来源:公众号看到一篇文章
原文:https://arxiv.org/pdf/2301.04275.pdf

0、摘要
基于LiDAR的语义分割在机器人和自动驾驶领域至关重要,因为它提供了对场景的全面理解。本文提出了一个轻量级的,高效的基于投影的语义分割网络称为LENet的编码器-解码器结构的基于激光雷达的语义分割。该编码器由一个新颖的多尺度卷积注意力(MSCA)模块组成,具有不同的感受野大小来捕获特征。解码器采用插值和卷积(IAC)机制,利用双线性插值对多分辨率特征图进行上采样,并通过单个卷积层整合先前和当前的维度特征。这种方法大大降低了网络的复杂性,同时也提高了其准确性。此外,我们还引入了多个辅助分割头,以进一步提高网络的准确性。对公开数据集(包括SemanticKITTI,SemanticPOSS和nuScenes)的广泛评估表明,与最先进的语义分割方法相比,我们提出的方法更轻,更有效,更鲁棒。可在https://github.com/fengluodb/LENet上获得完整实施。
关键字:Index Terms—LiDAR point clouds, 3D semantic segmentation, LiDAR perception, Autonomous Driving
1、引言
环境感知对于自动驾驶车辆理解周围场景至关重要。LiDAR和RGB相机通常用于自动驾驶的感知系统。虽然相机具有高分辨率和低成本等优势,但LiDAR传感器更强大,不受照明和天气条件的影响。此外,LiDAR点云数据提供了物体的几何精确表示,使其成为3D点云分析的理想选择。点云语义分割为点云中的各个点分配标签,提供了对场景的丰富理解。因此,点云语义分割已成为学术界和工业界越来越热门的研究课题。
由于3D点云的无序性和不规则性,直接应用标准卷积神经网络是不可行的。因此,研究工作一直集中在探索点云语义分割。基于点的方法,包括PointNet [2],PointNet++ [3],PointCNN [4]和RandLA-Net [5],直接从原始点云中提取特征,从而降低了预处理阶段的计算复杂性和噪声误差的影响。然而,基于点的方法遭受高计算复杂度和有限的处理速度。基于体素的方法将不规则的点云转换为规则的网格表示,这允许他们使用3D卷积神经网络。然而,基于体素的方法仍然面临类似于基于点的方法的问题。基于投影的方法通过球面投影将点云转换为2D范围图像来克服这些问题。除了与基于点和基于体素的方法相比提供上级推理速度和准确性之外,由于卷积网络在图像语义分割中的成功,基于投影的方法最近变得越来越流行。(一般就这三种)
在本文中,我们提出了一个轻量级和高效的激光雷达语义分割网络,利用基于投影的方法。通过对流行的公共基准测试(如SemanticKITTI [1])进行广泛的实验,我们已经证明我们的网络以每秒26帧的速度实现了最先进的准确性(如图1所示)。综上所述,本文的主要贡献如下:
- 我们开发了一种新的多尺度卷积注意力模块(MSCA)来取代我们编码器中的ResNet块。通过使用不同的内核大小(3,5,7),MSCA能够捕获关键信息,激光雷达扫描中不同大小的物体。该组件在优化语义分割方面起着至关重要的作用。
- 我们已经介绍了一个新的IAC模块,结合双线性插值上采样多分辨率特征图与一个单一的卷积层集成以前和当前的功能。我们的方法的结果是轻量级和强大的机制,显着降低了解码器的复杂性,同时也提高了准确性。
- 我们增加了网络的准确性,而不添加额外的推理参数,通过合并多个辅助分割头。这些分割头以不同的分辨率细化特征图,最终提高网络的学习能力。
- 我们在公开的数据集上进行了全面的实验,包括SemanticKITTI,SemanticPOSS和nuScenes。结果表明,我们提出的方法达到了最先进的性能。
2、相关工作
近年来,SemanticKITTI [1],NuScenes [7]和SemanticPOSS [8]等大规模数据集可用于自动驾驶场景的点云分割任务,结合深度学习的快速发展,导致了广泛的3D LiDAR点云语义分割方法的提出。这些方法通常可以基于其输入数据表示分为四组,包括点、体素、范围图和混合表示。
Point-based methods基于点的方法直接处理原始3D点云,而不应用任何额外的变换或预处理,这能够保留3D空间结构信息。这个小组的先驱方法是PointNet [2]和PointNet++ [3],它们使用共享的MLP [9]来学习每个点的属性。在随后的一系列工作中,KPConv [10]开发了可变形卷积,可以使用任意数量的核点来学习局部几何。但这些方法都存在计算复杂度高、内存消耗大的缺点,阻碍了它们对大规模点云的处理。RandLA-Net [5]采用随机采样策略,利用局部特征聚合减少随机操作造成的信息损失,大大提高了点云处理的效率,减少了内存消耗。

