版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_37993251/article/details/88978817
Lecture 3 – Neural Networks
1. Course plan: coming up

Homeworks

A note on your experience!
Lecture Plan

2. Classification setup and notation

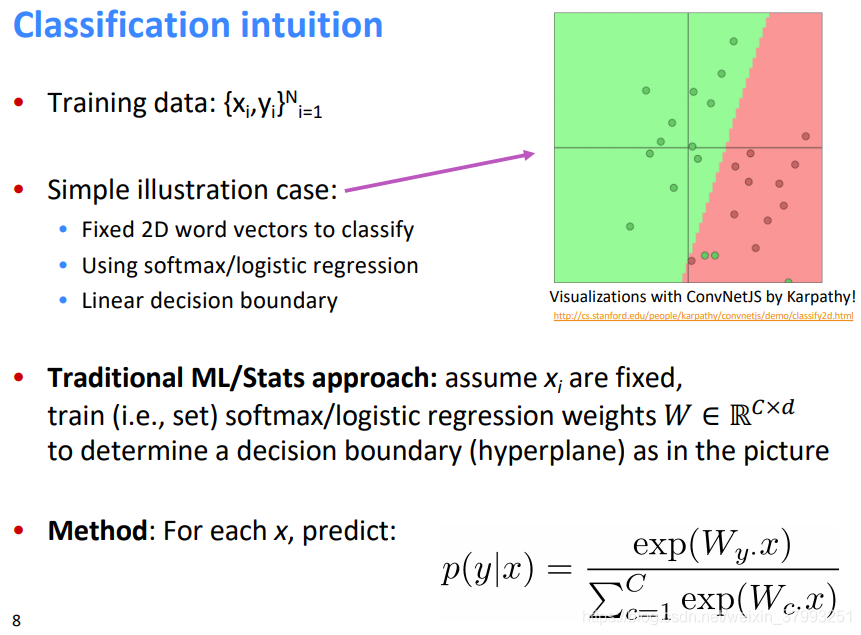
Classification intuition
Details of the softmax classifier

Training with softmax and cross-entropy loss

Background: What is “cross entropy” loss/error?

Classification over a full dataset

Traditional ML optimization

3. Neural Network Classifiers
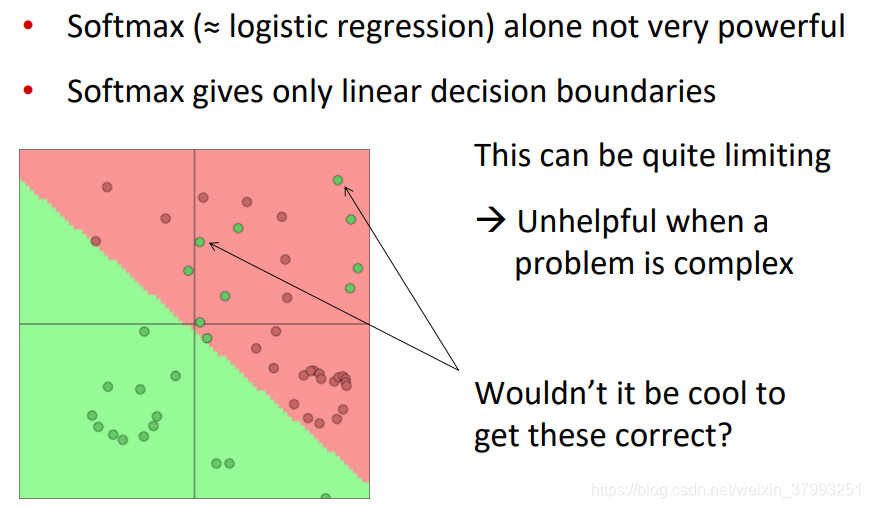
Neural Nets for the Win!
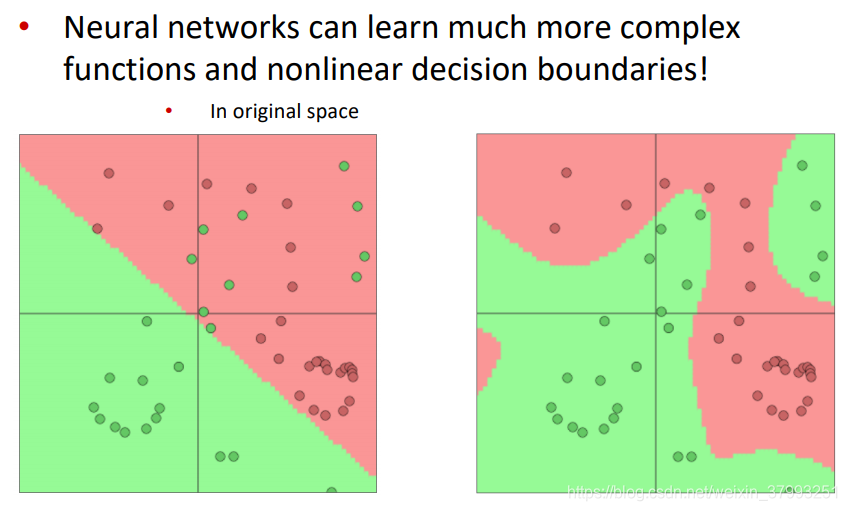
Classification difference with word vectors

