代码来源
首先看一下模型架构:
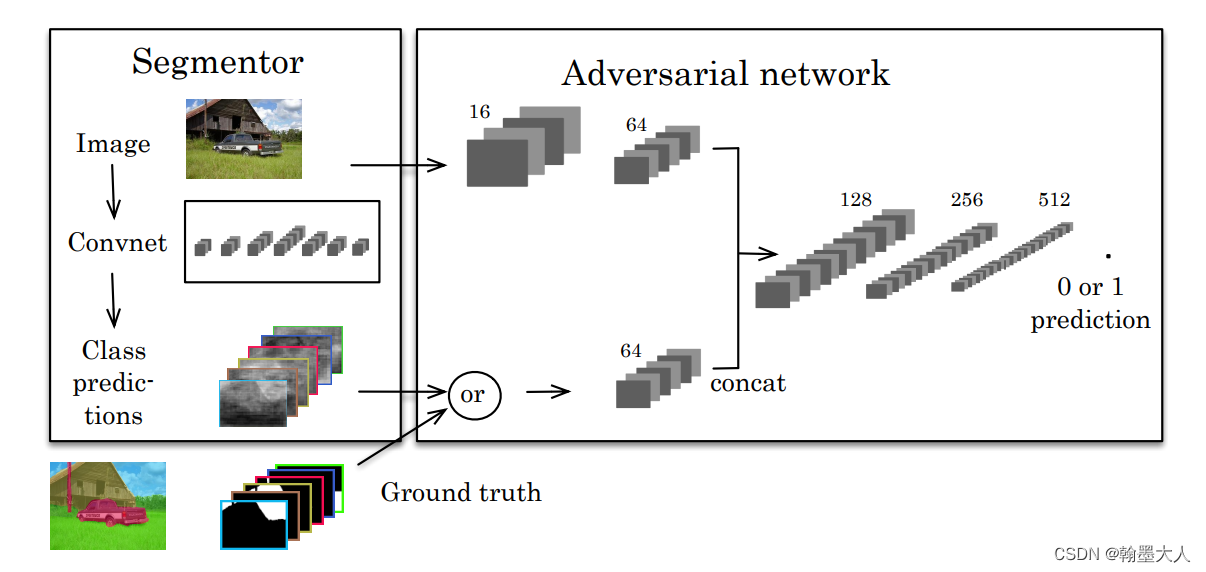
损失计算:


class GANUpdater(chainer.training.StandardUpdater, UpdaterMixin):
def __init__(self, *args, **kwargs):
self.model = kwargs.pop('model') # set for exeptions.Evaluator
self.gen, self.dis = self.model['gen'], self.model['dis']
self.L_bce_weight = kwargs.pop('L_bce_weight')
self.n_class = kwargs.pop('n_class')
self.xp = chainer.cuda.cupy if kwargs['device'] >= 0 else np
kwargs = self._standard_updater_kwargs(**kwargs)
super(GANUpdater, self).__init__(*args, **kwargs)
def _get_loss_dis(self):
batchsize = self.y_fake.data.shape[0]
loss = F.softmax_cross_entropy(self.y_real, Variable(self.xp.ones(batchsize, dtype=self.xp.int32), volatile=not self.gen.train))
loss += F.softmax_cross_entropy(self.y_fake, Variable(self.xp.zeros(batchsize, dtype=self.xp.int32), volatile=not self.gen.train))
chainer.report({
'loss': loss}, self.dis)
return loss
def _get_loss_gen(self):
batchsize = self.y_fake.data.shape[0]
L_mce = F.softmax_cross_entropy(self.pred_label_map, self.ground_truth, normalize=False)
L_bce = F.softmax_cross_entropy(self.y_fake, Variable(self.xp.ones(batchsize, dtype=self.xp.int32), volatile=not self.gen.train))
loss = L_mce + self.L_bce_weight * L_bce
# log report
label_true = chainer.cuda.to_cpu(self.ground_truth.data)
label_pred = chainer.cuda.to_cpu(self.pred_label_map.data).argmax(axis=1)
