Title: Deep Metric Learning for Person Re-Identification
Authors: Dong Yi, Zhen Lei, Shengcai Liao and Stan Z. Li
Affiliation: Center for Biometrics and Security Research & National Laboratory of Pattern Recognition Institute of Automation, Chinese Academy of Sciences (CASIA)
ICPR14 Invited Paper
Contribution
- 行人重识别深度学习开山之作之一(同时期还有一篇),将siamese网络结构用于行人重识别问题上
- 对siamese网络结构中两个子网络的参数是否共享作了探讨,认为共享适用于更general的情况,而不共享更specific
- 进行了cross database的实验,更符合实际应用
摘要
各种手工设计的特征和度量学习方法在人的再识别领域占主导地位。与这些方法相比,本文提出了一种更通用的直接从图像像素学习相似性度量的方法。该方法采用”siamese”深度神经网络,可以在统一的框架内共同学习颜色特征、纹理特征和度量。该网络具有两个子网络的对称结构,子网络由一个余弦层连接。每个子网包括两个卷积层和一个全连接层。为了处理人的形象的巨大变化,采用二项式偏差法对相似性与标签之间的成本进行了评估,证明了二项式偏差法对离群值具有很强的鲁棒性。通过对VIPeR的实验,证明了该方法的优越性,并通过跨数据库的实验,证明了该方法的良好推广性。
1. Introduction
第一段:定义了行人重识别是判断两张人的图像是否属于同一主体。思考:每次输入两张图像限制了这个问题,很多时候是需要比对query和多张图像的相似性,每次都是两两比较显然在时间和资源上都存在极大地浪费。
第二段:行人重识别的挑战包括:行人图像的低质量和高差异;行人图像分辨率低(大约是48*128);光照条件不稳定;摄像头的方向和行人姿势不定,导致大的类内变化和类间的不确定。
第三四段:图像上行人的表达方式是关键,有很多其他领域的特征被借鉴过来(HSV histogram,Gabor, HOG, etc)。基于这些特征分为直接匹配或者是判别学习(主要,such as KISSME [1], RDC [2])。一般步骤分为特征提取和度量学习(metric learning)。特征一半来自颜色和纹理。这篇文章提出“Deep Metric Learning”的思想,把颜色特征、纹理特征和度量结合在一个框架内。
第五段:DML(Deep Metric Learning)借鉴了判断签名的siamese模型。对于两张人的图像x和y,用该网络来判断二者的相似性 。不同于原始的siamese模型,DML的两个子网络不共享权重和偏置,作者认为这样每个子网络有各自的view,更适合行人重识别问题。最后是余弦层计算相似性,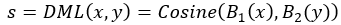 ,B1和B2分别表示两个子网络。B1和B2共享参数则更加的generic(不考虑view)。
,B1和B2分别表示两个子网络。B1和B2共享参数则更加的generic(不考虑view)。
第六段:作者认为DML的优势有三:①直接从图像学习相似性,不需要手工设计特征;②多通道的滤波器可以同时捕捉颜色和纹理信息,不需要像传统方法一样再进行特征融合;③两个子网络可以共享/不共享参数。
第七段:作者在VIPeR数据集上测试;泛化能力则是用cross-database的方法,在CUHK Campus数据集上训练,VIPeR上测试。
2. RELATED WORK
三个方面介绍:
- feature representation
- metric learning for person re-identification
- siamese convolutional neural network.