Neural computation
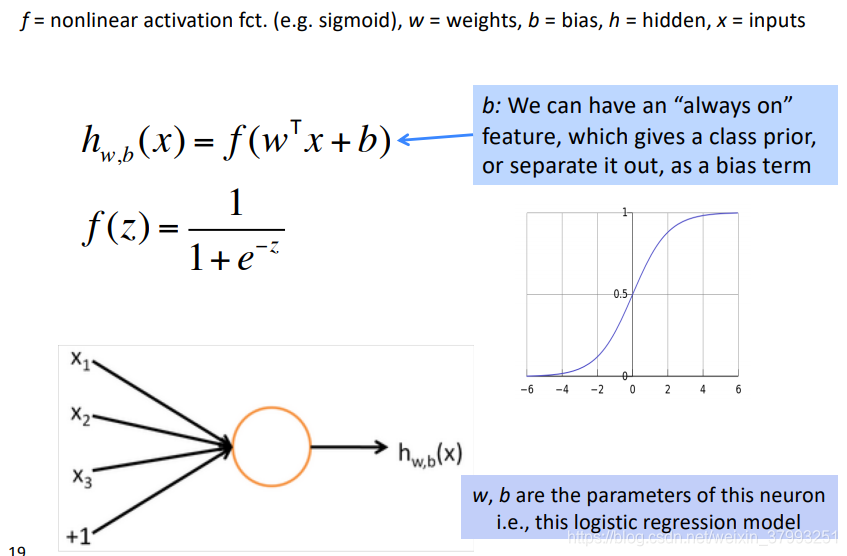
An artificial neuron

A neuron can be a binary logistic regression unit
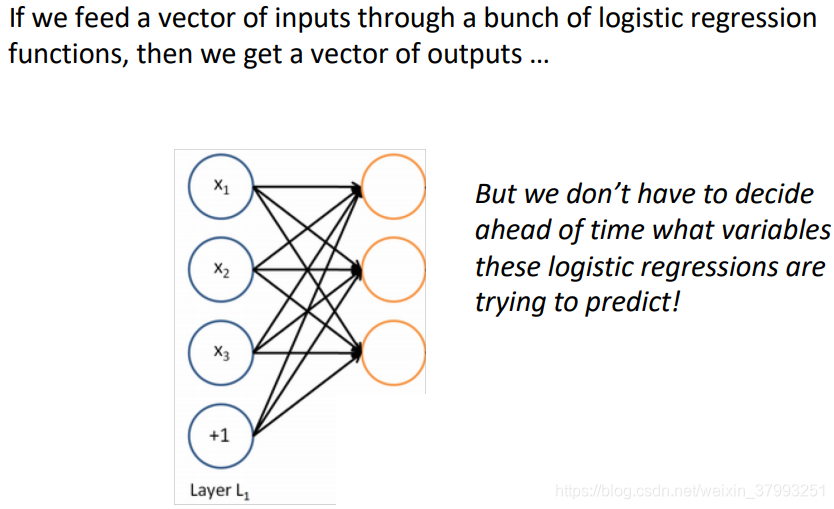
A neural network = running several logistic regressions at the same time
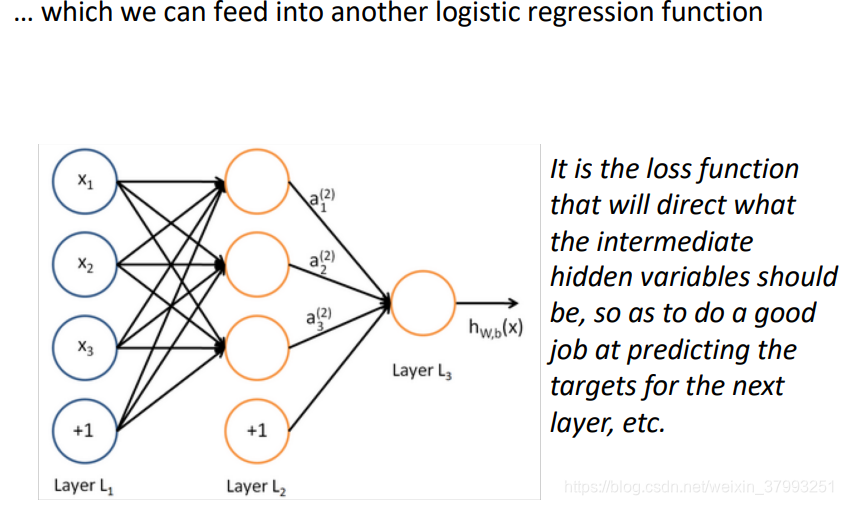

Matrix notation for a layer

Non-linearities (aka “f ”): Why they’re needed

4. Named Entity Recognition (NER)

