上周由于看了一篇关于条件随机场的文章,卡了很久,整个周末都花在看懂CRF以及玩耍上面了,我承认错误,炉石这个坑我不该跳第二次的,果然浪费了整个周末。
今天看的这篇文章叫用于ReID的融合感知网络,看了半天有些懂又有些不懂,似懂非懂,所以这篇文章尽量本着翻译解释的目的,我自己也借着这个过程再梳理一次。
Abstract&introduction
现存的方法要么是基于对齐好的人像边框图片或者依赖于约束感知选择机制去排除没有对齐的图片。因此他们对于任意对齐的图像可能有着类似角度问题图片的匹配不是最优的。在这个文章里,展现了通过最大化不同level的数据额感知物体的互补信息同时学习感知选择以及特征展示的优点。提出了一种HA-CNN的模型用来共同学习软像素特征以及硬区域感知特征,同时优化特征感知的技术被应用于错位的图像。现存的方法中,自动生成的标注往往并不是最优的,因为会由于背景,重叠,残缺等问题造成错位现象。
Harmonious Attention Network
给定n张画好boundingbox的图片由nid个不同的个体产生,并且由不重叠的相机拍摄,并且由对应的标签Y={y1.。。。yn},y属于指向nid个个体的标签。我们的目的是产生一个用于ReID的深度模型可以在有很大差异的条件下进行匹配。所以提出了HA-CNN用于学习一组融合特征,全局和局部特征,用于最大他们的互补优势并且能够兼具好的分辨性以及结构简便的特点。由于没有提供局部信息,所以这个学习过程是弱监督的。我们设计了轻量且深度的CNN结构,通过设计了一个整体机制用于确定最优判别度的像素以及区域用在进行ReID。
HA-CNN的概括
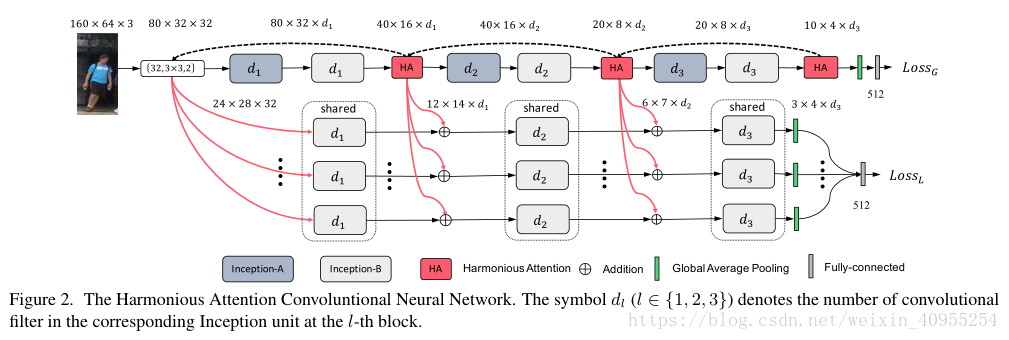
整个模型是一个多分支的结构。整个模型的设计是为了在减少参数体积的同时保证模型的参数。模型的概况见下图2。整个模型包括了两个分支:1)局部分支包含了T个直流,图中用省略号表示了,每个支流的目的是学习每张图片的boundingbox中T个局部区域里的一个最有判别力的部分2)全局分支,目的是从整个图像中学习最优的整体特征。两个分支中都使用了Inception-A/B作为基础模块。inception模块的宽度由d决定。
全局以及局部分支最后都转化为一个512维的输出。这个过程中局部和整体分支共用第一个卷基层,并且相同的inception模块参数共享。为了对边框内一些未知的错匹配的进行感知选择,我们建立HA学习机制用于学习一部分的互补映射包括局部分支的硬注意力,以及全局分支的软感知。
同时为了更好的加强局部分支以及整体分支之间的融合以及匹配程度并且同步增强前一个分支的特征表达能力,又引入了交叉感知相互作用学习机制。
,
3.1Harmonious Attention Learning
这里的HA概念就是硬区域感知,软空间以及通道感知的概念集合。就简单模仿人体·左右脑的功能。软感知学习目的是选择细粒度分类特征,硬感知学习寻找整体有判别度的区域,他们在功能上有很大的互补性。他们的结合使用可以提高模型的性能。
我们设计了一种感知模型可以同时学习三种感知方式而只需要很少的参数。采用了block-wise感知设计,每个HA模型单独优化。在CNN分级网络里,这允许分级网络学习逐步的对齐感知映射,用分而治之的精神。作为一个结果,我们可以很大程度上减少映射搜索区域同时允许多特征的选择丰富特征的表达。这样的模型对于ReiD是有很大的好处的。
