发表年份:2022.1
发表单位:四川大学
期刊/会议:Geocarto International
论文链接:Crop_Classification_for_UAV_Visible_Imagery_Using_Deep_Semantic_Segmentation_Methods
目录
2.3 Classification Schema Devise
2.3.1 Sample Datasets and Preprocessing
2.3.2 Deep Semantic Segmentation
2.5.1 Comparison with Other Methods
2.6.1 The Effect of Using VDVI to Separate Non-vegetated Areas on the Results
2.6.2 The effect of Experimental Parameters on the Training Process
3. Experimental Results and Analysis
Abstract
无人机(UAV)已成为精准农业的主流数据采集平台。对于更易获取的无人机可见图像,高空间分辨率带来了丰富的几何纹理特征,触发了同一作物图像特征的巨大差异。我们提出了一种编码器-解码器的全卷积神经网络,结合可见带差植被指数(VDVI)对作物图像特征进行深度语义分割。该模型保证了精度和泛化能力,同时减少了参数和操作成本。在中国成都进行了一项作物分类的案例研究,其中对四种作物进行了分类,即玉米、水稻、苦瓜和红豆。结果表明,总准确率(OA)为93.18%。此外,本研究探索了一种基于可见光特征的精细作物分类方法,该方法可行且设备成本低,在基于无人机低空遥感的作物调查中具有应用前景。
1. Introduction
精确的作物分类是精确农业的共同要求,它对精确农业中的各种主题都有价值,包括农田提取、生长分析、作物产量估计和精确作物管理,因此,如何有效获取高度准确的作物分布信息已成为当今精准农业的重要因素(Atzberger 2013;Tatsumi等人2016;Kumar等人2017;G.Yang等人2020)。
长期以来,农田种植信息是通过综合统计或抽样调查等传统方法获得的,这些方法耗时、费力、主观,且存在时滞(王元元,2004年;明泉等人,2014年)。遥感技术具有分辨率高、覆盖范围广的优势,可以为相关部门提供更准确的农田分布信息(Liu等人,2019;梁J,郑Z W,夏S T,张X T和唐Y Y 2020;苏和张2020)。然而,使用目前可用的卫星传感器的主要限制是多云场景的风险和长的重访时间。低空和灵活的无人机是作物表型的一种负担得起的工具(Liebisch等人,2015年;M.Der Yang等人,2020年),它可以提供许多优势,如不受云影响;更灵活,因为您可以为不同的应用、更高的空间分辨率和实时监测选择特定传感器(Gevaert 2015;Gómez Candón等人,2016)。无人机携带的图像传感器对于根据需要选择合适的图像传感器至关重要。RGB摄像机是无人机在作物表型研究中最常用的配置。传感器具有成本低、重量轻、操作方便、数据处理简单、工作环境要求相对较低的优点(Stöcker等人,2017)。
无人机可见光图像的作物自动分类方法处于发展阶段,目前还没有广泛使用的成熟方法(Moser等人,2013年;Ozdarici Ok等人,2015)。原因是:首先,机载微传感器导致采集的图像数据波段较少,仅红-绿-蓝三个通道导致特征光谱信息采集不足(Zhao&Du 2016);第二,作物生长复杂,受各种自然和人为因素影响,与通过采集获得的高分辨率遥感图像相比,遥感图像中呈现的纹理特征和其他特征差异较大,同时,采集的图像显示了特征之间高度详细的图像信息,这减少了不同物种之间的差异并且增加了相同物种之间的图像特征的差异。“同一物种的不同图像”的现象很容易发生,导致基于单个图像元素光谱信息的传统分类方法不再适用(Kwak&Park 2019)。
为了充分利用高分辨率遥感数据中丰富的特征细节信息,提高分类精度,逐步应用面向对象分类方法(Li等人,2020)。面向对象的分割算法分为三个主要步骤:数据分割、特征选择和图像分类。数据分割算法包括阈值分割算法、用于边缘检测的分割算法(Rydberg&Borgefors 2001)、区域分割方法等。尽管不同分割方法中使用的处理具有不同的思想,但它们都需要专注于选择分割参数,这直接影响后续分类结果作为最终确定分割对象的数量、形状和大小的指标的准确性。分割参数的选择主要依赖于重复的比较实验(Chen等人,2014;李明,黄玉琪,李旭萌,彭东兴,2018)。虽然特征选择阶段基于图像中的底层特征(Blaschke 2010;Liang J,Zheng Z W,Xia S T,Zhang X T和Tang Y Y Y 2020),例如纹理、形状、空间和其他信息,但传统的浅层分类算法对简单特征具有良好的提取效果(Weizman&Goldberger 2009;Cheng et al.2017),由于计算单元有限,处理过程仅通过较少级别的线性或非线性变换组合(例如,一层),这在提取图像中的复杂特征方面效率较低(Li等人,2020)。