logs = []
for i in six.moves.range(batchsize):
acc, acc_cls, iu, fwavacc = utils.label_accuracy_score(
label_true[i], label_pred[i], self.n_class)
logs.append((acc, acc_cls, iu, fwavacc))
log = np.array(logs).mean(axis=0)
values = {
'loss': loss,
'accuracy': log[0],
'accuracy_cls': log[1],
'iu': log[2],
'fwavacc': log[3],
}
chainer.report(values, self.gen)
return loss
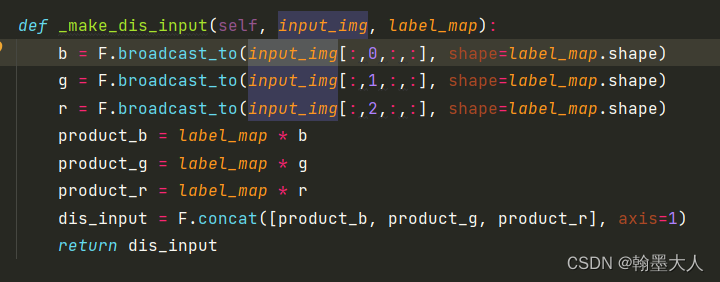
def _make_dis_input(self, input_img, label_map):
b = F.broadcast_to(input_img[:,0,:,:], shape=label_map.shape)
g = F.broadcast_to(input_img[:,1,:,:], shape=label_map.shape)
r = F.broadcast_to(input_img[:,2,:,:], shape=label_map.shape)
product_b = label_map * b
product_g = label_map * g
product_r = label_map * r
dis_input = F.concat([product_b, product_g, product_r], axis=1)
return dis_input
def _onehot_encode(self, label_map):
for i, c in enumerate(six.moves.range(self.n_class)):
mask = label_map==c
mask = mask.reshape(1,mask.shape[0],mask.shape[1])
if i==0:
onehot = mask
else:
onehot = np.concatenate([onehot, mask])
return onehot.astype(self.xp.float32)
def forward(self, batch):
label_onehot_batch = [self._onehot_encode(pair[1]) for pair in batch]
input_img, ground_truth = self.converter(batch, self.device)
ground_truth_onehot = self.converter(label_onehot_batch, self.device)
input_img = Variable(input_img, volatile=not self.gen.train)