Voxel-based Methods采用基于体素的方法将点云数据转换为体素进行处理,有效解决了点云数据的不规则性问题。早期的基于体素的方法首先将点云转换为3D体素表示,然后使用标准的3D CNN来预测语义标签。然而,常规的3D卷积需要巨大的内存和繁重的计算能力。Minkowski [11]选择使用稀疏卷积代替标准3D卷积和其他标准神经网络来降低计算成本。Budder3D [12]采用3D空间划分,并设计了一个非对称的残差块来减少计算。AF2S3Net [13]实现了最先进的体素方法,它提出了两个新的注意力块,即注意力特征融合模块(AF2M)和自适应特征融合(ASFM),以有效地学习局部特征和全局上下文。
Projection-based Methods基于投影的方法将三维点云投影到二维图像空间,可以利用大量的高级层进行图像特征提取。SqueezeSeg [14]提出球面投影,将散射的3D激光点映射到2D Range-Image,然后使用轻量级模型SqueezeNet和CRF进行分割。随后,SqueezeSegV 2 [15]提出了上下文聚合模块(CAM),以从更大的感知场聚合上下文信息。RangeNet++ [6]将Darknet集成到SqueezeSeg中,并提出了一种有效的KNN后处理方法来预测点的标签。SqueezeSegV 3 [16]提出了根据输入图像的位置使用不同滤波器的空间自适应卷积(SAC)。SalsaNext [17]继承了SalsaNet [18]的编码器-解码器架构,并提出了一种用于点特征学习的不确定性感知机制。Lite-HDSeg [19]通过引入三个不同的模块,Inception-like Context Module,Multi-class Spatial Propagation Network和边界损失来实现最先进的性能。为了获得更好的性能,并受到SegNext在图像分割方面的成功的启发,我们提出了一种新的MSCA模块和IAC模块,以在FIDNet的基础上组成新的流水线[20]。
Hybrid methods混合方法试图综合逐点方法、投影方法和体素方法的优点。SPVNAS [21]提出了一种稀疏点-体素卷积,它由基于点的分支和基于稀疏体素的分支组成。基于点的分支关注点云的局部特征,基于稀疏体素的分支关注全局上下文。RPVNet [22]提出了一种融合三种类型数据的网络,包括三个分支:基于点的分支、基于投影的分支和基于体素的分支。基于点的分支作为中间节点融合不同分支的输出。
3、方法
A. Range Image Representation.
使用球面投影方法,我们可以将非结构化的点云转换为有序的范围表示,即2D图像。范围表示的优点在于,它可以使用有效的2D卷积运算进行快速训练和推理,并且可以促进在基于图像的任务中已经得到很好研究的成熟深度学习技术。
在距离图像表示中,具有笛卡尔坐标的每个LiDAR点p =(x,y,z),使用球面映射R3 → R2将其变换为图像坐标,如下所示:
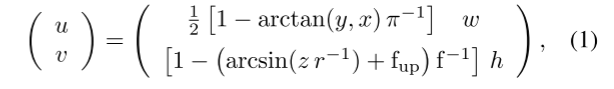
其中(u,v)是图像坐标,(h,w)是期望的距离图像表示的高度和宽度,f = fup + fdown是传感器的垂直视场,并且r = px2 + y2 + z2是每个点的距离。
B. Convolution Attention Encoder
多尺度特征在语义分割中至关重要,因为它们能够处理单个图像中不同大小的对象。为了提取这些特征,常规方法涉及使用具有不同感受野的卷积并融合它们各自的场,如[17]所示。受SegNext [23]的启发,我们提出了一种为我们的问题域定制的新型多尺度卷积注意力(MSCA)模块。与SegNext中的原始版本相比,我们进行了重大修改和调整。其中包括优化MSCN卷积内核以适应激光雷达数据,用SiLU替换GELU激活函数以提高效率,同时保持准确性,以及优化BasicBlock结构以充分利用MSCN的功能。
如图在图3(B)中,MSCA模块包括三个部分:深度卷积用于聚合局部信息,多分支深度条带卷积用于捕获多尺度上下文,以及1 × 1卷积用于对不同通道之间的关系进行建模。最后,1 × 1卷积的输出直接用作注意对MSCA输入的权重进行重新加权。此外,我们遵循[20]采用金字塔结构用于我们的编码器。如图3(a)所示,编码器中的构建块由3 × 3卷积层和MSCA组成。

