文章目录
课程视频连接:《 深度学习与自然语言处理(6)》
——————————————————————————
对于英文来说,并没有牵扯到分词的问题,因此,这里第一个自然语言处理任务为句法分析。
句法分析的目的是分析出句子的结构,基于词的意思,对于整个句子有一个更深的理解。
1. 原理
1.1. 为什么需要句子结构?
单单依靠句子中一个个的词,是不能够准确理解句子的含义。人类的语言非常复杂和难以理解,不同的单词的组合会有不同的含义。尤其是长句子,有很多的从句和修饰,这就使得其句子的意思可能有多种理解角度。
1.2 如何理解句子结构?
从句子成分上讲,我们可能会有主谓宾定状补表等成分,但是单纯的成分表示并不能从全局上对于句子结构有一个清晰的认识。因此,基于最早于公元前4世纪的印度语言学家Panini对语义、句法和形态依存的分类研究。现代的句法分析逐渐分为两个方向,成分句法分析和依存句法分析。根据hankcs的说法;这并不是随机选择,而是由于前者的优势。90年代的句法分析论文99%都是短语结构树,但后来人们发现依存句法树标注简单,parser准确率高,所以后来(特别是最近十年)基本上就是依存句法树的天下了(至少80%)。
而在我看来,这是两种不同的方式,成分句法树走的是原来词性标注的路子,将词性标注扩展到了词组标注,子句标注等更大的层面,是一种自然的方式。而依存句法分析则是从关系入手,判断的是两个词或词组之间的关系,从而形成了依存句法树。(关系识别是一个现代非常庞大的任务,如实体关系、事件关系、篇章关系等,甚至所谓的知识图谱,也是关系识别的一种。更不用说问答任务和语义匹配任务,更是关系识别的特殊情况)。
成分句法树的形式如下,标注每个词的成分,然后词和词组成更大的短语或子句,继续进行标注成分,从而形成一棵树:
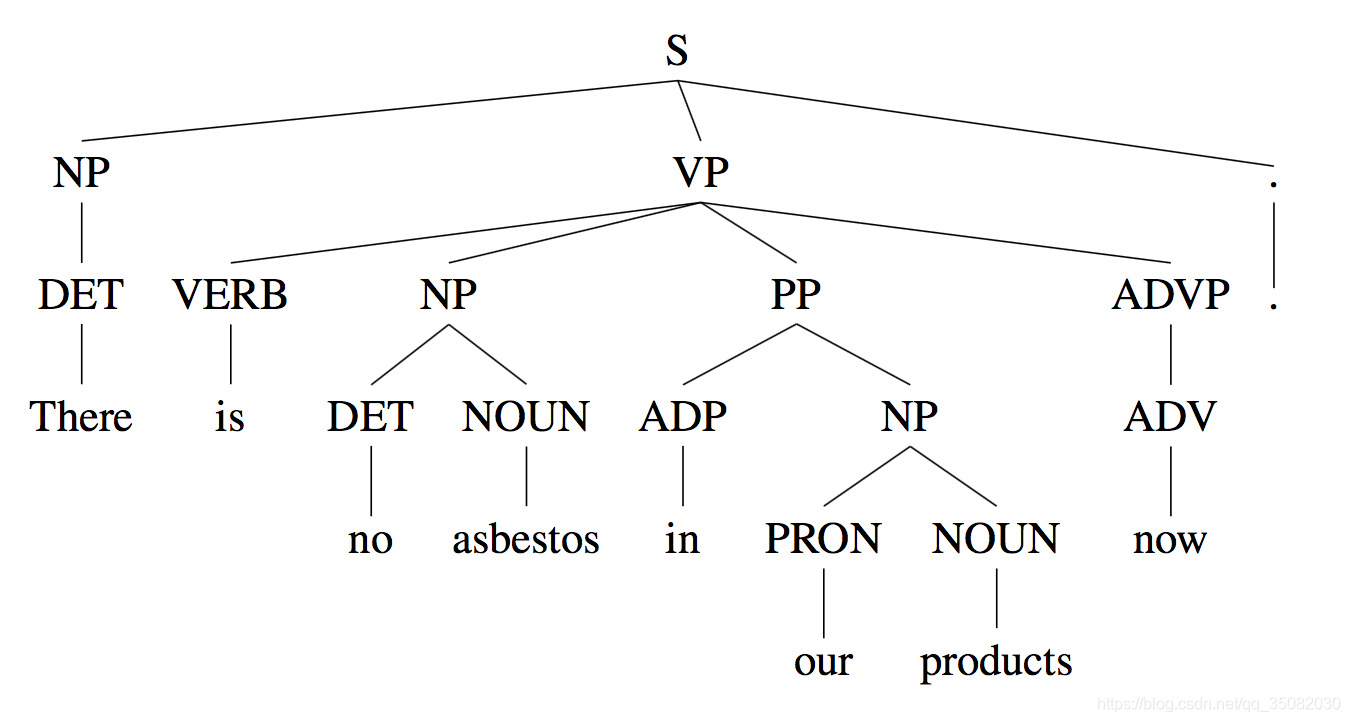
依存句法树的形式如下,只需要判断两个词之间是否存在关系即可,任务更加简单:

1.3 有什么难点?