(I) Soft Spatial-Channel Attention
输入可以看为h,w,c的三维张量,l表示在整个网络中的层数,Soft spatial-channel attention学习目的是产生一个显著权重映射与原始图像保持着相同的唯度。鉴于空间与通道之间很大的差异性,我们提出将他们分开学习,格式如下:
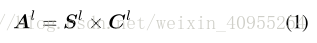
Sl是h*w*l的张量,C是1*1*C的张量,分别代表spatial以及channel映射。为了实现如图一的公式分解,我们设计了一个如图三所示的两分支单元,一个用来对空间感知S建模,另一个用来对C进行建模。
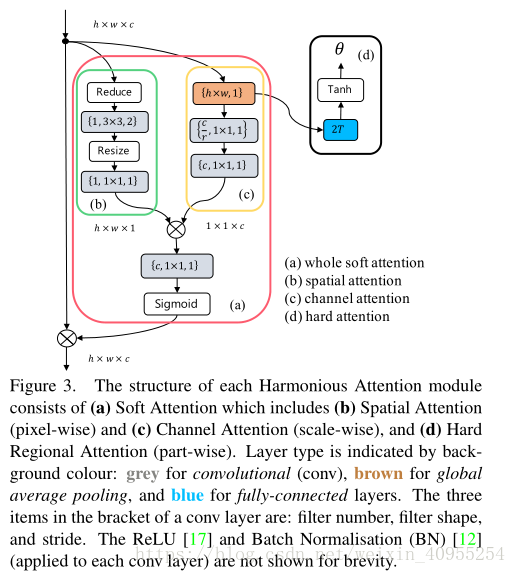
1)spatial Attention
通过如图三b所示的四层小网络对spatial attention进行建模,主要包括一个全局均值池化,一个步长为2的3*3卷积,一个relu层,一个缩放卷基层。其中全局均值池化的公式如下:
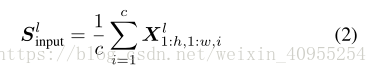
主要是设计了用来对参数进行维度压缩,使得参数量只有原来的1/c。
2)Channel Attention
对channel attention的模型用了一个四层的小模型,参数量只有原来的2*c*c/r。首先也是通过全局均值池化形成一个挤压操作,将图像压缩到只有一维,公式如下:
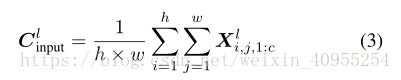
这个C表达了图片每个通道的映射结果,因此提供了内部通道激励操作下的完整信息,整个过程可以表达如下:
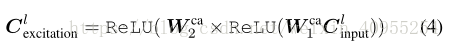
如果r=16,这个模型将参数压缩到只有原来的1/8
为了更好的将spatial atrtention和channel attention结合,在张量相乘后面,我们还加上了1*1的去充分混合得到soft attention。这是因为spatial和channel这两个信息并不是互斥的而是互补的。最后通过sigmoid将输出压缩至0.5-1之间。
(II) Hard Regional Attention
这部分主要内容是去标注类似于人体的位置,这是一个弱监督过程。通过学习下面这样一个矩阵来对模型进行构造:
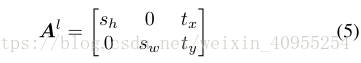
通过这个可以进行图像裁剪,转换童工区别两个尺寸因素Sw和Sh以及二维空间位置tx,ty。使用预定义好的区域尺寸在固定sh和sw。所以唯一有关系的部分就只剩下空间位置了,输出维度是2*T。为了执行这个,我们引入了一个简单的二层网络如3d所示。第一层是全连接层,拥有2*T*C个参数目的是为了进一步减少参数的数量。第二次是一个tanh函数映射层,将数据区间转换到-1到1之间。然后最后生成一个参数,通过如图二所示的上方虚线,将这个参数传到网络前端,提供给local分支去决定移动的方向,并生成K部分不同的局部特征。
最后整篇文章今天再看了一遍加深了我对于整个网络的理解,文章已发本人比较懒就不在做过多解释了,真正的收获就是这个学习的过程,欢迎有兴趣的朋友与我私下交流。