文章来源
GAN在语义分割方面除了前面利用辨别器将真实GT和分割的predict进行优化,也可以用来进行数据增强。对于一些小数据集,可以通过扩充数据量来提高分割的性能。大致看了一下文章的结构,带着问题再细看文章内容。比较遗憾的是文章没有代码。
开头就说不平衡的标签分布影响了结果的精度,本文借助GAN来生成真实的图片用于语义分割。结果显示不仅对某些类别有及结果提升,整体的结果也有很大的提升。
真实图片的生成是一种image-to-image translation,目的是使用semantically labeled image生成photographic image。类似的方法有cycleGAN,pixel2pixel。(都没看过,下去看)数据增强可以划分为两种:1:传统的几何变换,就是普通语义分割任务中对图片进行旋转剪切,高斯模糊,随机缩放等。2:引导增强或特定任务方法,通过标签生成图片,可以叫做人工合成数据。
文章的贡献:
1:提出一个通过GANs生成互补数据的模型。
2:提出一种用于像素级别的图像增强方法。
3:在数据集上提升了效果。
方法描述:1:在原始图像-label对上训练一个GAN,用作将人工标注的标签转换为真实图片。2:使用生成的补充图片平衡标签分布。3:将生成的图片和原始的图片进行语义分割的训练。
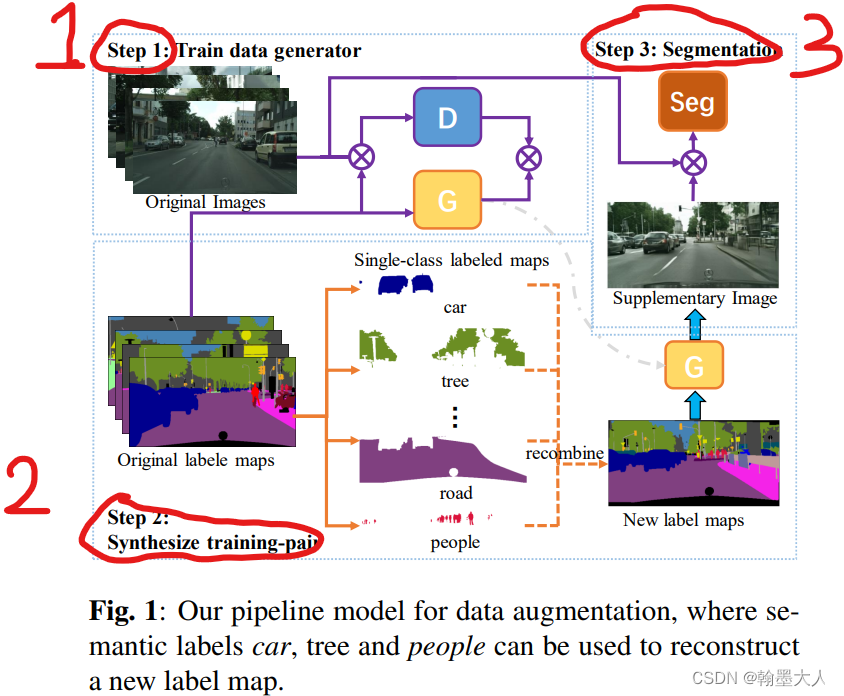
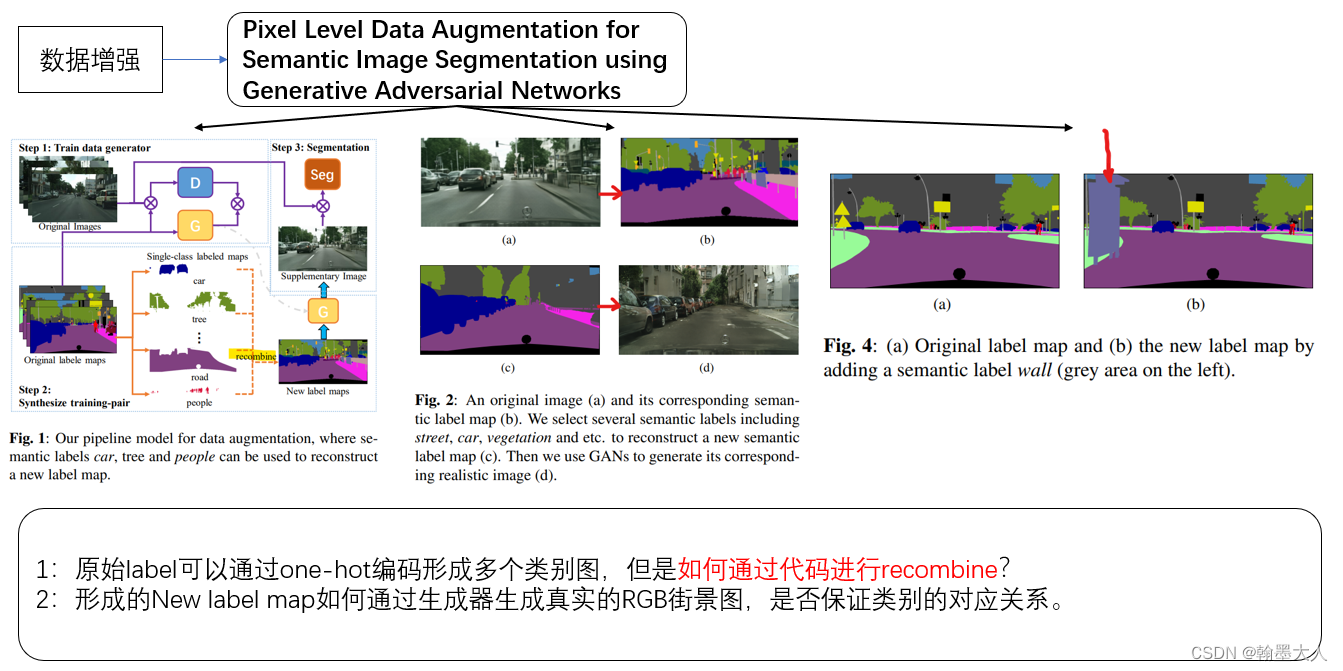