3. DEEP METRIC LEARNING
为什么用深度学习:作者认为两张行人图像的相似性受分辨率、光照和姿态联合影响,所以理想的度量可能是高度非线性的。因此深度学习是理想的学习方法。
A. Architecture
第一段解释为什么选用siamese网络结构,是因为深度学习传统的“样本à标签”方法在行人重识别问题中不再适用,因为在该问题中训练集和测试集的主体不一样(identity不是同一批)。
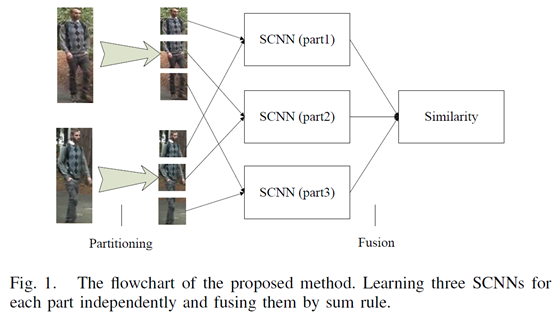
第二段:网络流程图如图一。每两张行人图像划分成有重叠的三个子块,然后两张的上中下子块各自对应组成图像对输入到3个siamese convolutional neural network (SCNN)中。每个SCNN输出±1的标签表示该图像对是否来自同一个主体(即同一个行人)。由于许多应用需要根据探针图像(probe image)对图像库图像进行相似性排序,所以该文输出相似性分数similarity score作为替代。SCNN网络结构如图二,包含两个CNN,这两个CNN由一个余弦层(cosine layer)连接起来。两张图像的相似性计算公式为
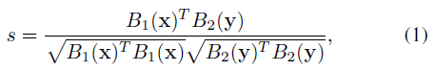
其中B1和B2分别表示两个CNN。
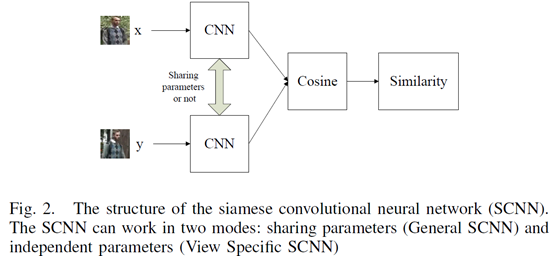
第三段指出在本文中,siamese网络模型中的两个CNN的参数可共享(称之为“General” SCNN模式)也可以不共享(称之为“View Specific” SCNN模式)。作者指出共享参数更适合与一般性的重识别问题,如cross database的识别。
B. Convolutional Neural Network
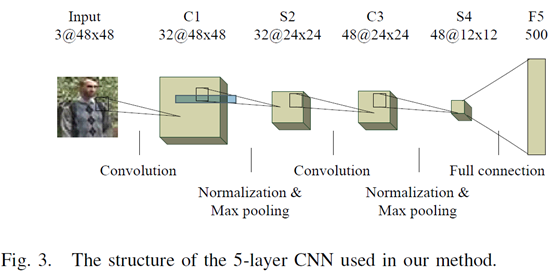
CNN的结构如图三,每个CNN包含2个全连接层和2个max pooling层,以及一个FC层。卷积层和池化层的通道数分别是32, 32, 48, 48。输出是500维。每个池化层包含一个归一化层(cross channel normalization unit)。卷积前填充0使得输出大小一致。卷及尺寸分别是7X7和5X5。每层后使用ReLU激活。
C. Cost Function and Learning
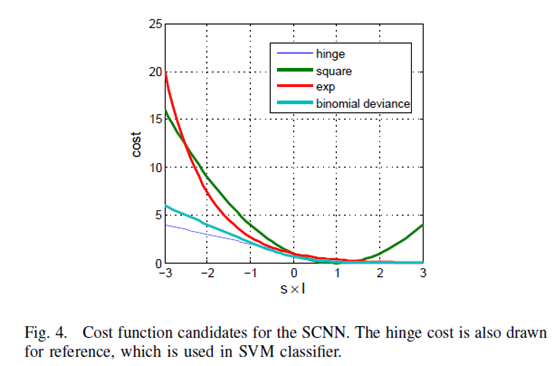
对于损失函数的设计,作者候选了三种函数,平方差、指数和Binomial deviance (二项式偏差?)

