原文很容易理解,建议看官可以稍微瞄一眼~

废话不多说,下面正式开始主要谈谈这篇文章的重点和创新之处。
目标
文章还是延续之前DeepLab系列的风格框架,采用atrous convolution在保证卷积特征分辨率不变的基础上实现感受野的指数级扩大(语义分割任务的challenge之一)。本文的关注点在于:如何更好的解决multi-scale问题,即分割目标具有不同的大小(语义分割任务的challenge之二)。DeepLab V3 采用了多种atrous rate空洞率的atrous convolution级联和并联的方式有效的提取多尺度的语境信息,而且通过结合image-level的信息改进APSS对于全局语境信息的提取能力,进一步提高效果。精彩的Review —— 多尺度语境提取方法
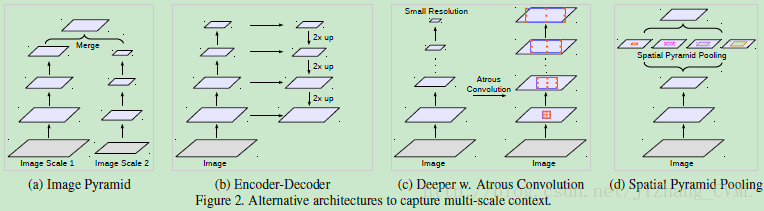
- 图像金字塔的构架 (DeepMedic、2-scale-RefineNet等)
首先对输入图像进行尺度变换得到不同分辨率的版本(multi-scale input),然后将所有尺度的图像都放入CNN中得到不同尺度的分割结果,最后将其不同分辨率的分割结果融合得到原始分辨率的分割结果。这类方法的缺陷在于计算量大,运算时间长。 - 编码器-解码器的构架 (FCN、SegNet、U-Net和RefineNet等)
编码器一般采用图像分类预训练得到的网络,采用不断的max pooling和strided convolution有利于获得长范围的语境信息从而得到更好的分类结果。然而在此过程中特征分辨率不断降低,图像细节信息丢失,对于分割任务而言具有巨大的挑战。因此在编码器之后需要利用解码器进行图像分辨率的恢复。值得注意的一点:一般解码器常常具有类似skip的结构将encoder得到的细节信息加入后续decoder的信息恢复中。 - 语境模块 (Multi-scale context aggregation、DeepLab V1,V2和CRF-RNN等)
语境模块一般是级联在模型后面,以获得长距离的语境信息。以DenseCRF级联在DeepLab之后理解,DenseCRF能够对于任意长距离内像素之间的关系进行建模,因此改善逐项素分类得到的分割结果。 - 金字塔池化方法(PSPNet等)
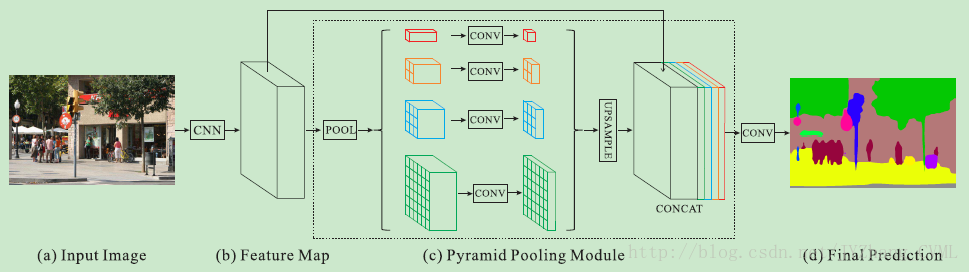
金字塔池化的方法作用在卷积特征上,能够以任意的尺度得到对应的语境信息。一般采用平行的多尺度空洞卷积(ASPP)或者多区域池化(PSPNet)得到对应尺度语境信息的特征,最后再将其融合形成综合多个尺度语境的特征向量。下图是PSPNet中金字塔池化模块的具体构架。
- 图像金字塔的构架 (DeepMedic、2-scale-RefineNet等)
创新思路
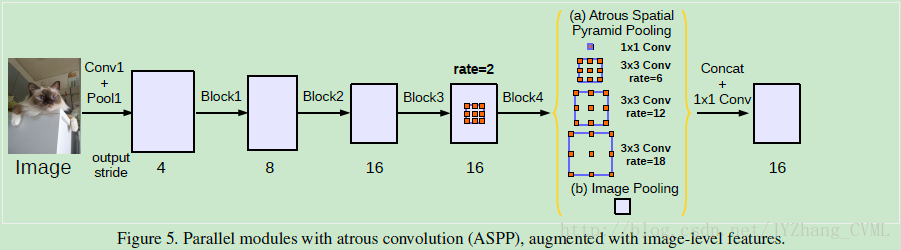
利用atrous convolution构建语义模块(级联方式Go Deeper)
重复多个ResNet的Block4模块,并以级联的方式,得到直到Block7的更深的网络~(为什么能够搭建更深的网络?空洞卷积的效果)。其中采用多网格的方法使得同一个block内的感受野能够迅速增大,这样能够迅速增进语境信息。加入image-level的ASPP(并联方式)
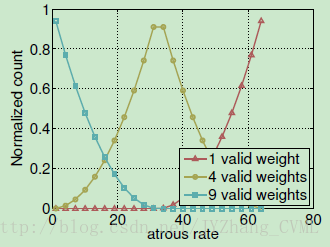
需要注意的是,即使ASPP内的空洞率很大,其实真正的感受野并没有理论上的感受野那么大,尤其对于很深的网络而言。因此,在ASPP中3*3的卷积核会退化成1*1的卷积核,因此我们需要更好的方式获得全局语境信息。
所以类似于PSPNet的网络构架,在之前ASPP的基础上添加通过global average pooling得到的image-level信息。同时在每一个平行空洞卷积后添加batchnorm构架,能够有效的捕获全局语境信息。
一句话概括
全文围绕如何更好的提取多尺度的语境信息~ 采用了级联的语境模块和并联的增广的ASPP模块。通过这样的方式,多尺度的语境信息能够更好的辅助分割算法,得到准确的物体描述。