版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_41427758/article/details/80962028
Motivation
已有很多方法利用人体姿态估计对来解决re-id中的姿势变化问题,并在一定程度上提升了re-id性能,但是pose information信息是否被充分利用了呢?
在Re-ID场景中有大量的遮挡问题,有什么好的办法区分肢体对人的遮挡(weak feature)以及包裹等对人的遮挡(强特征)呢?
Contribution
- 提出了处理re-id中misalignment与occlusion问题统一的框架:Attention-Aware Compositional Network(AACN)
- 通过Pose-guided Part Attention得到更精细的身体区域来减少噪声的干扰
- Visibility score来衡量身体区域的遮挡程度
- 大量的实验表明本文方法在已有数据集上的优越性
思考
- 利用attention机制来提高对局部特征的效果是个很值得研究的方法
- 如何让网络更加灵活地区别对待强特征与弱特征是一件很有意思的事情
- 最后对于区分相似异类人物的效果很有趣
1.Introduction
- re-id的定义与意义
- 面临的挑战
- 许多工作尝试利用人体姿态估计解决视角与姿势变化造成的misalignment问题,从patches、stripes、pose-guided region of interest(RoI)来提取特征:
- 矩形框往往会包含背景噪声,如下图
- 不同视角下的姿势差异包含不一致的背景与噪声,直接匹配会影响精度
- ==> 如何产生更精细的轮廓来充分利用pose信息呢?
- 动机与贡献

2. Related Work
2.1.Person Re-identification
- 特征学习与度量学习
- 行人对齐问题:
- 全局特征
- 局部特征
- 精度较低 ==> 姿态估计:
- Spindle Net、PDC、PIE仅仅基于刚体(精度有限)
- ==> 本文:通过关键点的连接性得到了非刚体部分(更加准确)