Named Entity Recognition on word sequences

Why might NER be hard?

5. Binary word window classification

Window classification

Window classification: Softmax

Simplest window classifier: Softmax

Binary classification with unnormalized scores

Binary classification for NER Location

Neural Network Feed-forward Computation

Main intuition for extra layer
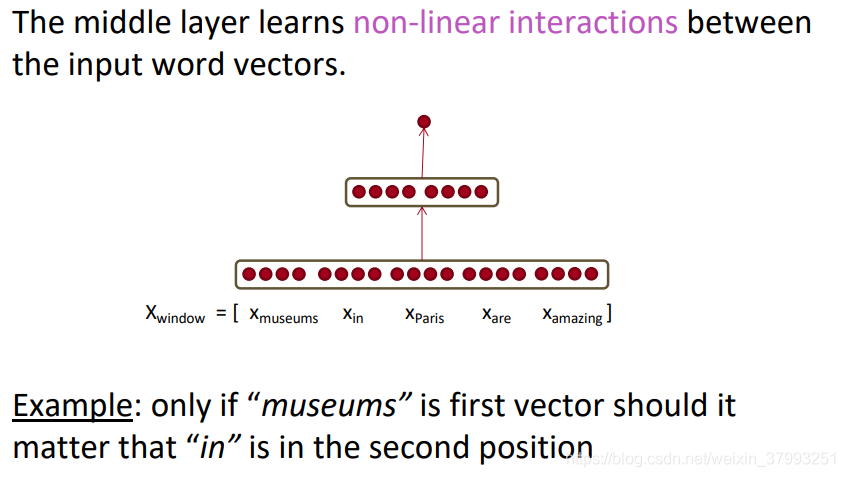
The max-margin loss


