传统的文本分类方法主要是基于统计的机器学习方法,使用向量空间模型(vector space model,VSM)或者叫做词袋模型(bag of words),抽取文本中的单词特征,并利用TF-IDF方法计算每个单词的权重。这样,得到一个单词-文档矩阵,矩阵的行为不同的文档,矩阵的列为不同的单词特征。将这个矩阵输入至相应的文本分类器(e.g. SVM,NB,...),就可以实现文本的分类任务。这类方法使用的特征是单词的出现与否(较强一点是单词的词频),忽略了单词的顺序、单词构成的词组(n-grams)和单词与单词之间的语义相似度关系。在工程实践中实现较为容易,但是缺点也较为明显。
本文所提到的方法,将文本转换为类似图像的矩阵,采用CNN来完成文本分类任务,则更多的利用到单词的顺序、和语义特征。笔者对原论文[1]进行简要介绍,并参考文献[2],对本CNN网络超参数的影响进行分析,并在最后给出调参的实践方法论。
1. 网络结构
首先祭出这张网络结构图,这是作者kim Yoon给出的结构图。

网络自左至右分别为输入层-卷积层-池化层-全连接层。
1.1 输入层:
输入层为单词矩阵,这个矩阵中,行向为每个单词对应的单词表示,纵向为句子的所有单词构成。图中句子为:wait for the video and do n't rent it. ,可以明白,句子的每个单词构成了矩阵的一行。那么,每一行的内容是什么呢?这里可以说是句子中的单词表示,或谓之单词嵌入(word embedding)。单词嵌入是带有单词语义的表示方法,不同于one-hot编码(类似于vsm和bag of words),单词嵌入得到的向量是稠密的,相似的两个单词向量在希尔伯特空间中的距离较小,反之较大。作者使用的单词向量是预训练的,方法为fasttext得到的单词向量,当然也可以使用word2vec和GloVe方法训练得到的单词向量。
实践上,作者在这里使用了两个通道,一是static的,在训练过程中不会发生改变,另一种是non-static的,将之设为可训练的,在训练过程中可以改变。单词向量的长度为100维等长的向量,设句子中的单词数相等,采用padding的方法,对较长的句子进行截断,对较短的句子采用填0方法补充。
1.2 卷积层:
作者使用了卷积的方法来提取文本特征,这也是该网络结构的核心。卷积核的size分别为2,3,4,其含义为在2个3个4个单词上作为一个窗口进行计算。不同于图像,文本的卷积核是只有长度没有宽度的。这样说吧,假设单词向量的长度为100维,单词数量为10,那么在3个单词上进行卷积的卷积核尺寸为100*3,步长为1,那么得到的结果为一个8*1的向量。
作者使用3种卷积核,size为2,3,4,数量分别为100,100,100,总共为300个卷积核。
1.3 池化层:
池化层是直接连接在卷积层之后的。上面说到300个卷积核,共得到300个卷积之后的向量,池化则是对每个向量进行处理。作者采用最大池化策略(max-pooling),具体的说就是对这300个向量中的每个向量,取维度中的最大值。这个的主要想法是取出最重要的特征。池化的结果是得到300个值,可以拼接为300维的向量。
1.4 全连接层:
这里的全连接层接受300维的向量,设n为类别数目,则全连接层的神经元数量为n。通过全连接层,起到分类器的作用,输出结果经过softmax方法,就可以得到各个类别的可能性概率。
下图是文献[2]中给出的网络结构图,参数上不同但结构上是一致的。可能更有助于理解吧。
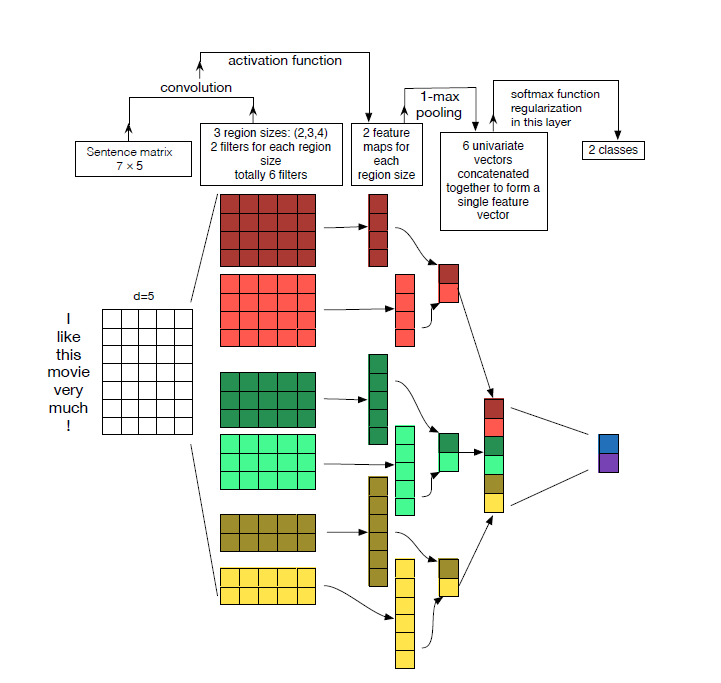
2. 实验结果
首先给出数据集:

作者在上述数据集上进行实验。实验中作者给出四种变体。CNN-rand:随机初始化单词向量;CNN-static:单通道不可变的预训练单词向量;CNN-non-static:单通道可变的预训练单词向量;CNN-multichannel:双通道可变与不可变相组合的预训练单词向量。
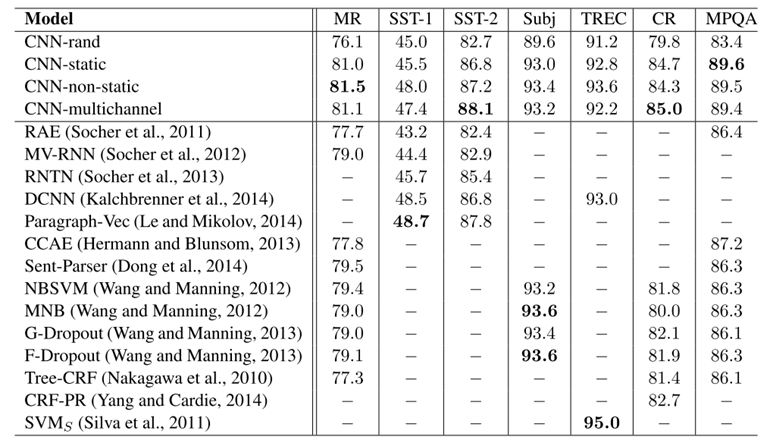
可以看到,在作者的实验结果上看,好于之前的所有分本分类方法。
3. 超参数的分析
重头戏来了。文献[2]对超参数进行了十分详尽的实验,对每个超参数的具体影响进行了考察。我想还是不要展开了,确实很详尽.......这里仅仅给出baseline参数,并给出结论和实践方法论。

调参的实践方法:
(1)以baseline参数作为初始设置
(2)使用单词向量来进行初始化,好于one-hot和随机
(3)寻找最优的卷积核大小值,并适当组合值附近的卷积核
(4)寻找最优的卷积核数量(100~500),调整dropout权重(0~0.5),较弱的l2-norm限制
(5)尝试不同的激活函数(ReLU、tanh和Iden)
(6)1-max pooling
(7)在改变卷积核数量时,重新调整dropout
(8)评价性能时使用CV,多次重复取平均值
4. 结语
作者使用的基于CNN的文本分类方法,使用单词向量表示来作为输入。从特征工程的角度上讲,我认为和传统的文本特征相比,增加了单词的语义特征,卷积核的使用类似于n-grams特征,增加了多种n-grams信息。总之,这是一篇很经典的利用CNN来处理文本分类问题的论文,后来的CNN文本分类可能都有借鉴这篇论文。最后,以上观点只代表笔者所饰演的笔者的观点,与笔者本人无关。如有错误,不吝赐教,不胜感激。
传送门:
大佬博客:http://www.wildml.com/2015/12/implementing-a-cnn-for-text-classification-in-tensorflow/
代码实现:https://github.com/dennybritz/cnn-text-classification-tf
REFERANCE:
1. Kim Y. Convolutional Neural Networks for Sentence Classification[J]. Eprint Arxiv, 2014.
2. Zhang Y, Wallace B. A Sensitivity Analysis of (and Practitioners' Guide to) Convolutional Neural Networks for Sentence Classification[J]. Computer Science, 2015.