版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_41427758/article/details/80253955
Motivation
- 继14年两篇用深度学习做re-ID工作之后,进一步对深度学习方法的探索
Contribution
- 提出了一个新的网络模型来同时学习特征和对应的相似性度量,两个特点:
- neighborhood difference layer:比较两个输入图像对中经卷积后Feature map相近区域的相似特征
- patch summary featrues:对图像对相近区域中的差异求和
- 本文提出的模型相比之前的SOTA方法在CUHK03与01上有很大的提升,同时该模型在较小的VIPeR上不容易过拟合
1. Introduction
- Re—ID问题定义:跨摄像或跨时间进行行人识别
- 实际应用:
- 视频监控
- 人机交互
- 挑战:跨摄像头带来的光照变化以及不同视角下的巨大差异使相同的一个人看起来不同,不同的人看起来很相似。(类内差异增大,类间差异减少),如下图:
- row1为正样本对
- row2为被分类错误的负样本对
- row3为负样本对

2.Related Work
2.1.Overview of Previous Re-Identification Work
- 特征方面工作:寻找鲁棒的特征来应对各种变化
- color histogram
- local binary patterns
- Gabor features
- color name
- 度量学习方面:将特征空间的点映射到新的空间,使特征空间相同图像对在新空间更近,不同图像对更远
- Mahalanobis metric learning
- Locally Adaptive Decision Functions
- saliency weighted distance
- Local Fisher Discriminant Analysis
- Marginal Fisher Analysis
- attribute consistent matching
- 本文的方法可以同时学习有效的特征以及相应的相似性度量函数
2.2.Deep Learning for Re-Identification
- 之前的工作。14年的两篇,可以参考之前的笔记:
- 本文的模型相比之前的工作层数更深,并加入了两个新的层使网络能够更有效的比较特征
