
文章目录
分类问题
- 问题介绍
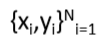
是输入,如词(下标或向量)、句子、文档等
是类别(C个类别的其中之一),例如:情感分析,命名实体识别,预测其他词等等
上面一共有N个样例
分类问题就是给定输入 ,判断其类别
训练方法
假设
是固定的,训练softmax或logistic回归参数
对于每个x,预测
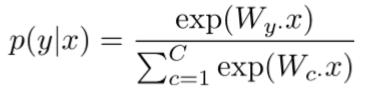
使用softmax和交叉熵(cross-entropy loss)
对于每个样例(x,y),我们的目标函数是最大化正确类别y的概率
或者我们可以最小化这个类别的负对数概率
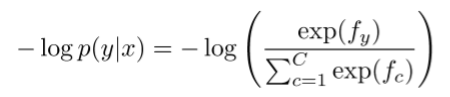
- 交叉熵损失介绍:来源于信息论,假设真实概率分布为p,我们的模型计算出来的概率分布为q,则交叉熵为
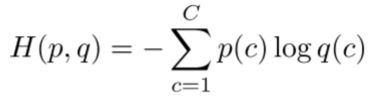
假设真实类别概率为1,其余概率为0,那么p=[0,…,0,1,0,…0]。因为向量p,所以上式留下的只有正确类别的负对数概率 - 在整个数据集上的交叉熵损失函数为
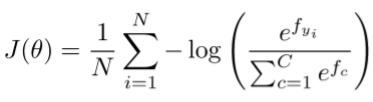
根据上面的介绍,可知,这里的log之后的softmax式子表示上上图中的q©,即我们模型计算出来的正确类别的概率,而p©我们将其认为是1. - 参数更新
我们一般将W表示为由行向量组成
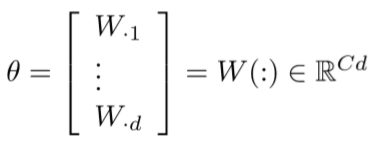
故通过其梯度就可以更新参数
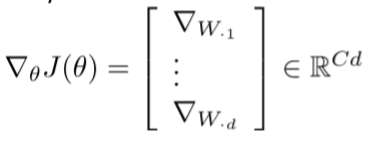
神经网络分类器
上述softmax和logistics回归只是对输入进行线性运算,只能在二维平面内画出直线分界线,在问题比较复杂,分类界线不是一条简单的直线时,误差就会很大

- 神经网络可以学习到更加复杂的函数和非线性的分界线
- 使用词向量分类
通常在NLP深度学习中:
我们同时学习参数矩阵W和词向量x
同时学习卷积参数和重新表示
词向量重新表示one-hot向量,通过将它们在中间隐藏层移动,从而使得最后能够用一个线性的softmax层分类器来进行分类

神经网络
神经网络的组成
- 一个人工神经元的计算


- 一个神经网络:同时运行多个logistics regressions
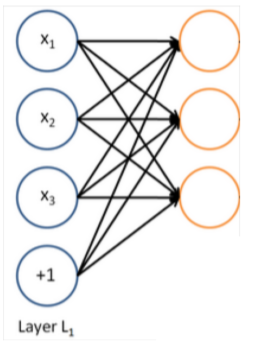
我们向网络输入一个向量,将会得到一个输出向量,但我们不需要提前决定这些向量将要预测什么变量
如果我们将这些结果又输入另一层逻辑回归中

神经网络计算
- 对于其中一层的计算如下图示例,其余层类似

- 为什么需要非线性的激活函数
因为若只有线性转换,不管多少层都只能对输入做一个线性变换,因为
命名实体识别(Named Entity Recognition (NER) )
任务介绍:

有两个任务,确定实体边界和实体类别,将其转化为序列标注问题,对字(word)进行分类,BIO标注法,即可解决以上两个问题
- 该任务的可能目的
跟踪文档中特定实体的提及
对于问答,答案一般都是命名实体
相同的技术可以被拓展用来填槽分类
Window classification
- idea:通过一个词周围的词(选定window)来对其分类
- 1.一个简单的方法是:平均在同一个window中的词向量,然后对其进行分类
问题:将会损失位置信息 - 2.训练一个softmax分类器,通过与c在同一个window中的词,来对c进行分类
- 1.一个简单的方法是:平均在同一个window中的词向量,然后对其进行分类
Binary classification with unnormalizedscores
Method used by Collobert& Weston (2008, 2011)
神经网络架构