2.2.Human Parsing
- 同样能够精确定位身体部分,但是现有模仿很难泛化到监控场景的数据上
- pose相比parsing更容易标注,且有很多不同的数据集得到容易泛化的模型
2.3.Attention based Image Analysis
- 注意力机制在很多任务都有应用
- 本文的attention map通过姿势估计引导学习得到,相比RoI更加精度
- part attention的强度也表明了每一个部分的可见程度,能够帮助应对遮挡问题
3.Attention-Aware Compositional Network
- 如下图为AACN的整体架构,由两部分构成:
- Pose-guided Part Attenion(PPA):估计每个预定义身体部位的attention map与visibility score;
- Attention-aware Feature Composition(AFC):part feature alignment
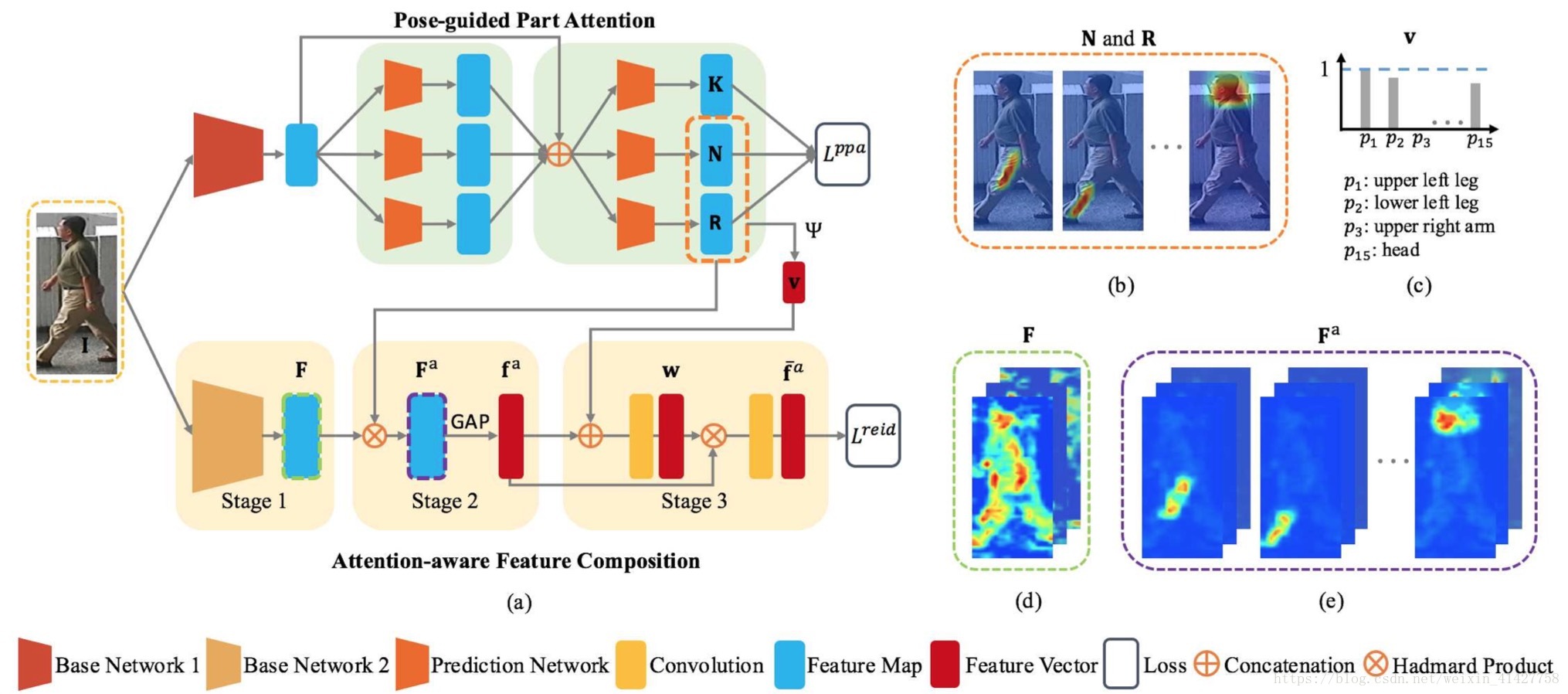
3.1. Pose-guided Part Attention
- Part attentions:对part confidence map进行归一化处理
人体身体部位的分类:
- rigid parts:head-shoulder,upper torso,lower torso
- non-rigid parts:upper arms,lower arms,upper legs,lower legs(容易产生剧烈的姿势差异)
two-stage网络来学习part attention:
- 通过三个独立的预测网络分别预测non-rigid part attention ,rigid part attentions , keypoint confidence maps
- 为VGG-19第十层的特征图
- 考虑之前所有的预测refine the attention maps