3.Our Architecture
- 网络的整体结构如下图
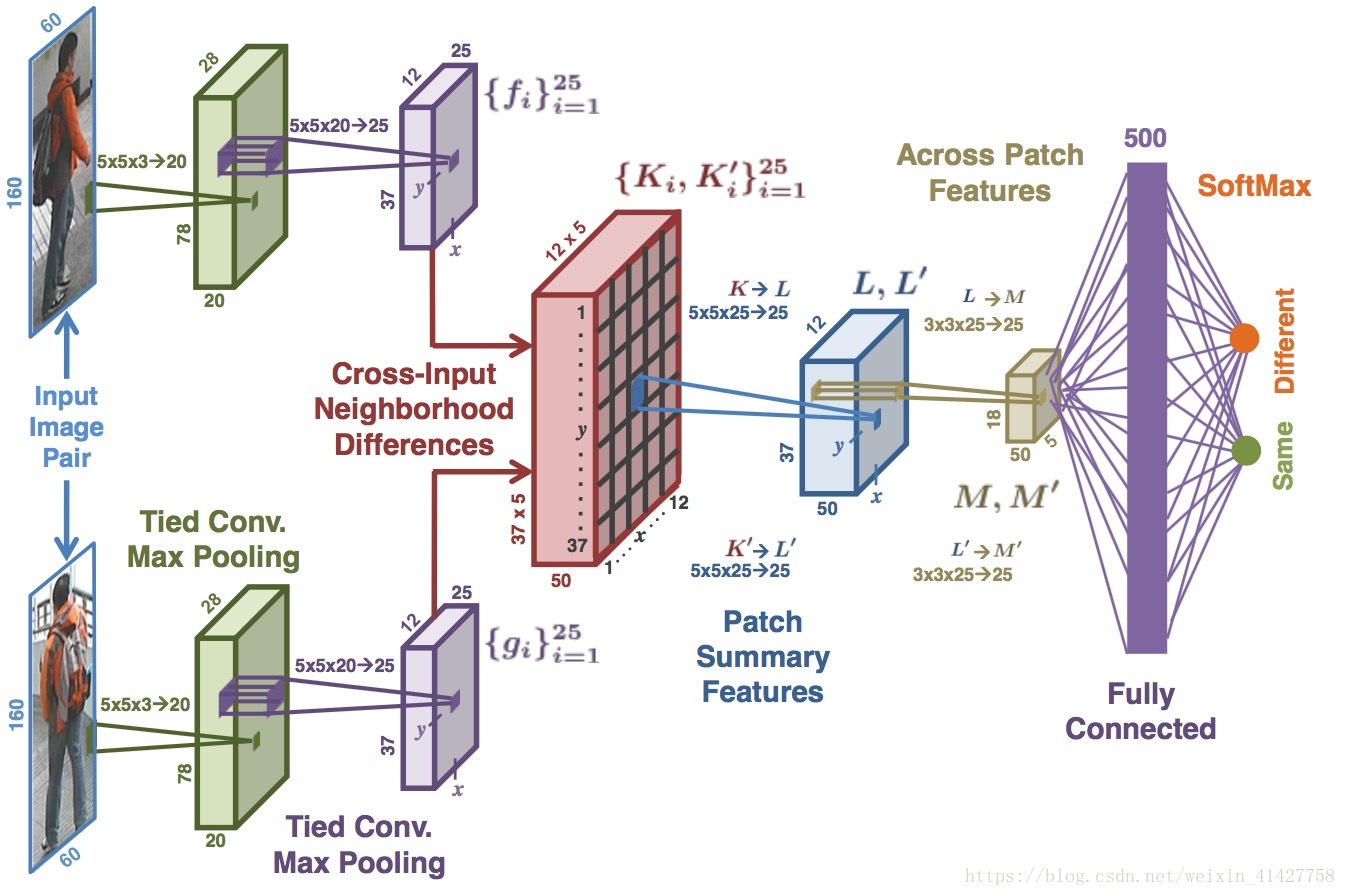
3.1. Tied Convolution
- 两个conv-maxpooling来对图像对提取特征,论文里称为higher-order features,但是网络前两层一般不是边缘,纹理等信息么。
- 为了提取的特征的可比较性,对于两个图像对的卷积操作权重共享,即Tied Convolution
- inputsize:60 x 160 x 3 –> 5 x 5 x 3 x 20 filters –> max-pooling (28 x 78 x 20)–> 5 x 5 x 20 x 25 –> max-pooling–>12 x 37 x 25
3.2. Cross-Input Neighborhood Differences
- 该层对前层输出计算对应两个特征图上特征值周围5个邻域内的特征值差异,产生25个近邻差异图
该层输入为从图像对经过卷积得到的feature map记作 ,该层输出为 ,每个 ,即是5x5的矩阵, ,具体公式如下:
(这里用latex语法输入公式显示不了下文。。)
大致过程如下图:
- 在临近区域计算差异可以提高两个输入图像相应特征位置差异的鲁棒性
- 因为上述公式的公式的不对称性,将上式中的 交换后计算了 ,一共计算了50个neighborhood difference maps,之后再经过ReLu得到输出。
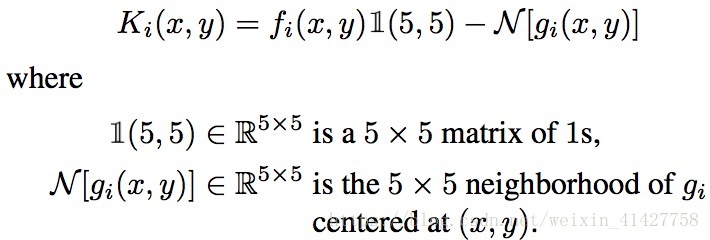

3.3.Patch Summary Features
- 该层对每个上层输出中的每个5x5块进行求和来得到整体的差异,即将 , 同理
- 该操作对 分别用25个5x5x25,步长为5的卷积核完成(两个部分不共享参数)
- 位置的25维patch summary feature vector是对位置 的cross-input differences in the neighborhood更高级的汇总,得 经过ReLu得到输出
3.4.Across-Patch Features
该层对 分别使用25个3x3x25、步长为1的卷积核(两个部分不共享参数)学习neighborhood differences之间的空间关系,之后接了个2x2的max-pooling
将
3.5.Higher-Order Relationships
- 通过全连接层来捕获高层次的关系