Simple net for score

Remember: Stochastic Gradient Descent

Computing Gradients by Hand

Gradients


Jacobian Matrix: Generalization of the Gradient

Chain Rule

Example Jacobian: Elementwise activation Function
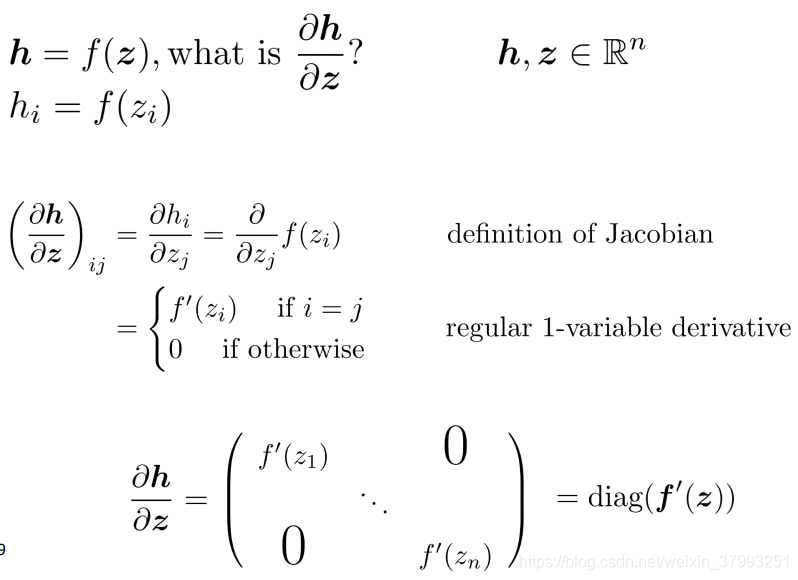
Other Jacobians

Back to our Neural Net!
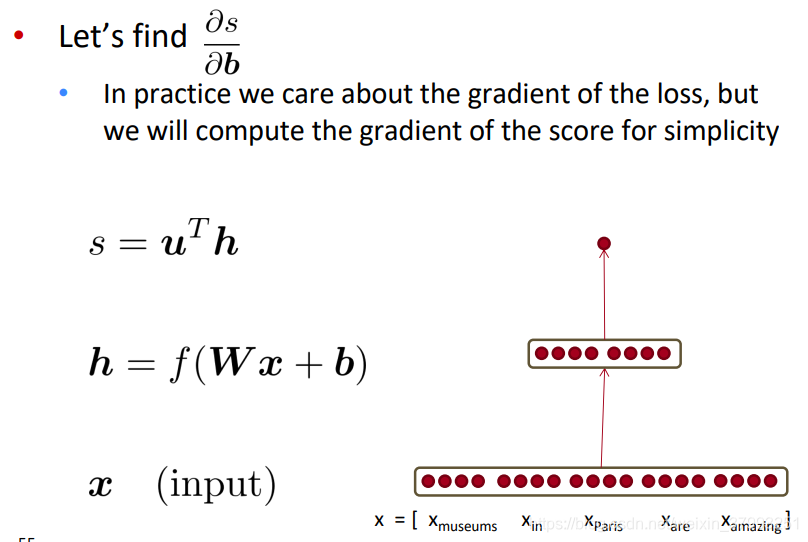
1. Break up equations into simple pieces
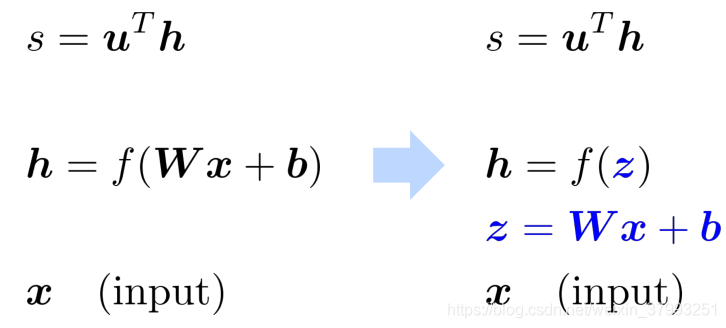
2. Apply the chain rule
3. Write out the Jacobians

Re-using Computation


Derivative with respect to Matrix: Output shape

Derivative with respect to Matrix

Why the Transposes?


What shape should derivatives be?


Next time: Backpropagation