ground_truth = Variable(ground_truth, volatile=not self.gen.train)
ground_truth_onehot = Variable(ground_truth_onehot, volatile=not self.gen.train)
x_real = self._make_dis_input(input_img, ground_truth_onehot)
y_real = self.dis(x_real)
pred_label_map = self.gen(input_img)
x_fake = self._make_dis_input(input_img, F.softmax(pred_label_map))
y_fake = self.dis(x_fake)
self.y_fake = y_fake
self.y_real = y_real
self.pred_label_map = pred_label_map
self.ground_truth = ground_truth
def calc_loss(self):
self.loss_dis = self._get_loss_dis()
self.loss_gen = self._get_loss_gen()
def backprop(self):
self.dis.cleargrads()
self.gen.cleargrads()
self.loss_dis.backward()
self.loss_gen.backward()
self.get_optimizer('dis').update()
self.get_optimizer('gen').update()
def update_core(self):
batch = self.get_iterator('main').next()
self.forward(batch)
self.calc_loss()
self.backprop()
首先看生成器的损失:由两项组成,第一项计算分割的label_map和GT之间的损失,第二项计算进过生成器的输出和1之间的损失。
def _get_loss_gen(self):
batchsize = self.y_fake.data.shape[0]
L_mce = F.softmax_cross_entropy(self.pred_label_map, self.ground_truth, normalize=False)
L_bce = F.softmax_cross_entropy(self.y_fake, Variable(self.xp.ones(batchsize, dtype=self.xp.int32), volatile=not self.gen.train))
loss = L_mce + self.L_bce_weight * L_bce
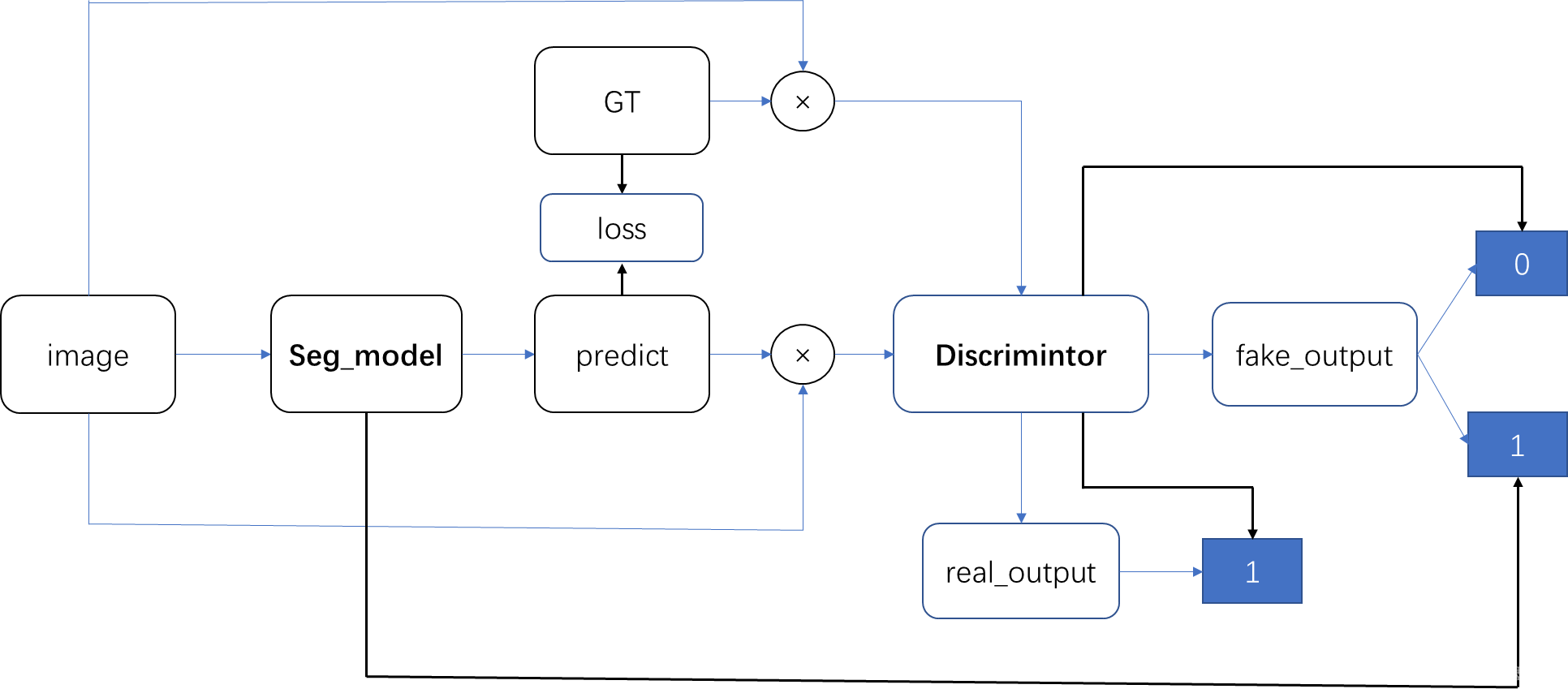
