版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_41427758/article/details/82827684
Motivation
- 对于大幅度的姿势变化以及错检带来的行人框对准问题,现有方法采用constrained attention selection mechanisms解决并不是最优的,如何更好的优化该问题呢?
Contribution
- 提出了新的联合学习多尺度注意力徐州与特征表示方法
- Harmonious Attention Moudle
- hard region-level
- soft pixel-level
==> a lightweight Harmouious Attention module
- cross-attention interaction learning scheme:进一步提高注意力选择与特征表示的兼容性
1.Introduction
- 本文关注的问题:
- 检测算法带来的对准、背景混杂、遮挡、缺失身体问题
- 不同摄像头视角下姿势变化的图像匹配不对准问题
- 现有方法解决思路:
- 成对图像匹配中的局部区域校准和显着性加权 ==> 缺点:依赖手工特征,缺少深度特征的判别力
- Attention deep learning model:借助现有分类模型,过于复杂且只有粗糙的区域注意力,忽视了细节信息,对小数据集的训练不是很有效
- 本文将注意力选择与特征表示进行联合学习,提出了一个轻量级网络HACNN
2.Related Work
- attention selection techniques:
- hand-crafted features
- attention deep learning methods(PDC等):
- regional attention selection sub-network(hard attenion)
- soft attention
- HA-CNN的优势:
- soft + hard
- multi-level correlated attention
- cross-attention interaction learning
3. Harmonious Attention Network
- 目标:在剧烈的视角变化的情况下学到最优的深度特征表示模型
HA-CNN Overview
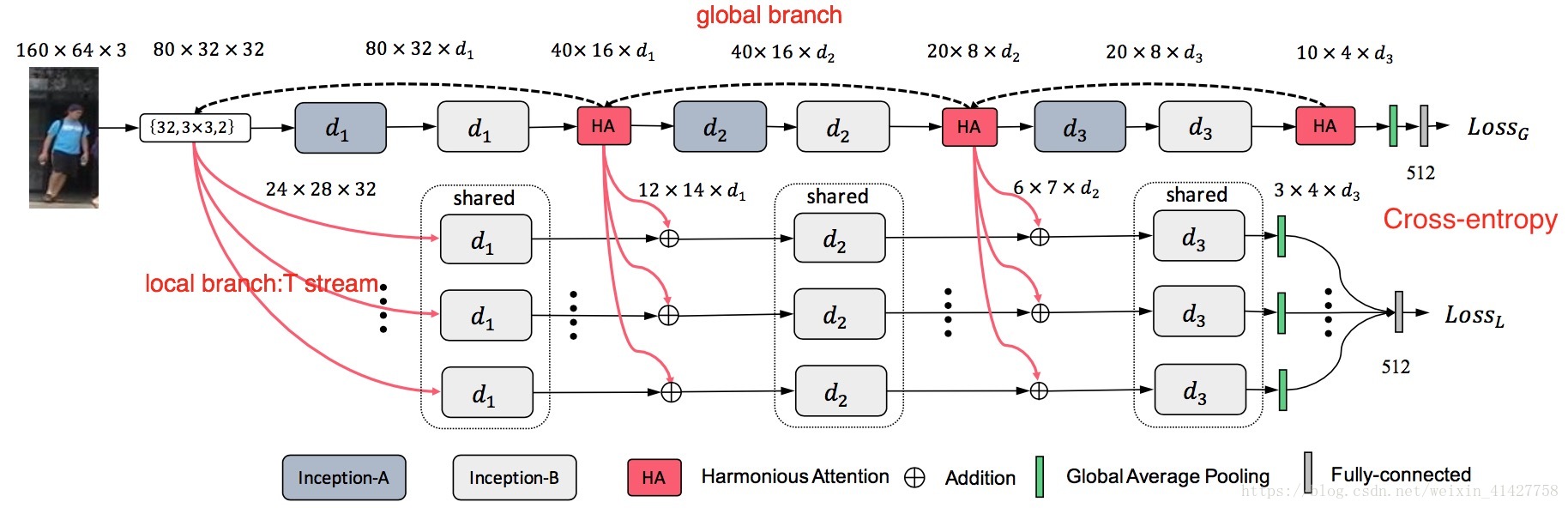
3.1.Harmonious Attention Learning
- hard regional attention(STN) + soft spatial(RAN) + channel attention(SE)

(Ⅰ)Soft Spatial-Channel Attention
(1) Spatial attention:
- 4层的网络(10个参数)
- a global cross-channel averaging pooling layer(通道维度池化)
- 3 x 3 conv s = 2
- resizing bilinear layer
- scaling conv layer:自适应学习融合尺寸,达到与通道注意力的最优融合
- 跨通道池化公式定义:
==>
,对于第二层的卷积降低了c倍参数
- cross-channel pooling合理性:所有通道共享相同的空间注意力图
Channel Attention
- 4-layers
squeeze-and-excitation sub-network
(Ⅱ)Hard Regional Attention
- 作用:利用STN思想,在不同的层次通过转换矩阵定位潜在的
个判别区域 (这里有些细节还不是很清楚需要再看看)
