一篇新的论文,题目是《一个新颖的行人重识别方法:基于GANs的条件转换网络》
论文链接: https://ieeexplore.ieee.org/abstract/document/8943114
以前看过相关论文,提到过利用GAN网络来生成扩充数据集,因为现存的数据集大小太少,一直没碰到相关的论文,正好这次可以总结一下。
摘要
目前person re-id 最大的挑战就是不同摄像机下的显著性差异,包括光照,背景和行人姿势。已经存在的person re-id 方法大都是依靠隐藏式的方法,比如寻找鲁棒性的特征或者设计有缺别度的距离度量。相比于这些方法,人类的解决方法更加直接,那就是,在匹配前想象目标人物在不同摄像头下的外表,关键思想是人类可以直观地实现视点转换,注意到目标人在不同摄像机视角下的关联,但是机器却不行。这篇论文,我们尝试模拟人类行为,在匹配前转换行人图片到具体的相机视角,实际上,我们提出了条件转换网络(cTransNet),有条件的实施视角观点转换,通过Generative Adversarial Networks(GANs)的变体来将图像转换到具有最大域间隙的视点。然后,我们通过融合最初图片和转换图片得到混合人物表征。再然后,根据余弦距离来进行相似度排序。与以前的方法相比,我们提出了一种类似人类的方法,并且使Market-1501,DukeMTMC-ReID和MSMT17数据集中的rank-1精度比基线分别提高了3%,4%,4%。
介绍
作者利用了一个盲人摸象的寓言故事,个人认为非常形象,正如多个摄像头一样,每个角度看到的都不一样。person re-id 就是利用计算机视觉技术来判断不同摄像机角度下是不是一个人,作为一个细粒度的视觉识别问题,行人重识别已经被类似视点问题困扰了好长时间。
 FIGURE 1.Examples of pedestrian image pairs from two camera viewpoints in CUHK01 dataset. Each column indicates a pedestrian, the first row are images from camera A and the second row are those from camera B
FIGURE 1.Examples of pedestrian image pairs from two camera viewpoints in CUHK01 dataset. Each column indicates a pedestrian, the first row are images from camera A and the second row are those from camera B
然而,在不相交的摄像头下寻找特征的行人非常困难,因为变换的视角。不容位置和角度的摄像头下,背景,光照,行人姿态也是非常的不同。如图1所示,从摄像头A到摄像头B的转换下,行人的光照显著的不同,另外,背景和行人姿势也不同。在Market-1501,DukeMTMC-re-id,和MSMT17这些数据集中,这些问题更加困扰,因为数据多。
为了解决这些挑战,很多方法被提出来【8】-【12】,大致分为两类:特征学习和度量学习,一般的特征学习方法就是在不同的摄像机视角下,学习稳健的特征表征。不同于特征学习,度量学习主要是关注于如何让相同类别的向量更近,不同类别的向量分离。毫无疑问,这些方法的确促进了行人重识别领域的发展,然而,这些方法的表现性能有限和对个多数据集不稳定。主要原因在于这些方法过分依赖提取的特征的泛化能力。 换句话说,由不同摄像机捕获的人的外观是不固定的,仅通过深度模型之类的方法很难区分。
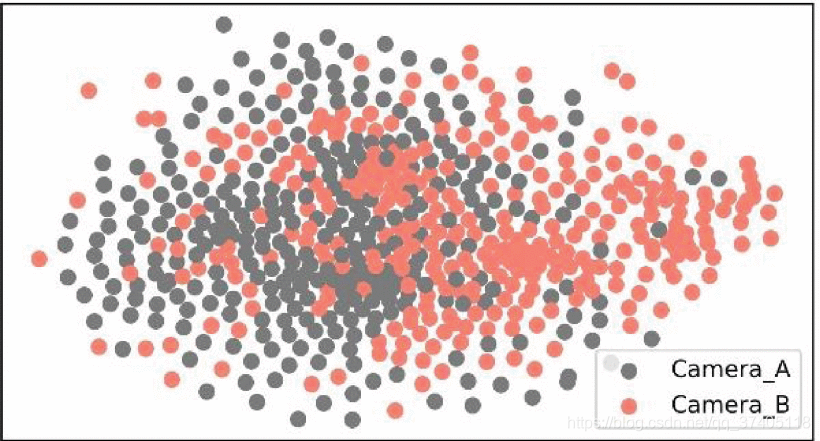
FIGURE 2.Visualization of 600 samples from two camera viewpoints in the CUHK01 dataset through T-SNE algorithm. The red dot indicates the image from camera A, and the gray dot indicates the image from camera B.
