
文章目录
- The spectrum of language in CS
- Building on Word Vector Space Models
- How should we map phrases into a vector space?
- Recursive Neural Networks for Structure Prediction
- Version 2: Syntactically-Untied RNN
- Version 3: Compositionality Through Recursive Matrix-Vector Spaces
- Version 4: Recursive Neural Tensor Network
- Version 5: Improving Deep Learning Semantic Representations using a TreeLSTM
- 使用树结构的几个场景
- 广告
- 总结
如何完成project

The spectrum of language in CS

- 左上角是一个艺术品,袋子表示词袋模型,袋子里装着词。将词摔下来就相当于把词映射到不同位置上,词向量模型。右边是语言的结构表示
Semantic interpretation of language – Not just word vectors
我们如何理解更大短语的含义
- The snowboarder is leaping over a mogul
- A person on a snowboard jumps into the air
The snowboarder 在语义上相当于 A person on a snowboard,但它们的字长不一样
- 人们之所以可以理解 A person on a snowboard ,是因为 the principle of compositionality 组合原则
- 人们知道每个单词的意思,从而知道了 on a snowboard 的意思
- 知道组件的含义并将他们组合成为更大的组件
人们通过较小元素的语义组合来解释较大的文本单元 - 其他事物也有很多组合关系,比如机械和图片中


- 语言理解 - 和人工智能 - 需要能够通过了解较小的部分来理解更大的事物
- Noam Chomsky 提出语言具有递归性,能够将语言中的一些部分递归组合在一起是人类区别其他智能生物的一个特征
Are languages recursive?
- 认知上有点争议(需要前往无限)
- 但是:递归对于描述语言是很自然的
- [The person standing next to [the man from [the company that purchased [the firm that you used to work at]]]]
- 包含名词短语的名词短语,包含名词短语
- 它是语言结构的一个非常强大的先验

Building on Word Vector Space Models

- 我们如何表示更长短语的意义呢?
- 将它们映射到相同的向量空间
How should we map phrases into a vector space?

- 基于组合原则,使用单词的含义和组合他们的规则,得到一个句子的含义向量,需要知道
- 词的含义
- 组合的规则
- 这部分的模型能够同时学习解析树以及组合向量表示
Constituency Sentence Parsing: What we want

Learn Structure and Representation

Recursive vs. recurrent neural networks

- 递归神经网络需要一个树结构
- 循环神经网络不能捕获没有前缀上下文的短语含义(即RNN每个时间步的输出都是之前所有词的总和),并且在得到的最终向量中含有太多最后一个词的含义。
- 因此递归神经网络更适合
Recursive Neural Networks for Structure Prediction

- 输入:两个候选的子节点的表示
- 输出:
- 两个节点被合并后的语义表示
- 新节点的合理程度
Recursive Neural Network Definition

- 将 和 拼接起来,经过一个线性变换,再加个偏置,最后经过非线性变换得到两者混合后的表示。
- 使用混合后的表示与一个矩阵相乘得到混合表示的分数
Parsing a sentence with an RNN (greedily)




- 相邻的两两结合,每次选择得分最高的进行 merge,每次 merge 之后,把 merge 得到的部分当作一个整体,继续两两结合。
Max-Margin Framework -Details
- 一个解析树的分数是所有节点得分的综合
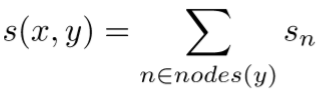
- 其中 x 是句子,y 是解析树
- 与 max-margin 解析类似(Taskaret al. 2004),一个受监督的 max-margin 目标方程
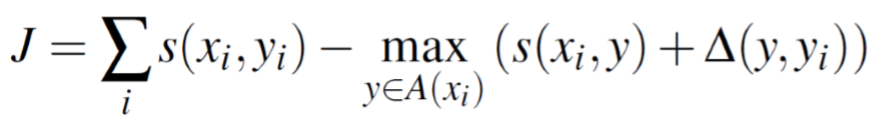
- loss 惩罚所有的不正确项
- 结构搜索
是贪婪的(每次加入最佳节点)
- 使用 Beam search
Scene Parsing