生成器的输入为x_fake。是输入图片和经过softmax之后predict_label进行concat之后的结果。如果是原始的GAN就是predict_label直接输入到辨别器中。x_fake输入到辨别器产生的为y_fake。
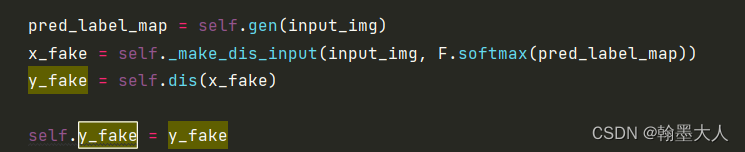
辨别器的损失:y_real即GT和原始的RGB图concat之后输入到辨别器的结果。那么希望分辨器能够分辨出来,所以与0进行损失计算。
这里的concat并非RGB和GT直接Concat,而是RGB广播到label大小后与label逐通道相乘再concat。
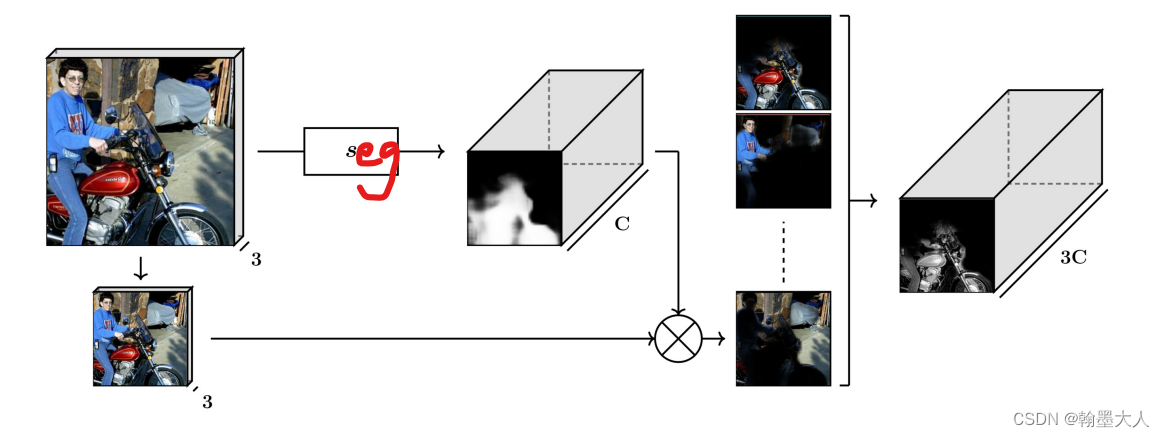
经过分割模型后生成的GT进行one-hot编码,即numclass个通道,每个通道由0,1组成。每个通道即为RGB中的每个类别,用1组成其余的由0组成。那么与原始的RGB相乘后,选择出RGB中对应的类别。
y_fake同上所述,我们希望分辨器能够辨别出来他是分割的结果而非原始的GT,因此与0计算损失。

与传统的GAN不同的地方是:segmentation的输出并非直接输入到adversarial model中,而是真实的GT和原始的RGB相乘,通道由C变为3C。
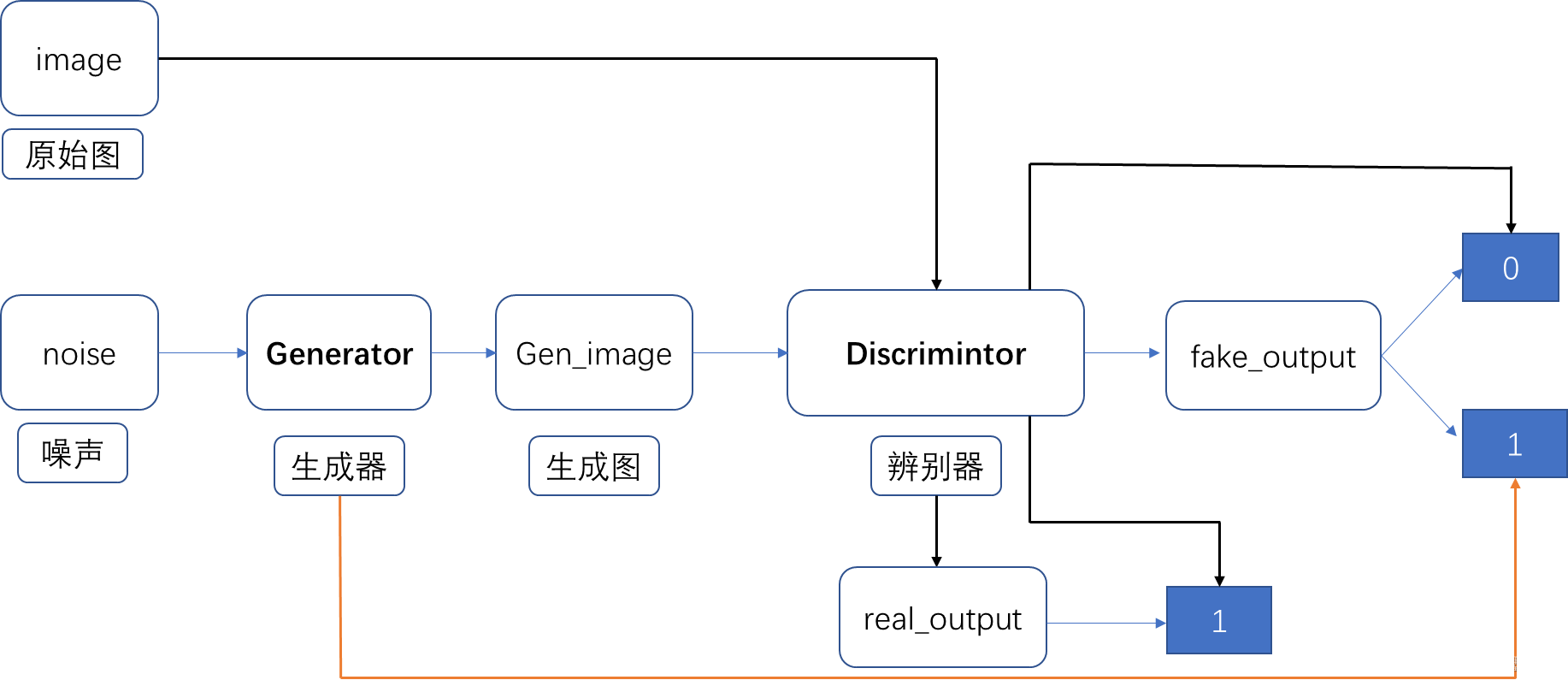
为了防止混淆画一下流程图:原始GAN。
本文:
接着是生成器和辨别器的组成:和DCGAN区别的地方是生成器输入不再是噪声,而是图片。和DCGAN类似的地方是用卷积进行下采样和上采样。
生成器:
import os,sys
import chainer
import chainer.functions as F
import chainer.links as L
import numpy as np
sys.path.append(os.path.split(os.path.split(os.getcwd())[0])[0])
import functions as f
class FCN32s(chainer.Chain):
"""Fully Convolutional Network 32s"""
def __init__(self, n_class=21):
self.train=True
super(FCN32s, self).__init__(
conv1_1=L.Convolution2D(3, 64, 3, stride=1, pad=100),
conv1_2=L.Convolution2D(64, 64, 3, stride=1, pad=1),
conv2_1=L.Convolution2D(64, 128, 3, stride=1, pad=1),
conv2_2=L.Convolution2D(128, 128, 3, stride=1, pad=1),
conv3_1=L.Convolution2D(128, 256, 3, stride=1, pad=1),
conv3_2=L.Convolution2D(256, 256, 3, stride=1, pad=1),
conv3_3=L.Convolution2D(256, 256, 3, stride=1, pad=1),
