版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_41427758/article/details/81160812
Motivation
- 目前的方法只考虑在某一个特征的卷积层输出来计算相似性,是否可以使用多尺度提高相似度的计算的准确性呢?
- 许多工作假定相关视觉特征不会平移太大的距离,没有在整张图上考虑相关性,很容易丢失信息
- 之前都是在特征图的rigid part来计算product或者difference,没有对于尺度、旋转的不变性
Contribution
- 提出了全卷积Siamese网络,包含能够高效实现且带有注意力机制的Convolution Similarity Network来改进两个图片相似度的计算
- 在不同的层次计算视觉相似性,并结合多层次的信息提高匹配的鲁棒性
- 通过大量的实验证明本文提出低复杂度与内存使用的模型与SOTA能达到相当的性能
1.Introduction
- reid定义、意义、挑战
- 现在工作两个主流方向:
- 特征表示学习
- 有效的距离度量
- 深度学习在re-id上取得的成功
- 存在局限性 ==> 动机与贡献
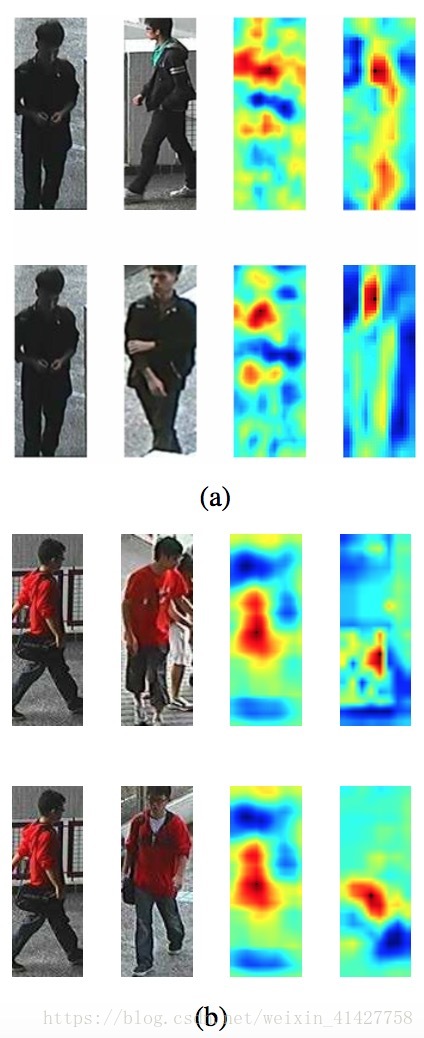
- 多层次相似度对于识别的帮助如下图:低级特征(衣服颜色)、高级特征(背包)等等

2.Related Work
- 传统方法:handcrafted feature + metric learning
- 深度学习方法:
- Siamese网络二分类
- rank problem
- 分类方式提取特征
3.Proposed Method
3.1.Model description
- 网络的整体结构如下图:
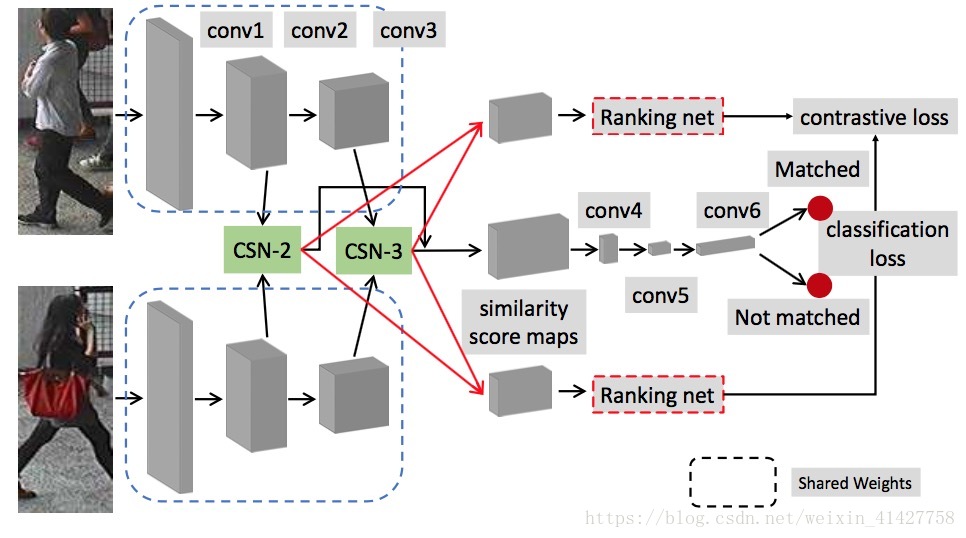
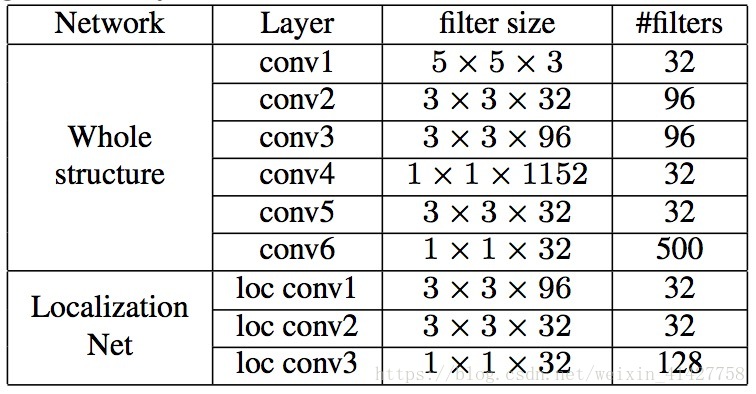
Convolution similarity network(CSN): 用来衡量个输入的相似性
- 利用STNs来提取有意义的局部区域特征
- 将局部部分看作卷积核来计算两组特征之间的相关性
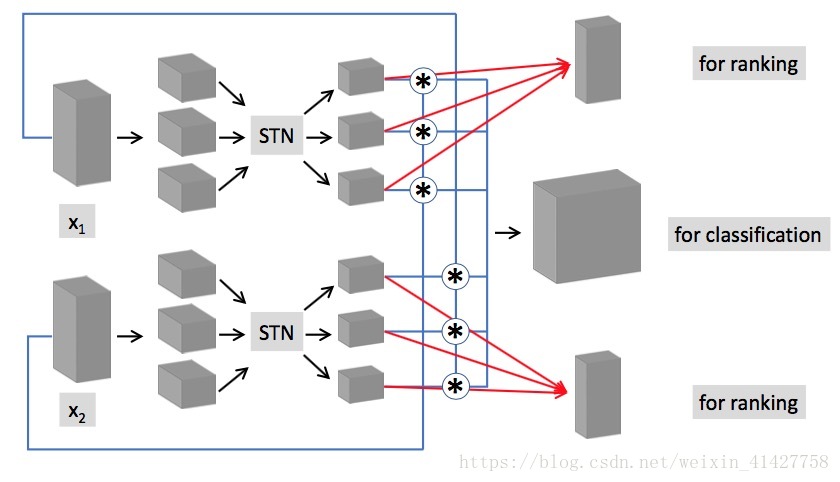