- 整体的损失函数:
Loss for Keypoint Confidence Map
- 由在真实关键点位置使用高斯核产生, 为关键点数量
Loss for Non-Rigid Part Attention
- 借鉴了Part Affinity Field(PAF),通过两个关键点的连接区域来定义ground truth non-rigid parts
- non-rigid part attention损失:
Loss for Rigid Attention
- 用一个矩阵 来定义rigid part, ,
- rigid part attention损失:
Part Visibility Score.
- attention map上的强度值表明了每个部分的可见程度,通过该值可以定义用来衡量不同身体部分重要性的global visibility score:
3.2. Attention-aware Feature Composition
- 三个阶段:
- Global Context Network(GCN) ==> global features
- Attention-Aware Feature Alignment ==> part-attention-aware features
- Weighted Fearture Composition ==> 利用visibility scores对aligned featured重新加权
Stage 1: Global Context Network (GCN)
- 利用base network(GoogleNet)来提取特征
- 为了降低计算量,在“inception_5b/output”后增加了更多256-channel 3x3卷积层,最后将256channel的特征图送入下一个stage
- 输入尺寸变成了448 X 192经过最后一层卷积输出的特征图为14 X 6
- 先独立训练GCN,然后再与其他阶段联合fine-tune
- GCN用ImageNet初始化,后面添加的卷积层随机初始化 ==> GAP ==> identification loss + verification loss
Stage 2: Attention-Aware Feature Alignment.
- Global context features容易产生body part misalignment
- 通过global feature maps与每一个human part attention map作Hadamard Product产生attention-aware feature maps;将得到的feature maps进行GAP并concatenated成aligned feature vector