为了验证这个猜想,做了一个小实验,如图2所示, 随机挑选三百个样本在CUHK01数据集上,不同的摄像头视角,通过T-SNE算法【13】把这些样本映射到二维空间中,可以发现有两点比较重要:第一点:从整个图来看,两个摄像头视角有很明显的分布趋势。 d第二点:在某些情况下,一个摄像机视图的表示可能类似于另一摄像机视图的表示。 结果,当照度,背景或人的姿势由于相机视图的变化而大大不同时,我们可能会出现图1中所示的硬样本。(明显不同就是硬样本。)
通过实验可以发现,我们不能像一般的图片分类任务简单地从原始图片里提取特征。因为信息不充足或者偏置等,真相就会被隐藏在图2中间地带。不同于机器,人类可以通过观察特定行人的摄像头视角信息,尝试想象这个人在其他摄像头下的视角是什么样子,而不是从原始图片里强行重提取特征。而是更加关注相机视角对当前图片的影响。然后获得稳健的特征,获得更好地识别效果。
这篇论文,采取了模拟人类行为方式来提高行人重识别的表现力。实施过程分为两步:第一步,提出了修改后的StarGAN【14】来学习每一个摄像头下的观察方式。然后我们测量每一个摄像头的领域间隙,最后,把图片转换到最大的领域间隙的视角。 第二步,融合原始图像和生成图像的特征,然后根据余弦相似度进行匹配排序。
总而言之,论文主要贡献是提出了 基于StraGAN的图片条件转换网络,根据源域和目标域之间的域距离执行图像转换(也就是转换条件) ,这个方法和前边的方法不一样,主要在于两点,第一点是:我们的方式是直接从生成的图片里提取特征,而不是仅仅扩大数据集【7,15,16】 第二点是,cTransNet只需要训练一次就可以将某个图像转换为多个相机视点,这由StarGAN的结构保证[14]。
(cTransNET 根据原始图片生成各个摄像角度下的图片--------根据两个领域距离来判断哪个最大--------------生成最大的。----------融合特征进行基于余弦距离的匹配排序。)
相关方法
A 基于深度学习的行人重识别
因为所提出的方法是基于图片级别的,所以主要关注于基于图像的person re-id。(基于视频的方法上一篇博客有 链接: https://blog.csdn.net/qq_37405118/article/details/105168166.
受到迁移学习思想的启发,Zheng等人。 [10]提出了从ImageNet [17]预训练模型进行微调的ID区分嵌入(IDE)嵌入,该模型将人的re-id视为常见的分类问题。
另一种有效的策略是将手工制作的特征与CNN特征相结合。 在[18]中,Wu等。 通过将手工制作的特征整合到CNN特征中,提出了一种特征融合网络,从而大大提高了匹配精度。
在[19]中,李伟等。 提出了一种新颖的和谐注意CNN(HA-CNN)模型,用于联合学习软像素注意和硬区域注意,同时优化特征表示,有效地学习共享相似特征表示的不同类型的注意。
同样,吴等。 [20]提出了一些简单的深度学习方法,以学习具有区别性和视图不变性的可比表示。 另外,在[21]中,他们提出了一种用于鲁棒性地标检索的新型协作深度网络,该网络可在地标潜在因素上工作,以进一步为多查询集和其他地标照片生成高级语义特征。
这些深度学习方法采用全局欧氏距离来评估硬样本。 然而,由于行人图像的特征由于姿态,照明和遮挡的巨大变化而呈现出未知的分布,因此欧氏距离可能无法准确地描述复杂视觉特征空间中的理想相似度。 为此,吴等。 文献[22]提出了一种新颖的采样方法,可以在局部范围内挖掘合适的样本,以改善大的类内差异情况下的深度嵌入。 然后,Wu等人提出了一种用于细粒度目标识别的端到端深度模型。 文献[23]产生了在空间上可以整体表达的粗粒和局部细粒的表达形式。
B person re-id 的数据扩充(防止过拟合)
郑等。 [15]证明,即使深度卷积生成对抗网络(DCGAN)[24]生成的不完善样本也可以提高训练过程中基线模型的正则化能力。