而深度学习卷积神经网络(CNN)(Hinton等人,2006年)因广泛用于图像分类而广受欢迎,并可提取图像的深度特征(Bhosle&Musande,2019;Chen等人,2019年;Liu&Chen,2019,Yang等人2019年)。Exception由Chollet(Chollet 2017)于2017年提出,用于图像分类的CNN模型,在收敛速度和精度方面优于ResNet(He 2015)和其他深度神经网络模型,最近变得更受欢迎。然而,在高空间分辨率图像中,特征元素表现出多尺度特征。单尺度分类在适用性方面有很大的局限性,因为小尺度往往会分割大面积部分,而大尺度往往会忽略小面积特征的特征。人类视觉系统遵循“目标-环境-背景”观察模式,从高分辨率图像中提取信息应该具有类似的特征。通常用于提取高分辨率可见光遥感图像中作物空间信息分布的卷积神经网络只能将小遥感图像分割成局部图像块进行单独处理。由于没有充分考虑不同作物田目标的多尺度特征以及它们所处场景的上下文信息,这种直接引入CNN网络进行作物提取或识别的方法无法获得最佳结果。然后,为了充分利用单尺度输入数据无法利用的上下文信息,需要对多尺度结构和语义信息进行实际挖掘(Han等人;Yang YD,Zhuang Y,Bi FK,Shi H 2017;Karim等人,2019)。用于深度语义信息挖掘的深度全卷积网络结构可以充分利用多尺度语义信息(Lu等人,2017;Huang等人,2018;M.Der Yang等人,2020)。基于深度学习的语义分割方法FCN(Shelhamer等人,2017)从抽象特征中恢复每个像素所属的类别。即,分类进一步从图像级扩展到像素级。FCN是一种基于图像语义分割的神经网络,它是CNN模型中由卷积层取代的完全连接层,使用卷积层提取特征并使用去卷积层解码功能图,这种变化允许模型输入任意大小的图像,并在输出端直接获取每个像素所属的类别,从而实现一对一的端到端训练。典型的全卷积神经网络是SegNet(Badrinarayanan等人,2017年)、DeepLab(Chen等人,2018年)、U-Net(Qian等人,2020年)和RefineNet(Lin等人,2020)。许多学者已成功将FCN应用于高空间分辨率遥感图像分类(Ammour等人,2017年;Kestur等人,2018年;Gebrehiwot等人,2019年;Yang等,2019;Fu等人,2020年)。此外,U-Net是一种轻量级FCN模型,但它同时考虑了图像全局和图像细节的信息,并融合了不同尺度的特征。早期,U-Net模型广泛应用于医学图像(Navab等人,2015年),近年来,其对遥感图像的分类结果也表现得更加出色(Zhang等人,2018年;Ji等人,2019年)。
在本研究中,我们提出了一种基于编码器-解码器的深度语义分割模型,以提高无人机可见图像分类的模型训练效率,还可以为特定作物种植面积计算、作物生长和水分监测以及农业自然灾害监测提供方法学参考。
2. Materials and Methods
2.1 Study Area
研究区域位于中国四川省成都市郫都区(东经103°42′~104°2′,北纬30°43′~30°52′)。它是成都平原的腹地,耕作条件优越,尤其是地表为岷江新冲积灰色水稻土细砂粒泥层,洪泛平原下为黄泥层或黄泥砂层,加上该地区农民种植水平较高(王斌、黄盛义、闵庆文2020)。该地区为玉米、水稻、苦瓜、红豆等作物提供了良好的种植环境。
研究区域主要作物的物候日历如图1所示。研究区域出现复杂物候。例如,水稻一般在4月上半月播种,8月收割,而玉米则在5月下旬至6月上旬播种,8至9月收割,生长周期短;苦瓜适合生活在温暖的气候中,耐热但不耐寒,通常在5月种植,8月夏季上市;红掌是一种经济作物,喜温暖和阳光,适合肥沃、潮湿、微酸性土壤,成活率高。它是一种有价值的观赏树种,用于美化公园、庭院、道路等。其繁殖方法通常为嫁接、扦插和播种。经田间研究,研究区内的红木兰采用插条繁殖,每年3月至9月的插条播种率高,约25天内发芽,每年生长20至30厘米。

