Camera Style Adaption for Person Re-identification
(只记录论文中的Introduction和The proposed method部分)
一、简介:
由于深度学习行人ReID领域的对数据量的巨大需求和注释大量数据集的昂贵花费,通过关注不同相机间的style差异来添加更多的training sample是一个好的选择。这一点能够1)处理数据匮乏问题。2)学习不同相机间的不变特征。这个过程不需要大量的人工标注,因此开销较低。
本文提出了一种CamStyle相机style适应方法,来regularize行人Re-ID的CNN训练。在它的普通版本中,我们使用circleGAN。这种普通版本减少了过拟合,并得到了相机不变性特性,但是也给系统加入了许多噪声。当将方法应用到全相机系统中,这种不良情况会恶化,但是过拟合的风险变小。在改进版本中,加入了标签平滑正则化(LSR)在style转变(style-transferrd)样例上,它们的标签在训练时均匀的散布。
Camstyle有三个优点:
1.它能作为数据增强方案,不仅平滑了相机之间的显著差异性,也减少了CNN过拟合的影响。
2.通过合并相机信息,它通过利用相机不变特性协助学习行人身份。
3.此外,它是非监督的,在CircleGANd的保证下,有很好的应用潜力。
三、方法:
-3.1CycleGAN综述
假设有两个数据集是分别从域A、B收集的,CycleGAN学习的则是A->B的映射(使用adversarial loss,使得生成的图片和真实图片难以分辨(即相似度高))。CycleGAN包含2个映射函数,2个对抗生成器用于区别图片是否是由另一个域转变而成的。CycleGAN使得生成模型和判别模型可以联合训练。loss function写成如下形式:
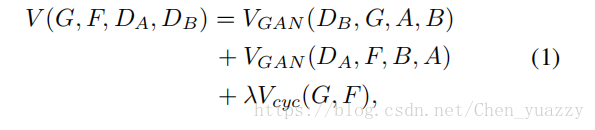
其中,Vgan(DB,G,A,B)是映射函数G,判别器DB的损失函数,Vgan(DA,F,B,A)是映射函数F,判别器DA的损失函数。Vcyc是cycle consistency迫使F(G(x))=x和G(F(y))=y,因此每一张图像都可以在cycle mapping后重建。入 代表了Vgan和Vcyc之间的重要性。
–3.2基于相机的图到图转换
为保证style-transfer中的色彩连贯性,我们加入了identity mapping loss,确保当使用真实图片作为输入时,生成器生成接近于identity mapping。loss函数表示如下:
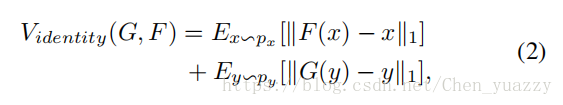
图像尺寸256*256.使用CycleGAN,生成器包含9个残差块(Residual blocks),4个卷积层,判别器为70*70的PatchGANs。
对于每一个收集来的图像,我们生成L-1的新样例,style与对应的相机相似。新图片与原始图像ID相同,这允许我们将它们同时用于CNN的训练。
提出的数据增强工作机制主要包括如下两个方面:
1)生成图像和原始图像有着相似的分布
2)生成图像的ID标签被保护。
–3.3深度ReID模型baseline
通过真实图像和生成图像(都含有ID标签),我们使用IDE(ID-discriminative embedding)来训练re-ID CNN模型。使用Softmax loss,IDE将re-ID训练视作图像分类任务。使用在Imagenet上预训练的Resnet-50。与原始的IDE不同,我们去掉了最后的分类层,加入了两层全连接层。第一个全连接层有1024维,称为“FC-1024”,之后跟随着一个bn,RelU,Dropout。这一层能提高精度。第二个全连接层有C维,C代表训练集的种类数。输入图像尺寸256*128.网络结构如下:
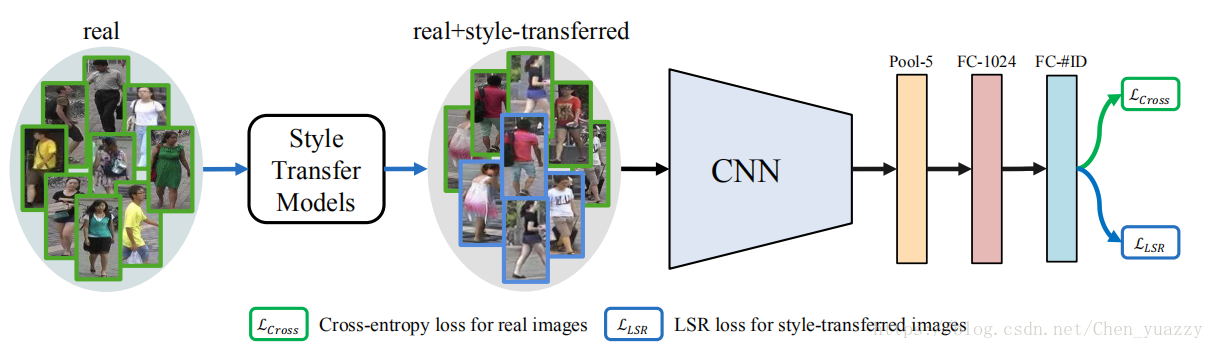
–3.4Camstyle训练
普通版本:
新训练集中的每一个样本都属于一个单独的ID。在每一个mini-batch中,随机选取M个真实图片和N个生成图片,loss函数能被写成:
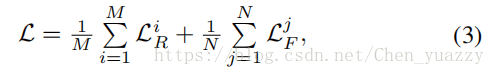
LR和LF是真实图片和生成图片的cross-entropy loss。Cross-entropy loss函数能被写成:
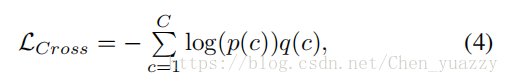
C是种类数,p(c)是属于label c的输入的预测可能性,p(c)被softmax层标准化。q(c)是真实值分布。因为每一个人属于一个身份y,所以q(c)能被定义成:
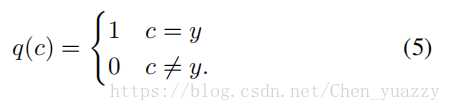
所以最小化cross entropy等同于最大化真实值标签的概率。对于给定给定行人身份y,cross entropy损失可以被写成:
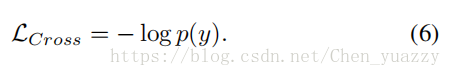
因为生成图像和真实图像的相似性,这个版本的算法能够提高baseline的IDE准确度,在少量的相机下。
改进版本:
Style转变的图像能够对数据进行增强,但也引入了噪声。普通版本的能减少few-camera系统时的over-fitting现象,但由于缺乏数据集,over-fitting有发生的趋势。若有更多的相机,over-fitting就不那么严重,但是更多的噪声将会出现。
噪声来源于1)CycleGAN生成图片本身就会产生误差。2)原始样本中就会有噪声图像。
为了缓和噪声干扰,我们使用LSR标签平滑正则化方法,softly分布它们的标签。我们分配更少的真实变迁置信度,以及对其他类别分配更少的权重。这个重新分配的标签分布被写成:
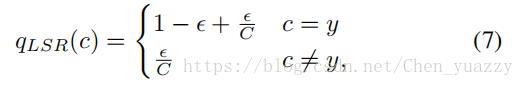
对于真实图片,我们不使用LSR;对style转变图像,我们设置参数E=0.1,Loss函数为:Lf=Llsr(E=0.1)