conv4_1=L.Convolution2D(256, 512, 3, stride=1, pad=1),
conv4_2=L.Convolution2D(512, 512, 3, stride=1, pad=1),
conv4_3=L.Convolution2D(512, 512, 3, stride=1, pad=1),
conv5_1=L.Convolution2D(512, 512, 3, stride=1, pad=1),
conv5_2=L.Convolution2D(512, 512, 3, stride=1, pad=1),
conv5_3=L.Convolution2D(512, 512, 3, stride=1, pad=1),
fc6 =L.Convolution2D(512, 4096, 7, stride=1, pad=0),
fc7 =L.Convolution2D(4096, 4096, 1, stride=1, pad=0),
score_fr=L.Convolution2D(4096, n_class, 1, stride=1, pad=0,nobias=True, initialW=np.zeros((n_class, 4096, 1, 1))),
upscore=L.Deconvolution2D(n_class, n_class, 64, stride=32, pad=0,nobias=True, initialW=f.bilinear_interpolation_kernel(n_class, n_class, ksize=64)),)
def __call__(self, x):
h = F.relu(self.conv1_1(x))
h = F.relu(self.conv1_2(h))
h = F.max_pooling_2d(h, 2, stride=2, pad=0)
h = F.relu(self.conv2_1(h))
h = F.relu(self.conv2_2(h))
h = F.max_pooling_2d(h, 2, stride=2, pad=0)
h = F.relu(self.conv3_1(h))
h = F.relu(self.conv3_2(h))
h = F.relu(self.conv3_3(h))
h = F.max_pooling_2d(h, 2, stride=2, pad=0)
h = F.relu(self.conv4_1(h))
h = F.relu(self.conv4_2(h))
h = F.relu(self.conv4_3(h))
h = F.max_pooling_2d(h, 2, stride=2, pad=0)
h = F.relu(self.conv5_1(h))
h = F.relu(self.conv5_2(h))
h = F.relu(self.conv5_3(h))
h = F.max_pooling_2d(h, 2, stride=2, pad=0)
h = F.relu(self.fc6(h))