2.2 UAV Image Acquisition
这些图像由无人机类型的DJI Phantom4 pro采集,配备1英寸、2000万像素CMOS传感器和机械快门,以防止快速移动过程中出现拖尾图像。还配备了位置和定向系统(POS),以实时获取数据传感器位置和姿态信息。采集的图像包括三个波段:红色、绿色和蓝色。
这种多旋翼无人机通常只有30分钟的有限续航时间,因此我们根据研究区域的实际情况和飞行要求将研究区域划分为22个调查区域,总面积为6000平方公里。航拍时间是2019年8月8日,当时天空晴朗,风轻。空中飞行的地面分辨率设置为8厘米,高度280米,返回高度280米。图像航向重叠率设置为80%,航班之间的重叠率为60%。飞行速度设定为每秒15米。DJI地面站Pro软件用于飞行控制。研究区域的正射影像图由Pix 4D制图软件制作,并由ArcGIS软件拼接。

2.3 Classification Schema Devise
本实验中用于对无人机高分辨率图像进行作物分类的深度学习技术主要由两部分组成(图3)。在模型训练阶段,将训练和验证数据集输入到提出的深度语义分割模型中,用于深度特征提取,然后使用Adam优化算法(Kingma&Ba 2015)优化梯度下降过程。验证集用于避免过拟合,并通过交叉熵函数选择最佳参数(Cheng et al.2018);经过训练过程,得到了最优模型。第二部分是利用深度语义分割模型进行作物分类的实验和精度验证阶段,将不同区域的测试数据集输入到训练好的优化模型中,直接获得输入图像的作物分类结果,并验证了分割结果与地面实际标注数据的准确性。
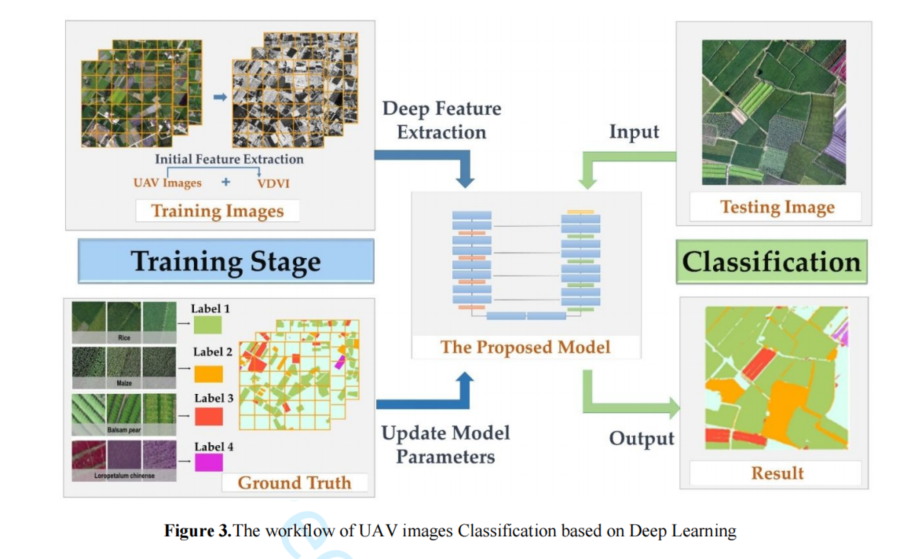
2.3.1 Sample Datasets and Preprocessing
研究区域的特征被分为五类:水稻、玉米、苦瓜、红景天和其他。深度学习分类方法需要大量标记块,从原始图像和增强图像中选择样本可以扩展样本集,提高模型训练的准确性。虽然在主要的人工智能平台中有各种用于图像分割的公共数据集,但语义分割在无人机图像分割中的应用并不多,大多数是单类元素提取数据集,如建筑物提取,而且多类分割数据集少,分类标准统一,难以满足实际应用的要求。构建数据集后,进行样本集中和标准化,使数据具有相同的单位尺度。
本实验从无人机遥感图像中选取作物样本,构建样本数据库。具体操作是选择100个2048*2048像素区域大小的样本,并标记每个类别的样本。我们将数据随机分为训练组(80%)、验证组(10%)和测试组(10%”)。通过交叉验证选择最佳分类参数。将所有地面实况数据从RGB图像转换为标签值为0、1、2、3和4的图像,分别对应于0玉米、1水稻、2苦瓜、3红花菜和4背景的五大类。
试验区的数据收集时间为8月初,这是各种作物生长发育的关键时期。在此期间,水稻成熟,玉米处于铃期,苦瓜处于瓜期,数据收集期间,由于物候历较短,红花广泛分布于研究区域的各个物候期。为了进行光合作用,为自己提供足够的养分,四种作物都已完成叶片发育,叶面积相对较大,具有典型的绿色植物特征。示例解释标志如图4所示。

农田地区高分辨率遥感图像特征类型多样,环境复杂,作物类型提取面临更多干扰因素。因此,首先从图像中去除非植被,然后在植被区域中提取作物类型。在可见光的波长谱中,绿色植被在绿光波段具有反射特性。相反,它在蓝光和红光波段具有吸收特性,蓝光波段的吸收略高于红光波段。因此,利用绿色植被的反射和吸收特性,通过构建可见光带植被指数来提取植被信息。
基于无人机高空间分辨率图像的这一特征,VDVI可以区分植被和非植被(Cholet 2017)。我们对VDVI波段组合执行8位的图像进行了归一化处理,并将4-3-2标准假彩色图像合成为第四波段图像。其计算公式如下:

其中R、G和B分别表示图像中的红色、绿色和蓝色条带。
2.3.2 Deep Semantic Segmentation
语义分割网络通常由编码结构和解码结构组成。建议模型的示意图如图5所示:

编码器:
解码部分将在编码格式中学习的特征从语义映射到像素空间,以获得每个像素的类别。在编码部分,其作用是使卷积层和池层通过图层,获取高分辨率地图下的特征信息。随着向下采样的进行,感知场逐渐扩大,这相当于图像被压缩,单位面积感知的面积变得更大。通常,最大池用于卷积或卷积时将步幅设置为2,从而保留其位置信息,并在执行上采样时恢复其位置信息。
图5显示,该网络结构的编码由8个块组成,网络的输入图像为256*256*4无人机高分辨率图像。首先,它经过一个3*3普通卷积并对其进行归一化,激活函数采用ReLU6;然后经过5个深度可分卷积。编码会话中的所有编码器使用2深度可分离卷积的步长,而不是向下采样。
在本实验的编码部分引入深度可分离卷积(Jing et al.2020),在普通卷积过程中,将同时考虑图像区域中与卷积核对应的所有信道,实现信道相关性和空间相关性的联合映射。本实验使用了一种深度可分离的卷积,它相当于将空间特征学习和信道特征学习分离,它将是普通的。卷积操作被分解为两个过程。图3-3显示了该实现。首先,使用分组卷积对每个信道分别进行卷积,每个信道的输入数据仅与相应的卷积块卷积。
如果输入图像的大小为![]() ,输出图像的大小是
,输出图像的大小是![]() ,并且取大小为K×K的卷积核,则信道分组卷积的计算为式(2)
,并且取大小为K×K的卷积核,则信道分组卷积的计算为式(2)
![]()
普通卷积的计算如式(3)所示
![]()
比较传统三维卷积和深度卷积的计算工作量,如方程(4)所示。

可以看出,深度可分离卷积参数的数目是标准卷积的数目的![]() 。与图6所示的标准卷积运算相比,深度运算可以大大减少参数的数量。
。与图6所示的标准卷积运算相比,深度运算可以大大减少参数的数量。

为了保证模型的泛化能力,我们在深度和点方向访问Batch归一化层,以便在深度神经网络的训练过程中,神经网络各层的输入保持相同的分布。这避免了“内部协变量移位”问题。在不特别注意梯度爆炸或消失等优化问题的情况下,使用更显著的学习率可以加快收敛,在一定程度上可以避免使用Dropout,这是一种降低收敛速度的方法,但对提高模型泛化起到了正则化作用;具体来说,批处理分为两个步骤:归一化和转换重构。归一化由以下方程式(5)、方程式(6)和方程式(7)给出:

其中,m是批量大小,![]() 是平均值,
是平均值,![]() 是有偏方差,
是有偏方差,![]() 是保持值稳定的常数集,
是保持值稳定的常数集,![]() 是规范化值。上述变换在一定程度上破坏了在网络层中学习到的特征分布,因此需要进行下一次重构操作。转换重建的方程(8)如下
是规范化值。上述变换在一定程度上破坏了在网络层中学习到的特征分布,因此需要进行下一次重构操作。转换重建的方程(8)如下
![]()
其中,![]() 是要学习的参数。
是要学习的参数。
ReLU是一个非线性激活函数,用于向神经元引入非线性因素,而ReLU6函数在计算深度可分离卷积时更为稳健(Sandler et al.2018),对于上诉表达式,ReLU6可以表示为方程(9):
![]()
Bottleneck用于将编码器和解码器停靠在移交位置。深度可分卷积后面1*1通道的逐点卷积起到了降维作用。同时,瓶颈在深度可分卷积之前又增加了一个逐点卷积,以发挥维数增加的作用,这一层的逐点卷收可以称为扩展卷积,扩展因子一般设置为6。“维数化深度卷积维数化”结构增强了梯度信息的传播,减少了推理。此外,还添加了线性瓶颈结构以直接线性化结果的输出,从而保留了特征的多样性并提高了网络的鲁棒性。
本实验中的瓶颈的中间层增加了2层深度可分离卷积,用2层更实用的深度可分离褶积增强了网络提取抽象特征的能力,提高了使用深度特征的效率,并通过略微增加参数数量和计算能力来提高网络精度。示意图如图7所示。

