1.调试处理(Tuning process)
- 调参优先级(红色>橙色>紫色)

如何做:(1)随机取值;(2)由粗糙到精细
3.2为超参数选择合适的范围(Using an appropriate scale to pick hyperparameters)
1.搜索超参数α: 假设你在搜索超参数α(学习速率),假设你怀疑其值最小是0.0001或最大是1。如果你画一条从0.0001到1的数轴,沿其随机均匀取值,那90%的数值将会落在0.1到1之间,结果就是,在0.1到1之间,应用了90%的资源,而在0.0001到0.1之间,只有10%的搜索资源,这看上去不太对。
反而,用对数标尺搜索超参数的方式会更合理,因此这里不使用线性轴,分别依次取0.0001,0.001,0.01,0.1,1,在对数轴上均匀随机取点,这样,在0.0001到0.001之间,就会有更多的搜索资源可用,还有在0.001到0.01之间等等。
可以这样做: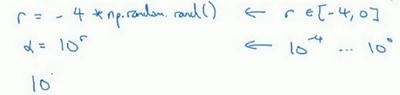
2.β取值: 你想在0.9到0.999区间搜索,那就不能用线性轴取值,不要随机均匀在此区间取值,所以考虑这个问题最好的方法就是,我们要探究的是1-β,此值在0.1到0.001区间内。
注意:
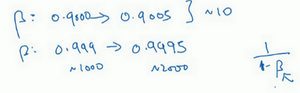
在这两种情况下,是根据大概10个值取平均。但这里,它是指数的加权平均值,基于1000个值,现在是2000个值,因为这个公式1/(1-β),当β接近1时,β就会对细微的变化变得很敏感。所以整个取值过程中,你需要更加密集地取值,在β 接近1的区间内,或者说,当1-β 接近于0时,这样,你就可以更加有效的分布取样点,更有效率的探究可能的结果。
3.3超参数调试的实践:Pandas VS Caviar(Hyperparameters tuning in practice: Pandas vs. Caviar)
-
关于如何搜索超参数的问题,有两种不同的方式:
1.一种是你照看一个模型,通常是有庞大的数据组,但没有许多计算资源或足够的CPU和GPU的前提下,基本而言,你只可以一次负担起试验一个模型或一小批模型,在这种情况下,即使当它在试验时,你也可以逐渐改良。2.另一种方法则是同时试验多种模型,你设置了一些超参数,尽管让它自己运行。用这种方式你可以试验许多不同的参数设定,然后只是最后快速选择工作效果最好的那个。
3.4归一化网络的激活函数(Normalizing activations in a network)
1.效果: Batch归一化会使你的参数搜索问题变得很容易,使神经网络对超参数的选择更加稳定,超参数的范围会更加庞大,工作效果也很好,也会使你的训练更加容易,甚至是深层网络。
2.争论: 深度学习文献中有一些争论,关于在激活函数之前是否应该将值z归一化,或是否应该在应用激活函数a后再规范值。实践中,经常做的是归一化z。
3.实现:
(1)你要计算平均值,然后用正如你常用的那个公式计算方差,接着,你会取每个z^((i))值,使其规范化,方法如下,减去均值再除以标准偏差,为了使数值稳定,通常将ε作为分母,以防σ=0的情况。
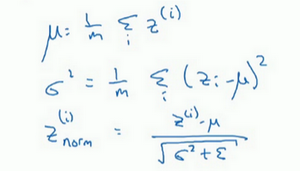
(2)现在我们已把这些z值标准化,化为含平均值0和标准单位方差,所以z的每一个分量都含有平均值0和方差1,但我们不想让隐藏单元总是含有平均值0和方差1,也许隐藏单元有了不同的分布会有意义,所以我们所要做的就是计算,

γ和β是你模型的学习参数,和更新其他参数一样,你可以用优化算法如Momentum、Adam等。注意:γ和β的作用是,你可以随意设置̃z^((i)) 的平均值,事实上,如果γ=√(σ^2+ε), 如果γ等于这个分母项(z_norm((i))=(z((i))-μ)/√(σ^2+ε)中的分母), β等于μ,这里的这个值是z_norm((i))=(z((i))-μ)/√(σ^2+ε)中的μ, 那么γz_norm^((i))+β 的作用在于,它会精确转化这个方程,如果这些成立(γ=√(σ^2+ε),β=μ), 那么̃z((i))=z((i))。
通过对γ和β合理设定,规范化过程,即这四个等式,从根本来说,只是计算恒等函数,通过赋予γ和β其它值,可以使你构造含其它平均值和方差的隐藏单元值。
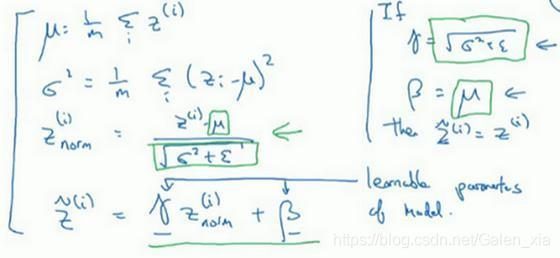
所以,在网络匹配这个单元的方式,之前可能是用z^((1)), z^((2)) 等等,现在则会用̃z^((i)) 取代z^((i)),方便神经网络中的后续计算。如果你想放回[l],以清楚的表明它位于哪层,你可以把它放这。
归一化输入特征X是怎样有助于神经网络中的学习,Batch归一化的作用是它适用的归一化过程,不只是输入层,甚至同样适用于神经网络中的深度隐藏层。
4.说明: 应用Batch归一化了一些隐藏单元值中的平均值和方差,不过训练输入和这些隐藏单元值的一个区别是,你也许不想隐藏单元值必须是平均值0和方差1。
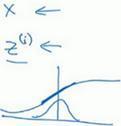