C. IAC Decoder
为了设计一个简单有效的解码器,我们研究了几种不同的译码器结构。在[6],[16],[17]中,他们使用标准的转置卷积或像素重排来产生上采样的特征图,然后使用一组卷积来解码特征图,这是有效的,但计算量很大。在FIDNet中,它的解码器使用FID(完全插值解码)来解码不同层次的语义,然后使用分类头来融合这些语义。虽然FID是完全无参数的,但它不具有从特征中学习的能力,这使得模型的性能过度依赖于分类头。此外,FIDNet的分类头融合了太多的低层信息,这降低了性能。
在这项工作中,我们提出了一个轻量级的解码器,如图2所示IAC模块包含两个部分:采用双线性插值对来自编码器的特征图进行上采样,采用3 × 3卷积融合来自编码器和前一个IAC的信息。最后,我们使用逐点卷积来融合来自最后三个IAC模块的特征。与其他两种译码器相比,我们的译码器具有最少的参数和最好的性能。

D. Loss Function
在这项工作中,我们用三种不同的损失函数训练所提出的神经网络,即加权交叉熵损失Lwce,Lov 'asz损失Lls和边界损失Lbd。最后,我们的总损失如下:

w1、w2和w3是关于每个损失函数的权重。在我们的实现中,我们设置w1 = 1,w2 = 1.5和w3 = 1。
三个损失函数解释了三个不同的问题。为了应付类别不平衡的问题,采用加权交叉熵损失Lwce来最大化点标签的预测精度,从而能够平衡不同类别之间的分布。它的定义是
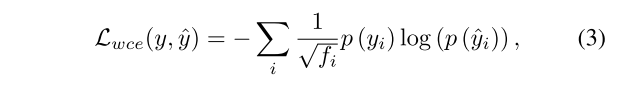
其中yi表示地面真值,并且fyi是预测,fi是第i类的频率。
为了解决交叉-合并(IoU)的优化问题,使用Lov 'asz损失Lls来最大化交叉-合并(IoU)得分,该得分通常用于语义分割的性能评估。其定义为:
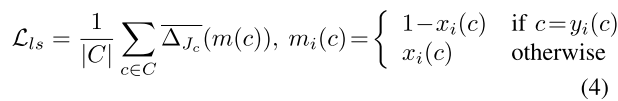
哪里|C|是类号,Jc表示Jaccard索引的Lov 'asz扩展,xi(c)∈ [0,1]和yi(c)∈ {−1,1}分别保存类c的像素i的预测概率和地面真值标签。
为了解决[19],[30],[31]中提出的模糊分割边界问题,边界损失函数Lbd用于LiDAR语义分割,其可以公式化定义如下:
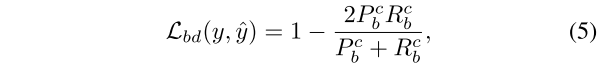
其中,Pc B和Rc b定义了预测边界图像的精确度和召回率,其中,对于类别c,预测边界图像的精确度和召回率为真实的的yb。边界图像计算如下:
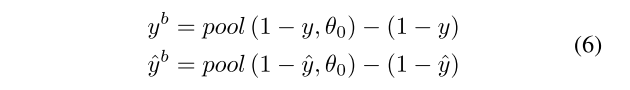
其中pool(·,·)在大小为θ0的滑动窗口上采用逐像素最大池化。此外,我们设置θ0 = 3。
(前两个loss比较常见,第三个loss见的比较少,通过先再每个类别上取反,再根据池化后的相减就是边界线)
在我们提出的网络中,分类头融合最后三个不同维度的特征图进行输出,这使得它的性能主要依赖于最后三个IAC模块。因此,我们使用辅助分割头来进一步改进我们提出的网络准确性。这些辅助分段头计算加权损失和主损失。同时,由于不同维度的特征图具有不同的表达能力,因此每个损失都有相应的权重,这与[16],[31]不同。最终损失函数可以定义为,