- 场景图像的含义也是小区域的一个函数
- 它们作为部分如何组合成大的物体
- 这些物体如何交互
Algorithm for Parsing Images
与NLP中的递归神经网络相同

(Socher et al. ICML 2011)
Multi-class segmentation

Backpropagation Through Structure
Introduced by Goller& Küchler(1996)
- 基本上与一般的反向传播相同
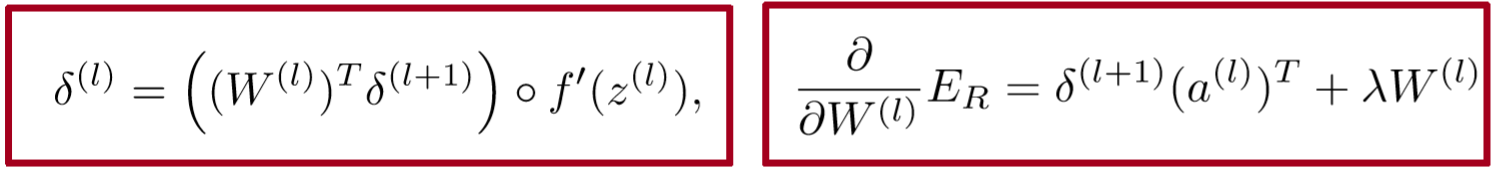
- 将所有节点的 W 的导数加起来(就像 RNN)
- 在每个节点(解析树中)处拆分导数
- 将来自 父节点的错误信息与该节点自身的错误信息加起来
BTS: 1) Sum derivatives of all nodes
可以假设每个节点的 W 都不同,计算出来是相同的
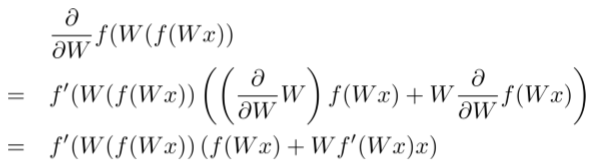
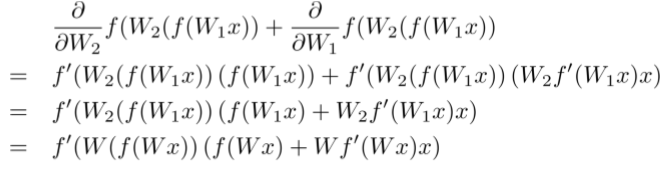
BTS: 2) Split derivatives at each node
- 在前向传播中,父节点是通过两个子节点计算得来的
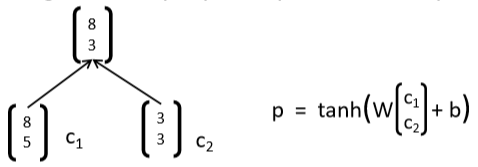
- 因此,错误需要对每个子节点都要算
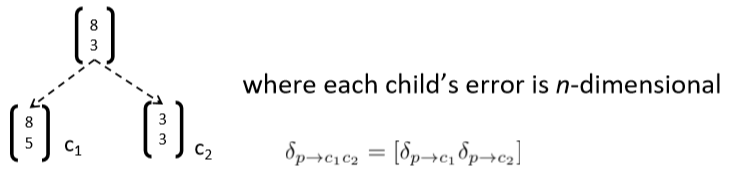
BTS: 3) Add error messages
- 在每个节点:
- What came up (fprop) must come down (bprop)
- Total error messages = error messages from parent + error message from own score
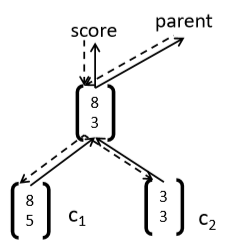
Phton的实现代码见课件
Discussion: Simple TreeRNN
- 单权值矩阵TreeRNN 能得到较好的结果
- 单权值矩阵TreeRNN可以捕捉一些现象,但不适合复杂的、高阶的句子合成和句法分析
- 输入词之间没有进行真正的交互(将两个子节点拼接在一起,然后乘一个权重矩阵 W,其实相当于权重矩阵的分成两部分分别与子节点相乘,两个子节点之间没有进行真正的交互)
- 所有句法范畴、标点符号等的构词功能都是一样的,等等。
Version 2: Syntactically-Untied RNN
[Socher, Bauer, Manning, Ng 2013]
- 符号上下文无关语法(CFG)主干足以构成基本的句法结构
- 我们用子节点的离散句法范畴来选择合成矩阵
- 在不同的句法环境下,使用不同的构词矩阵使得 TreeRNN 性能更好
- 结果给我们一个很好的语义表示