比如,如果你有sigmoid激活函数,你不想让你的值总是全部集中在这里(就是上图中的中间部分),你想使它们有更大的方差,或不是0的平均值,以便更好的利用非线性的sigmoid函数,而不是使所有的值都集中于这个线性版本中,这就是为什么有了γ和β两个参数后,你可以确保所有的z^((i)) 值可以是你想赋予的任意值,或者它的作用是保证隐藏的单元已使均值和方差标准化。那里,均值和方差由两参数控制,即γ和β,学习算法可以设置为任何值,所以它真正的作用是,使**隐藏单元值的均值和方差标准化,即z^((i))有固定的均值和方差,均值和方差可以是0和1,也可以是其它值,它是由γ和β两参数控制的。**
3.5 将Batch Norm你和进神经网络(Fitting Batch Norm into a neural network)
-
Batch归一化的做法是将z^([1]) 值进行Batch归一化,简称BN,此过程将由β^([1]) 和γ^([1]) 两参数控制,这一操作会给你一个新的规范化的z^([1] )值(̃z^([1] )),然后将其输入激活函数中得到a^([1]), 即a^([1]) = g^([1]) (̃z^([l]))。
-
注意一点:Batch归一化做的是,它要看这个mini-batch,先将z ^([l)归一化,结果为均值0和标准方差,再由β和γ重缩放,但这意味着,无论b ^([l])的值是多少,都是要被减去的,因为在Batch归一化的过程中,你要计算z ^([l)的均值,再减去平均值,在mini-batch中增加任何常数,数值都不会改变,因为加上的任何常数都将会被均值减去所抵消。所以Batch归一化超过了此层z ^([l)的均值,b ^([l])这个参数没有意义,你必须去掉它,由β ^([l])代替,这是个控制参数,会影响转移或偏置条件。
3.6 Batch Norm为什么奏效?(Why does Batch Borm work?)
- 为什么深度网络需要BN呢?我们都知道,深度学习的话尤其是在CV上都需要对数据做归一化,因为深度神经网络主要就是为了学习训练数据的分布,并在测试集上达到很好的泛化效果,但是,如果我们每一个batch输入的数据都具有不同的分布,显然会给网络的训练带来困难。另一方面,数据经过一层层网络计算后,其数据分布也在发生着变化,此现象称为InternalInternal InternalInternal CovariateCovariate CovariateCovariate ShiftShift ShiftShift,接下来会详细解释,会给下一层的网络学习带来困难。batchnormbatchnorm batchnormbatchnorm直译过来就是批规范化,就是为了解决这个分布变化问题。
1.原因一:你已经看到如何归一化输入特征值x,使其均值为0,方差1,它又是怎样加速学习的,有一些从0到1而不是从1到1000的特征值,通过归一化所有的输入特征值x,以获得类似范围的值,可以加速学习。所以Batch归一化起的作用的原因,直观的一点就是,它在做类似的工作,但不仅仅对于这里的输入值,还有隐藏单元的值。
2.原因二:它可以使权重比你的网络更滞后或更深层。提升了层层之间的相互独立性,降低了前一层参数变动对后层的影响等价于减少了后层对前层的参数限制,使得参数初始化变得更加容易。
3.Batch归一化还有一个作用,它有轻微的正则化效果。
参考链接:
1.https://blog.csdn.net/airliberal/article/details/89021943
2.https://blog.csdn.net/qq_25737169/article/details/79048516
3.7测试时的Batch Norm(Batch Norm at test time)
- 在训练时,μ和σ^2 是在整个mini-batch上计算出来的包含了像是64或128或其它一定数量的样本,但在测试时,你可能需要逐一处理样本,方法是根据你的训练集估算μ和σ^2, 估算的方式有很多种,理论上你可以在最终的网络中运行整个训练集来得到μ和σ^2, 但在实际操作中,我们通常运用指数加权平均来追踪在训练过程中你看到的μ和σ^2 的值。还可以用指数加权平均,有时也叫做流动平均来粗略估算μ和σ^2, 然后在测试中使用μ和σ^2 的值来进行你所需要的隐藏单元z值的调整。在实践中,不管你用什么方式估算μ和σ^2 ,这套过程都是比较稳健的,因此我不太会担心你具体的操作方式,而且如果你使用的是某种深度学习框架,通常会有默认的估算μ和σ^2的方式,应该一样会起到比较好的效果。但在实践中,任何合理的估算你的隐藏单元z值的均值和方差的方式,在测试中应该都会有效。
3.8 Softmax回归(Softmax regression)
看下图:
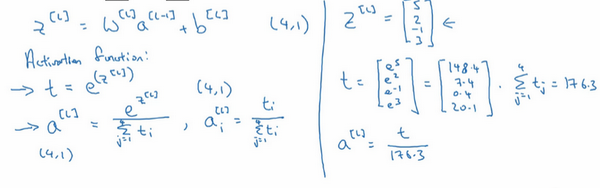
softmax loss层的求导反向传播:https://blog.csdn.net/b876144622/article/details/80958092