- 与STN的区别:
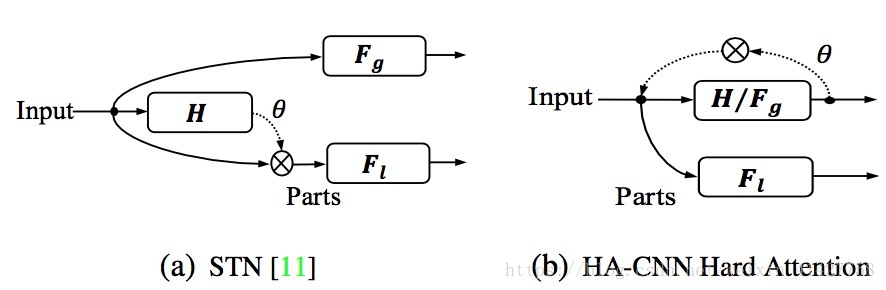
(Ⅲ)Cross-Attention Interaction Learning
-
通过全局与局部特征的交互来提高联合学习soft与hard attention的效果:
- 利用Hard attention产生的区域将全局与局部特征对应
- 利用Hard attention产生的区域将全局与局部特征对应
-
反向传播过程中,全局分支的参数通过全局与局部损失联合进行优化
3.2. Person Re-ID by HA-CNN
- 将行人图片通过HACNN得到1024维的特征表示,并计算 距离进行排序
4. Experiments
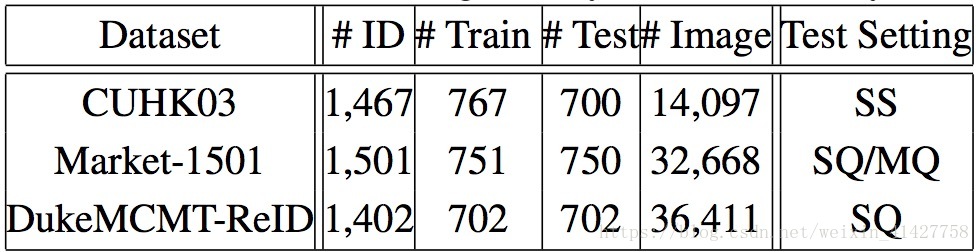
Datasets and Evaluation Protocol
- CUHK03、Market-1501、DukeMTMC
- CMC与mAP

Implementation Details
- Tensorflow
- Inception units:
- Adam、lr:5x10e-4、
- batch size:32、epoch:150、momentum:0.9
- no augmengtation method
4.1. Comparisons to State-of-the-Art Methods
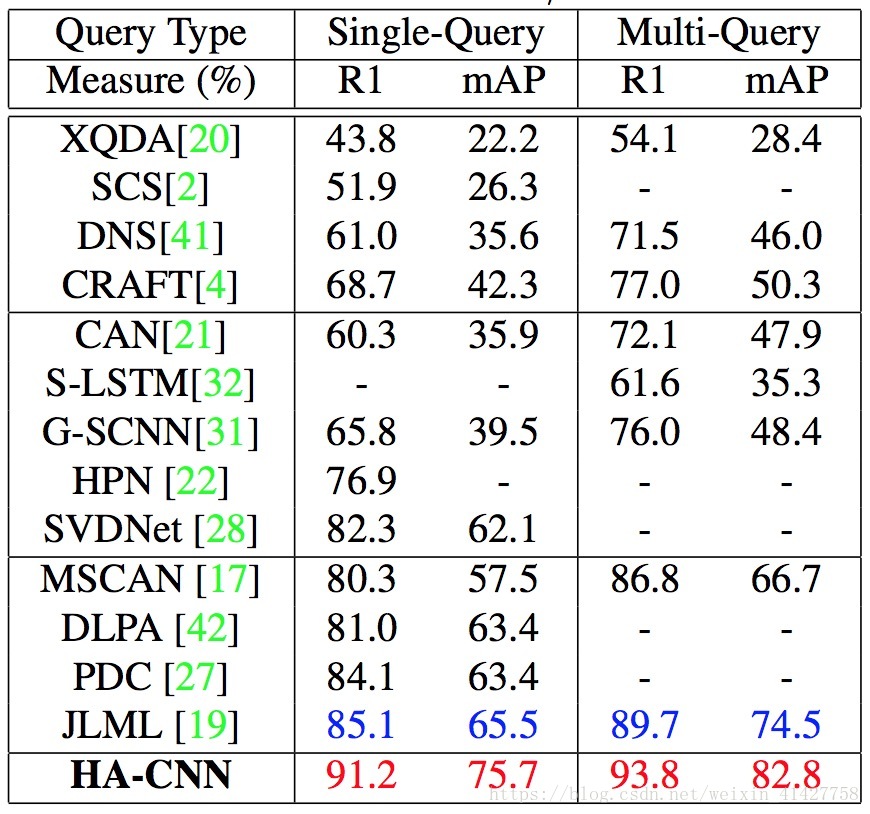
Evaluation on Market-1501
Evaluation on DukeMTMC-ReID
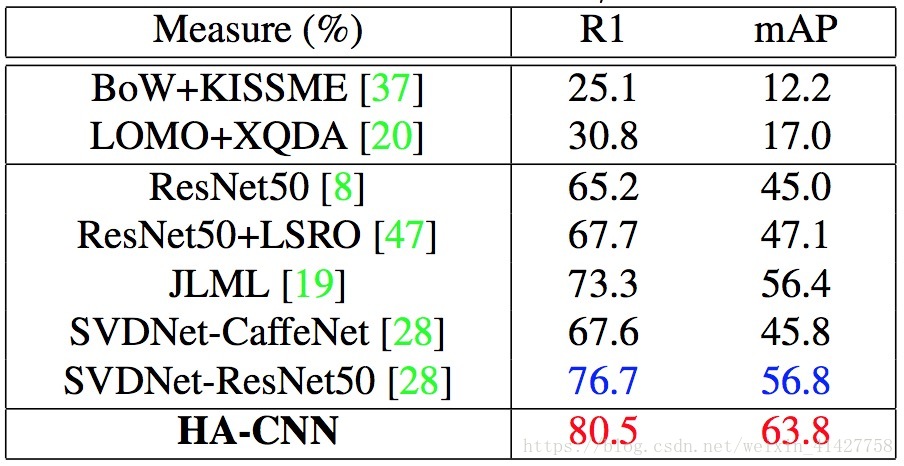
Evaluation on CUHK03

4.2. Further Analysis and Discussions