- 结合相距较远的块之间的信息
- 结合 的信息
- 输出为500维的向量,经过ReLu,再通过一层两个带softmax节点的全连接得到输出
4.Visualization of Features
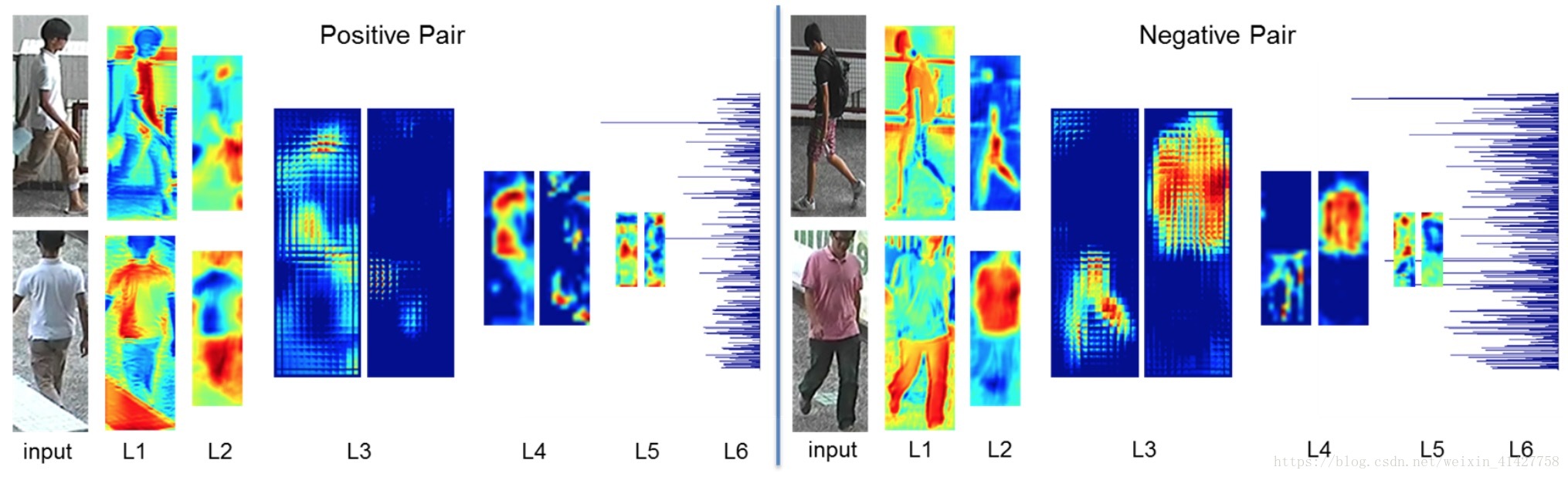
特征的可视化:
- L1为第一个tied conv的特征响应:左边为正样本对,右边为负样本对,其中左边对白色区域响应较大,右边对黑色响应较大
- L2为第二个tie conv的特征响应:左边对legs、hands、face响应较大,右边对不同视角的图片不同区域响应较大
- L3为cross-input neighborhood differences layer的响应:主要是计算两个视角特征图的差异,对于正样本理想的特征图差异应该为0,对于负样本,应该突出差异性
- L4为patch summary feasture后的响应:因为是对L3输出的加和,结果与L3类似
- L5:计算L4特征图的高层次关系
- L6: 第一个全连接层后的输出特征
卷积核可视化:

5.Comparison with Other Deep Architectures
通过不同结构的网络提出的结构进行了评价
Element-wise difference: 对比element-wise difference与cross-input neighborhood differences,说明了cross-input neighborhood的优势
- Disparity-wise convolution: 对比了使用卷积进行patch summary features与直接rearrange成25组的方法,说明了patch summary feature层的优势
- Four-layer convnet: 使用4层网络与之前工作的两层网络进行对比,说明了深度的优势
- FPNN: 自己实现了FPNN进行比较
6.Training the Network
- SGD:base lr: ,momentum=0.9,weight decay = 5 x 10-4
- inverse policy:
6.1.Data Augmentation
- 老问题:在生成图像对时候,负样本往往远远大于正样本,会造成数据不平衡以及过拟合问题
- random 2D translation,对于较小的数据集加了水平翻转
6.2.Hard Negative Mining