后来,钟等人。 [16]提出了一种相机风格的适应方法,以增加数据多样性,防止过拟合,还采用了标签平滑正则化方法来减轻噪声的影响。
Wei等。 [7]更进一步,提出了PTGAN来弥合不同人re-ID数据集之间的领域鸿沟,还贡献了一个新的数据集,称为MSMT17。
在本文中,我们采用预训练的ResNet-50 [25]作为基线模型,并表明经过修改的样本有效地提高了其性能。 当CNN模型与训练样本数量相比过于复杂时,可能会发生过度拟合。 为了解决这个可能过度拟合问题,在深度学习社区中已经提出了许多正则化方法和数据增强方法:
例如Dropout [26]和Batch Norm [27]用于正则化,以及各种转换,包括用于数据增强的裁剪,翻转和转换 。 丢弃被广泛用于各种识别任务中。 它在训练阶段以概率随机削减(分配为零)每个隐藏神经元的输出,并且仅在向前通过和向后传播中使用剩余权重的贡献。
近来,几种方法旨在解决人重新ID中的过度拟合问题。
McLaughlin等。 [28]通过利用背景和线性变换来生成各种样本,提高了网络的泛化能力。
钟等人。 [29]使用随机值随机擦除输入图像中的矩形区域,这可以防止模型过度拟合并使模型对遮挡具有鲁棒性。
相似,黄等。 [30]建议用对抗性样本进行扩充来增加训练数据。
C 图像转换中的GAN
GANs 是非常强大的生成模型,【32】,相比于传统的生成式模型,比如 Deep Boltzmann machines [33] VAE ,[34] GANs 时间效率高,更少的限制,并且可以生成更好地样本。随着人们的关注,得到了重大的突破,很多变体
【24】 DCGAN 事实证明,该模型比原始模型更稳定。 由于GAN和DCGAN都将随机噪声作为输入,因此它们的输出趋于不可控。
【35】 对GAN施加条件约束,以便可以预测生成的输出。 条件GAN(cGAN)的提议为图像转换领域提供了基础。 不幸的是,cGAN属于监督算法,该算法需要标签并且不适用于某些数据集
【36】 然后在2017年,CycleGAN [36]的发布,为GAN引入了与周期一致的标志,标志着图像转换领域的又一个里程碑。 CycleGAN的优势体现在两点。 首先,CycleGAN属于无监督算法,对标签没有限制。 其次,CycleGAN可以生成具有转移样式的高质量图像。
尽管CycleGAN的提议为一对一的域图像转换提供了解决方案,但是CycleGAN仍然不适用于需要执行多域翻译的情况。 为此,提出了StarGAN [14],它可以同时实现多域图像翻译。
D GANs in Person Re-Identification
尽管许多研究人员致力于正常人的重新识别设置,但很少有文献[37],[38]研究无监督域对re-ID的适应,
【37】Peng等。 [37]提议基于非对称多任务字典学习来学习目标域的判别式表示。
【38】 [38]学习一种基于CycleGAN的相似度保持生成对抗网络,将图像从源域转换到目标域。
转换后的图像用于以监督方式训练re-ID模型。 这些方法试图减小图像空间[7],[16]或特征空间[8]上源域和目标域之间的差异。在这项工作中,我们明确考虑了由目标相机引起的域内图像变化,以学习目标域的判别式表示。
我们提出的cTransNet受到[14],[16],[36]的启发,但有两点不同。 第一点是,现有工作只是将GAN用作通过生成相机样式样本来提高基线模型的正则化能力的工具,而我们直接从修改后的图像中提取特征。 第二点是, 先前的工作是通过诸如CycleGAN之类的一对一域转换网络执行图像转换的,而我们采用的StarGAN一次实现了多域图像转换。
The Proposed Method
A StarGAN
StarGAN的目的就是训练一个单独的生成器G,学习多领域的映射。StarGAN 把带有目标领域标签c的图像x输入,输出y, StarGAN 包含了两个映射函数, 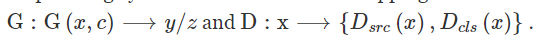
总之,这个网络应用了三种损失.
