目录
@
0. 论文链接
FCN(https://arxiv.org/abs/1411.4038)
1. 概述
语义分割(semantic segmentation)其实就是对每个像素点进行预测分类(dense prediction)。这也应该是第一个训练对像素进行预测并且采用了有监督预训练的端到端FCN网络,可以对任意尺寸的输入利用现有的网络对其进行密集预测(dense prediction)。学习和推理能在全图通过密集的前馈计算和反向传播一次执行(whole-image-ata-time)。网内上采样层能在像素级别预测和通过下采样池化学习。作者提出了一种利用了结合深、粗层的语义(semantic)信息和浅、细层的表征(appearance)信息的特征谱的跨层网络结构(skip architecture)。
2. Adapting classifiers for dense prediction
因为之前的分类网络通常只能固定输入图片尺寸,然后输出概率,并没有空间信息。但是全连接层同样用卷积层进行表示,具体就是在用与输入分类网络FC层尺度大小相同卷积核从而获得与FC层相同维度的输出(比较经典也比较简单,不细举例了),换成全卷积层就可以接受任意尺度的输入并且输出一个分类图(classification map),具体可以看下图:
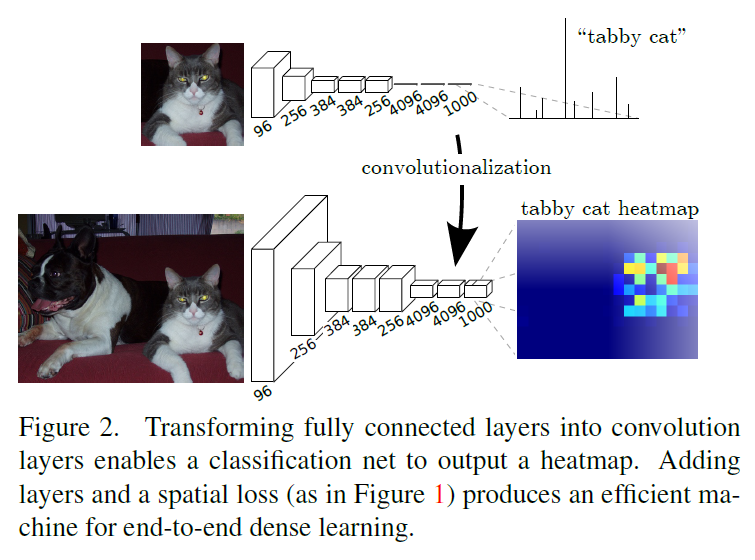
值得注意的是全卷积层最后输出的classification map相当于原来网络在某些特定patch上进行预测(可以想象成一个滑动窗口),但是很多计算都在这些patch的overlap上,浪费很多计算资源与时间,而全卷积层的效率是很高的。
3. upsampling
之前的对分类网络的改动,还是有一个问题的,比如output map相比原图维度是减少了很多的,因为在网络过程中通常会做一些 subsample来让卷积核变得更小,让计算量相对合理,所以我们需要通过一些手段使coarse output维度增加获得dense prediction的分割输出,文章中说了一句 感受野的步长等于输入尺寸与输出尺寸的系数比。接下来文章中介绍了三种upsample的方法。
3.1 Shift-and-stitch
这里首先推荐这位中科大学长的一篇博客,讲解的很不错,我也加了他的微信,为人也很好呢~在这我就简述一下Shift-and-stitch。
Shift-and-stitch是从coarse outputs到dense predictions的一种trick,文章在《Overfeat: Integrated recognition, localization and detection using convolutional networks》中被提到。他的方法为(直接看英文原版更清晰一些):

这里注意,通常需要在输入加相应的padding,来让他进行“shift”,引用上面中科大学长的文章内容:

为表述简洁,用 “ 像素 i ” 表示“ 值为 i 的像素 ”
红色 output中的像素1对应shifted input(0,0) 的红色部分, 而对应 original image 的部分,也即receptive field仅仅为像素[1], 所以 receptive field 的中心为像素[1], 该位置填上红色output中像素 1 的值。
- 黄色 output 中的像素4 对应 shifted input (1,0)的黄色部分, 而对应 original image 的部分,也即receptive field为像素 [3,4] , 所以 receptive field 的中心为像素 [4], 该位置填上黄色output中像素 4 的值。
以此类推..注意: 我们注意到黄色 output 中的像素 5 与红色 output 中的像素5对应的receptive field 中心是重叠的,所以将黄色 output 中的像素 5 标为灰色,表示不予考虑。同理其他ouput 中的灰色区域也代表 receptive field中心重叠的像素。
这里需要说明一下的是, 感受野的中心可以简单的理解成:给定一个矩形,求他的中心, 小数需要向上/下取整,所以上图2x2的感受野,在其实四个值都可以作为“中心”, 在论文《RECURRENT CONVOLUTIONAL NEURAL NETWORKS FOR SCENE PARSING》中,他举得例子是没有上图中“灰色块”的,如果按照灰色块里的数值计算,会发现他对“感受野中心”定义是不同的,有的是左下有的是右下,而在论文中,他则是忽略了灰色块, 我的理解是论文里是按照右下的规则,在灰色地方,感受野的中心成了padding的0,不是原图的像素,因此需要去掉,因此这样恰好可以拼成原图大小,不会多像素也不会少像素,如下图。

(关于中科大学长的观点目前还不知道他从哪得到的,也没看FCN中的源码,以后补充)
3.2 decreasing subsampling
上述采用的shift-and-stitch方案,需要反复计算 \(f*f\) 个输入,造成计算效率的降低。而 decreasing subsampling 方法提供了另外的一种思路,减小传统网络中降采样操作,从而实现 coarse output 的 dense prediction。
考虑其中某一层具有stride = s,后面卷积层具有卷积核权重 fij。现在我们设置原本stride = 1避免降采样的出现,形成上采样结果。然而直接对这样的上采样结果进行按照原本卷积核操作并不能得到相等于 shift-and-stitch的结果。因为这样的卷积核仅仅能看到上采样结果的一小部分,所以我们扩大原本的卷积核:
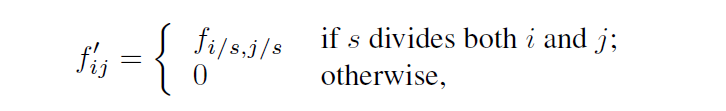
值得注意的是,这样的操作方式会造成一种 trade-off:卷积核如果需要看到更精细的信息,往往需要较小的感受野且需要更多的操作。这样的一种方式,使得感受野固定成一种较大的 input size,不能完成精细的定位分割信息。