转自:https://blog.csdn.net/teeyohuang/article/details/77250541

DeepLabV2对主要在V1的基础上做了一些改进。
1.回顾Atrous Convolution
Atrous Convolution 也就是V1那篇论文里面的hole algorithm,本篇论文依然先叙述了一下这个方法:
一维时,就如下这个公式所述,

The rate parameter r corresponds to thestride with which we sample the input signal.
r表征了要填进去的0的个数,个数为(r-1)个,所以标准的卷积是r=1,也就是不插0;
二维时如下图所示:

上面一行表示原来的一些方法比如FCN这种,图像的分辨率缩小了,就算增采样之后,最终也只能获取部分的像素点的位置信息。
下面一行,表示采用插了0的卷积核去对原图像进行卷积,尽管filter的size变大了,但是他们只考虑卷积核中非零的值,所以其实the number of filter parameters and the number of operations per position stay constant。
然后作者说的确可以使用一连串的Atrous Convolution来使网络最后输出的结果feature map的分辨率和原始图像的分辨率一样大,但是这样计算量就显得有点大,所以他们是采用了一种混合的方法:
…but this ends up being too costly. We have adopted instead a hybrid approach that strikes a good efficiency/accuracy trade-off, using atrous convolution to increase by a factor of 4 the
density of computed feature maps, followed by fast bilinear interpolation by an additional factor of 8 to recover feature maps at the original image resolution.
上面这段话的意思是,他们并不是把整个网络都运用成Atrous Convolution,而是既用了Atrous Conv, 也用了传统的思路—增采样。
所以他称之为混合的方法(a hybrid approach)。
具体来讲,就是只运用Atrous Conv使得feature map能够达到原来的密度的4倍就ok了,然后使用双线性插值法来进行插值处理(也就是简单的增采样),再把feature map放大8倍,这样就使得分辨率恢复到原来的大小了(4x8=32)。
(注,作者举这样说是因为他基于的VGG16Layer模型,这个模型的5个pooling层让图片总共缩小了2^5=32倍.详见DeepLabV1的论文,我上篇博文也讲了)
2、Atrous Convolution的变动
Atrous Convolution也能使得我们能扩大卷积核的感受野!
Atrous convolution with rate r introduces r-1 zerosbetween consecutive filter values, effectively enlarging the kernel size of a kxk filter to ke= k + (k - 1)(r - 1) without increasing the numberof parameters or the amount of computation.
然后作者提到有两种方法来实现Atrous Convolution:
①
The first is to implicitly upsample the filters by inserting holes (zeros), or equivalently sparsely sample the input feature maps
第一个是通过插入空洞(零)来隐式地对kernel进行上采样,或者等效稀疏地对输入特征图进行采样。他们在之前的工作中用的就是这种方法,比如DeepLabV1中用的就是这个方法。
②
to subsample the input feature map by a factor equal to the atrous convolution rate r, deinterlacing it to produce r2 reduced resolution maps, one for each of the r x r possible shifts.
对输入feature map进行降采样,降采样率设置为 atrous convolution rate r,对其进行去隔行操作以获得r^2大小的分辨率减小的maps,……
然后用这种方式进行操作,我们的卷积kernel就不用进行改变,还是用标准的kernel。
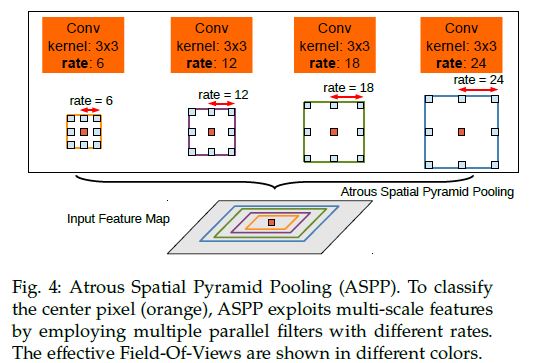
3、Multiscale ImageRepresentations using Atrous Spatial Pyramid Pooling
多尺度处理
这里他们也提及两个方法:
①
The first approach amounts to standardmultiscale processing.
第一个是标准的多尺度处理。我们使用共享相同参数的并行DCNN分支从多个(我们的实验中有三个)提取原始图像的重新定标版本的DCNN分数图。
We extract DCNN score maps from multiple(three in our experiments) rescaled versions of the original image usingparallel DCNN branches that share the same parameters.
他们从多个(他们的实验中是3个)经过重新缩放过的原始图像来提取DCNN得分图,利用多个并行的、共享相同参数的DCNN分支。
简单点说就是把原来的图像缩放一下得到几个尺寸不同的图,然后把这些图都各自送进相同的DCNN处理。
为了产生最终的结果,他们对各个分支的输出map都采用双线性插值的方法来恢复到原始图像的分辨率大小,然后融合他们,
融合的办法是对于每个点都取这些不同的map中的最大的那个值就ok。
②
The second approach is inspired by thesuccess of the R-CNN spatial pyramid pooling method.
第二中方法是收到R-CNN中的空间金字塔池化方法的启发:
这种方法显示,对于任意尺度的一块区域,都能通过重采样 在单一尺度提取的卷积特征 来准确的且有效的被分类。
因此他们提出了“atrousspatial pyramid pooling” (DeepLab-ASPP)
具体来说,就是使用多个不同采样率的atrous conv layers,被不同的采样率提取出的feature会进一步在各自独立的分支中进行处理,最后融合到一起,得到最终的结果。如图所示:
4、总结
所以DeepLabV2相较于V1来说,做了两个改动:
①atrous的方法改了一下;
②提出了ASPP方法,这个是重点,
做实验的对比如下:
图7,左侧是原来的单尺度处理,右侧是V2的多尺度处理
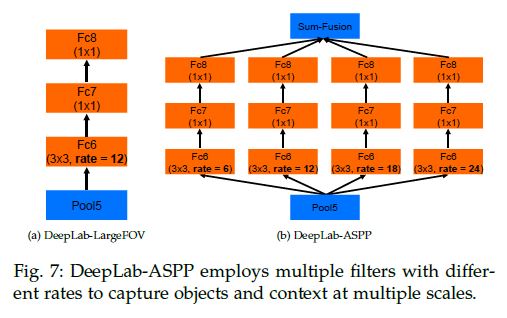
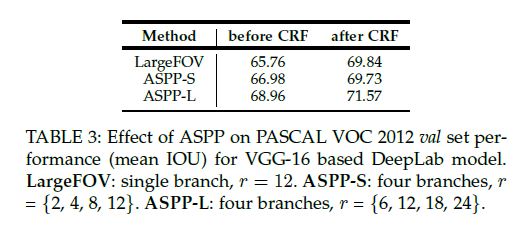
表3:显示了添加CRF前后准确度的提升,以及是否采用ASPP和ASPP的采样率的大小(也就是感受野的大小)对结果的影响。
然后就没了,谢谢观看。╰( ̄▽ ̄)╮