文章一
《Neural Relation Extraction with Selective Attention over Instances》
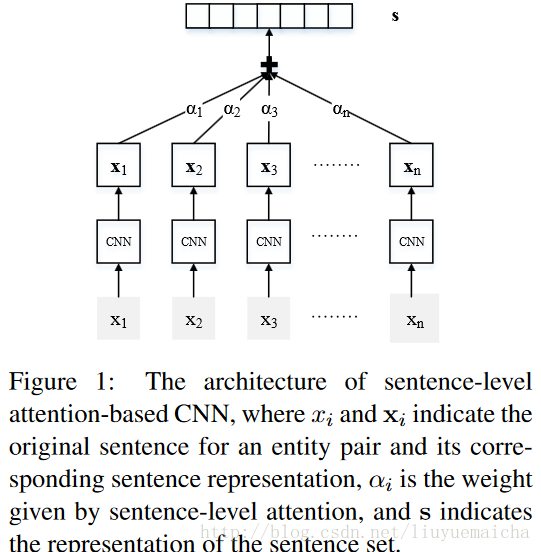
该论文中提到的Distant supervised是一种弱监督形式,作用是在Relation Extraction中可以从未标注的Knowledge Bases(KBs)语料中自动生成训练数据,定义由 (Mintz et al., 2009) 提出,distant supervised假设如果两个entity在KBs中存在某一关系,那么KBs中所有包含这两个entity的sentence都会表达这一关系。当然这样的假设是错误的,或者说是不完全正确的,所以在这个过程中自动生成的训练数据会存在噪音。为了解决这个问题,后来有人通过multi-instance来缓解了噪音。然而这种传统方法的最大弊端是大部分的features是由NLP工具(eg:POS tagging)获得,这种NLP工具产生的错误会在这些传统方法中扩算。再后来,人们提出在关系分类中使用neural net来代替手动特征选取,但是这些方法需要人工标记的sentence-level数据作为训练集,无法应用KBs。
最后 (Zeng et al., 2015) 提出了基于muti-instance的neural net模型,该模型通过distant supervision数据来建立一个关系抽取器。该模型在训练和预测时,假设在包含这两个entity的sentences中,至少会有一条包含这两个entity的relation,从而从中选取概率最大的那条作为训练或预测。该方法取得了不错的效果,然这种选取最大概率的方法也丢失了大量了信息(没有充分利用所有包含这两个entity的sentences)。如何利用所有包含这两个entity的sentences呢?论文使用了sentence-level的attention机制。
引用两点总结:
karis:(1)网络结构上: sentence Encoder:词的嵌入和相对实体位置的嵌入,然后利用CNN得到关系的向量表示; Selective Attention: 计算包含实体的所有有效句子并计算句子权重,以此来降低错误标注句子带来的影响。 (2)学习算法上:交叉熵、SGD,优化的目标是逼近计算句子集合所表达的主要关系类型。 (3)与(Zeng et al., 2015, Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks)的不同在于:后者仅仅在包含实体对的最有可能的一个句子上进行训练,未充分利用语料。
LeoZhao:基本思路: distant supervision: 包含实体对的句子 都表达了 实体之间的specific关系。 1. 解决 标记样本的缺乏 >+ 引入 distant supervision, [Mintz et al., 2009] 1. 解决 传统单向方法的误差积累问题 >+ 使用 CNN去学习 句子的语义(与实体的距离 + embedding本身蕴含的 semantic similarity), 抛弃原有的POS等传统方法。 而 第二步的 RE误差可以传导回来 从而 调整这一部分学习到的句子语义。 >+ 本文采用的是static vector representation, 并不是类似 not-static vector representation [Convolutional neural networks for sentence classification (2014), Y. Kim] 1. 解决 错误标记样本 误导 distant supervision >+ 正向样本 表达了 specific关系, [Zeng et al., 2015]只使用at least one sentence。 >+ 负向样本 不包含 specific关系, 利用sentence-level attention的特性来充分学习这部分特征。
开源代码:
https://github.com/thunlp/NRE 这个是本文的TF代码。 https://github.com/thunlp/TensorFlow-NRE 这个包括了16年RC和RE两个工作。
思考:现在有很多文章是通过知识图谱向量来增强表示学习能力,那么nlp任务是不是也可以加入知识图谱来增加知识表示的语义信息,来达到一个相辅相成的作用?