其中Lmain是主要损失,yi是从阶段i获得的语义输出,并且(yi表示对应的语义标签。L(·)根据等式2计算。在我们的实现中,我们根据经验设置λ1 = 1,λ2 = 1和λ3 = 0.5。
4、实验
A. Experiment Setups
为了评估我们的方法,我们使用SemanticKITTI,这是一个用于自动驾驶场景点云分割任务的大规模数据集。它为KITTI Odometry Benchmark中的22个序列(43,551次扫描)提供密集逐点注释。序列00到10(19,130次扫描)用于训练,11到21(20,351次扫描)用于测试。我们遵循[1]中的设置,并使用序列08(4,071次扫描)进行验证。为了评估我们所提出的方法的有效性,我们将输出提交到在线评估网站,以获得测试集上的结果。
为了验证我们提出的方法的通用性,我们在SemanticPOSS和nuScenes数据集上进行了额外的实验。SemanticPOSS由北京大学收集,使用与SemanticKITTI相同的数据格式。然而,与SemanticKITTI相比,它是一个更小,更稀疏的数据集,具有2988个复杂的LiDAR扫描和大量的动态实例,使其成为一个具有挑战性的基准。另一方面,nuScenes由1000个序列组成,每个序列的持续时间为20秒,使用32束激光雷达传感器记录。在这三个数据集中,nuScenes在其点云中每帧的点最少,但帧数最多。
为了便于公平比较,我们评估了不同方法在联合度量上的平均交集(mIoU)的性能,其定义如下:

其中,TPc、FPc和FNc表示类别c的真阳性、假阳性和假阴性预测。
B. Implementation details.
我们使用PyTorch [36]实现了我们提出的方法,并在具有四个NVIDIA RTX 3090 GPU的计算机上进行了所有实验。为了训练网络,我们使用了批量大小为8,范围图像大小为64 × 2048。我们采用了AdamW [37]优化器和PyTorch中的默认设置,初始学习率设置为2e−3,我们使用余弦退火调度器在50个epoch中动态调整。在训练过程中,我们使用随机旋转,随机点丢失和翻转3D点云来执行数据增强。
C. Evaluation Results and Comparisons
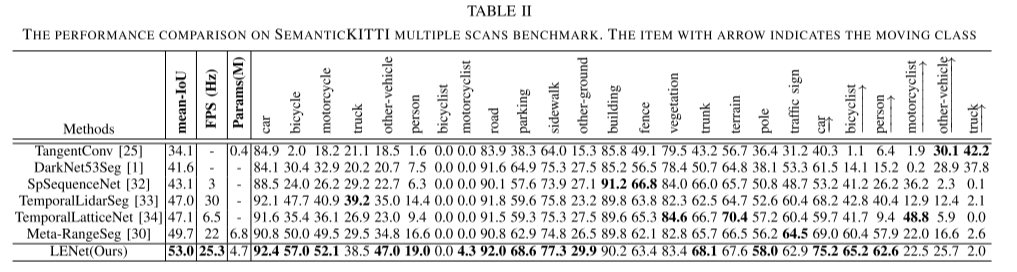
表I显示了在SemanticKITTI单扫描基准上测试的各种最新方法的结果。我们的方法实现了最先进的性能相比,基于点和基于图像的方法在单扫描基准(64.5% mIoU)。表II显示了SemanticKITTI多次扫描基准上各种最新方法的定量结果。我们提出的方法还实现了最先进的性能,mIoU为53.0%。值得注意的是,我们提出的网络是轻量级的,只有大约470万个参数,运行速度约为每秒26帧,同时保持高精度。(存疑,也不是最先进性能啊,CENET不是最高的吗)

