网络的底层往往代表一些类似于颜色,形状的低级特征,而高层的网络往往能够反映出来一些高级的语义特征,比如头部,背包这类的挂饰这些特征。看下面这张图:

图中的a,b包含的是两个不匹配的对象,图像c包含的是同一个人。在a中我们看到他们有着相似的低级特征,比如短袖的颜色,都是露着小腿等,在b中同样是这个表现,这两个人都穿着红色的短袖。但是如果引入了高级特征他们就很容易被识别出来,因为都是第二个人背着包,第一个人没有背包,所以引入了高级特征之后,能够很好地提高模型的性能。在图片c里面,我们可以看到这是同一个人,只是它距离摄像头的距离不同,利用高级和低级特征同步处理,就可以判别出有很大概率,这是同一个人。但是如果使用单一的特征,就很难识别出来,这就显示出了利用多层特征进行处理的好处。

这是文章中提出的整个系统框架,图片中虚线里面是三个卷基层组成的模块,他们是用来提取图片中的特征的,这两个模块可以看为是我上篇博客中提到的孪生网络,他们的网络结构完全一样,并且共享参数。同时我们本篇文章中最大的特点,多层特征对比可以从这里看出,这里从conv2以及conv3中各自将输入引出到CSN-2以及CSN-3这两个网络中去。
那么什么是CSN?
引用文章中的话,CSN目标是计算两个输入之间的相似性。CSN的框架图如下所示:

我们可以看到,CSN有两个输入X1,X2,然后作者发现在训练的过程中,如果输入完整的图像很难利用STN网络找到图中的关键部分,所以作者就当图片分为等大的上中下三块,但是这三块在连接的地方时重叠的,目的是为了避免在图像分割过程中造成的信息丢失。
然后我们发现,这个网络就像俄罗斯套娃那样,真的是一层套一层,这里又出现了一个叫做Spatial Transform Networks的网络。作者说他对于提取包含一种物体的图像是十分有效的。
STN主要分为三部分,第一部分就是affine transformation,负责将图片进行平直变换,然后网格生成以及采样器负责将输入图片进行相关性变换转变为另一个图片输出。affine transformation的公式如下所示:

图中CSN中包含的两个STN其实是一个STN,因为文中说整个结构中一共有两个STN,STN2对应CSN2,STN3对应CSN3,所以说,我们看到的同一张图中的两个STN,也可以看为是一个共享参数的孪生网络,但是STN2和STN3他们只是网络的结构相同,关于网络的参数是不一样的。STN其实也是三层卷积网络,关于他们的网络参数,我们可以从下表中发现。
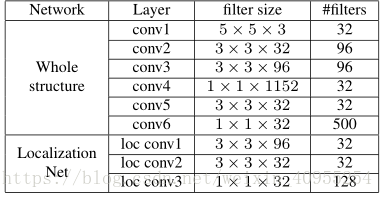
看完STN,我们回到CSN,经过STN之后,我们可以看到分别对应图片分成的三部分输出了三组包含关键信息的特征图。然后利用这上下三幅一共六个特征图,步长为1,与原图进行卷积。这个过程被称为相似度匹配,可以表示如下:
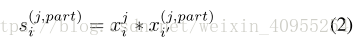
这里注意一下,不是六个都卷积,是第一幅图像对应的三个部分与第二幅图像进行卷积,这个过程是交叉进行的。然后一共生成6个特征,将他们沿通道方向对齐输出。此外还将卷积前一步的信息同时进行输出提供给排位使用。CSN但这里也基本说好了,下面我们会带大框架:
CSN的输出分为两部分,一部分称为相似分数映射,我们会对他在进行三次卷积操作,最后通过一个二分类选项来判断这两幅图片是否相似,另外一组信息被用来提取局部信息进行模型的训练工作。
模型的目标函数分为两部分:
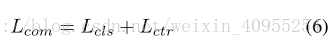
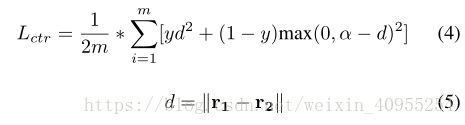
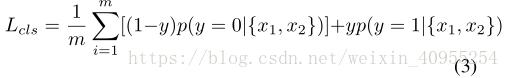
第一次尽量按着自己的想法梳理文章的脉络,果然有所发现。如有疏忽,欢迎大家指正交流
PS刚刚花了点时间,看懂了ranking net这部分,我就不贴在上面了,有兴趣的旁友可以私下交流。嘻嘻