http://aclweb.org/anthology/N15-1086 由一篇通过对话构建KG的。 将KG用到NLP任务中,可以用KG的embeding形式。
https://github.com/thunlp/KB2E 试过用user, item的embedding来表征 相似度 做 推荐系统的。
**
文章二
**《Distant Supervision for Relation Extraction with Sentence-level Attention and Entity Descriptions》

我的理解:
简述下我对该模型理解和一点疑惑,该模型主要分三部分,APCNN(算是sentence的embedding层),Sentence-level Attention(带有attention机制的分类层)和 Entity Description(描述语句的embedding层)。作者将关系提取作为分类处理,那么应该会有几个候选的关系类别对应了softmax。将bag中的sentences通过APCNN(embedding)处理后转换成对应的vector,并通过attention机制进行softmax分类,这里训练的目标是使分类的准确率最大化。后面附加的Entity Description模型我不太理解,其中训练使Description vector和Entity vector尽可能接近我没疑问,但使这样的训练附加到前面分类模型的训练中就会使效果更好吗?感觉上面的分类模型和Description模型是相互独立的,即使后面公式看到他们两个进行训练目标的整合,也感觉不到Description的训练会对分类的准确率产生什么影响啊。想知道作者是怎么考虑将这两个训练目标进行相加整合的?
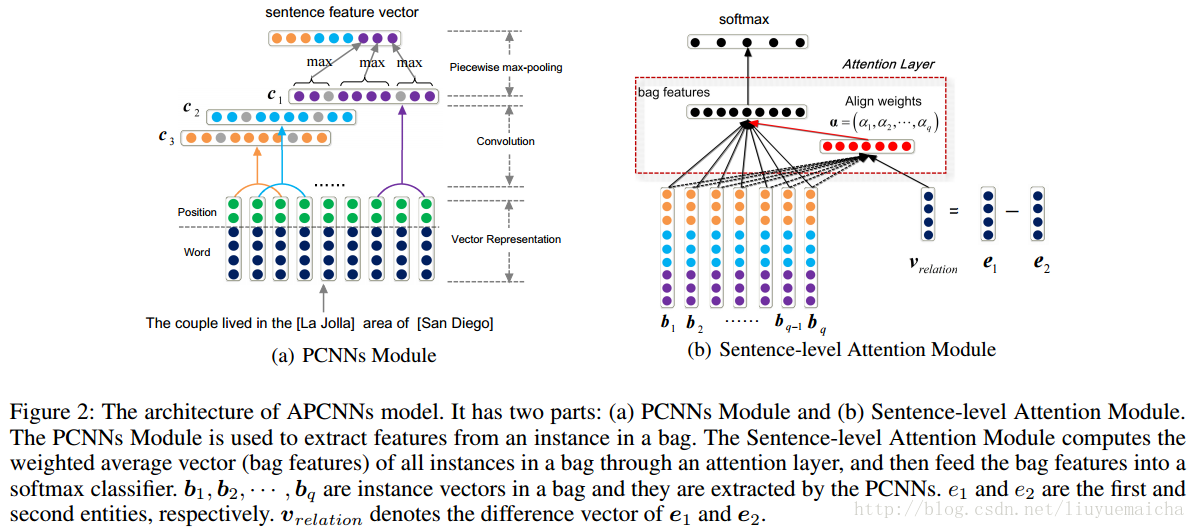
我的疑问:
Figure2中的(a)部分,
(1)每个word对应了两个position embeddings,这两个embedding怎么处理?是将两个位置vector计算成一个vector还是两个vector级联?
(2)postion vector是怎么计算的?在训练时,是不是我们要先确定e1和e2,再计算word分别到e1和e2的距离d1和d2,那我们怎么根据d1和d2来确定对应的位置vector呢?对应的vector是随机初始化还是和其长度大小有关系?