从图四的曲线来看,Binomial deviance在相似性不正确时cost最大,所以作者选取了它。
最终损失函数为
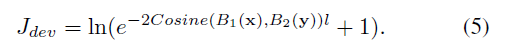
分别求偏导以用于BP算法
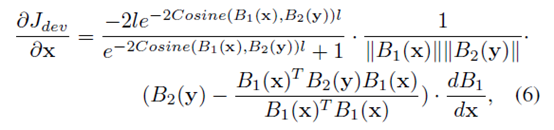
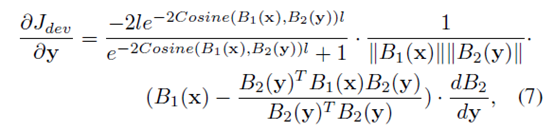
作者用mini batch SGD训练,每个batch大小为126(64个正样本对和64个负样本对)。由于负样本对更多,作者采用随机选取的方式。训练大概300epochs收敛。
4. EXPERIMENTS
数据集的选择:作者选取VIPeR,因为其评价体系最清晰(the evaluation protocol of VIPeR is the clearest one)。
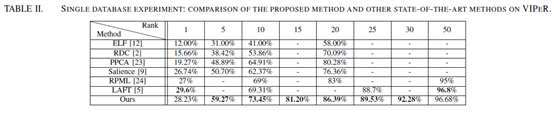
A. Single Database Person Re-Identification
训练和测试数据都是VIPeR。该数据集包含632个主体,每个主体有2张图像(分别来自camera A和camera B)。作者随机将其分成含316个主体的训练集和含316个主体的测试集,并重复11次。其中第一次的随机划分数据集(Dev split)用来选取参数,后面10次(Test splits)用来会把汇报结果。
作者通过Dev split实验选取了两个参数:
- 一个是epochs=300
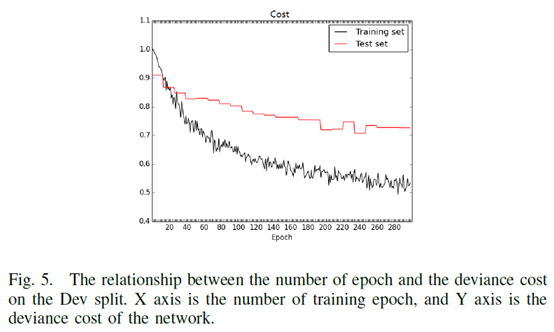
- 另一个是图像对不属于同一个identity时ground truth(l)的值c=-2。原因是由于产生的负样本远多于正样本,可能造成负样本对的欠拟合,所以用不对称的惩罚来限制。

三个网络(比较上中下或者头、躯干、腿)通过累加相似性来融合。
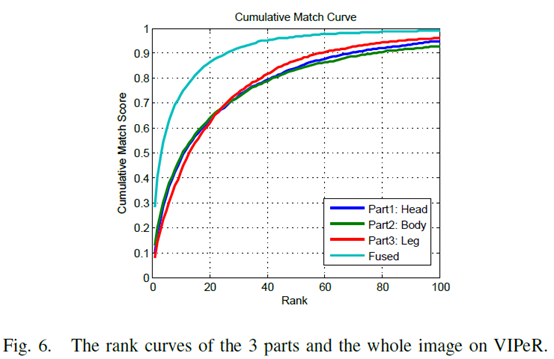
实验结果
B. Cross Database Person Re-Identification
训练数据集:CUHK Campus database (1816 (subjects) X 4 (images from 2 camera views/subject) = 7264 (images))。
测试数据集:同上VIPeR,对半分,重复10次
对比方法(transfer Rank SVM, DTRSVM):adapt a model trained on the source domain (i-LIDS or PRID [25]) to target domain (VIPeR). source domain的所有样本和target domain的负样本对被用来训练。该文方法是source domain训练,target domain测试。
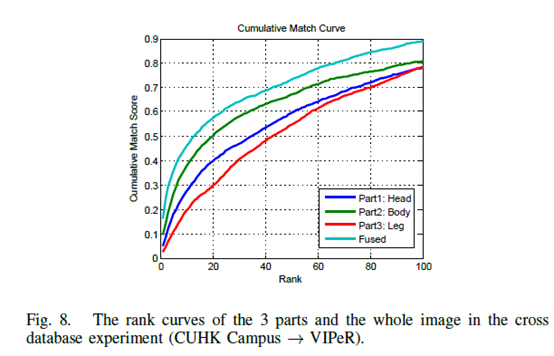
与single database相比,cross data base模式下身体不同部分对结果影响不一样(body>head>leg),作者认为是因为躯干最稳定而腿的结构变化最大。思考:是否考虑加权?融合确实有效,如果不切分呢?
实验结果
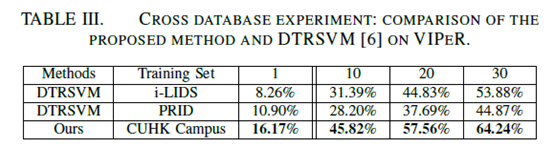 感觉对比不严谨
感觉对比不严谨