首次将GAN用于语义分割,用于辨别分割图是来自GT还是来自分割网络。作者的想法来自借助GAN可以检测和矫正GT和模型分割图的高阶不一致。最后在Standford和PASCAL VOC 数据集上验证了想法。
对抗学习:
使用两个权重和的混合损失函数进行优化,第一个是多类别交叉熵优化分割模型,使用S(x),表示类别c的概率图,第二个损失基于辅助对抗卷积网络,如果辨别器可以分辨出真实的标签和分割模型输出的标签,那么它就会很大。因为对抗CNN认为整个图片或者图片的一部分,和高阶的标签统计不匹配。
我们使用a(x,y)∈[0,1]表示对抗模型预测y是x的标签而不是由分割模型输出s()的标签的概率。
给出数据Xn,对应的标签Yn,损失定义为:
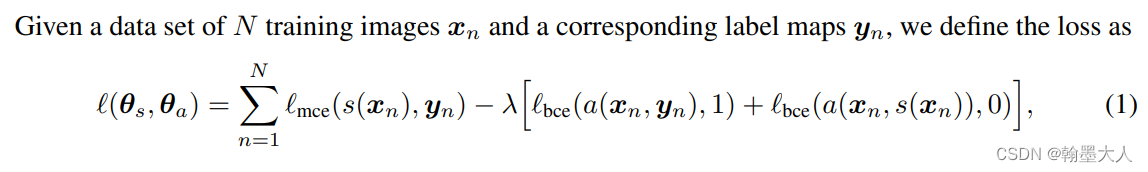
原始GAN的损失为:

看第一项:标签与经过segment模型的输出进行损失计算,即为不加对抗网络的损失,也即为加了对抗网络的生成器损失。

第二项:按理讲就是判别器损失了,判别器中我们知道需要输入的是原始的x和生成的S(x)。
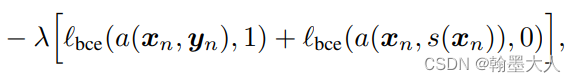
a()输入的是原始图片Yn是Xn GT的概率越大越好,输入的是分割后的S(Xn),则是Xn GT的概率越小越好。
最小化分割模型损失是为了让模型分割的更准确,最大化对抗模型损失是为了让对抗模型辨别的更准确。

训练对抗模型:

训练分割模型:这里多了一个正则化项,解释为在训练分割模型时候还要降低对抗模型的表现。我们最小化分割模型的损失,根据公式我们要最大化λLbce,λLbce表示的是将分割模型输出的结果预测为真实标签的概率,我们希望他为0,如果要最大化,则将分割模型输出的结果预测为真实标签的概率最大,可以替换为将分割模型输出的结果预测为真实标签的概率希望他为1。随着模型训练,我们希望分辨器将分割模型的输出预测为x真实标签的概率为1的损失最小,就与前面的mce损失一致。