Stage 3: Weighted Feature Composition.
- 针对姿势的变化以及遮挡情况,对人体的部分进行自适应调整匹配
- 权重向量 通过同时考虑part visibility与feature salience估计得到
- 将visibility score与attention-aware aligned feature vector拼接起来送入FC
3.3. Implementation Details
- AFC中,GoogleNet用来提取全局特征,两个额外1X1卷积层用来part weight estimation与final feature fusion
- AACN逐步训练过程:
- 独立训练PPA(part attention and pose estimation loss)与GCN(reid loss)
- 固定PPA与GCN,训练AFC中feature weighting与组合的参数
- 联合训练所有模块
4. Experiments
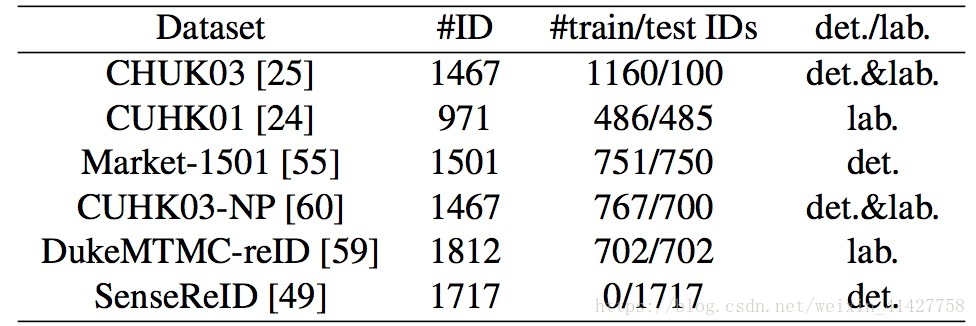
4.1. Datasets and Protocols
- 在下列数据集上进行了实验
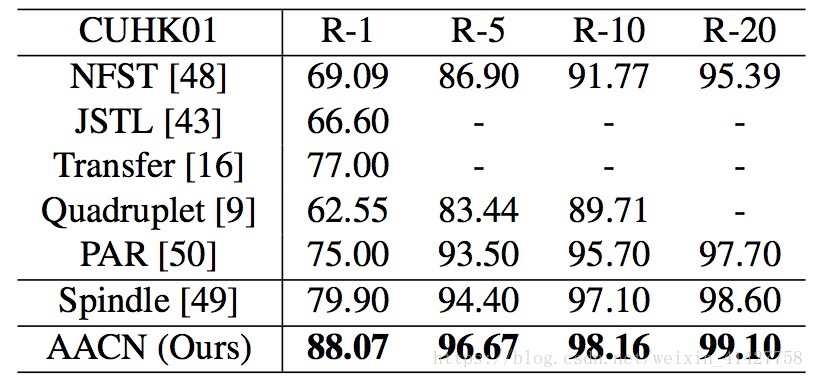
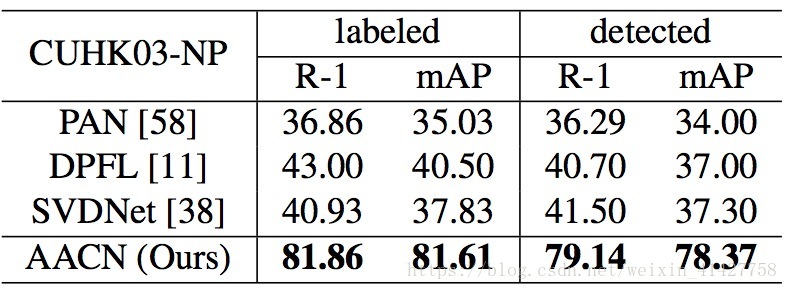
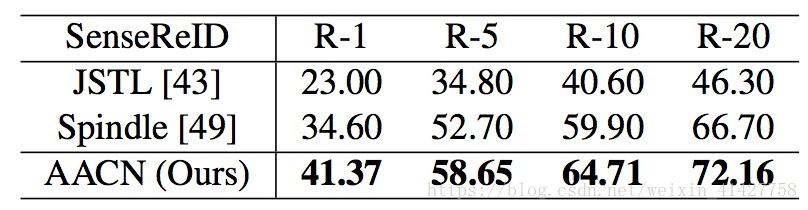
4.2. Comparisons with State-of-the-Arts
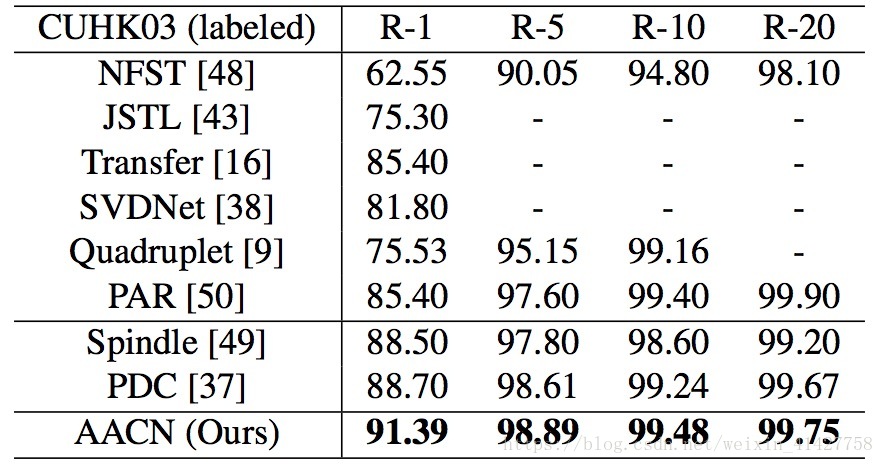
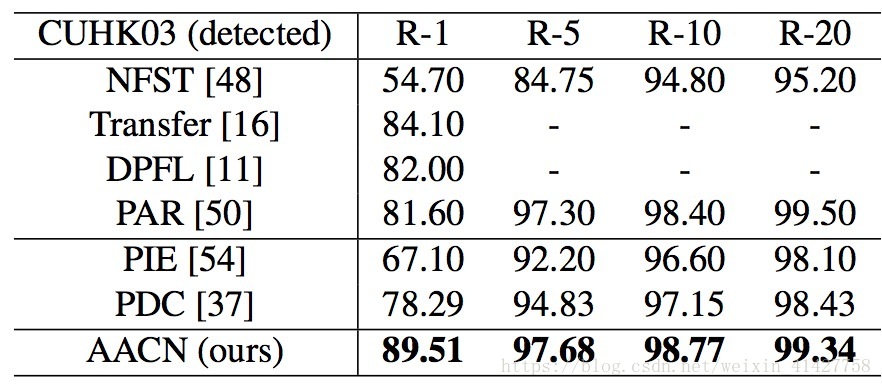
- 比较的方法分为两类:姿势无关、加入姿势估计
- 结果如下表


4.3. Ablation Analysis
Base Network.
- 如下表所示,本文的网络与其他方法有相当的大小,但是整体的模型大小更小8M;同时将本文的base network换成Spindle,性能仍然优于Spindle

Pose-guided Part Attention.
比较了PPA与RoI定位的准确性
比较了不同部位定位方法在ReID上的性能


Attention-aware Feature Composition
- AFC能够很好区分外貌相似但不是同一类的人

Visibility Score.
- 一定程度上提高了精度

5. Conclusion
- 本文提出的网络架构与目的
- visibility对于遮挡程度的衡量(其他地方也可以借鉴)
- AFC对于鲁棒特征学习
- 大量实验证明本文方法很有效