那么,无论我们使用何种方法,进行句法分析存在什么客观问题?
1.1.1 介词短语依附(PPs)修饰会使得句子有歧义
介词短语如with, of, in 等开头的短语,可以用来修饰其他成分,如果像汉语一样就近原则,倒并不会有什么大问题,而难就难在,有很多句子会有不同的理解。
例如:San Jose cops kill man with knife?
一种解释是with knife 可以修饰kill,警察用刀杀死了那个人。
另一种解释是with knife也可以修饰man,警察杀死那个拿刀的人。
例如:Scientists count whales from space.
一种解释是from space 可以修饰whale,即科学家统计来自太空的鲸鱼。
另一种解释是from space也可以修饰count,即科学家从空中统计鲸鱼。
对应的,若有N个修饰词,将会有卡特兰数种可能,如下图所示:
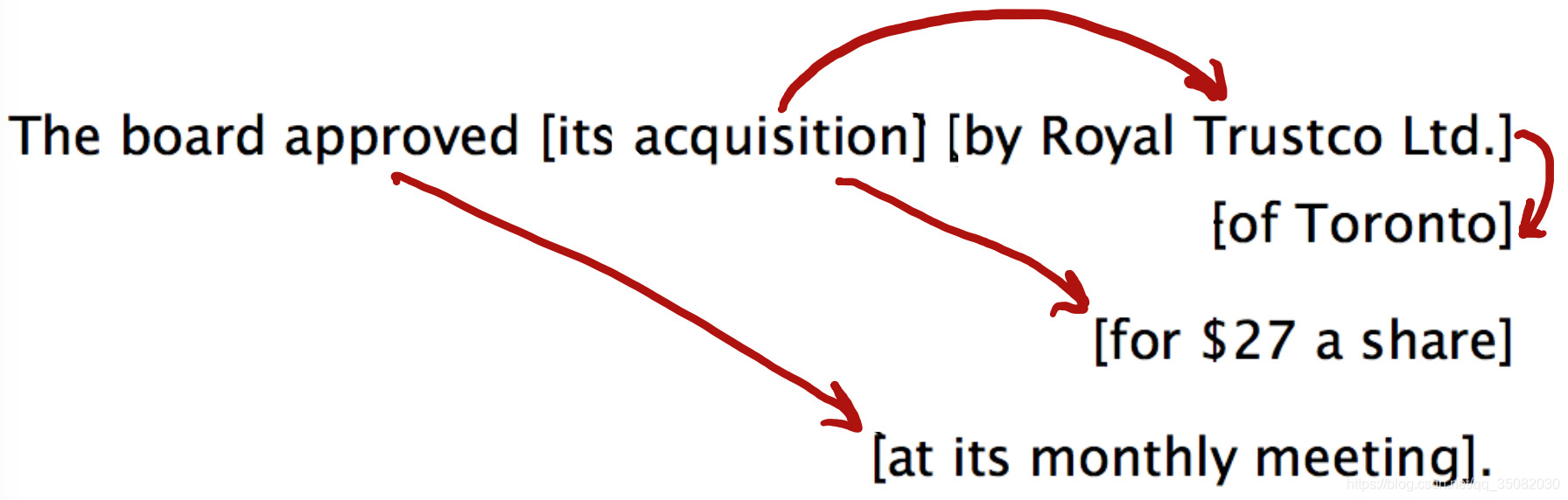
更不用提及更加复杂的从句表示了,如下所示:
Proponents of G-M foods argue using biotechnology in the production of food products has many benefits: it speeds up the process of breeding plants and animals with desired characteristics; can be used to introduce traits that a product wouldn‘t traditionally have; can improve the nutritional value of products; and can produce cheaper and more environmentally friendly fertilizers.