注:更详细的解释是首先使用原始的RGB标签输入到生成器,生成一个真实的图片,然后将原始的RGB和生成的图片共同输入到辨别器,直至辨别器无法辨别真实的图片和生成的图片。将真实GT的每个类进行随机recombine,输入到已经训练好的生成器,生成对应的图片,这样同时就有了合成的标签和生成的图片和原始的标签和原始的图片。最后共同输入到分割模型中。
1:训练数据生成器:
使用pix2pixHD作为生成器G,在给定标签的情况下生成真实的图片。真实图片和对应的标签成对进行训练,辨别器D用于分辨生成图片是来自于真实的图片还是生成器生成的图片。这个流程可以建模为:
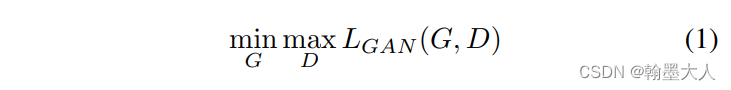
2:合成训练数据:
通过重建标签生成新的标签,然后通过训练好的生成器生成真实图片。首先根据类别将标签分开,数据集有N个标签K个类别,对于每一张图片,对应的标签为I1,I2,I3…In,我们可以从每一个标签图中提取m个semantic label,每一个I都有m个L,每个L代表一个类别即单标签图。
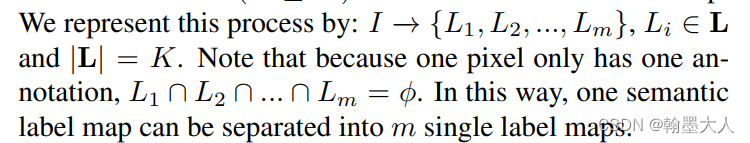
因为每个像素只有一个annotation,所以每一个类别都不相交。
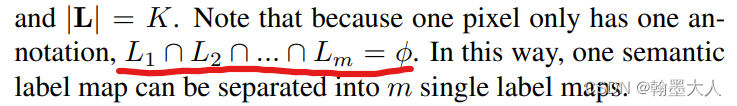
然后根据这些单标签图重建语义标签图。任意选择n个语义标签图,将它们重新组合形成新的标签。

作者设计了几个方法去reconstruct新的标签。下文讲。通过改变图片中每一个标签的位置,就可以改变语义标签分布。