- 左图是我们的第一个版本,右图中使用了不同的权重矩阵,与两个子节点相关。如假设 B,C分别是形容词和名词,那么权重矩阵 就是用于计算形容词和名词组合表示的矩阵
Compositional Vector Grammars
- 问题:速度,beam search 中的每个候选分数都需要一个矩阵向量积。
- 解决方案:只计算来自更简单、更快模型(PCFG)的树子集的分数
- 为了加速剪掉概率很小的候选
- 为每个beam候选提供子类的粗略语法类别
- Compositional Vector Grammar = PCFG + TreeRNN
组合向量文法 = 概率无关上下文文法 + TreeRNN
Related Work for parsing

Experiments

SU-RNN / CVG [Socher, Bauer, Manning, Ng 2013]
Learns soft notion of head words

- 初始化为一对对角矩阵
- 学习的是,子节点中那个更加重要(橙红色表示更重要,蓝色表示不重要)
- 学习到的部分结果如下

Analysis of resulting vector representations

- 从语料中找出与给出的句子最相似的两个句子。上述结果表明模型表现很好,能够找出很相近的句子,甚至有些结构有很大不同,但意思相近
Version 3: Compositionality Through Recursive Matrix-Vector Spaces
[Socher, Huval, Bhat, Manning, & Ng, 2012]
- 在之前,我们使用
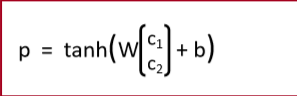
- 一个能使组合函数更加强大的方法是使用不同的权重矩阵 W(Version 2中)
- 但如果词的作用是修饰,比如,“very good” 中的 “very”
- 提议:一种新的组合方式
Compositionality Through Recursive Matrix-Vector Recursive Neural Networks
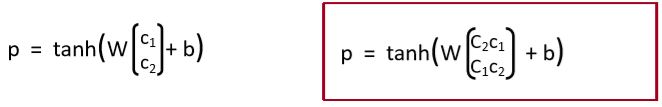
Matrix-vector RNNs
[Socher, Huval, Bhat, Manning, & Ng, 2012]

- 每个节点用一个 vector 和一个 matrix 表示,其中 vector 表示含义,matrix 表示修饰作用。
- 具体运算见上图,将 “very” 和 “good” 组合起来:用"good"的矩阵乘以"very"的向量,用"very"的矩阵乘"good"的向量,然后将结果拼接起来,线性变化后使用非线性变换得到组合后的 向量,将两个矩阵拼接起来,通过线性变化后得到组合后的 矩阵
Predicting Sentiment Distributions

- 横轴表示情感积极程度,向左是消极,向右是积极
- 结果显示 MV-RNN 能够很好的捕获短语的语义信息
Classification of Semantic Relationships
- MV-RNN 可以学习到大的句法上下文传达语义关系吗?