Ladv 用来区分图像是真是假,
Lcls 帮助鉴别器将真实图像x分类为其对应的原始域类别c。
Lrec 帮助生成器来生成逼真的图片,并且分类为正确的目标领域。
StarGAN的损失函数表达式如下所示:
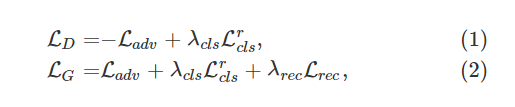
其中λcls和λrec是预先定义的参数,与对抗性损失相比,它们分别控制域分类和重构损失的相对重要性。 StarGAN的概述结构如图3所示。
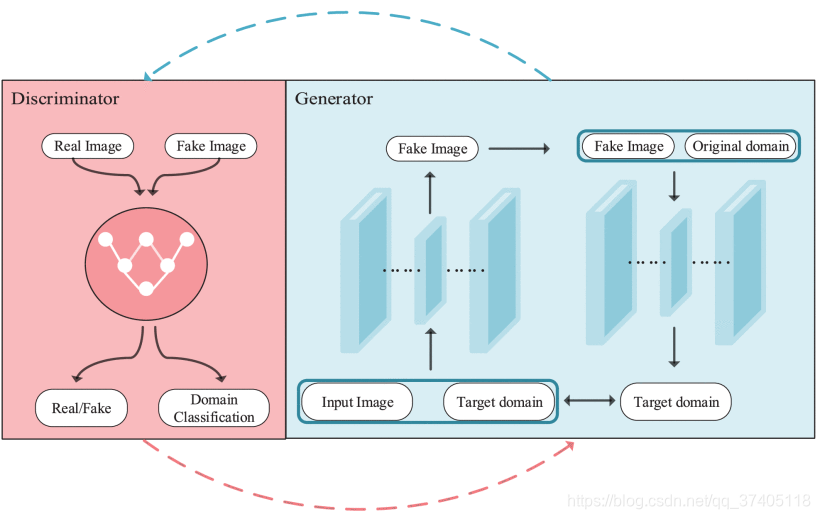
FIGURE 3.The original StarGAN model includes a generator G and a discriminator D. D take image as input then predict the corresponding domain class and Real or Fake for image. G take image then generate image conditional on the target domain.
有关StarGAN的细节信息 可以参考这篇博客 (本人转载)
链接: https://blog.csdn.net/stdcoutzyx/article/details/78829232.
B 基准深度重新ID模型
鉴于真实图像和转换图像都具有ID标签,我们使用ID区分嵌入(IDE)来训练re-ID CNN模型。 采用交叉熵损失函数,IDE 认为行人重识别是常见的图片分类问题,我们使用resnet-50作为主干网络,并按照[18]中的训练策略对ImageNet预训练模型进行微调。不同于【10】中提出的IDE,我们取代了最后的分类层,利用bottleneck层,批处理规范化,ReLU,Dropout,然后是完全连接层。【18】提出来的,可以增加精度。如图4所示
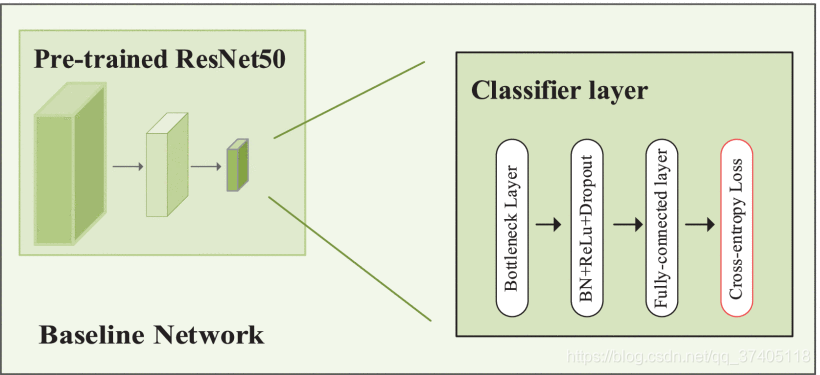
FIGURE 4. The structure for baseline network. We use pre-trained ResNet-50 as backbone and replace the original Fully-connected layer with our custom classifier layer which composed of bottleneck layer, batch normalization layer, ReLU layer with slope 0.1, Dropout layer with rate 0.5 and a fully-connected layer with C-dimensional, where C is the number of classes in the training set. The loss we adopt is cross-entropy loss.