h = F.dropout(h, ratio=.5, train=self.train)
h = F.relu(self.fc7(h))
h = F.dropout(h, ratio=.5, train=self.train)
score_fr = self.score_fr(h)
upscore = self.upscore(score_fr)
score = f.crop_to_target(upscore, target=x)
return score
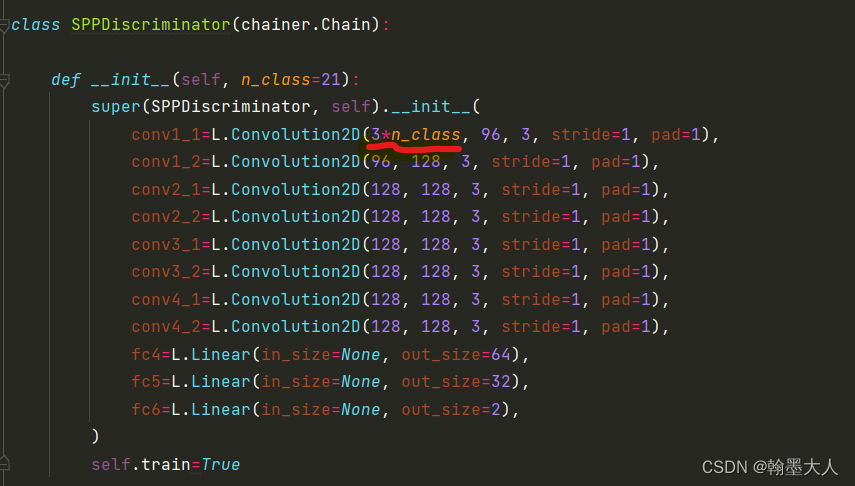
辨别器:四种变形,主要的区别就是卷积的通道不一致。
import os, sys
import chainer
import chainer.functions as F
import chainer.links as L
sys.path.append(os.path.split(os.path.split(os.getcwd())[0])[0])
import functions as f
class LargeFOV(chainer.Chain):
def __init__(self, n_class=21):
super(LargeFOV, self).__init__(
conv1_1=L.Convolution2D(3*n_class, 96, 3, stride=1, pad=1),
conv1_2=L.Convolution2D(96, 128, 3, stride=1, pad=1),
conv1_3=L.Convolution2D(128, 128, 3, stride=1, pad=1),
conv2_1=L.Convolution2D(128, 256, 3, stride=1, pad=1),
conv2_2=L.Convolution2D(256, 256, 3, stride=1, pad=1),
conv3_1=L.Convolution2D(256, 512, 3, stride=1, pad=1),
conv3_2=L.Convolution2D(512, 2, 3, stride=1, pad=1),
)
def __call__(self, x):
h = F.relu(self.conv1_1(x))
h = F.relu(self.conv1_2(h))
h = F.relu(self.conv1_3(h))
h = F.max_pooling_2d(h, 2, stride=2)
h = F.relu(self.conv2_1(h))
h = F.relu(self.conv2_2(h))
h = F.max_pooling_2d(h, 2, stride=2)
h = F.relu(self.conv3_1(h))
h = self.conv3_2(h)
h = f.global_average_pooling_2d(h) #B,2,1,1
h = F.reshape(h, (h.shape[0],h.shape[1]))# B,2
return h
有一个疑惑的地方是输出的通道为2,输出的是一个概率,那输出不应该为1?