 表III显示了我们提出的LENet与SemanticPOSS的其他相关作品的比较。由于传感器和环境的差异,所有方法的精度都略低。尽管如此,我们提出的方法实现了最先进的性能,正如其在整体mIoU和几乎所有类的mIoU指标中的高分所证明的那样。
表III显示了我们提出的LENet与SemanticPOSS的其他相关作品的比较。由于传感器和环境的差异,所有方法的精度都略低。尽管如此,我们提出的方法实现了最先进的性能,正如其在整体mIoU和几乎所有类的mIoU指标中的高分所证明的那样。

表IV比较了我们提出的LENet与FIDNet和CENet在nuScenes验证集上的性能。与SemanticKITTI和SemanticPOSS相比,nuScenes数据集具有最稀疏的采样点云,这使得任务更具挑战性。尽管如此,我们的方法仍然达到了很高的准确性,分别超过了基准FIDNet和CENet的2.3%和0.4%。(这个0.4是怎么出来的)

为了更好地可视化我们提出的模型在基线系统上的改进,我们在图中对FIDNet和LENet进行了定性比较。图4我们比较了预测结果和生成的错误映射的两个模型上的三个数据帧从SemanticKITTI验证集。比较表明,我们提出的方法在FIDNet上有显着的改进。

(好奇这种三维可视化怎么做到每次角度一样的)
D. Ablation Studies
在本节中,我们将介绍在SemanticKITTI验证集(序列08)上进行的多个消融实验的结果,以观察我们提出的网络中各个模块的性能影响。为了公平比较,我们使用FIDNet作为基线,因为它与我们的网络结构相似。然后,我们用第三节中提出的MSCA和IAC模块替换基线。最后,我们逐步增加边界损耗和辅助损耗,以评估它们对网络的有效性。表V显示了SemanticKITTI验证集上的模型参数数量和相应的mIoU分数。我们提出的LENet方法与基线相比,参数改善了4.8%以上,减少了25%,验证了每个模块的有效性。
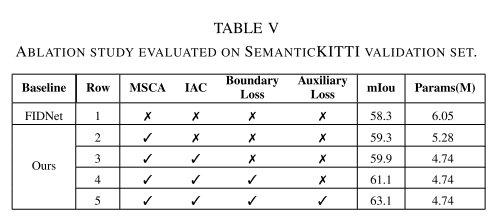
我们提出的网络实现了更高的精度,当我们用MSCA替换基线的基本块时,精度提高了1.0%以上。同时,由于在MSCA中使用了群卷积,我们的网络将参数总数减少到5.28M,使其轻量级。在用IAC替换原始解码器后,我们的网络也提高了准确率,与之前相比提高了约0.6%。尽管IAC包含可学习的卷积参数,但改进的性能清楚地证明了ICA的有效性。此外,伊卡的使用消除了解码器中对沉重的分段头的需要,如FIDNet,从而减少了参数数量(4.74M)。在附加损失函数方面,边界损失带来了超过1.2%的性能增益,而辅助损失实现了超过2.0%的令人印象深刻的性能跃升。
V. CONCLUSIONS
我们提出了一个轻量级的,高效的实时CNN模型称为LENet的激光雷达点云分割的任务。我们的新的编码器-解码器架构是基于MSCA和IAC。此外,我们还引入了边界损失来强调语义边界,并引入了几个额外的分割头来进一步提高特征学习能力,而不会影响参数或效率成本。我们提出的方法实现了单扫描语义分割和多扫描语义分割以及实时能力的最先进的性能,如SemanticKITTI测试数据集上的评估所示。此外,我们在SemanticPOSS和nuScenes上进行了进一步的实验,并取得了令人满意的结果。
自己总结
- 轻量化的编码器,但是感觉很熟悉哪里看到过
- 轻量化解码器,文中解释不太清楚,应该和unet也差不多,但是是根据最后三层做一次恢复原始尺寸,多个辅助头因该用在不同层级的语义标签。
- 指标看着有点懵