中间层学习输入的词向量之间的非线性交互关系
- The max-margin loss
idea:确保正例的window分数比负例的window分数足够大

虽然这个函数是不可微的,但是连续,所以可以使用SGD - 与word2vec类似,对每个正样例也采样几个负样例
- 使用SGD
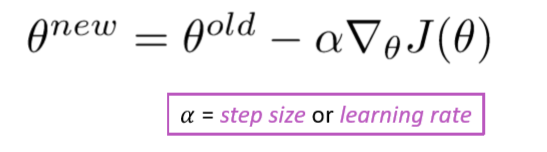
- 如何计算后一项(除去学习率)
手算(本课内容)
算法:后向传播算法(下节课内容)
计算梯度
手算
基本计算方法
- 一个输出一个输入的函数
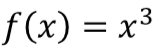
计算结果如下
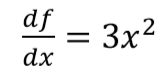
- 一个输出,n个输入
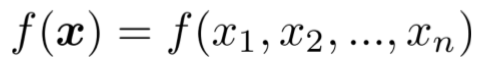
结果如下
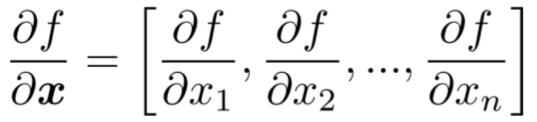
- 雅可比矩阵:梯度的推广
n个输出,n个输入
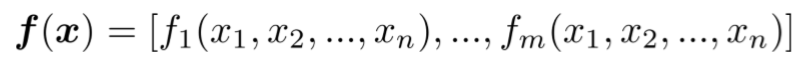
结果如下:

- 链导法则(Chain Rule)
对于一个变量的函数
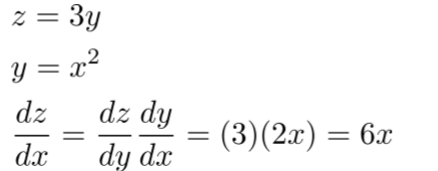
对于多个变量

- 对每个元素使用激活函数,求解梯度的例子

- 其余公式

神经网络中具体的计算

- 计算:实际上需要计算关于loss的梯度,这里我们为了简便起见,计算s的梯度作为示例
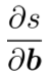
计算过程如下

- 计算
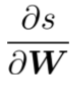
使用链导法则

具有重复过程,可以避免重复计算,如下

被称为局部错误信号(local error signal )
关于矩阵的导数(输出形状)
的形状是什么样子的?
-
一个输出,nm个输入:1× nm -->不方便SGD更新参数( )
-
相反,遵循惯例,梯度的形状组织成参数的形状

-
上文中得出
应等于x,因为
所以结果应为
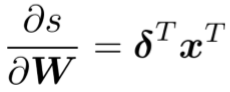
是局部错误信号( local error signal),(中文为百度翻译)
是本地输入信号(local input signal) -
为何要转置
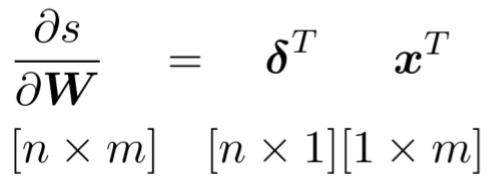
粗略的回答:这使得维度满足要求
详细解释:每一个输入得到每一个输出–>得到了外积

即如右下图,求关于参数矩阵
的梯度,则结果的形状应为2 × 3,对于
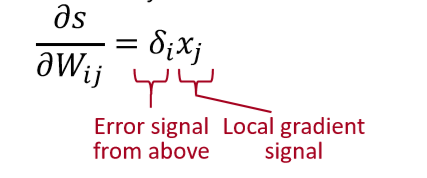
来说,在该网络中与它有关的函数有:
故对其求导为
如上图所示第一行第一列元素。其余元素求解过程相同
What shape should derivatives be?
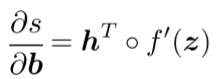
是一个行向量,但是惯例认为梯度应该是一个列向量,因为b是一个列向量
- 分歧:雅可比形式使得链式法则容易,形状惯例使得SGD实现容易
我们期望答案遵循形状惯例,但是雅可比形式容易计算答案 - 两种选择
- 1.尽可能使用雅可比形式,最后根据惯例进行整形。这就是我们刚做的,但在最后将 进行了转置,来使得derivative变为一个列向量,即
- 2.总是遵循惯例:查看维度以确定何时对其进行转置和/或重新排序。
反向传播(下一节)
- 算法高效地计算梯度
- 将我们刚才手算的过程转化为一个算法
- 使用深度学习框架:TensorFlow,Pytorch等