Effect of Different Types of Attention
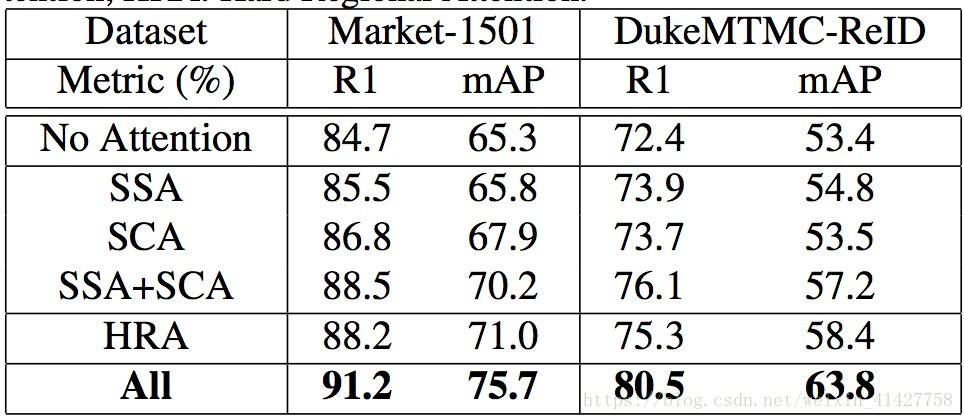
- 评估不同的attention component
- 每个component都对性能有提升
- SSA与SCA结合有互补作用
- hard与soft attention结合进一步提升了性能
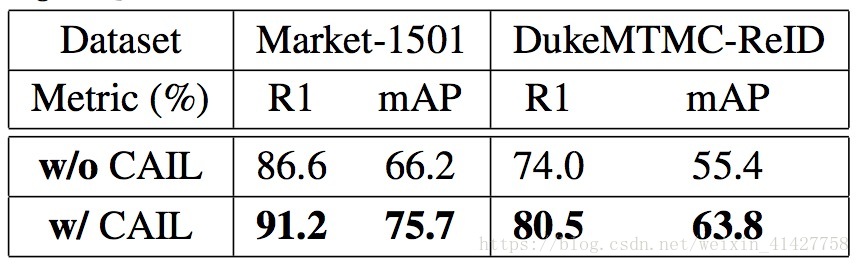
Effect of Cross-Attention Interaction Learning
Effect of Joint Local and Global Features
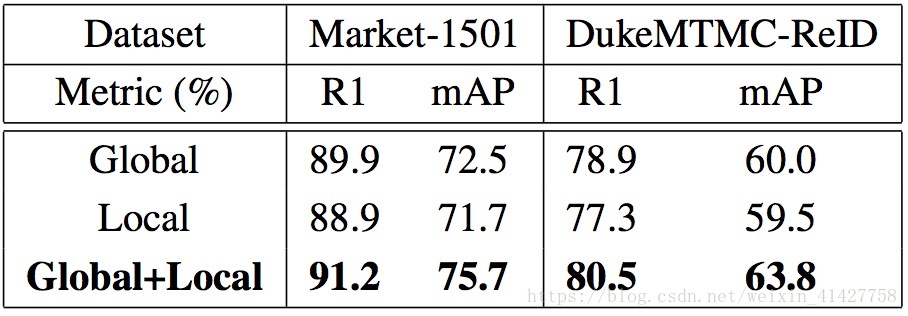
- 全局特征与局部特征具有互补性
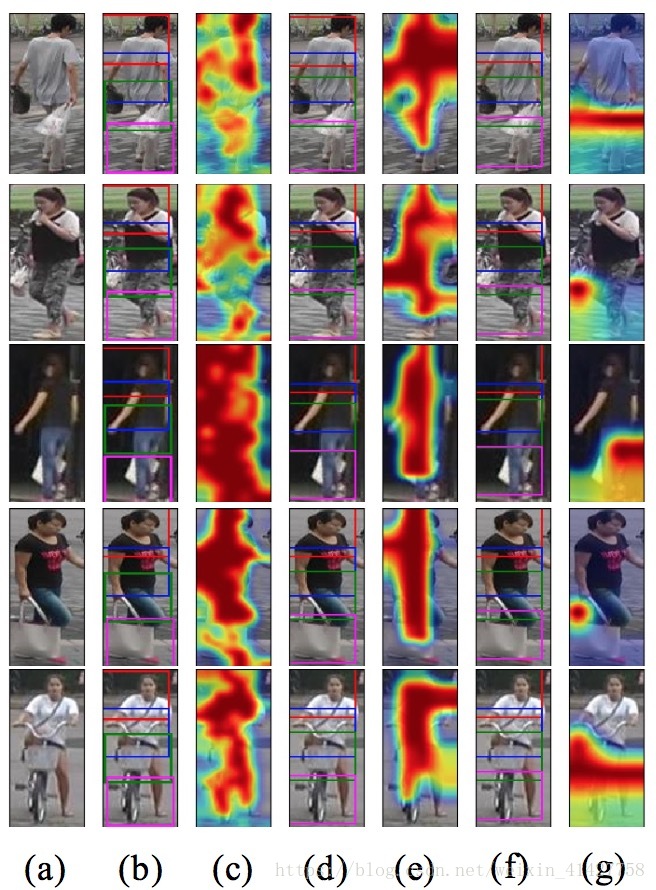
Visualisation of Harmonious Attention
- 不同层次的HA与SA的可视化
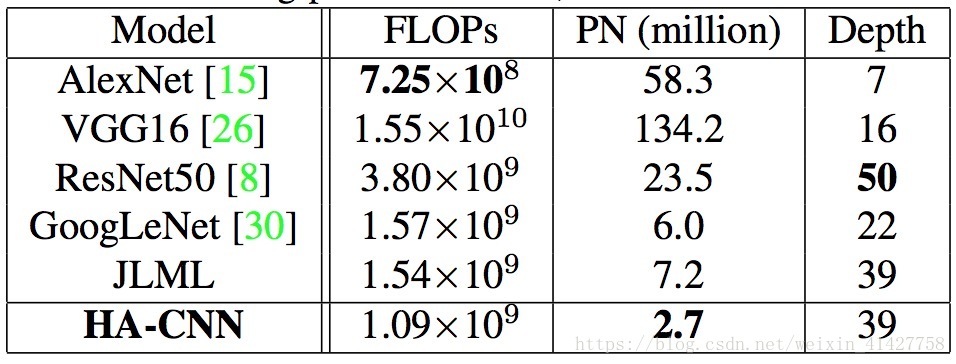
Model Complexity
5. Conclusion
- 提出了轻量级网络HACNN,在三个基准数据上取得了SOTA方法
- 相比其他工作,本文通过结合soft、hard attention提出了Harmounious Attention Module,能更好解决不对准问题以及提高attention方法的互补性
- 提出了CAIL来进一步优化模型的学习
思考
- 本文工作充分利用了现有的attention方法,并没有借助ImageNet预训练模型,取得了SOTA性能,是否今后的工作也可以进一步尝试在re-id数据集上更有针对性的搭建模型呢
- hard attention得到的区域包含很多噪声,有没有更好的方法更精准的定位呢?