- 尽管做了数据增强,负样本对还是比正样本对多,如果在这样的数据集上训练,网络可能训练所有的图像对为负样本。
- 对负样本集合进行了下采样使其数量是正样本对的二倍
- 在上述数据集上训练使网络收敛后,得到的模型因为没看过所有的负样本可能不是最优的,用模型对所有负样本进行分类,选出与正样本数量相同的表现最差的负样本继续训练模型的全连接层
6.3 Fine-tuning
- 对于小的数据集,本文用在大数据集上训练好的模型参数作为初始化
- SGD,
7.Experiments
7.1. Experiments on CUHK03
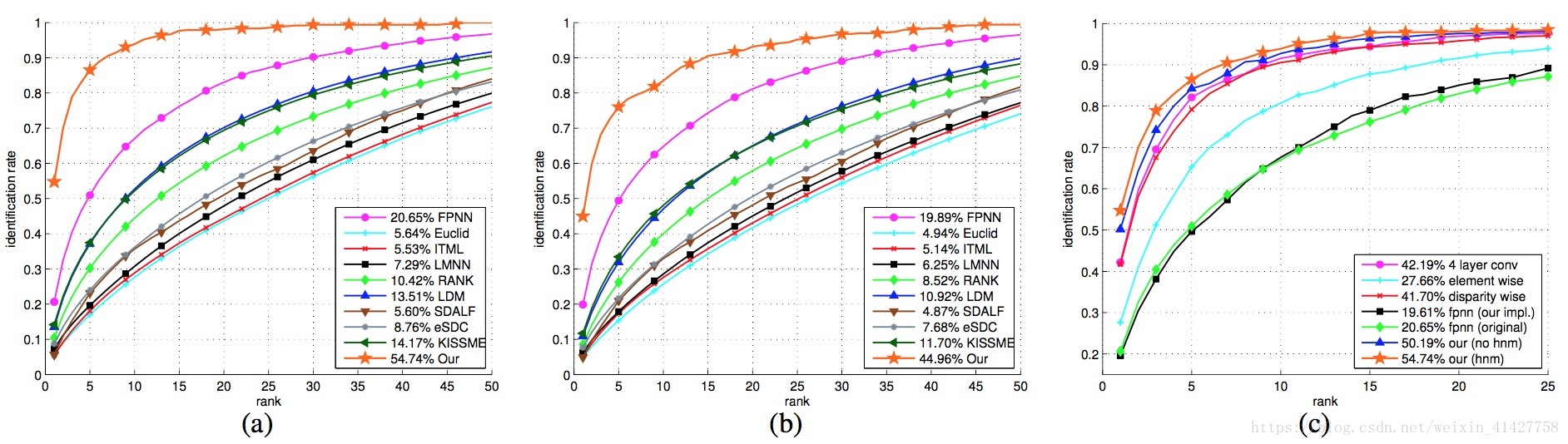
- 实验结果如上图:(a)为手工标注,(b)为检测框,(c)训练策略的对比,对于之前的FPNN,本文的rank-1 acc超过了其的两倍(54.74% vs.20.65%)
7.2. Experiments on CUHK01

(a)CUHK01-100tests (b)CUHK01-486tests (c)VIPeR
- a) 100 test IDs :
- b) 486 test IDs :
- 因为训练集太小,不适合用深度学习的方法从头开始训练
- 在CUHK03上训练,在CUHK01上测试,因为数据分布的不一致,rank1只有6%
- 在CUHK03上训练,在CUHK01上fine-tune,rank1 40.5%–>继续进行hard negative mining训练top layer–>rank1 47.5%
7.3.Experiments on VIPeR
- 在CUHK03 + CUHK01训练,在VIPeR上fine-tune,因为该数据集的负样本对很少,使用hard negative mining没有太大提升
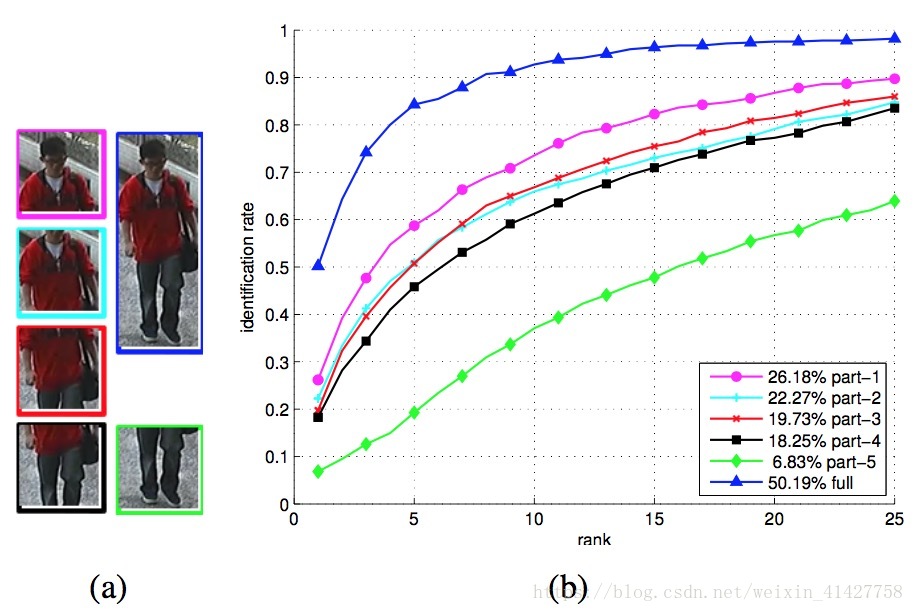
7.4.Analysis of different body parts
- 验证身体不同部分对识别的贡献,如下图:
- 未来工作可以对不同的部位训练不同的模型最后对分数求和来得到结果,这样在一定程度上可以应对严重的遮挡以及识别不同时间拍摄的人
Conclusion
- 设计了两个新的层
- 用本文的方法在各种数据集上进行了实验:
- 在CUHK03大幅度超过了SOTA
- 在CUHK01上,相比其他深度学习方法容易过拟合,本文的方法具有很好的泛化能力,且取得了SOTA
- 本文的方法可以从大的数据集上学习并在小数据集上调整达到不错的性能