崩溃!一觉醒来发现昨天写到半夜的总结没保存......  不是隔一段时间系统就提示几点几分已保存的嘛~ 都是骗人的
不是隔一段时间系统就提示几点几分已保存的嘛~ 都是骗人的 码字好辛苦 不想说话
码字好辛苦 不想说话
————————————————————正事分割线———————————————————————————
一、综括
全卷积网络可以自己进行端到端,像素到像素的训练,改善了以前在语义分割中的结果。全卷积网络可以输入任意大小的数据,并通过有效的推理和学习生成相应大小的输出。将目前分类网络(AlexNet,VGG网络和GoogLeNet)调整为全卷积网络,并通过微调将其学习表示转移到分割任务。然后,定义一个跳过体系结构,将来自深层粗略的语义信息与来自浅层精细层的外观信息相结合,以生成准确和详细的分段。该全卷积网络是第一个端到端,监督预训练的网络,实现了对PASCAL VOC(相对于2012年的平均IU的30%至67.2%),NYUDv2,SIFT Flow和PASCAL-Context的改进分割,而对于典型图像,推断需要十分之一秒。
二、研究内容与方法
文章将各层的特性融合在一起,定义了一个由局部到全局的非线性表示。
1、扩大滤波器:设原图与FCN所得输出图之间的降采样因子是f,对输入的每个f*f的区域(不重叠)x,y 向右向下移动,把这个f*f区域对应的输出作为此时区域中心点像素对应的输出,这样就对每个f*f的区域得到了f^2个output,也就是每个像素都能对应一个output,所以成为了dense prediction。另一种放大CNN网络中的subsampling层的filter的尺寸,得到新的filter:
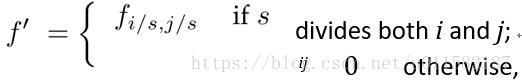
其中s是采样的滑动步长,这个新滤波器的滑动步长要设为1,这样的话,采样之后不会缩小图像尺寸,最后可以得到dense prediction。