1.1.2 并列范围模糊
就像刚才提到的那样,并列范围模糊也是一个比较大的问题,
例如:Shuttle veteran and longtime NASA executive Fred Gregory appointed to board.
一种解释是Shuttle veteran and longtime NASA是一个东西。
另一种解释是Shuttle veteran是一个东西,ongtime NASA executive Fred Gregory是另一个东西。
再如:Doctor:No heart,cognitive issues.
一种解释是No heart是一件事,cognitive issues是另一件事。
另一种解释是heart,cognitive issues是一件事。
1.1.3. 形容词修饰歧义
例如:Students get first hand job experience.
一种解释是学生得到第一手工作经验,另一种解释。。。自己理解,提示[hand job]。
1.1.4. 动词短语歧义
和修饰词一样,动词短语也有修饰歧义。
例如:Mutilated body washes up on Rio beach to be used for Olympics beach volleyball.
一种解释是to be used for Olympics beach volleyball.可以形容 Rio beach。
另一种解释是to be used for Olympics beach volleyball.也可以形容Mutilated body。
2. 语料库
早期关于人工智能自然语言处理都是遵循着符号主义的思路,尤其是受到乔姆斯基的文法理论,大多是使用一些规则和推理进行自动句法分析。后来,基于统计学习方法的兴起使得人们越来越依靠大规模语料进行实验。其中比较著名的两个树库有PTB(英文)和CTB(中文)两个,当然也有其他语言的语料库(UTB)。为实验提供了大量可用的信息,比如句法信息,词性,以及其他语言学特征等。另一个比较重要的功能就是为模型提供了评判标准。毕竟一人一世界,千人千雷特。
3. 方法
3.1 任务定义
3.1.1 成分句法分析
成分句法分析分为两个任务,一个任务是组块分析,即判断哪几个合并为更大的语义单元,另一个任务则是对词组、子句进行成分分类。然后不断循环两个任务,最终构建一个成分句法树。
3.1.2 依存句法分析
依存句法的任务则是先判断两个语义单元是否存在关系,然后判断谁更重要,以arrow的形式连接起来,最后在arrow上标记其关系,最终也是以句法树的形式将进行展示。
另外一个需要注意的是,一般的其句法弧并不会交叉,但是有时候也会有交叉情况,这时候,其实可以调整语序,使得其不交叉而不影响语义表达。
3.2 传统机器学习方法
这里主要讲解依存句法分析,现有的依存句法分析器主要有动态规划(PCFG)、图算法和最小生成树及基于转移的句法分析器,其中以基于转移的句法分析器最为流行。传统的句法分析方法在之前的句法分析理论中都已提及过了,这里不再赘述,这里主要提及基于转移的句法分析方法。
3.2.2 基于转移的句法分析
基于转移的句法分析器初始时,只需要一个栈和一个队列,分别存储着已构建完成的树和待构建的语义单元,然后对于每一个在队列头的语义单元判断其操作,可以为移进(Shift)和规约(Reduce)两种行为,分别对应让队列头的语义单元进入栈中还是和栈顶元素合并:
经典的基于转移的句法分析器具有以下特点:
1.使用机器学习模型决定行为
2.每个行为都只有3种选择(Shift-Right-Left),也可以简化为两种(Shift-Reduce),而且可以从词和词性中进行学习。
3.没有搜索过程,可以使用柱搜索来提升性能,但会降低运行速度。
4.模型虽然没有最优模型好,但是是一个线性模型,可以应用到实践中。
而这其中的重点就是决定行为的模型,常用的只需要使用最大熵模型等进行训练,效果不错。
3.3 神经网络方法
为什么要用神经网络方法实现依存句法分析器?
1.数据稀疏
2.不可实现
3.昂贵计算
神经网络方法都是基于图和基于转移的,重点在于将原有的分类模型替换为神经网络模型即可。
3.4 评估标准
评估标准有UAS和LAS,UAS不评判其关系标签,LAS评判其关系标签。