STN可以用来缓解大的视角差异以及遮挡问题,从图片中找到有意义的内容,细节介绍参考Spatial Transformer Networks
- 两个权重不共享的全卷积STNs, 对应 , 对应
- 实验发现很难通过STNs从 的全局发现相对重要的区域,本文将 划分成了部分重叠的三个部分,upper,middle,bottom,共享localization net
- sampler的输出对于 为 , 为 , 大于
将提取的区域当做卷积核,在另外一个特征图上进行卷积操作,stride=1,通过计算cross-correlation来得到相似性
depth wise convolution
Combination of visual similarities from different levels:
- 结合低级与高级特征:
- 将第二个以及第三个卷积的 与 concatenated得到10 x 4 x 1152个相似分数图
- 再通过三个卷积层conv4(1x1), conv5(3x3), conv6(1x1)处理相似得分图
Objective function: 结合了classification与ranking
- 二分类使用softmax loss
- 使用二分类损失会忽略正确的ranking,可以结合ranking loss来缓解该问题,本文认为全局特征难以突出最具有判别力的特征,不适合做ranking ==> 基于局部视觉特征的ranknet
- 三个卷积层
- ==> conv(3x3x96) ==> max pooling ==> concatenated(竖直方向) ==> conv(3x3x96) ==> 不同层的特征图(concatenated) ==> GAP ==> linear embedding ==> 256维图片的attended parts的特征向量 ==>
- Contrastive loss
- 整个网络的loss
- 测试阶段最后的相似得分计算:
3.2. Discussion
Efficiency.相比从tensor直接通过切片来选取rigid part,本文通过全卷积STN来选取有意义的局部特征在目前深度学习框架下更加容易实现
Learned visual similarity from different levels.
- 由下图可以看出不同层具有不同层次的特征(关于CSN2的解释有点懵)
Model extension.
