这是一篇整整琢磨了快两天,最后在我郭大师的指导下才看懂的论文,话不多说,直接上干货。
传统的 ReID通常来讲会将行人描述为一个单一的特征向量,并且通过特定任务的矩阵空间进行特征向量对比,从而得出相似度。然而这篇文章的作者认为,单一的特征向量并不足以克服一些现实场景中常常出现的视觉障碍。所以这篇文章提出了DuATM(双感知匹配网络)去学习上下文感知特征序列,同步执行序列对比。文章的核心是双感知机制,在这个机制里序列内和序列间的感知策略都被用来进行特征精炼以及对齐。同时还采用triplet loss、decorrelaton loss以及cross-entropy loss三种损失函数进行模型训练。
1)为什么单一的特征向量不行?
当行人信息经历剧烈的变化或者当不同的行人穿着相似的衣服,用单一的特征向量进行描述可靠的ReID就变得很困难了。在下面的图片a中,不同的人穿着相似的衣服,除了短裤的样式稍微不同,其他都很相似。但是单一的特征向量往往注意人物的整体表现而不是局部特征,所以很难获得正确的匹配结果。比如在d中的视频序列,存在许多的干扰帧,这会严重损坏特征向量的质量并导致最后的错匹配。

2)如何解决这个问题?
解决这个问题的常用手法是利用一组特征向量或者是特征序列去进行匹配。针对这个,本文提出了DuATM的框架。这是一个端到端的可训练的框架体系,可以协同从上下文学习感知特征序列并进行细致的特征序列比对工作。整个框架由两个模型串联构成,一个用来进行特征序列的提取挖掘,一个用来进行特征序列的比对工作。特征序列挖掘模型的基础是CNN网络,他可以用来提取时间和空间上的特征序列。而特征匹配模型是基于一个双感知机制,一个感知策略用来进行序列内的精炼,一个用来进行序列间的对齐。
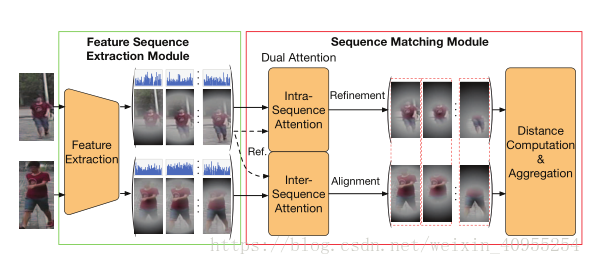
3)关于特征序列提取模型
在DuATM里面,我们选取了Densenet-121作为整个特征序列提取模型的基础。因为Densenet的每个层与它之前的层之间都存在直接连接,所以局部信息可以被更好的传播到输出,同时丰富了最后的特征序列。这里有一点需要注意的是,对于图片输入与是视频输入的网络结构是存在一些稍微的差异的。两者的结构分别如下图6.2所示:
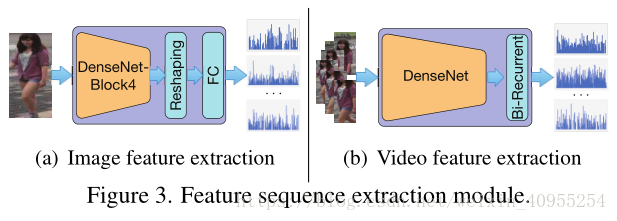
input image:输入一张图片X,大小是H*W*3,我们所需要得到的feature map是从densenet的block-4输出来的。每个指定位置的所有通道的特征向量都包含了空间信息以及上下文语义信息由于他大的接受尺寸。然后这些特征向量就被按照位置信息rearranged形成一个特征序列。这里我思考了很久才明白,最后的这个reshape其实是依据特征图的每个像素进行的,比如特征图第一个像素点的进行的,然后这个像素点的三个通道的值被提取为一个特征向量,所有的特征向量又一起组成了特征序列。