通常,在解码部分,通过反卷积进行上采样以恢复图像大小。在恢复下采样(双线性)数据时进行解码,特征尺度将发生变化,并且必然会丢失信息。因此,引入跳跃连接来实现特征融合,每个反卷积都以与特征提取中通道数相同的比例进行缝合和融合编码部分。这样就实现了不同尺度的特征融合。在这个实验中,我们使用了叠加操作(串联),也被称为复制。简而言之,跳跃连接起到了补充信息的作用,使模型能够依赖更多的信息,改善了上采样期间信息不足的问题,从而提高了分割精度。在网络结构的中间,深度可分离卷积层需要同时并行处理大量卷积运算,这会严重影响在CPU上运行时的网络速度。因此,用深度可分离卷积代替网络中的所有卷积运算是不可取的。因此,本实验在解码过程中使用普通卷积,解码器使用双线性插值代替反卷积对特征图进行上采样。与反卷积上采样方法相比,双线性插值方法可以有效地避免反卷积中可能出现的镶嵌效应带来的训练困难。
该研究的解码结构与编码结构不对称,这在一定程度上减少了网络参数的数量,加快了推理过程。首先,将编码网络的第三层特征图与瓶颈后的特征图连接起来作为解码网络的输入。经过两次卷积和一次上采样操作,它与第二特征层的信息相关联,然后经过两次褶积和一个双线性插值与第一层特征图相结合。通过使用1*1大小的卷积核,通道数减少到256*256*5,并以与输入图像相同的比例输出图像。另一方面,本文将滤波器的深度统一设置为64。这是因为实验中使用的数据集仅包含4个类别,特征组合的数量远小于CIFAR-100、Pascal VOC和其他数据集中样本的特征组合数量。如果参考原始U-Net中的过滤器深度,网络收敛不容易,分割精度低。具体而言,这基于三个考虑因素:
(1) 数据集中待识别的类别数量和特征数量都很小,网络池操作中丢失的信息可以通过“反卷积”和“跳跃连接”来检索。
(2) 在这个分类任务中,模型不需要理解和识别高级3D对象的概念。在较高的网络层中增加过滤器的数量不会影响模型的实际预测性能。参照经典版本的网络结构设置,实验的硬件设备,尤其是GPU,要求很高。设计统一数量的滤波器本质上是考虑减少时间和空间复杂度;
(3) 过滤器的统一数量使网络结构更清晰,更易于编码。
2.4 Algorithm Implementation
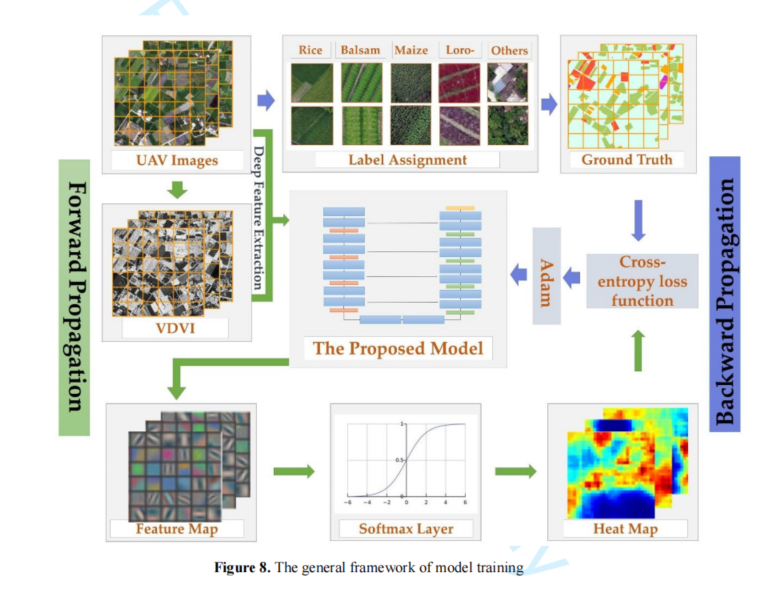
神经网络可以在相互连接的神经元之间传递信息,这样的系统可以用来建模复杂的函数。模型的训练主要分为前向传播和后向传播两个过程。相反,前向传播从输入图像开始,计算网络每层中每个神经元的输出值、特征映射的输出值,计算时会停止输出值,而模型训练的目的是寻求模型权重和这些参数的偏差的解,向后传播是寻找预测分类结果的关键,利用预测分类结果不断迭代调整参数,更新权重和偏差,最后通过不断迭代和更新获得参数的最优解,最终结束学习任务。图8显示了模型训练的流程图。该模型首先学习图像的特征地图,然后使用Softmax函数将特征地图映射为一个概率,即一个热图,然后得到提取的分类结果,称为转发传播。后向传播是根据样本库中的实际地面标签对前向传播中预测的分类结果进行比较,得到损失值,根据损失值的大小,使用Adam优化算法调整梯度下降步长,调整网络权重,直到损失值迭代到特定的阈值范围,模型训练结束。然后对模型的参数进行优化,模型的精度也达到了最高。通过不断调整参数,使预测分类结果与实际结果最佳匹配,从而完成训练过程。
在正向传播中,对于采样图像中的每个像素![]() ,是整个图像中的像素总数。如果整个图像被归类为C类,则其真实类别可以用方程(10)表示。它意味着真实类别的标签:
,是整个图像中的像素总数。如果整个图像被归类为C类,则其真实类别可以用方程(10)表示。它意味着真实类别的标签:
![]()
深度特征学习的样本输入模型,得到的特征图可以表示为等式(11)
![]()
当模型损失值最小,最小损失值是输出值![]() 与地面真值标签
与地面真值标签![]() 之间的差值最小时,模型训练寻找模型参数的过程。通常,对于图像多分类问题,Softmax函数通常用于将特征向量
之间的差值最小时,模型训练寻找模型参数的过程。通常,对于图像多分类问题,Softmax函数通常用于将特征向量![]() 中所有类别的线性预测值转换为概率值。C类像素i的预测概率计算公式(12)为:
中所有类别的线性预测值转换为概率值。C类像素i的预测概率计算公式(12)为:

Softmax作为一种分类能力较强的分类器,可以直接计算各种类别的概率值,并通过每个类别的概率值来区分类别的类型。它是目前深度学习分类中最常用的分类器。通过Softmax层获得概率值后,使用交叉熵损失函数获得地面真实数据与预测分类结果概率之间的损失值。如方程(12)所示,损失值被量化,以表明预测分类结果与实际数据之间的差距大小。如果两者之间的损失值较小,则分类精度较高;如果损失值较高,则分类准确性较低。
地面真实数据概率和预测分类结果概率之间的损失值由Softmax层使用交叉熵损失函数获得(Cheng et al.2018),如方程(13)所示,它通过量化预测分类结果与真实数据之间的损失值,来表示预测分类结果和真实数据之间差异的大小。如果两者之间的损失值越小,分类精度越高,如果损失值越高,分类精度就越低。否则,情况就相反了。

在反向传播中,需要不断调整网络参数,以确保损失值达到一定阈值。本实验使用Adam优化算法调整网络参数来训练模型。Adam算法是一种优化梯度下降的算法。在传播过程中,通过梯度下降更新网络的权值。Adam的算法是找到损失值最小的点的值。Adam算法具有较高的计算效率和较低的内存需求,并且相对容易实现。它是目前广泛应用于深度学习的优化算法。更新Adam算法参数的方法方程式(14)、方程式(15)、方程式〔16〕、方程式(17)和方程式(18)如所示:

![]() 是要更新的参数,
是要更新的参数,![]() 是学习速率;
是学习速率;![]() 是随机目标函数的梯度;
是随机目标函数的梯度;![]() 是部分一阶矩估计,
是部分一阶矩估计,![]() 是部分二阶矩估计;
是部分二阶矩估计;![]() ;
;![]() 和
和![]() 是矩估计的指数衰减率;
是矩估计的指数衰减率;![]() 是小正数。
是小正数。
2.5 Performance Assessment
2.5.1 Comparison with Other Methods
为了验证本实验的训练结果,将测试数据集的图像输入到先前训练的模型中,以获得分类结果图。SVM算法、Xception和标准U-Net使用实验中的相同样本数据进行分类。SVM选择径向基函数作为核函数,并使用基于交叉验证的网格搜索方法确定惩罚因子 C 和核函数参数![]() 。此外,标准U-Net Xception由超参数设置和我们提出的模型的输入和输出组成。
。此外,标准U-Net Xception由超参数设置和我们提出的模型的输入和输出组成。
2.5.2 Accuracy Evaluation
为了验证模型的泛化能力,我们将测试集输入到模型中。由于该模型的输入和输出都是256×256像素的图像,因此使用了滑动窗口方法。256×256(像素)图像从上到下和从左到右输入到训练模型中。由于本研究中使用的无人机遥感图像分辨率较高,其模型输出的256*256像素区域大小的分类结果对应较小的特征分类区域,无法更好地进行分类可视化其分类效果,将256×256区域大小的输出结果缝合为2048×2048区域大小结果。
为了准确定量地验证模型在测试集中的准确性,使用混淆矩阵和总体分类精度来评估分类结果。Confusion Matrix是一个矩阵,它通过在特定矩阵中可视化结果来表示算法的性能。混淆矩阵的关键是使用数值总结正确和错误预测的数量,并按类进行细分。混淆矩阵显示在进行预测时,分类模型的哪一部分被混淆。它不仅可以洞察分类模型所犯的错误。但更重要的是,发生了哪些类型的错误。混淆矩阵图如图9所示。

TP(真阳性):将是模型预测的阳性类别预测。如果真值为0,则预测也为0,这意味着模型预测数或概率是正确的。和FN(假负):模型将原始的正类预测为负类的数量,真应为0,而模型预测为1,指的是模型预测的错误数量或概率;FP(假阳性):错误的负类预测为正确的类数,真为1,而模型预测误差为0;TN(真阴性):错误的阴性类别的数量被预测为错误的类别,真值为1,预测值也为1。
总体精度是所有测试集上正确预测数与模型总数的比值,反映了训练后模型的分类精度,对模型的泛化能力有一定的评价作用。其计算方法如方程式(19)所示。
![]()
2.5.3 The Experimental Setup
实验环境是一个运行PyTorch作物分类和鉴定深度学习框架的windows 10操作系统。PyTorch作为一种深度学习框架,是当今最流行的深度学习框架之一,具有包装简单、操作快速、对各种环境支持良好等特点(Mazza和Pagani,2021)。实验环境的主要配置如表1所示:

2.6 Sensitive Analysis
2.6.1 The Effect of Using VDVI to Separate Non-vegetated Areas on the Results
在本实验中,在输入端加入VDVI波段组合,使其加入先验信息,去除非植被区域,以避免网络训练振荡的发生,提高模型的精度。为了验证上述说法,我们在引入VDVI和不引入VDVI之间进行了比较实验,使用更大的初始学习率0.01,批量选择为64,其余条件相同。图10显示了其训练过程。