C Domain-Gap Evaluate Network(根据这个距离选择最大的作为最终生成目标)
为了测量每一个领域的间隙,我们需要定义一个距离Ds来评估不同领域的不同风格差距,DE-N基于VGG-19(在ImageNet上进行了预训练)进行了修改,但用平均池替换了最大池,该平均池与[39]中的设置一致。 DE-N中的每个激活层都定义了一个非线性特征提取器,较深层学习的特征比浅层学习的特征更复杂。 给定输入图像x⃗,由DE-N提取的特征包括每个激活层的输出。 通常,每个激活层都有N个大小为M的特征图,其中M表示特征图的高度和宽度。 给定k层具有大小为M的N个特征图,以此方式,可以将k层的滤波器和特征图分别写为Nk和Mk。 因此,由第k层提取的特征可以表示为矩阵Fk∈R^Nk ×Mk
其中Fkij是第k层中第j个位置的第i个滤波器的激活。
假设x⃗是原始图像,y⃗是DE-N提取的特征,则第k层中的特征表示可以分别写为Fk和Yk。(??????)
两种特征表示之间的平方误差损失可以写成: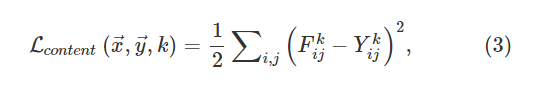
样式相关性由Gram矩阵Gk∈RNk×Mk给出,其中Gkij是第k层中矢量化特征图i和j之间的内积:
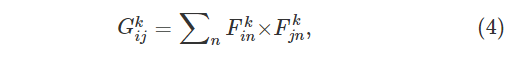
层k中的图像x⃗和图像y⃗之间的样式距离Ek可以形成为: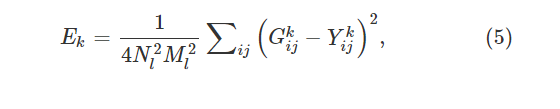
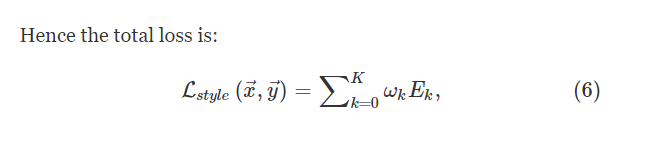
WK是每一层对最终损失的贡献大小权重,图5展示了域差距评估网络的工作流程。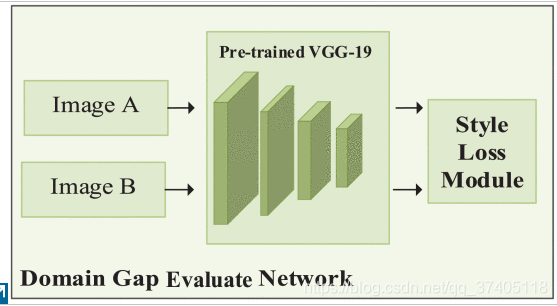
FIGURE 5. The structure for Domain Gap Evaluate network. Consistent with baseline network, we replace the original Fully-connected layer with style loss module which composed of bottleneck layer and the style loss function we defined.
样式损失在计算特定层样式损失的网络中充当透明层。 要计算样式损失,我们需要计算语法矩阵GXL。 gram矩阵是给定矩阵与其转置矩阵相乘的结果。 最后,必须通过将每个元素除以矩阵中元素的总数来对gram矩阵进行归一化。 根据[40],样式特征往往位于网络的更深层。 因此,需要额外的归一化以抵消以下事实:具有较大N维的F ^ XL矩阵在Gram矩阵中产生较大的值。 在实施过程中,我们遵循[39]的作者,此处使用L-BFGS算法。
D cTransNET 的结构(作者所提出来的)
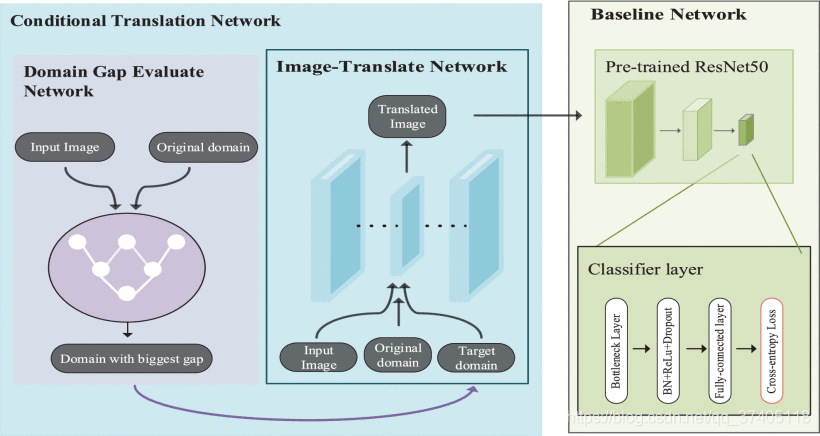
整个cTransNET的结构由基于图像转换的StarGAN和基准网络组成,图像转换网络遵循StarGAN的基本结构,并插入域评估网络,以指导生成器根据域距离度量的输出生成样本。然后,我们将转换后的图像输入基线网络,以预测每个人图像的身份。 在图6中,我们说明了网络的整个结构。(很重要)
E 使用cTransNet训练基准