input video:一个视频输入X,大小是H*W*3*T,T是视频的时间长度或者说帧数,这里需要注意一点就是不管是基于image还是基于video的ReID都是短时间段内的,长时间的效果是不佳的,比如某个人本来在视频里,去超市买了一堆东西,换了一身衣服,这样的话这个人的表现特征就发生了极大地变化,我们再进行的话就只能说是人脸识别了,因为他行人的意义已经发生了很大程度上的改变。言归正传,视频每一帧的图像作为输入到densenet中产生帧级别的特征向量,然后许多帧的集合就构成了特征序列。然后一个双向的recurrent层被采用去对时间空间信息进行编码,通过允许信息在时间过程中传递。
所有被挖掘出来的特征序列里面的特征向量在传入下一个模块之前都会经过正则化。
4)关于特征匹配模型
框架中从特征挖掘模型中传过来两个特征序列 (X a ,X b ),其中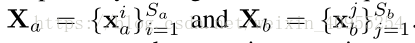
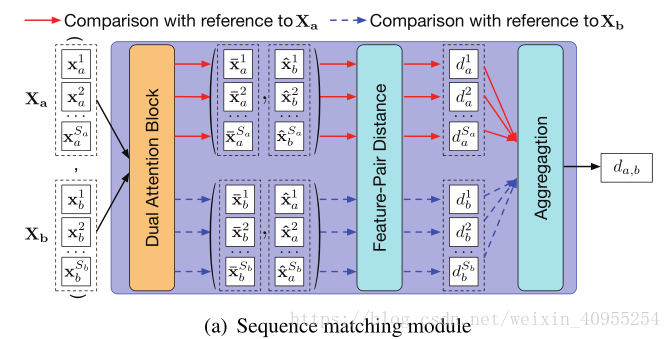
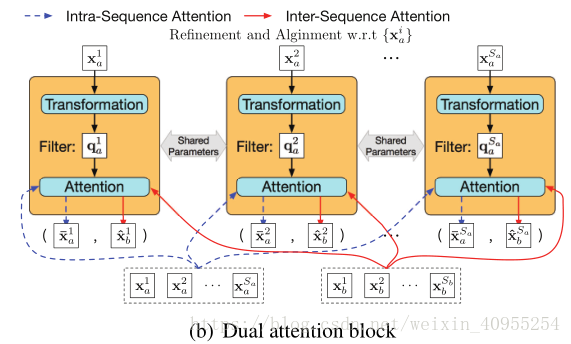
4.1双感知模块
双感知模块由一个转换层以及一个特征感知层构成,其中转换层负责产生特征感知滤波器参数,简单来说就是构造一个方程,以下图第一个模块为例,将Xa1表达为qa1的这个过程就是转换层的作用,感知层的作用是用来生成相应的感知权重,然后我们看下面这个图,它是以Xa为基准话的,所有的数据都是以Xa为中心,计算的是Xb与Xa的距离,简单来说,所以Xa是蓝色虚线,它代表特征序列Xa内的自相关,而Xb是红实现代表的是Xa与Xb的相关性。其中生成q的就是refine的过程,能够去除数据本身一些不利的影响而生成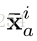
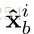
下面按照论文的步骤来系统的讲讲:
首先,通过转换层生成如图所示的滤波器: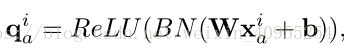
然后,课题通过感知层分别计算出关于序列内refinement以及序列间alignment的感知强度,通过如下所示的公式:
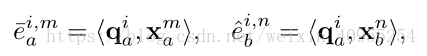
最后,我们通过序列内的线性组合就获得了经过refine和align的向量特征对。相应的这个获得的过程如下:
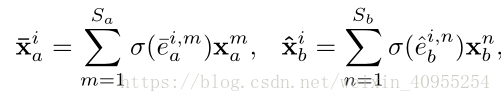
通过上述的过程,我们最终获得了所有的需要的特征对。
论文的主体的难懂的部分都在上面讲过啦,接下来还有一个距离的计算,不过这个我相信大家都很容易搞明白,以及在训练模型的时候使用的三种损失函数结合的方法,不过那属于编程时候的难点,在阅读文章的时候先不管那么多啦,等我以后编程实践的时候如果有机会,我会把他们做一个单独的介绍的。
今天的学习到此结束,欢迎大家有空交流指正。
明天是周末啦,终于可以睡到十二点起床了,hiahiahia。。。。