这种方法下采样的功能被减弱,滤波器能接收到更精细的信息,但是感受域会变小,可能会损失全局信息,且会对卷积层引入更多运算,输出的密度增加而不减少过滤器的接受域大小,但是过滤器被禁止以比原始设计更细的比例访问信息。文章研究了这两种方法都没有采用,因为发现结合上采样和跳跃链接效果更好。
2、upsampling:可以看成是反卷积(deconvolutional),卷积运算的参数和CNN的参数一样是在训练FCN模型的过程中通过bp算法学习得到。实质就是将卷积池化过程反过来。
3、特征融合:以上是对CNN的结果做处理,得到了dense prediction,而作者在试验中发现,得到的分割结果比较粗糙,为了将粗、高的层信息与精细、低层次的信息结合起来,定义了一个新的结构,将特征层次的信息相融合。FCN-32s:单流网络,upsamples将32个预测转换为单个步骤中的像素。FCN-16s:结合最后一层和pool4层的预测,步幅16,net预测更详细的细节,同时保留高级语义信息。FCN-8s:来自pool3的额外预测,步幅8,更进一步提高了精度。结构如下图:
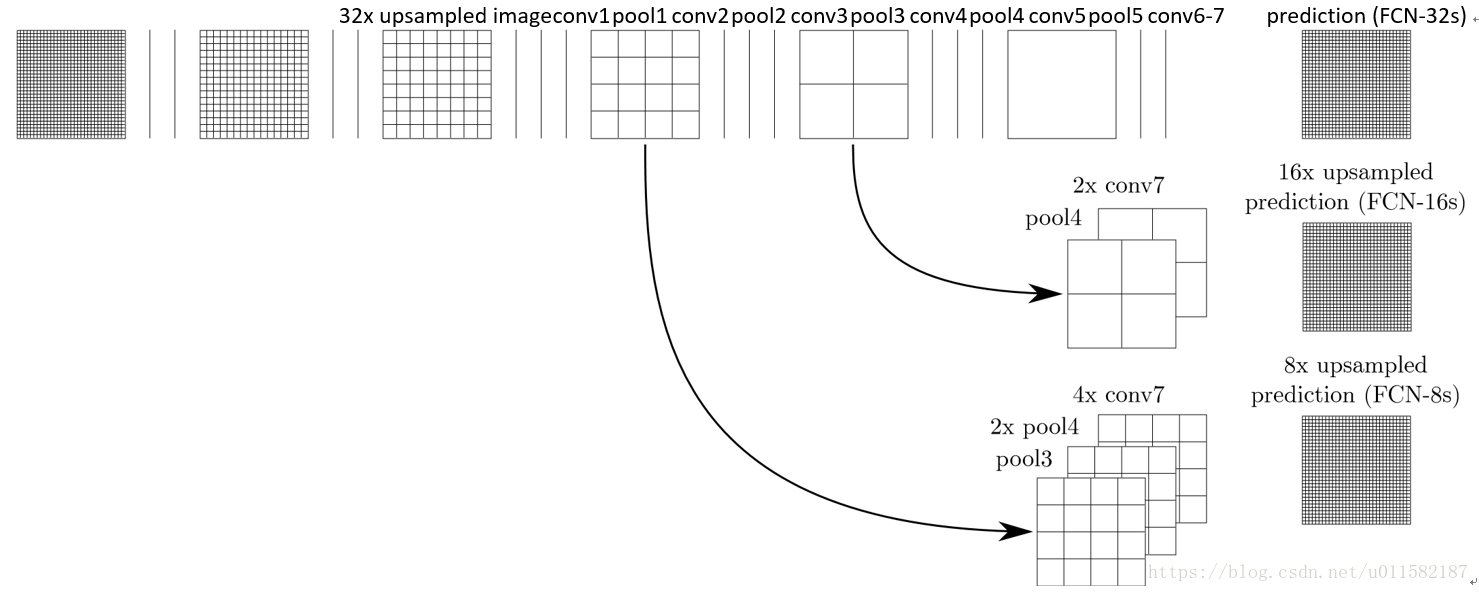
实验表明,这样的分割结果更细致更准确。在逐层融合的过程中,做到第三行再往下,结果又会变差,所以作者做到这里就停了。
4、文章先在Alex net、VGG16、GoogleNet结构上作初始测试,发现VGG16结果比较好,最终决定使用VGG16结构。在VGG16上通过梯度累积、在线学习和“heavy”学习的高动量来比较图像与图像的优化。所有的方法都是对10万张图像的固定序列进行训练(从8498的数据集中取样),以控制随机性,并平衡梯度计算的数量。损失不是标准化的,所以每个像素都有相同的权重。在PASCAL VOC 2011年的subset5的训练中,分数是最好的。
三、实验结果分析
度量方式:
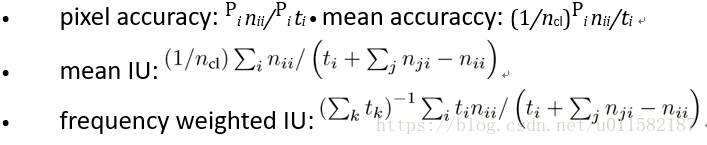
VGG16学习结果:
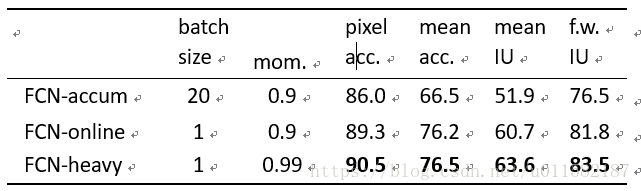
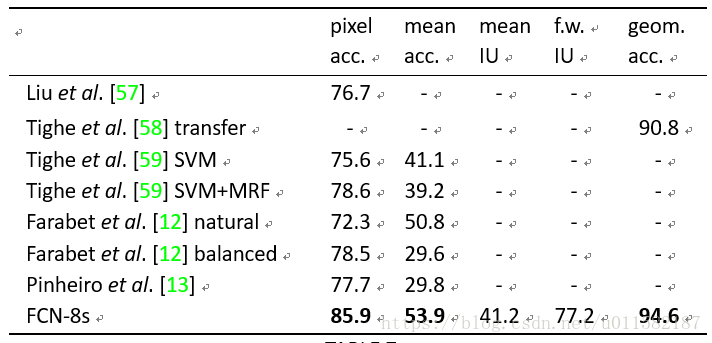
