前言
Multi-Stage Pathological Image Classification using Semantic Segmentation ICCV2019论文,日本的作者,主要是东京大学的。解决的是病理学领域,组织切片上病变组织的识别与分类。所谓Multi-Stage是指在传统Classify Net的基础上加了一个Segementaion Net。主要的创新点在如何连接Classify Net 与 Segementation Net。
下图为组织切片的图像:
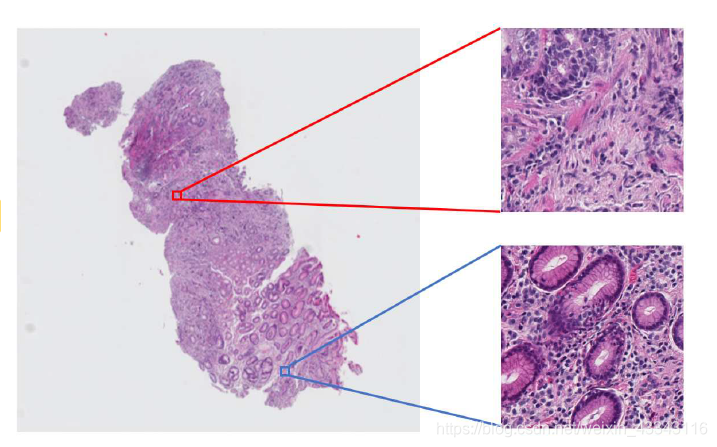
Motivation
组织切片图像像素大(Over pixels)不能直接拿到分类网络训练,所以目前常用的手段是将其分割成固定大小的小Size的图再放入网络训练。但是这种做法有一个问题,用原文中的话来说就是:However, patch-based classifi-cation uses only patch-scale local information but ignores the relationship between neighboring patches.
因此,作者想要提出一种解决方案来弥补ignores the relationship between neighboring patches的缺点,这是全篇的出发点。
此外,作者还提出了两种训练方法以减少内存的消耗,但是这不是我看这篇论文的重点,所以此部分内容只是简单概括
Model
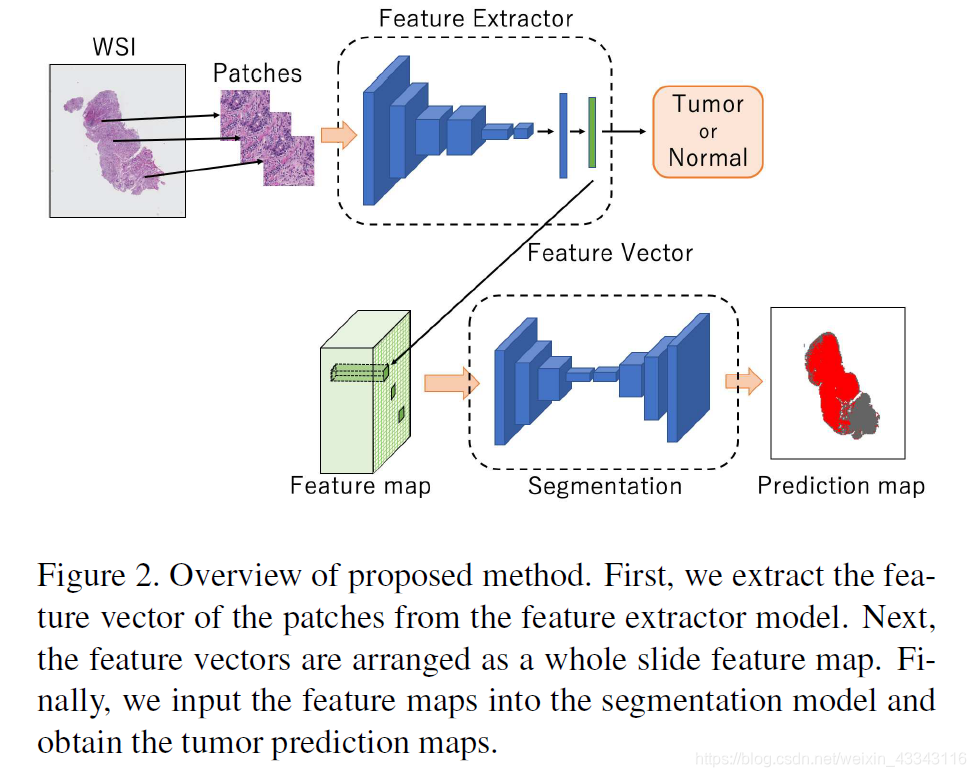
下面我将用序列的方式解释整个模型
- 首先将一幅大尺度的组织切片图分割成若干个patches(文中为256*256)
- 将每个patches送入Feature Extractor,得到一列向量(文中为16*1)
- 将每一个patch对应的vector合在一起,组合成一张Feature Map,如果你对这里不理解,可以把一个vector想象成一根筷子,Feature Map就相当于一把筷子,筷子的数量就是patch的数量
- 然后将第三步中得到的Feature Map送入Segementation Net,进行Encoder和Decoder,最终的到Prediction Map
值得注意的是:关于Label论文中并没有讲的很清楚,所以对一开始的理解会有一些影响:
Feature Extracter 的Label是对应的patch中有无tumor,假设中one-hot这种形式,表示为01或者 10
Segementaion的Label就是数据集中的label 标注了病灶的区域,如下图所示:

如果你对我上述流程的后面还是不清楚的话,也没有关系,作者给出了跟详细的解释图:
网络的关键在于如何优化,有两种思路,第一种思路是分别优化,即分别训练两个网络;第二个思路是进行端到端的训练,由于直接训练太过于耗费资源,文章提出只利用必要的结果,其余全部丢弃。
由于这里不是我的重点,详细见论文
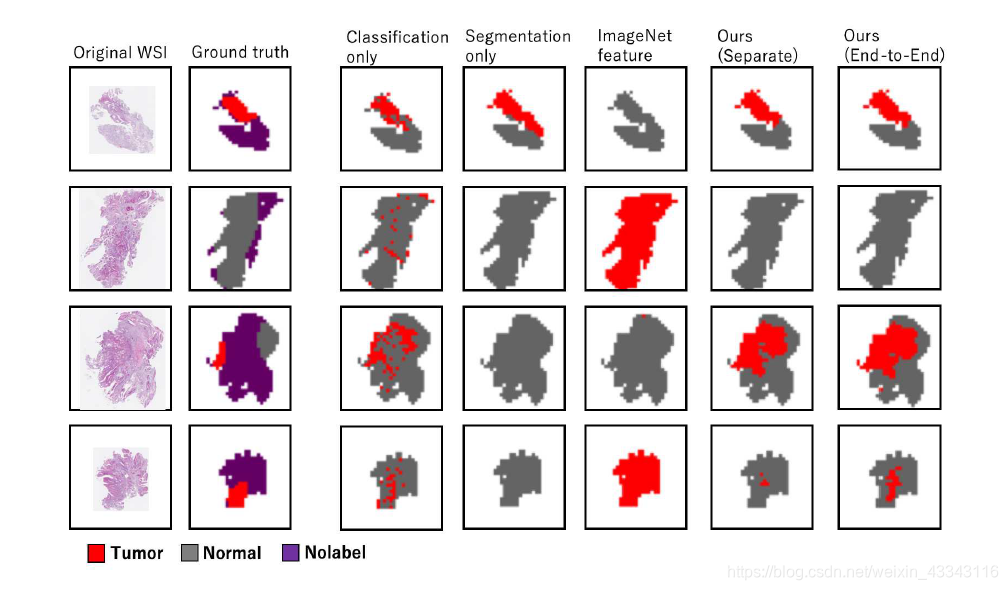
Experiment
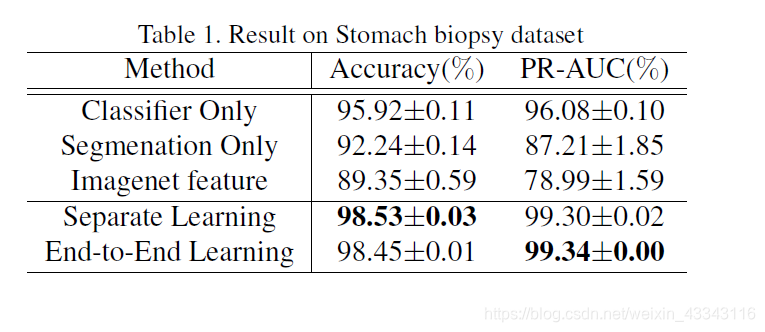
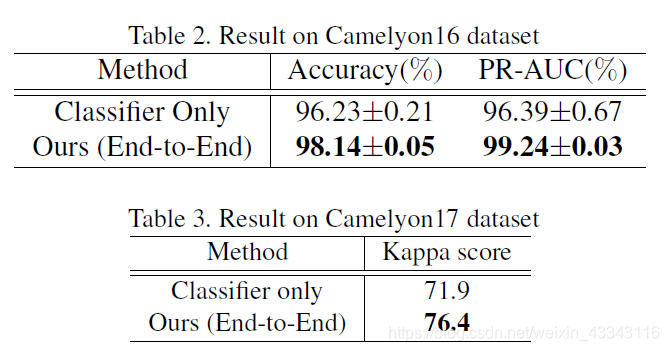
从数据上来看,确实有一点提升,但是从效果图来看,提升能力似乎有限
总结
这篇论文从解决将large resolution 的image 分割成patch产生的问题入手,找准了问题关键:ignores the relationship between neighboring patches。通过新建带有patch之间关系信息的Feature Map来在一定程度上解决这个问题,并且也达到了预期效果,同时,在训练时使用各种小技巧,减少显存的占用。但是局限性在于,考虑了patches之间关系的信息,但是也损失了patch连接处线条和纹理信息。猜想这种方法用于边缘检测可能效果提升不大。
而且,construct Feature Map的方式也比较简单粗暴,我认为这只是换一种方式堆叠,不知道与其它常用堆叠方式有什么异同。