给定一个新的训练集,该训练集由实际图像和转换后的图像(带有ID标签)组成,本节讨论使用cTransNet的训练策略。
cTransNet在人员重新识别任务中的优势主要体现在它提供其他摄像机视点信息。 但是,cTransNet生成的图像可能会在图像转换过程中引入噪声。在具有多个摄像机和足够图像数据的大规模人员身份数据集的情况下,相比于过度拟合问题,图像转换过程中出现的噪声问题更为重要。(因为生成了图片,变相的扩大了数据集,所以噪声更严重)为了减轻转换图像引入的噪声,我们在转换图像上应用了[16]中提出的改进的标签平滑正则化(LSR) 。 主要思想是在真实标签上分配较少的置信度,并在其他类别上分配较小的权重。
每个样式转换图像的标签分布的重新分配写为:
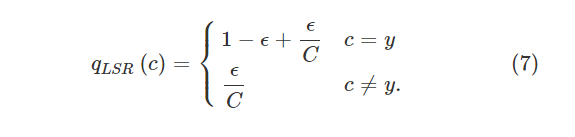
ϵ∈ [0,1]。 当ϵ = 0时,交叉熵损失定义为:(个人怀疑写错了,应该是不等于0吧???)
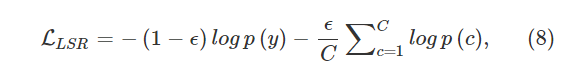
在强制执行期间,我们在实际图像上使用单标签(one-hot)分配,因为它们的标签正确匹配图像内容。 对于转换后的图像,我们遵循[16]中的设置,该设置将ϵ = 0.1
然而,LSR可能在某种程度上减轻了Generative模型引入的噪声,但是由于模型结构的限制,我们不能完全依靠TransNet生成的图像。 在实践中,我们将原始图像和转换后的图像都作为基线模型的输入,然后通过系数α融合两个图像的特征。 最终特征写为:
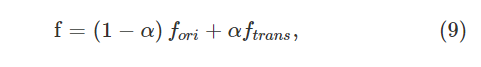
其中α∈[0,1],Fori代表从原始图像中提取的特征,ftrans代表从平移图像中提取的特征。 通过改变α,我们可以调整原始图像和cTransNet翻译的图像之间的平衡。 α与我们使用的数据集之间存在一定的相关性。 根据我们的经验,当数据集具有更复杂的场景和更多的摄像机时,较小的α是可取的。(数据集大,转换的图像可以分配的权重小点,因为原始的数据集更多) 更具体地说,我们将Market-1501,DukeMTMC-reID和MSMT17的α设置为0.7、0.6和0.6。
实验
A 数据集
(1) Market-1501
(2) DukeMTMC-reID
(3) MSMT17
与上述数据集相比,MSMT17具有几个新功能。
a)MSMT17具有更多的身份,边界框和照相机。
b)MSMT17具有复杂的场景和背景,其中包含12个室外场景和3个室内场景。
c)在训练阶段,MSMT17仅使用所有图像的35%,少于其他数据集。
利用rank-1和MAP来评估数据集的精度
实验设置
1)条件翻译模型
根据第III-D节,给定从N个摄像机视图中捕获的训练集,我们只为每个数据集训练一个cTransNet。 在训练过程中,我们将所有输入图像的大小调整为128×128,并使用Adam优化器[41]从头开始训练所有实验的模型,其中λ= 10。 我们将批处理大小设置为16。在前30个时间段中,生成器和鉴别器的学习率均为0.0001,在其余20个时间段中线性降低为零。 与文献[16]中的设置相比,在样式转换中,我们仅根据域间隙评估网络评估的域距离生成了一张伪训练图像。