- 增加更多的CSN模块,大幅度提高了性能,能达到与用pre-trained模型相当的性能
4.Experiments
4.1.Datasets and evaluation metrics
- CUHK03、CUHK01、VIPeR
- CMC、mAP
4.2.Implementation details
- TensorFlow
- ADAM、BN
- learning rate:0.0005、Weighting decay:0.0005
- Batch size:256 for CUHK03 128 for other
- 与 分别为10、5
- 数据增强:随机crop、水平翻转
- 对于每个正样本选取两个负样本
- 对于transformation parameters作了大于0;考虑到旋转很少在实际中发生,针对 与 作了
- part的划分,对于 row1-20为upper part,10-30为middle part,20-40为bottom part,对于 ,row1-10为upper part,5-15为middle row,10-20为bottom row
4.3. Comparison with state-of-the-arts

4.4. Ablation analysis
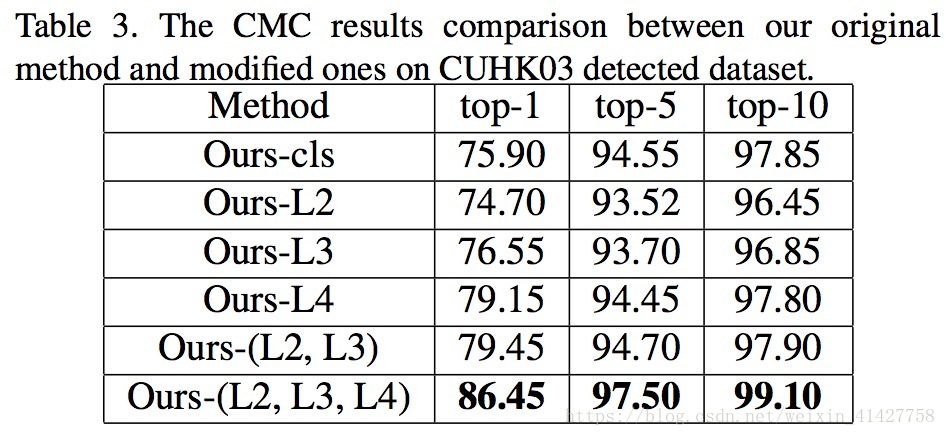
移除了contrastive loss
探究了结合不同层次视觉相似性的重要性
- 高级语义特征相比低级特征更加重要
- 结合不同层次视觉特征对性能的提升有帮助
不同网络配置的实验:
- C1:将图片分为三个部分的效果
- C2:将STN替换为固定的中心裁剪
- C3:只使用Level4的相似性
- C4:原模型

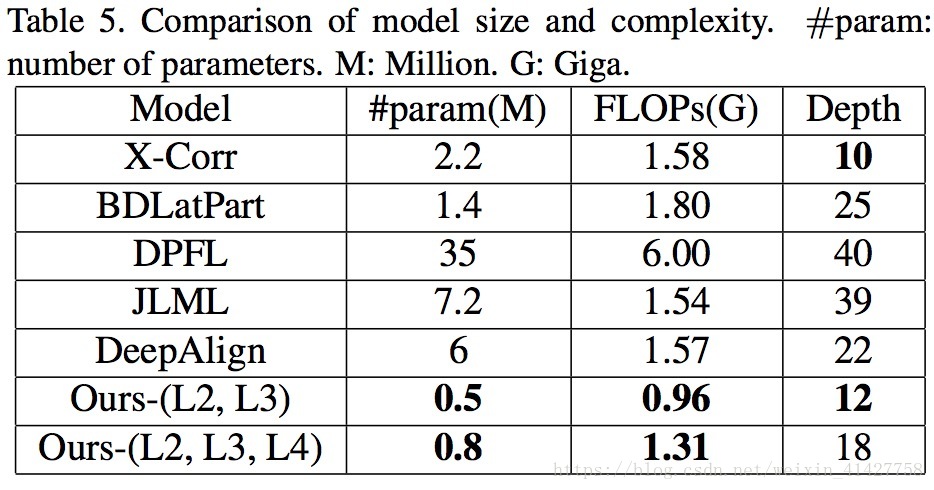
4.5. Complexity Analysis
- 与五个最近提出模型进行了大小与计算复杂度的比较,本文的模型相对较小且有较高的性能
5.Conclusion
- 本文提出的全卷积Siamese网络
- 从一个输入图片的局部提取特征,并与另一个图片通过depth-wise convolution高效计算视觉相似性
- 利用在不同卷积层的多个CSNs得到不同层次的视觉相似性
- 在局部区域通过Contrastive loss来提取特征(ranknet)
- 大量的实验证明了本文方法以较小的参数与计算复杂度达到了与SOTA方法相当的性能
- 通过Ablation与可视化方法证明了不同层次的特征对性能提升的贡献