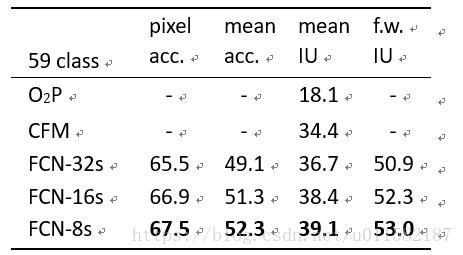
FCN特征融合的三种结构效果对比,FCN-8s得分最高:
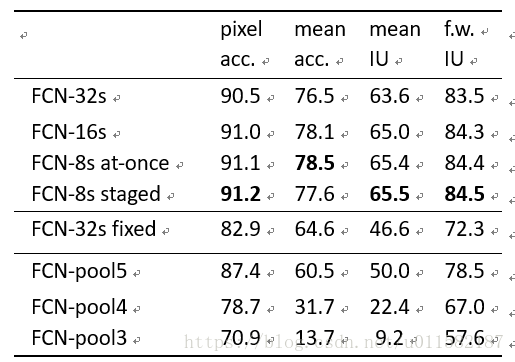
PASCAL VOC数据集:下表4给出了FCN-8s在PASCAL VOC 2011年和2012年测试集上的性能,并将其与之前最好的SDS和著名的R-CNN进行了比较。在平均IU上取得了最好的结果。推理时间减少114倍(事先,忽略建议和细化)或286倍(整体)。
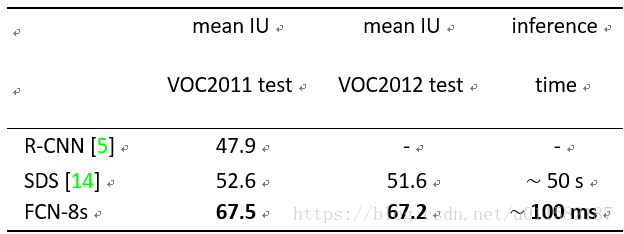
NYUD v2数据集:1449张图象,40类,分为795训练图,654测试图。下表5给出了不同模型之间性能测试结果,发现单独的RGB-D和HHA并没有提升实验结果,但是将两者融合之后得到了最高分。如下所示:
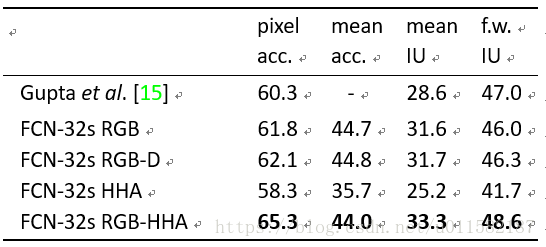
SIFT Flow数据集:2688张图像,33分类,分为2488训练图,200测试图。与其他方法相比较,达到85.9%准确率。如下所示:
PASCAL context数据集:在下表中,与之前的最佳结果做比较。FCN-8s的得分为39.1,相对提高10%以上。
四、读后感
1,直接使用现有的CNN网络,如AlexNet, VGG16, GoogLeNet,在末尾加上upsampling,训练一个end-to-end的FCN模型,利用卷积神经网络的很强的学习能力,得到较准确的结果,以前的基于CNN的方法都是要对输入或者输出做一些处理,才能得到最终结果。参数的学习还是利用CNN本身的反向传播原理。
2,不限制输入图片的尺寸,不要求图片集中所有图片都是同样尺寸,只需在最后upsampling时按原图被subsampling的比例缩放回来,最后都会输出一张与原图大小一致的dense prediction map。
根据论文的conclusion部分所示的实验输出sample如下图:
