
论文地址:https://arxiv.org/pdf/2005.10821.pdf
发表时间:2020
多尺度推理是提高语义分割结果的常用方法。多个图像尺度通过网络,然后将结果与平均或最大池化相结合。在这项工作中,我们提出了一种基于注意力的方法来结合多尺度预测。我们表明,在特定尺度上的预测更能解决特定的故障模式,并且网络学会了在这种情况下支持这些尺度,以产生更好的预测。我们的注意力机制是分层的,这使得它的训练效率比其他最近的方法高4倍。除了实现更快的训练之外,这还允许我们用更大的crop尺寸进行训练,从而导致更大的模型精度。我们在两个数据集上展示了我们的方法的结果:Cityscapes和Mapillary Vistas。对于具有大量弱标记图像的Cityscapes,我们也利用自动标记来提高泛化能力。使用我们的方法,我们在Mapillary Vistas(61.1 IOU val)和Cityscapes(85.1 IOU测试)中获得了一个新的最先进的结果。
1 Introduction
语义分割的任务是将图像中的所有像素标记为属于N类中的一个。在这个任务中有一个权衡,即某些类型的预测最好在较低的推理分辨率下处理,而其他任务最好在较高的推理分辨率下更好地处理。精细的细节,如物体的边缘或薄的结构,通常可以通过放大的图像大小更好地预测。与此同时,对需要更多的全局背景的大型结构的预测,通常在缩小图像尺寸时做得更好,因为网络的接受域可以观察到更多的必要的背景。我们将后一个问题称为类混淆。图1展示了这两种情况的示例。
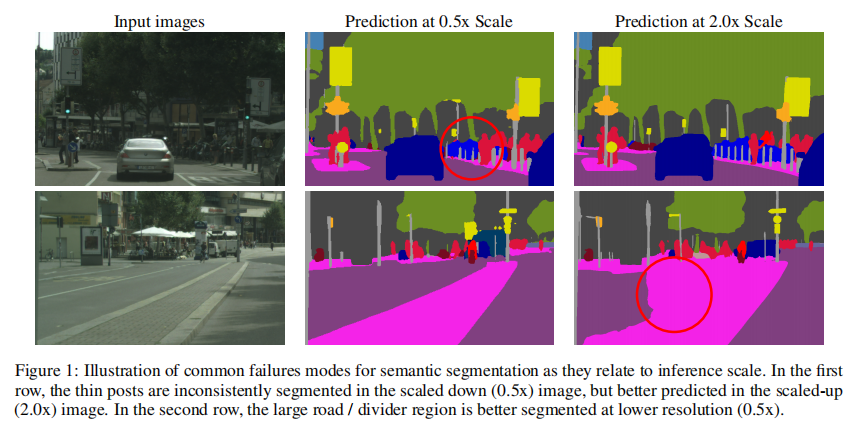
使用多尺度推理是解决这种权衡的一种常见做法。预测是在一系列尺度上完成的,结果与平均或最大池化相结合。使用平均来组合多个尺度通常会改善结果,但它会遇到将最佳预测与较差预测组合的问题。例如,如果对于一个给定的像素,最好的预测来自2倍尺度,而更糟糕的预测来自0.5倍尺度,那么平均将结合这些预测,导致低于标准的输出。另一方面,最大池化只选择N个尺度中的一个用于给定的像素,而最优答案可能是在不同的预测尺度上的加权组合。
为了解决这个问题,我们采用了一种注意机制来预测如何在像素水平上将多尺度预测组合在一起,类似于Chen [1]等人提出的方法。我们提出了一种层次注意机制,通过该机制,网络学习预测相邻尺度之间的相对权重。在我们的方法中,由于它的层次化性质,我们只需要用一个额外的尺度来增加训练管道,而其他方法,如[1],则需要在训练阶段显式地添加每个额外的推理尺度。例如,当多尺度评价的目标推理量表为{0.5、1.0和2.0}时,其他注意方法要求网络首先使用所有这些量表进行训练,从而产生4.25倍( 0. 5 2 + 2. 0 2 0.5^2+2.0^2 0.52+2.02)的额外训练成本。我们的方法只需要在训练期间增加一个额外的0.5倍的规模,这只增加了0.25倍(0.52)的成本。
此外,我们提出的分层结构与之前提出的仅限于在推理时使用训练尺度的方法相比,该机制还提供了在推理时选择额外尺度的灵活性。
为了在城市景观中获得最先进的结果,我们还采用了粗图像的自动标记策略,以增加数据集的方差,从而提高泛化程度。我们的策略是由最近的多项工作推动的,包括[2,3,4]。与典型的软标签策略相反,我们采用硬标签来管理标签存储大小,这有助于通过降低磁盘IO成本来提高训练吞吐量。
Contributions:
- 提出一种有效的层次多尺度注意机制,通过允许网络学习如何最好地结合来自多个推理尺度的预测,来帮助解决类混淆和精细细节
- 提出一种基于硬阈值的自动标签策略,利用未标记的图像和提高借据
- 我们在城市景观(85.1 IOU)和mapablvistas(61.1IOU)上取得了最先进的结果
2 Related Work
Multi-scale context methods. 最先进的语义分割网络使用具有低输出步幅的网络主干。这使得网络能够更好地解决细节,但它也有缩小接受域的效果。这种接受野的减少会导致网络难以预测场景中的大型物体。金字塔池化可以通过组装多尺度的环境来抵消缩小的感受域。PSPNet[5]使用一个空间金字塔池化模块,该模块使用池化和卷积操作序列从网络主干的最后一层获得的特征,在多个尺度上组装特征。DeepLab[6]使用了空间空间金字塔池化(ASPP),它采用了不同膨胀水平的无卷积,从而创造了与PSPNet相比更密集的特征。最近,ZigZagNet[7]和ACNet[8]利用中间特性,而不仅仅是来自网络主干的最后一层的特性来创建多尺度上下文。
Relational context methods. 在实践中,金字塔池化技术关注于固定的、正方形的上下文区域,因为池化和扩张通常以对称的方式使用。此外,这些技术往往是静态的,而不是需要学习的。然而,关系上下文方法通过关注像素之间的关系来构建上下文,而不绑定到正方形区域。关系上下文方法的学习本质允许基于图像组合构建上下文。这些技术可以为非方形语义区域构建更合适的上下文,如长火车或高高的薄灯柱。OCRNet[9],DANET[10],CFNet[11],OCNet[12]和其他相关的工作[13,14,15,16,17,18,19,20]使用这种关系来构建更好的上下文。
Multi-scale inference. 上述两种方法[21,22,23,9]都采用多尺度评价来获得最佳效果。有两种常见的方法可以在多个尺度上结合网络预测:平均池化和最大池化,其中平均池化更常见。然而,平均池化涉及到来自不同规模的同等权重,这可能是次优的。为了解决这个问题,陈等人[1,24]使用使用注意组合多个尺度。[1]使用神经网络的最终特征同时训练所有尺度的注意力头。而陈等人使用来自特定一层的注意力。杨等[24]使用来自不同网络层的特征组合来构建更好的上下文信息。然而,上述两种方法都有共同的特点,即网络和注意力头是用一组固定的尺度训练的。只有这些尺度可以在运行时使用,否则网络必须重新训练。我们提出了一种基于层次的注意机制,该机制与推理时间内的尺度数量无关。此外,我们还表明,我们提出的层次注意机制不仅提高了平均池化的性能,而且还允许我们诊断地可视化不同尺度对类和场景的重要性。此外,我们的方法正交于其他注意或金字塔池方法,如[22,25,26,9,27,10,28],因为这些方法使用单尺度图像和执行注意,以更好地结合多层特征来生成高分辨率预测。
Auto-labelling. 最近的Cityscapes语义分割工作,特别是利用了~20,000张粗标记的图像来训练最先进的模型[12,29]。然而,由于标签的粗糙,每个粗糙图像都有大量未被标记。为了在城市景观上取得最先进的成果,我们采用了一种由谢等人[2]提出的自动标签策略。其他语义分割[30,31,32,33,34]中的半监督自训练,以及其他基于伪标签的方法,如[4,35,36,3]。我们为城市景观中的粗糙图像生成密集的标签。我们生成的标签只有很少的未标记区域,因此我们能够利用粗图像的全部内容。
虽然大多数图像分类自动标记工作使用软标签,但我们生成硬阈值标签,以提高存储效率和训练速度。使用软标签,教师网络为图像的每个像素的N个类提供一个连续的概率,而对于硬标签,使用一个阈值来选择每个像素的单个顶级类。与[37,4]类似,我们为粗糙的城市景观图像生成硬致密的标签。示例如图4所示。不像谢等人[2],我们不对标签进行迭代细化。相反,我们使用默认的粗标签和细标签提供的图像对我们的教师模型进行一次完整的训练迭代。在这次联合训练之后,我们对粗糙的图像进行自动标记,然后在我们的教师训练配方中进行替换,以获得最先进的测试结果。使用我们的伪生成的硬标签,结合我们提出的层次注意,我们能够获得最先进的城市景观的结果。
3 Hierarchical multi-scale attention
我们的注意机制在概念上非常类似于[1],密集的mask学习为每个规模,和这些多尺度预测是通过执行像素乘法mask预测紧随不同规模之间像素的求和获得最终结果,见图2。我们把陈的方法称为显式的方法。使用我们的分层方法,我们不是学习每一组固定量表的所有注意力面具,而是学习相邻量表之间的相对注意mask。在训练网络时,我们只训练相邻的标度对。如图2所示,给定一组来自单一(较低)尺度的图像特征,我们预测了两个图像尺度之间的密集像素级相对关注。在实践中,为了获得一对缩放图像,我们取一个输入图像并将其缩放到2倍,这样我们就可以留下1倍比例输入和0.5倍缩放输入,尽管可以选择任何缩放比例。需要注意的是,网络输入本身是原始训练图像的重新缩放版本,因为我们在训练时使用了图像缩放增强。这使得网络网络学习预测一系列图像尺度的相对注意力。在运行推理时,我们可以分层地应用学习到的注意力,将N个尺度的预测组合在一起,如图所示,用下面的公式描述。我们优先考虑更低的尺度,并努力到更高的尺度,认为它们有更多的全局背景,可以选择需要通过更高尺度的预测来改进的预测。
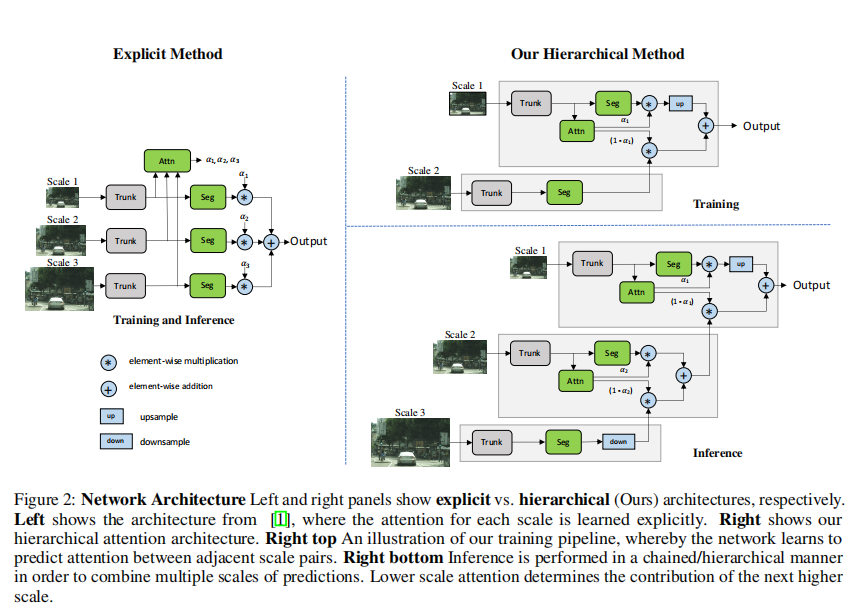
更标准地说,在训练过程中,给定的输入图像按因子r进行缩放,其中r=0.5表示2因子的降采样,r=2.0表示2倍的上采样,r=1表示不操作。在我们的训练中,我们选择了r=0.5和r=1.0。然后将r=1和r=0.5的两幅图像通过共享网络主干通道,产生语义逻辑值L和每个尺度的一个注意掩码(α),用于融合两个尺度之间的语义逻辑值L。因此,对于两种尺度训练和推理,以 U \mathcal{U} U为双线性上采样操作,∗和+分别为像素级乘法和加法,方程可以形式化为:
L ( r = 1 ) = U ( L ( r = 0.5 ) ∗ α ( r = 0.5 ) ) + ( ( 1 − U ( α ( r = 0.5 ) ) ) ∗ L ( r = 1 ) ) (1) \mathcal{L}_{(r=1)}=\mathcal{U}\left(\mathcal{L}_{(r=0.5)} * \alpha_{(r=0.5)}\right)+\left(\left(1-\mathcal{U}\left(\alpha_{(r=0.5)}\right)\right) * \mathcal{L}_{(r=1)}\right) \tag{1} L(r=1)=U(L(r=0.5)∗α(r=0.5))+((1−U(α(r=0.5)))∗L(r=1))(1)
使用我们提出的策略有两个优点:
- 在推理时,我们现在可以灵活地选择尺度。我们提出的注意机制可以分层连接在一起,因此我们提出的注意机制可以在0.5x和1.0x的尺度下训练,而在使用时支持新的尺度,例如0.25x和2.0x。这不同于之前提出的方法,后者仅限于使用在模型训练中使用的相同的比例。
- 与显式方法相比,这种层次结构允许我们提高训练效率。采用显式方法,如果使用0.5、1.0、2.0尺度,相对于单尺度训练,训练成本为 0. 5 2 + 1. 0 2 + 2. 0 2 = 5.25 0.5^2+1.0^2+2.0^2=5.25 0.52+1.02+2.02=5.25。使用我们的分层方法,训练成本仅为 0. 5 2 + 1. 0 2 = 1.25 0.5^2+1.0^2=1.25 0.52+1.02=1.25。注:这里的训练成本是是计算量,尺度为2,则训练成本为 2 2 2^2 22,因为长宽都变大了
3.1 Architecture
Backbone 对于本节中的消融研究,我们使用ResNet-50[38](配置为输出步幅为8)作为我们的网络的主干。为了获得最先进的结果,我们使用了一个更大、更强大的主干,HRNet-OCR[9]。
Semantic Head: 语义预测是由一个专用的全卷积头来执行的,它由(3x3 conv)→(BN)→(ReLU)→(3x3 conv)→(BN)→(ReLU)→(1x1conv)组成。最终的卷积输出num_classes通道。
Attention Head: 注意预测是使用一个单独的头部完成的,在结构上与语义头部相同,除了最终的卷积输出,它输出一个通道。当使用ResNet-50作为主干时,语义头和注意力头被输入来自ResNet-50最后阶段的特征。当使用HRNet-OCR时,语义头和注意力头被输入来自OCR块之外的特征。在HRNet-OCR中,还存在一个辅助语义头,它在OCR之前直接从HRNet主干中获取其特征。该头部由(1x1 conv)→(BN)→(ReLU)→(1x1 conv)组成。在注意语义对数后,通过双线性上采样将预测值上采样到目标图像的大小。
3.2 Analysis
为了评估我们的多尺度注意方法的有效性,我们使用DeepLabV3+架构和ResNet50主干来训练网络。在表1中,我们表明,与基线平均方法(49.4)或显式方法(51.4)相比,我们的层次注意方法具有更好的准确性(51.6)。当添加0.25x尺度时,我们也观察到我们的方法有明显更好的结果,当补充0.25尺度时我们的方法不需要重新训练模型。这种在推理时的灵活性是我们的方法的一个关键好处。我们可以训练一次,但可以用不同的尺度灵活地进行评估。
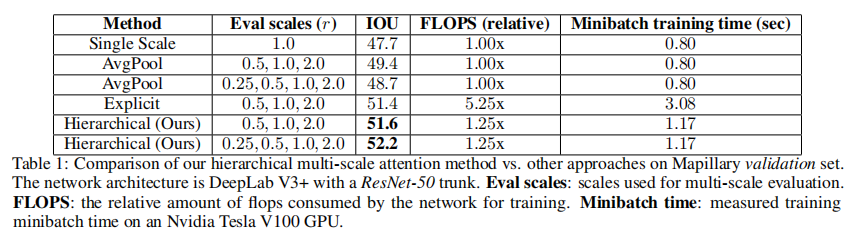
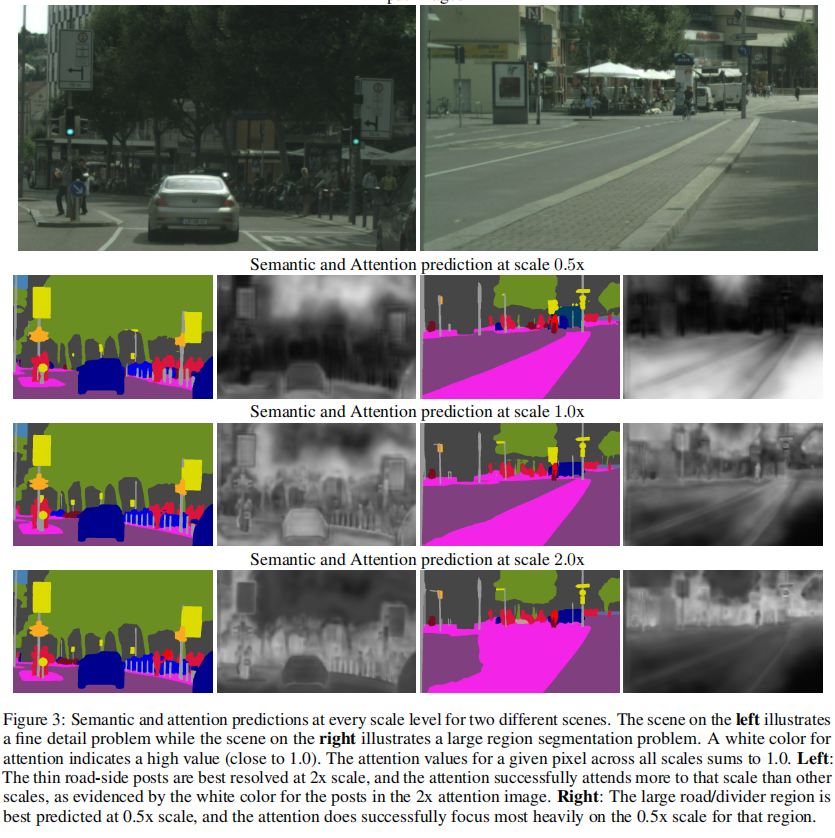
此外,我们还观察到,在基线平均多尺度方法中,简单地添加0.25x尺度对精度有害,因为它会导致IOU减少0.7,而对于我们的方法,添加额外的0.25x尺度会提高0.6的IOU。使用基线平均法,0.25x的预测是如此粗糙,当平均到其他尺度时,我们观察到车道标记、人洞、电话亭、路灯、交通灯和前后交通标志、自行车架等类别下降了1.5。预测的粗糙度影响了边缘和细节。然而,在我们提出的注意方法中,增加0.25倍的尺度可以使我们的结果提高0.6,因为我们的网络能够以最合适的方式应用0.25倍的预测,而避免在边缘周围使用它。这方面的例子可以在图3中观察到,对于左边图片中的精细目标,很少有0.5倍的预测,但是在2.0倍的尺度上存在非常强的注意信号。相反,对于右边非常大的区域,注意机制学会了最多地利用较低的尺度(0.5x),而很少利用错误的2.0x预测。
3.2.1 Single vs. dual-scale features
虽然我们所采用的体系结构从仅来自两个相邻图像尺度中较低部分的特征中获取注意力头(见图2),但我们实验用来自两个相邻图像尺度的特征来训练注意头。我们没有观察到在准确性上的显著差异,所以我们选择了一组特征。
4 Auto Labelling on Cityscapes
受最近关于图像分类任务[2]和[39]的自动标记工作的启发,我们采用了一种城市景观的自动标记策略,以提高有效的数据集大小和标签质量。在城市景观中,有20000张粗糙标记的图像和3500张精细标记的图像。粗图像的标签质量非常适中,并且包含大量未标记的像素,见图4。通过使用我们的自动标签的方法,我们可以提高标签的质量,从而有助于模型的IOU的提升。
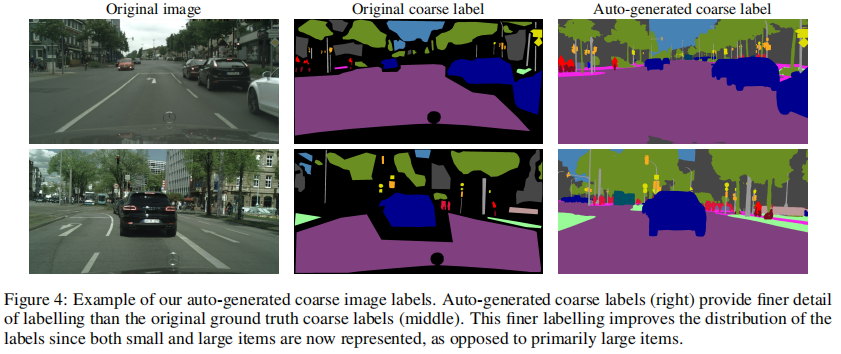
在图像分类中,一种常用的自动标记技术是使用软标签或者连续的标签,即教师网络为每个图像的每个像素的N个类中的每个类提供一个目标(软)概率。这种方法的一个挑战是磁盘空间和训练速度:存储标签大约需要3.2TB的磁盘空间:20000张图像2048 w1024 h19类4B=3.2TB。即使我们选择存储这样的标签,在训练中加载如此多的标签可能会大大减缓训练。
相反,我们采用了一种硬标签策略,即对于一个给定的像素,我们选择教师网络的顶级预测。我们基于教师网络输出概率对标签进行阈值化。超过阈值的教师预测将成为真正的标签,否则该像素将被标记为忽略类。在实践中,我们使用的阈值为0.9。
5 Results
5.1 Implementation Protocol
在本节中,我们将详细描述我们的实现过程。
Training details 我们的模型是在Nvidia DGX服务器上使用Pytorch[40]进行训练的,每个节点包含8个gpu,具有混合精度、分布式数据并行训练和同步批处理归一化。训练过程中,我们使用SGD做优化器,每个GPU的batch为1,动量为0.9,权重衰减为5e-4。我们应用“polynomial”学习率策略[41]。我们使用RMI[42]作为默认设置下的主要损失函数,并对辅助损失函数使用交叉熵。对于Cityscapes,我们使用poly指数为0.2,初始学习率为0.01,并在2个DGX节点上训练175个时代。对于Mapillary,我们使用的poly指数为1,初始学习率为0.02,并跨4个DGX节点训练200个时代。与在[29]中一样,我们在数据加载器中使用类均匀采样来对每个类进行等量采样,这有助于在数据分布不均匀时改善结果。
Data augmentation: 我们在输入图像上使用高斯模糊、颜色增强、随机水平翻转和随机缩放(0.5x-2.0x)来增强数据集的训练过程。我们使用的大小为2048x1024(Cityscapes),1856x1024(Mapillary)。
5.1.1 Results on Cityscapes
Cityscapes[43]是一个大型数据集,它在5000张高分辨率图像中的19个语义类。对于城市景观,我们使用HRNet-OCR作为主干,以及我们提出的多尺度注意方法。我们使用RMI作为主分割头的损失,但对于辅助分割头,我们使用交叉熵,因为我们发现使用RMI损失会导致训练中深处的训练精度降低。我们最好的结果是通过首先在更大的Mapillary数据集上进行预训练,然后在城市景观上进行训练。对于Mapillary预训练任务,我们不训练attention。我们最先进的城市景观配方是通过使用 train + val图像和自动标记的粗糙图像来实现的。在50%的概率下,我们从 train + val中采样,否则我们从自动标记的图像池中采样。在推理时,我们使用尺度={0.5、1.0、2.0}和图像翻转。
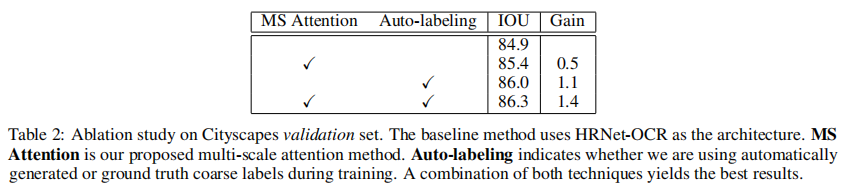
我们对Cityscapes验证集进行了消融术研究,如表2所示。多尺度注意比HRNet-OCR的平均池化的基线HRNet-OCR架构产生0.5%的IOU。自动标签法使基线提高了1.1%。将这两种技术结合在一起,总共可获得1.4%的IOU。
最后,在表3中,我们展示了我们的方法与Cityscapes test中其他表现最好的方法相比的结果。我们的方法得到了85.1分,这是所有方法中报告的最好的Cityscapes test分数,相比于上一个最好的IOU提升了0.6。此外,我们的方法在除三个类外的所有类别中都是最高的。一些结果在图5中可视化。

5.1.2 Results on Mapillary Vistas
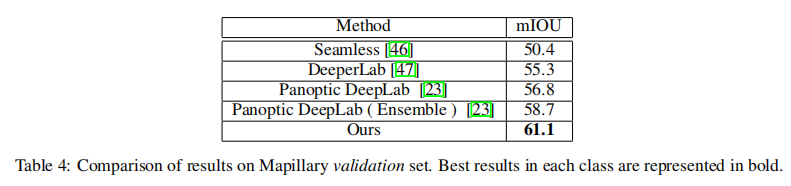
Mapillary Vistas[45]是一个大型数据集,包含25,000张高分辨率图像,label为66个对象类别。对于Mapillary,我们使用HRNet-OCR作为主干,以及我们提出的多尺度注意方法。因为Mapillary有非常高尺度和不同分辨率的图像,我们调整图像的大小,使图像的最长边2177,就像在[23]中做的那样。我们用经过ImageNet分类训练的HRNet的权重来初始化模型的HRNet部分。由于对Mapillary的66个类有更大的内存需求,我们将crop大小减少到1856x1024。在表4中,我们显示了我们的方法在Mapillary val上的结果。我们的基于单模型的方法达到61.1,比第二接近的方法[23]高2.4,后者使用模型集成实现58.7。
6 Conclusion
在这项工作中,我们提出了一种层次多尺度注意语义分割方法。我们的方法提高了分割精度,同时也提高了内存和计算效率,这两者都是实际关注的问题。训练效率限制了研究的完成速度,而GPU内存效率限制了一个crop size的训练规模,这也可能限制了网络的准确性。我们的经验表明,使用我们提出的方法在Cityscapes和Mapillary上有一致的改进。