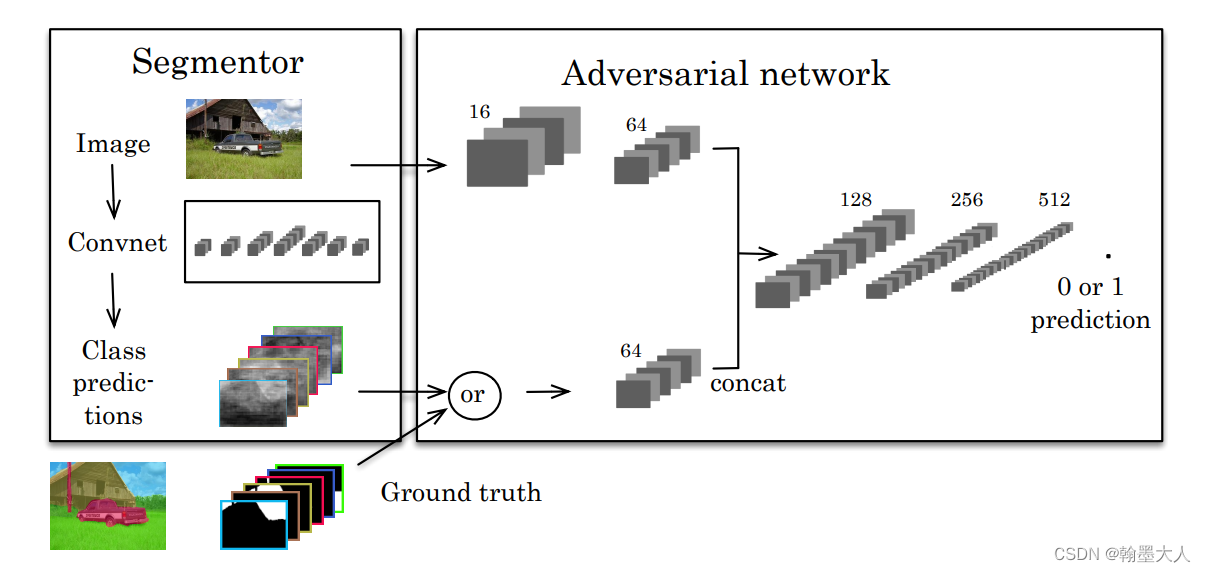
根据描述我们可以画出模型框图:
在两个数据集采用不同的模型:
在Standford Background数据集上,对抗模型输入为label map和对应的RGB,label map或者是真实的GT或者是分割输出的mask。两个分支分别处理RGB和label map,每一个输入信号的通道是一样的为64,然后两个信号传入一系列的卷积和池化层。紧接着一个sigmoid输出binary class的概率。
在Pascal Voc上使用了三种变体:Basic(使用分割的label map),Product(使用真实的GT),Scaling。在实验时候采用两种结构:
LargeFOV:label map的大小为34x34.
smallFOV:label map的大小为18x18.
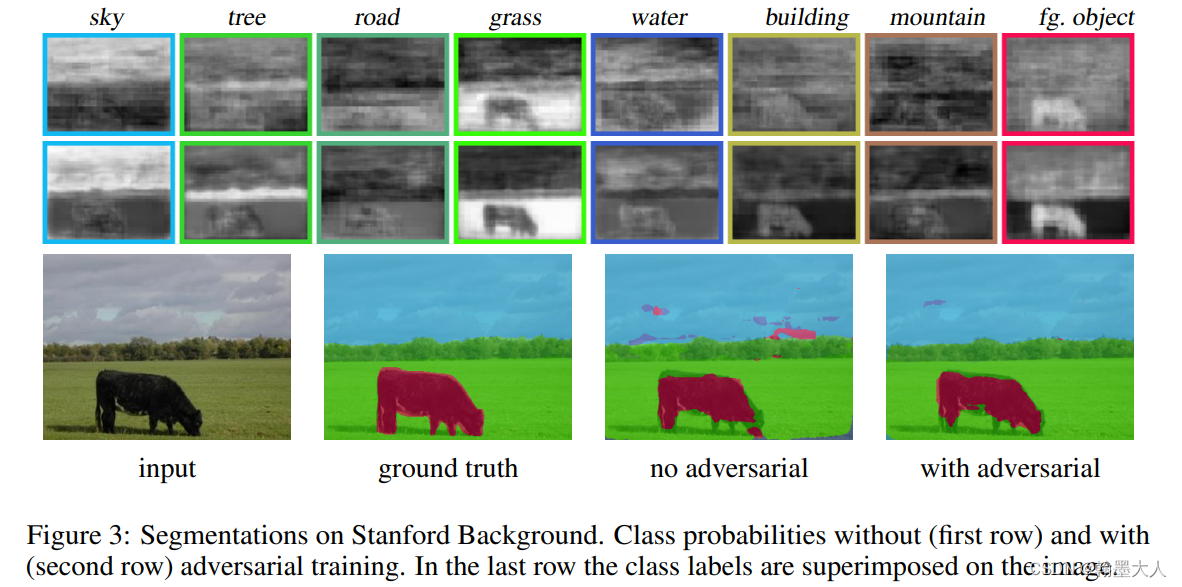
结果:
Semantic Segmentation using Adversarial Networks
猜你喜欢
转载自blog.csdn.net/qq_43733107/article/details/130555349
今日推荐
周排行