在基线方法的训练中,我们使用预先训练的ResNet-50作为骨干,并遵循[20]中的训练策略。 具体来说,我们保留所有图像的长宽比,并将它们的大小调整为288×144,然后随机裁剪为256×128。为了提高基线模型的通用性,我们在训练期间应用了随机擦除和随机水平翻转。 我们将执行随机翻转和随机擦除的概率都设置为0.5。 由于大多数人re-id数据集的训练数据不足,因此随机擦除可以在某种程度上减轻模型过度拟合的风险。
在模型结构中,我们根据每个数据集的训练样本数来修改ResNet-50的第二个完全连接层的输出单元。 对于ResNet-50基础层,学习率从0.005开始,对于两个新添加的全连接层,学习率从0.05开始。 我们使用SGD求解器来训练re-ID模型,并将批处理大小设置为32。在40个时期之后,学习率除以10,我们总共训练了60个时期。 在测试中,我们提取Pool-5层的输出作为图像描述符(2,048-dim),并使用余弦距离来计算图像之间的相似度。 在评估过程中,我们采用重新排序[42],这是通用实例检索中常用的另一种有效方法。== 重新排序方法的主要思想是,如果图库图像与k个最近邻居中的查询图像相似,则它更有可能是真实匹配(k是预定义参数)。==
C 实验分析
StarGAN涉及的一个重要参数是Generator内ResNet块的数量。经试验表明,四个resnet块效果最好,
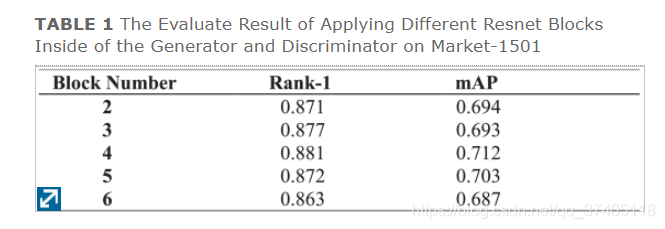
我们执行的方法是将图像转换为通过域间隙评估网络告知的域,并通过基准网络直接评估而无需应用任何技巧。
为了验证LSR的必要性,实验结果得出太高也不行,因为larger的值较大可能会导致性能下降。 根据[16],主要原因可能在于,即使伪图像可能包含一些噪声信息,它们仍然保留了主要的原始图像内容。
根据我们讨论的内容,我们倾向于对原始图像的分类设置较高的置信度。 考虑到以上考虑,我们选择ϵ = 0.1。
D Ablation Experiment
从表2中可以看出,所有三个损失对最终性能都有积极影响。 显然,对抗损失比其他损失更为重要。 从我们的角度来看,原因是在训练过程中对抗损失可以提供更多的梯度。 此外,这三个损失不仅提高了1级精度,而且还有助于训练过程的稳定性。

其次,为了解释DE-N(域间隙评估网络)如何指导生成器生成翻译图像,我们考虑以下实验。 在此实验中,我们仅删除DE-N并保留其他设置。 当删除域间隙评估网络时,我们只需遵循[16]中采用的策略,即使用五个CycleGAN将输入图像转换为所有其他五个相机视点
删除域评估网络可能会在一定程度上改善最终性能,但也会在很大程度上增加模型的复杂性。 总之,域差距评估网络可以在不牺牲精度的情况下提高训练效率,这对于cTransNet非常重要
在训练期间,我们实际上将整个过程分为两个单独的步骤。== 首先,我们将每个域的图像作为一个整体,然后预先计算每个域的距离。 通过这样做,我们获得了每个域的目标域,并将其保存为超参数==。 最后,我们在训练StarGAN时将此超参数传递给生成器(根据输入,计算每个域的距离,根据最大的也就是目标域,作为超参数送给生成器生成目标域的图像)
结果评估
(1) 作者提出的方法提高了精度,并且可以与其他常见的数据增强策略(例如随机擦除和重新排序)一起使用。
总结
(1)在本文中,我们提出了cTransNet,它通过使用基于StarGAN的模型基于原始相机视点生成转换图像来显式地解决人的re-id。
(2)而且,为了减轻由基于GAN的结构引起的噪声水平的提高,将标签平滑正则化(LSR)应用于转换后的图像。
(3)我们的方法是对其他数据增强技术的补充