abstract
在预先训练好的词向量训练CNN
特定任务的词向量有更好的效果
1 介绍Introduction
深度学习:CV,SR(计算机视觉,语音识别)
在自然语言处理中,关于深度学习的工作大都涉及学习词向量代表。
1-V的编码的向量通过一个隐含层投影到底维空间,这个空间可以捕获语义特征,在这个密集表示中,语义近的词距离近,距离计算可以是欧式距离,余弦距离。
Originally invented for computer vision, CNN models have subsequently been shown to be effective for NLP and have achieved excellent results in semantic parsing (Yih et al., 2014), search query retrieval (Shen et al., 2014), sentence modeling (Kalchbrenner et al., 2014), and other traditional NLP tasks (Collobert et al., 2011)
2 模型Model


2.1 规则化Regularization

3 实验Experimental
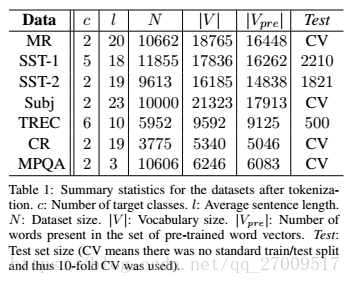
3.1 超参数和训练Hyper-parameters and Training

3.2 训练好的词向量Pre-trained Word Vectors
使用100 billion words from Google News,300维
没有出现的词随机初始化
3.3 模型变体Model Variations
CNN-rand:随机初始化,训练过程改变
CNN-static:由word2vec初始化,训练过程不变
CNN-non-static:word2vec训练好的向量调整好fine-tuned
CNN-multichannel:两个word2vec的词向量,每一种词向量都当做一个通道,每个滤波器都在不同的词向量上提取特征,但是梯度只在其中的一个通道中发生,所以模型可以调整其中一种词向量,而另一个保持不变。
4 结果和讨论Results and Discussion
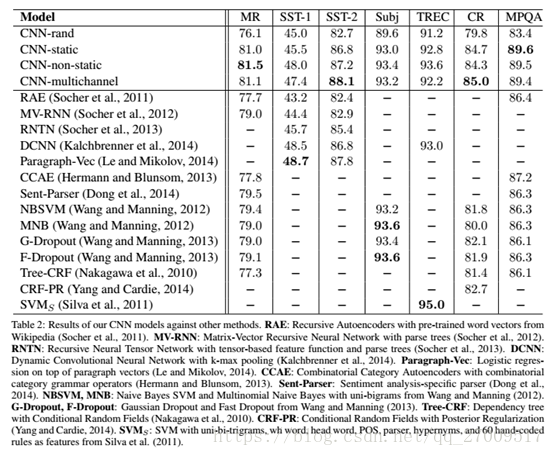
CNN-rand:表现不太好
CNN-static:好
CNN-non-static:很好
4.1 多通道和单通道模型Multichannel vs. Single Channel Models
希望:多通道好过单通道,多通道可以避免过拟合。
结果:混合
4.2 不改变和改变词向量代表Static vs. Non-static Representations
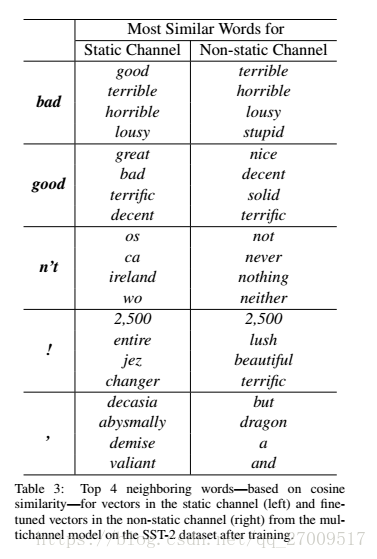
single channel non-static:
多通道模型可以调整非静态通道获得更好的结果。例如
good与bad更相似,语法是相等的,
调整好的非静态通道不是这样
nice和great更相似
4.3 Observations
5 结论Conclusion