- 为包含这两个词最小成分构建单个合成语义

Classification of Semantic Relationships

version 3有两个问题:
- 矩阵参数太多
- 构建短语的矩阵的方式不太好
Version 4: Recursive Neural Tensor Network
Socher, Perelygin, Wu, Chuang, Manning, Ng, and Potts 2013

- 参数比 MV-RNN 少
- 允许两个词或短语向量进行乘法交互
Beyond the bag of words: Sentiment detection
- 判断句子积极还是消极是容易的,对于有很多情感词的长文档,词袋模型能够做到 90%,但是

这样的就很难判断准确
Stanford Sentiment Treebank

http://nlp.stanford.edu:8080/sentiment/
- 对11855个句子的215154个短语进行了标注(每个短语都被标注了情感)
- 能实际训练和测试 compositions (组合)
Better Dataset Helped All Models

- 使用 Treebank 能够让所有模型提高性能
- 但对困难的否定句式的判断,大多数仍然是不正确的
- 我们需要一个更强大的模型
Version 4: Recursive Neural Tensor Network
-
想法:允许向量的加法和介导乘法相互作用

-
回到最初的使用向量表示单词的意义,但不是仅仅将两个表示单词含义的向量相互作用,左上图是在中间插入一个矩阵,以双线性的方式做注意力并得到了注意力得分。即令两个单词的向量相互作用并且只产生一个数字作为输出
-
如上图所示,我们可以拥有三维矩阵,即多层的矩阵(二维),从而得到了两个得分

-
在树中使用结果向量作为逻辑回归的分类器的输入
-
使用梯度下降联合训练所有权重
Positive/Negative Results on Treebank

Experimental Results on Treebank
- RNTN 可以捕捉类似 X but Y 的结构
- RNTN accuracy of 72%, compared to MV-RNN (65%), biword NB (58%) and RNN (54%)

Negation Results
当否定否定时,肯定的激活应该增加!

Demo: http://nlp.stanford.edu:8080/sentiment/
Version 5: Improving Deep Learning Semantic Representations using a TreeLSTM
[Tai et al., ACL 2015; also Zhu et al. ICML 2015]
目标:
- 仍然试图将句子的意思表示为(高维,连续的)向量空间中的一个位置
- 准确处理语义成分和句子意义
- 将广泛使用的链式结构LSTM推广到树上
Long Short-Term Memory (LSTM) Units for Sequential Composition
- 门是
乘元的矢量,用于软屏蔽

Tree-Structured Long Short-Term Memory Networks
[Tai et al., ACL 2015]

- 将连续LSTM推广到具有任何分支因子的树


Results: Sentiment Analysis: Stanford Sentiment Treebank


Semantic Relatedness SICK 2014 (Sentences Involving Compositional Knowledge)

Forget Gates: Selective State Preservation
Stripes = forget gate activations; more white ⇒more preserved

使用树结构的几个场景
QCD-Aware Recursive Neural Networks for Jet Physics Gilles Louppe, KyunghunCho, Cyril Becot, Kyle Cranmer (2017)

Tree-to-tree Neural Networks for Program Translation
[Chen, Liu, and Song NeurIPS2018]

- 探索使用树结构编码和生成在编程语言之间进行翻译
- 在生成时,对源树使用注意力

- 注意力有很大帮助(见上图)

广告


总结
-
介绍了五种对句子进行解析并获得较大短语表示的方法
- version1:两两拼接,使用相同的权重矩阵W进行线性变化,然后使用非线性变化得到 短语(或句子)的表示,使用此表示得到一个merge的分数
- version2:组合向量文法(CVG) = 概率无关上下文文法 + TreeRNN
使用CFPG对概率较小的解析树进行剪枝,然后使用TreeRNN计算短语表示 - version3:MV-RNN
每个节点用一个 向量 和一个 矩阵表示,merge 时两个子节点也能进行更多的交互。两个问题:矩阵含有参数太多,父节点的矩阵获得方式不好 - version4:RNTN
使用两个节点的向量表示,在其中间插入一个矩阵,然后乘起来,即使用双线性的方式得到注意力得分(两个数字),然后再通过一个逻辑回归分类器。 - version5:使用TreeLSTM
课堂中此处略过了,所以我了解的也不太深。大致就是加入了LSTM的思想,使用了门控
-
树结构在其他领域的使用
- 程序语言的转化
-
Tree Bank:一个斯坦福的情感分析语料。对句子中的每个短语都进行了标注(积极 or 消极)