3:使用增强的数据进行分割
首先使用补充的数据训练,这样可以得到更好的初始化,初始化中包含了一些很少出现类别的先验。接着使用原始的数据集微调网络。
实验研究:使用PSPNet作为分割模型,比较增强前和增强后的结果验证方法有效性。
1:分析语义标签分布
使用Cityscape的19类作为实验,计算标签的分布,对于每一个类别,统计它在训练集和验证集出现的频率。然后计算cityscape数据集top5算法的平均的分割精度。
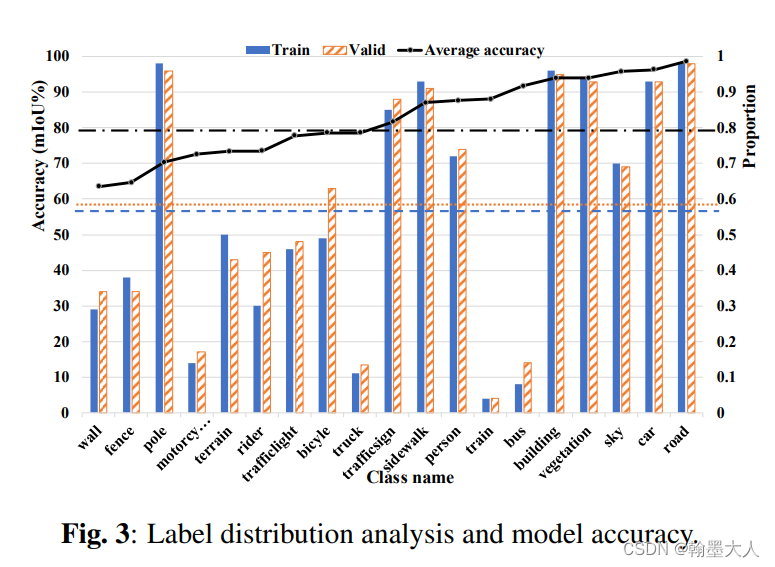
作者发现可以通过增加一些特定类别出现的频率来提高分割精度。
2:消融实验:
通过两个方法获得新的标签,(1):将一个单一的标签覆盖到原始的标签中(如果是一个新的标签则原来的标签就会多一个类别,如果放一个本来图中就有的标签,那标签总数不变,但是图片增加了复杂度)。(2):彻底重建标签来形成新的标签。补充的数据应该占总数据的多少才会达到最优解,作者做了一些实验。
2.1:给原始的标签增加一个新的类别,将那些分割结果比较差的类添加到原始标签中,这样原始标签就会增加一个类别。
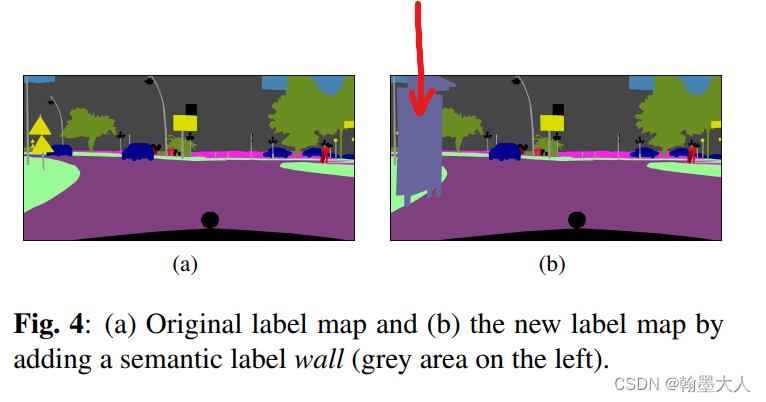
作者首先挑选出那个标签中没有wall的标签,接着随机挑选那个有wall的标签,然后将wall从挑选的标签中分离出来,然后覆盖到没有wall、的标签中。最后使用GAN将标签图转换为真实图片用于分割。
