ImageNet Classification with Deep Convolutional Neural Networks
基于深度卷积神经网络的ImageNet分类
发表时间:2012;
发表期刊/会议:NeurIPS;
贡献:提出AlexNet,2012年ImageNet大规模视觉挑战赛中夺冠,奠定了深度学习在计算机视觉领域中的地位;
0 摘要
【任务】训练了一个大型的深度卷积神经网络,将ImageNet LSVRC-2010比赛中的120万张高分辨率图像分为1000个不同的类别;
【效果】在测试数据上,我们实现了top-1和top-5的错误率分别为37.5%和17.0%;
【网络】该神经网络有6000万个参数和65万个神经元,由5个卷积层组成,其中一些层后面是max-pooling层,还有3个完全连接层,最后是1000分类的softmax;
【创新】为了使训练更快,使用了非饱和神经元ReLU和非常有效的GPU实现卷积运算;
【创新】为了减少全连接层中的过拟合,采用了一种最近开发的正则化方法,称为“dropout”,该方法被证明非常有效;
【效果】还在ILSVRC-2012比赛中输入了该模型的一个变体,并获得了15.3%的前5名的获胜测试错误率,而第二名的测试错误率为26.2%。
1 简介
目前的目标识别方法主要利用机器学习方法;提高性能——更多的数据、防止过拟合;
一个强大的模型:卷积神经网络(CNN);
CNNs的运算代价非常高——GPU加速;
本文贡献:
在ILSVRC-2010和ILSVRC-2012比赛中使用的ImageNet子集上训练了迄今为止最大的卷积神经网络之一,并在这些数据集上获得了迄今为止报道过的最好的结果。
- (加速训练)高度优化的GPU实现,用于2D卷积和训练卷积神经网络中固有的所有其他操作;
- (提高性能)网络包含了许多新的和不寻常的特征,这些特征提高了它的性能,减少了它的训练时间;
- (防止过拟合)网络的规模使得过拟合成为一个重要的问题,即使有120万个标记的训练示例,所以我们使用了几种有效的技术来防止过拟合;
本文网络包含5个卷积层和3个全连接层,网络的深度似乎很重要:本文发现删除任何卷积层都会导致性能较差(现在来看这个结论有一些局限性);
2 数据集
ImageNet是一个包含超过1500万张标记高分辨率图像的数据集,属于大约22000个类别。
ILSVRC使用ImageNet的一个子集,在1000个类别中每个类别大约有1000张图像。总共大约有120万张训练图像、5万张验证图像和15万张测试图像。
ILSVRC-2010是ILSVRC中唯一一个测试集标签可用的版本,所以我们在这个版本上进行了大部分实验。由于我们也在ILSVRC-2012竞赛中输入了我们的模型,在第6节中,我们也报告了我们在这个版本的数据集上的结果,其中测试集标签不可用。在ImageNet上,通常报告两种错误率:top-1和top-5,其中top-5错误率是测试图像中正确标签不在模型认为最可能的五个标签中的比例。
ImageNet图像大小不一,而网络需要固定的输入大小,因此,需要将图像采样到256 × 256的固定分辨率;
采样方法:给定一个矩形图像,首先重新缩放图像,使较短的边的长度为256,然后从结果图像中裁剪出中央的256×256patch。在像素的原始RGB值上训练网络(End-To-End,直接输入原始图像/文本,不做任何特征提取)
3 架构
3.1 ReLU Nonlinearity
标准的方法一般都使用tanh或者Sigmoid,但是在梯度下降的训练时间方面,这些饱和非线性比非饱和非线性f(x) = max(0, x)慢得多。将具有这种非线性的神经元称为整流线性单元(Rectified Linear Units, ReLUs);
使用ReLUs的深度卷积神经网络的训练速度比使用tanh单位的等效速度快几倍,如图1所示:

3.2 Training on Multiple GPUs
将网络分布在两个GPU上,采用的并行化方案本质上是把一半的内核(或神经元)放在每个GPU上,还有一个额外的技巧:GPU只在特定的层进行通信;
这意味着,例如,第3层的内核从第2层的所有内核映射中获取输入。然而,第4层的内核只从位于同一GPU上的第3层的内核映射中获取输入。选择连接模式是交叉验证的一个问题,但这允许我们精确地调整通信量,直到它是计算量的一个可接受的部分。
3.3 Local Response Normalization
ReLU有一个理想的特性,它不需要输入归一化来防止它们饱和;
然而,本文发现下面的局部归一化方案更有助于泛化;用 a x , y i a^i_{x,y} ax,yi表示神经元通过在(x, y)位置应用核i计算的活动,然后应用ReLU非线性,响应归一化活动 b x , y i b^i_{x,y} bx,yi由表达式给出:

n:同一个位置下与该位置相邻的内核映射的数量;
N:该层中核的总数;
常数k, n, α和β是超参数,其值由验证集确定,k = 2, n = 5, α = 10−4,β = 0.75;
3.4 Overlapping Pooling
CNN中的池化层总结了同一内核映射中相邻神经元组的输出。传统上,相邻池化单元总结的邻域不重叠。池化层可以被认为是由间隔s个像素的池化单元网格组成,每个单元汇总一个大小为z × z的邻域,以池化单元的位置为中心;
- 如果设置s = z,就得到了在CNN中常用的传统池化(不重叠池化、传统池化);
- 如果设置s < z,就得到重叠池化。这是本文在整个网络中使用的,s = 2和z = 3(重叠池化);
与非重叠方案s = 2, z = 2相比,该方案将top-1和top-5的错误率分别降低了0.4%和0.3%,后者产生了相同维度的输出。通常在训练过程中观察到,重叠池化的模型发现过拟合稍微困难一些。
3.5 Overall Architecture
如图2所示,AlexNet一共包含8层,前5层是卷积层,后三个是全连接层,最后一层连接1000类的softmax;
CNN布置在两块GPU上;
第2、4、5层的卷积内核只连接前一层位于同一GPU上的结果(没有GPU直接的通信),第3层卷积层的内核连接第二层所有内核的结果(GPU直接通信,第一个黑色箭头所指位置);
全连接层中的神经元与前一层中的所有神经元连接(GPU之间的通信,第二个黑色箭头所指位置);
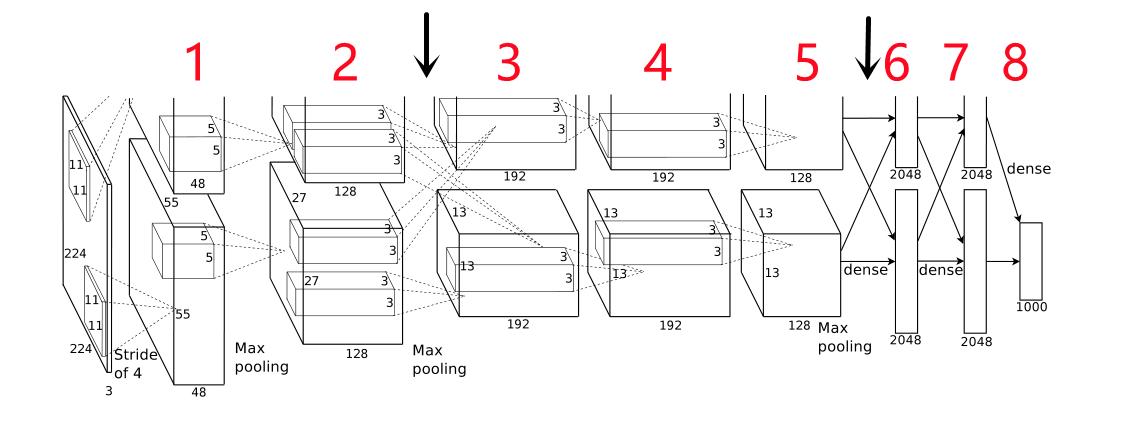
- 输入:224 * 224 * 3;
- (第一层)96个大小为11 × 11 × 3的核,stride = 4;
- (第二层)256个大小为5 × 5 × 48的核, stride = 1;
- (第三层)384个大小为3 × 3 × 256的核,stride = 1;
- (第四层)384个3 × 3 × 192大小的核,stride = 1;
- (第五层)256个3 × 3 × 192大小的核,stride = 1;
- (第六层)全连接层;
- (第七层)全连接层;
- (第八层)全连接层,接softmax;
# AlexNet网络架构
AlexNet(
(conv): Sequential(
# 第一层
(0): Conv2d(1, 96, kernel_size=(11, 11), stride=(4, 4))
(1): ReLU()
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
# 第二层
(3): Conv2d(96, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU()
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
# 第三层
(6): Conv2d(256, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU()
# 第四层
(8): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU()
# 第五层
(10): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU()
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
# 第六层
(0): Linear(in_features=6400, out_features=4096, bias=True)
(1): ReLU()
(2): Dropout(p=0.5, inplace=False)
# 第七层
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU()
(5): Dropout(p=0.5, inplace=False)
# 第八层 1000分类
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
4 Reducing Overfitting
本文的神经网络架构有六千万个参数。尽管ILSVRC的1000个类使每个训练例对从图像到标签的映射施加了10位约束,但这不足以在没有相当过拟合的情况下学习这么多参数。下面,将描述对抗过拟合的两种主要方法。
4.1 Data Augmentation
减少图像数据过拟合的最简单和最常见的方法是使用标签保留转换人为地扩大数据集。本文采用了两种不同的数据增强形式:
- 生成图像平移和水平翻转,从256×256图像中提取随机的224 × 224patch;
- 改变训练图像中RGB通道的强度,在整个ImageNet训练集中对RGB像素值集执行PCA;
4.2 Dropout
最近引入的技术,称为“dropout”[10],以0.5的概率将每个隐藏神经元的输出设置为零。以这种方式被“丢弃”的神经元不参与正向传递,也不参与反向传播。所以每次输入出现时,神经网络都会对不同的架构进行采样,但所有这些架构都共享权重。
本文在图2的前两个全连接层中使用dropout。在没有dropout的情况下,我们的网络表现出严重的过拟合。Dropout大约使收敛所需的迭代次数翻了一番。
5 Details of learning
用随机梯度下降(stochastic gradient descent, SGD)训练我们的模型,batch size为128,动量为0.9,权重衰减为0.0005。我们发现,这种少量的权重衰减(L2正则化)对模型的学习很重要。换句话说,这里的权值衰减不仅仅是正则化的:它减少了模型的训练误差。权重w的更新规则为:

i:迭代次数;
v:动量;
ε:学习率;
< ∂ L ∂ w ∣ w i > D i <\frac{∂L} {∂w} |_{w_i}>_{D_i} <∂w∂L∣wi>Di:第i次的目标函数关于w的倒数 D i D_i Di的平均值;
使用标准差为0.01、均值为0的高斯分布来初始化各层的权重;
使用常数1来初始化了网络中的第2、4、5个卷积层以及全连接层中的隐含层中的所有偏置参数,种初始化权重的方法通过向ReLU提供了正的输入,来加速前期的训练;
使用常数0来初始化剩余层中的偏置参数;
对所有层都使用相同的学习率,在训练过程中又手动进行了调整;
6 Results


6.1 Qualitative Evaluations定性评估
图3显示了由网络的两个数据连接层学习的卷积内核。该网络已经学习了各种频率和方向选择的内核,以及各种颜色的斑点;
请注意这两个GPU所表现出的专门化,GPU 1上的内核在很大程度上是颜色不可知的,而GPU 2上的内核在很大程度上是特定颜色的。这种专门化发生在每次运行期间,并且与任何特定的随机权重初始化(对gpu重新编号取模)无关。

7 Discussion
本文的结果表明,一个大型的深度卷积神经网络能够使用纯监督学习在高度具有挑战性的数据集上实现破纪录的结果。值得注意的是,如果去掉一个卷积层,的网络性能就会下降。例如,删除任何中间层都会导致网络top-1性能损失约2%。所以深度对我们的研究结果非常重要。
为了简化实验,本文没有使用任何无监督的预训练,即使期望它会有所帮助,特别是如果获得足够的计算能力来显著增加网络的大小,而没有获得相应增加的标记数据量;
Future work:希望在视频序列上使用非常大且深度的卷积网络,其中时间结构提供了非常有用的信息,而这些信息在静态图像中是缺失的或不太明显的;