加入VDVI频段组合后,训练曲线更平滑,在训练集和验证集中其损失值更低。这表明目标增强增强了目标分割的先验知识,并训练了一个更适合作物识别的模型,以获得图像中关于地块边界和作物类型识别的准确信息。
2.6.2 The effect of Experimental Parameters on the Training Process
学习速率是在逆梯度方向上调整的模型训练权重的步长。一般来说,初始学习率越小,模型训练效果越好,但同时学习率降低,训练速度会极慢,导致局部最优现象。如果初始学习率增加,学习率将过大,导致训练曲线无法收敛,或直接跳过模型训练的最佳点,导致性能不佳。本实验使用Adam优化器自适应调整梯度,有效地平衡了学习速率产生的效果。将三个初始学习率分别设置为0.01、0.001和0.0001,进行比较,所有的初始学习率都有200个训练周期,批次大小为64。它们的准确度变化如图11所示:

作物分类模型的收敛速度主要受学习速率的影响。在对典型作物样本进行训练识别时,小学习率(0.001,0.001)获得的收敛性低于大学习率(0.1),收敛后的识别精度仍低于大学习速率。这是因为,虽然小的学习率可以避免在训练的初始阶段出现振荡,但由于步长太小,因此会陷入局部最优。只要避免网络训练振荡,使用较大的学习速率可以避免陷入局部最优,同时快速收敛。
批量大小的选择对模型的收敛速度影响不大。但会对网络模型的稳定性产生影响。在本实验中,由于样本数据是大作物的高清航空图像,因此考虑到计算机内存的影响,选择了6、32和64三个批次大小进行训练。本文中,当批量选择为6时,网络模型即使平差后仍有较大的局部波动,而批量为64的网络模型平差后分类精度波动较小,其精度变化如图12所示

3. Experimental Results and Analysis
超参数是决定神经网络模型结构的变量(例如,隐藏单元数、神经元大小),用于训练神经网络的方法(例如,学习速率、批量大小、历元大小)。调整超参数后,模型训练收敛并停止训练,并且在测试集中也显示出更好的结果,此时模型显示出最优解的分类结果。在本实验中,迭代次数设置为200。为了提高模型的泛化能力,在每个历元之前随机中断训练数据,使其与自然条件下的样本分布更加一致。此外,如果损失值在10个时期后没有改善,则停止学习。经过培训,我们发现学习率为0.01,批次大小设置为64,导致提出的模型的最佳性能。此外,在模型培训中,Xception模型和标准U-Net模型的学习率均为0.001,批次大小均设置为64。这些参数的设置水平如图13和表2所示,模型的损失函数曲线所示:


该模型在训练数据集和验证数据集中的损失值低于标准U-Net模型和Xception,这也证明了训练图像和地面真相标签之间的差异。值越小,分类精度越高。
如图14所示:
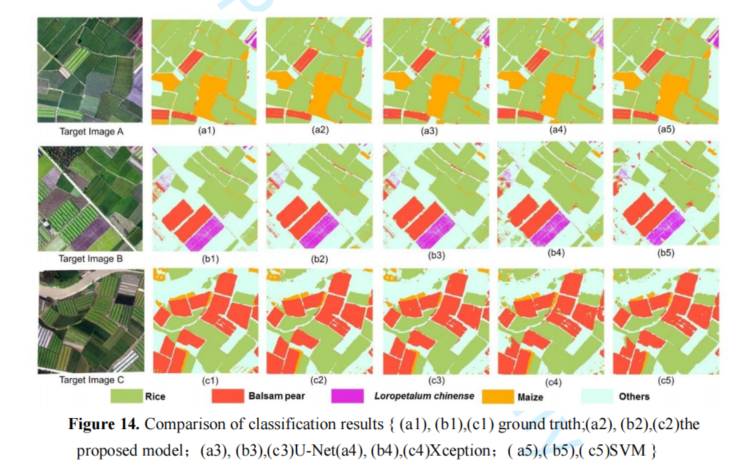
传统的分类算法存在模糊边缘识别和漏分现象。相比之下,使用本文算法的识别效果显著提高,尤其是因为识别结果边界相对清晰。这表明,目标增强增强了目标分割的先验知识,并训练了一个更适合田间作物识别的模型,能够准确地获得图像中的地块边界和作物类型识别信息。
四种模型的混淆矩阵如图15所示:


根据混淆矩阵中反应的正确分类像素数计算总体分类精度,可以得到各种模型的总体分类精度如表3所示。

SVM分类最差,原因是SVM通过核函数方法进行非线性分类,在处理小样本时效果更好,在处理遥感图像等大规模数据时效果稍差。对于类间差异较小的非线性问题,核函数的选择更加困难。虽然三种深度学习模型的分类精度更好,其中本文提出的方法的精度最高,其次是标准U-Net模型,而Xception由于使用图像块分类,在精度方面不如语义分割模型。
基于从混淆矩阵导出的四种作物的正确分类率,我们分析了每种分类方法对四种作物分类精度的性能,如图16所示:

(1) 玉米在所有四种分类模型中都没有显示出高精度,并且很容易被误分类为其他物种,如水稻。这可能是因为研究区域内玉米种植面积分布零散,通常作为农田分类出现在水稻种植场边界。
(2) 在这四种模型中,大米和苦瓜的分类效果较好,其分类准确率达到90%以上,但准确率没有明显提高。这可能是因为水稻和苦瓜的种植面积非常集中,采集的样本较多,易于区分。
(3)基于深度学习的三种模型对紫荆属作物分类精度的提高也更为明显:73%-83%-90%,可能是因为在传统的分类方法中,紫荆类作物由于生长周期短,很容易被误分类为其他物种,在特定时期采集的无人机图像中,它们表现出多个生长周期图像特征,给分类带来了一定的困难。Xception将深层信息提取为卷积神经网络,U-Net模型将深层信息与由于其结构优越,信息较浅,因此对于生长周期短和图像上呈现多种天气特征的紫荆等作物,分类精度得到了提高。
本文提出的模型的四种作物以及总体分类精度均高于其余三种模型,表明采用了深度学习神经网络。在深度学习中,基于卷积神经网络的Xception网络的分类精度低于基于语义分割的U-Net网络,表明对于高分辨率无人机图像,编码和解码的结构、,它将下采样获得的低分辨率图像特征与上采样获得的高分辨率图像特征相结合,更适合于高分辨率无人机图像进行作物分类
4. Discussion
本研究利用深度语义分割方法构建了作物分类模型,证明了所提出的模型能够准确地对作物进行分类。在建立模型的过程中,我们发现使用大批量(64)的大学习率(0.01)具有更高的准确性(93.18%)。与Zhao等人(M.Der Yang等人,2020年)最近提出的另一个实验相比,这些结果似乎也具有竞争力,该实验使用深度学习和水稻倒伏植被指数进行语义分割。然而,直接比较可能很困难,因为他们对一种作物进行分类,所以他们可以选择对水稻进行分类的最佳时间,而本研究中每种作物的生长期不同,所以对每种作物进行归类的最佳时间也不同。我们一起考虑了四种作物,并选择了最佳分类时间。同时,利用有限的无人机可见图像的RGB通道构建VDVI植被指数,并输入模型参与训练,也是对结果的改进。当考虑到输入仅由RGB通道组成时,这一点尤其有希望,模型的输入是通用图像特征,并且完全基于常规RGB图像,能够适应其他卫星、无人飞行器(UAV)或机载传感器。目前,它已经推出了一种能够实时计算NDVI植被指数的无人机,因此,本研究可以为制作用于作物分类的无人机提供一些思路。然而,每种作物的生长期各不相同,因此分类的最佳时间因作物而异。多时相可见光图像和作物天气特征可以进一步提高分类精度。
目前,无人机和传感器技术已日趋成熟,单架垂直起降固定翼无人机占地150平方公里,携带一台成本低、受天气影响小的数码相机,以较小的空间和简单的处理方式获取数字照片数据,使快速、及时地从大型农田收集信息成为可能。此外,随着卫星传感器技术的发展,具有高空间分辨率的低成本商用遥感卫星逐渐成为核心数据支持,并可以通过星座网络获得更短的重入周期,为更广泛的农业领域的遥感监测提供数据支持。同时,本文提出的方法可以快速完成气象条件好、作物种植类型相对固定地区的作物种植信息调查,也可以为特定作物提供方法学参考种植面积计算、作物生长和水分监测以及农业自然灾害监测。
5. Conclusions
目前,利用无人机遥感技术提取田间作物信息已成为一种主流方式。针对无人机可见光图像,提出了一种精确提取作物面积的方法。从结果对比测试可以看出,我们提出的方法的准确率为93.18%,高于现有的U-Net模型(92.46%)、Xception模型(91.77%)和传统的机器学习方法SVM(88.85%)。我们模型成功的关键在于其模型结构能够适应无人机高分辨率图像中作物区域的特征。本研究的主要贡献如下:(1)针对无人机高分辨率图像的特点,选择深度语义分割网络提取作物空间分布信息;(2) 同时,考虑到农田地区高分辨率遥感图像特征类型多样、环境复杂,作物类型提取面临更多干扰因素。为此,利用VDVI波段组合信息将非植被从图像中剥离出来,作为学习的第四波段信息输入到模型中,以减少非植被对其分类结果的影响;在编码部分引入深度可分离卷积,然后是批归一化层,以避免“内部协变移位”,然后使用1*1卷积进行信道间信息融合。在解码部分,用双线性插值上采样方法代替了标准上采样上采样方法。这种优化可以减少卷积参数的数量,进一步提高模型精度。在编码器和解码器的交叉点使用瓶颈对接,提高了网络的鲁棒性,提高了网的精度;(3) 在无人机遥感图像作物分类深度语义分割模型的训练过程中,较大的学习速率和大批量的参数更适合。然而,面对许多优点,我们也有缺点,例如需要更多标签。未来的研究应测试半监督分类的使用,以减少对样本标签的依赖。