2.2:接着实验了添加多个类别到原始的标签图,挑选准确率低的类别添加到随机挑选的label中。结果如下所示:
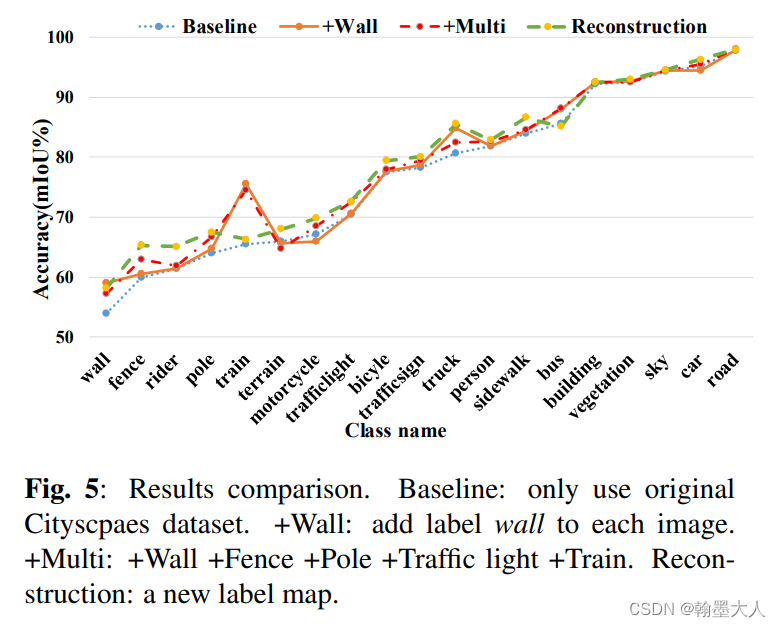

添加多个类别比只添加一个类别效果好一点,IOU提升的多,Miou略微提升。
2.3:重建
挑选多个来自标签的单class图,然后将它们结合在一起形成新的标签图。
首先画一个基础的label,包含最常见的,也是必须要有的,天空,路面,建筑,空白的地方像素为0,然后将单个lable重叠到基础的label上,就形成了一个新的label图。然后将新的label图送入到生成器中,形成对应的真实图。
分析:这个图本来是不存在的,里面的车,人,都是从别的图扣下来,然后放在基础label上的。大致看起来没有太大问题,但是细看的话就发现了端倪,右侧的车在人行道上,而人却在马路上走。不能说完全不可能,毕竟自动驾驶也是要判别行人不遵守交通规则,车辆乱放的情况,但是不敢保证这样随机放置会出现更加离谱的情况,会造成图片语义的混乱。
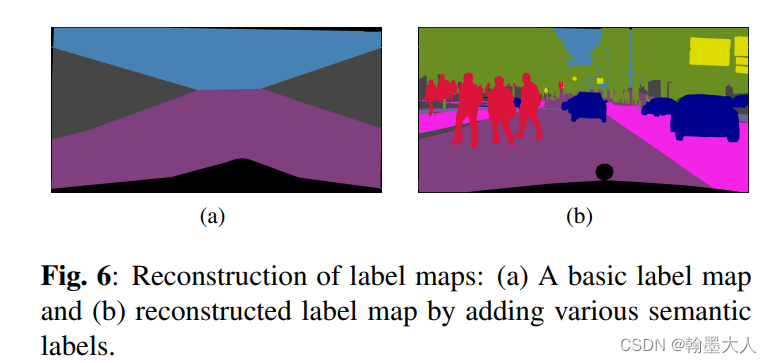
最后结果表明重建后的效果更好。那这样就没有多次用到准确率低的图了?
2.4:实验补充数据的比例:30%-70%更好。
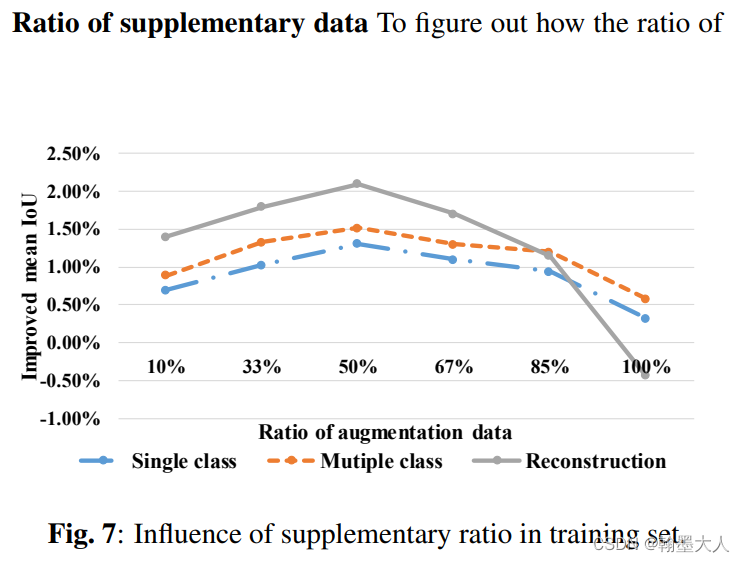
3:与其他的数据增强方式相比:集合增强,风格迁移。

结果:SOTA,是数据增强最好的方法。

待解决:reconstruct中的recombine是一个比较难的问题,该如何写代码。