
文章目录
Language Modeling
- 语言建模是预测下一个词的任务
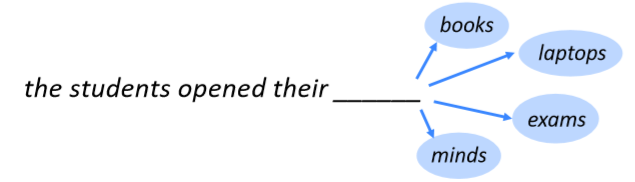
- 更正式来说,给出一个词序列
,计算下一个词
的概率
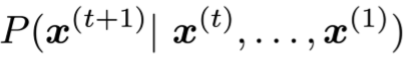
其中 可以是单词表中 任何一个单词 - 这样的系统就叫做语言模型
- 你也可以这样考虑:一个语言模型就是把一段文本指定一个概率的系统

- 我们每天都在使用语言模型,比如聊天时的输入法会根据你的输入习惯或固定搭配来推测下一个字或词,再比如搜素引擎也会根据已有的输入来推测之后的内容
n-gram Language Models
- 问题:如何学习一个语言模型
- 答案:学习一个n-gram语言模型
- 所谓n-gram指的是n个连续单词的一个块。如下例子
- unigrams: “the”, “students”, “opened”, ”their”
- bigrams: “the students”, “students opened”, “opened their”
- trigrams: “the students opened”, “students opened their”
- 4-grams: “the students opened their”
- idea:收集关于不同n-grams出现频率的统计数据,并使用这些数据预测下一个单词。
- 首先我们做一个假设:
只依赖于前n-1个单词

通过在大规模预料中对它们进行计数,就可以计算出这个值
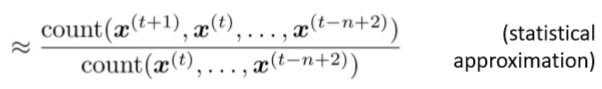
下面举一个4-gram的例子

假设在语料中:- “students opened their” occurred 1000 times
- “students opened their books”出现了400次–》
- “students opened their exams”出现了100次–》
- 但是我们应该放弃proctor(监考人员)上下文吗?很明显,想要预测这里的词,proctor至关重要,只有将其包括到上下文中,才能正确预测。但是要想包括进去,那么至少要9-gram,这是不切实际的,因为会导致稀疏和存储问题
Sparsity Problems(稀疏问题)
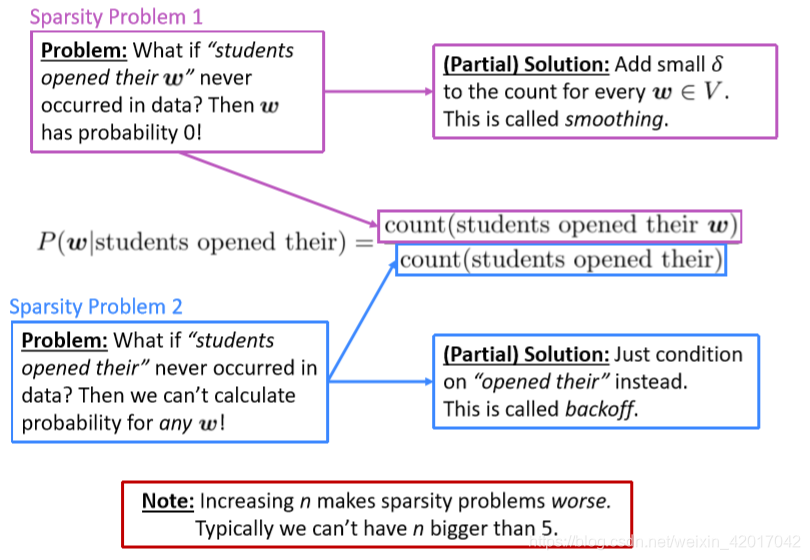
根据上面计算概率的公式,稀疏问题导致原因有两个:分子为0和分母为0
统计数据得到参数时,需要统计所有的参数。假设词典中有三个词,要构建一个3-gram的语言模型,则需要计算
,
,
,
,
,
,
这里的上标表示在词典中的位置。则会产生分子为0或分母为0
解决方法是使用各种平滑算法,如最简单的有加一平滑,线性插值平滑等
注:由于稀疏性问题,一般来说n不能超过5
Storage Problems(存储问题)
随着n的增大,模型参数将会爆炸性增加。比如上述的例子,三个单词的trigram就需要计算8个参数。
n-gram语言模型实际应用
可以用于文本生成,如下所示


最终生成:today the price of gold per ton , while production of shoe lasts and shoe industry , the bank intervened just after it considered and rejected an imf demand to rebuild depleted european stocks , sept 30 end primary 76 cts a share .
得到的句子语法方面很不错,但是语无伦次。如果我们要获得一个比较好的语言模型,我们需要考虑trigram,但是随着n的增加会导致稀疏性问题和模型大小急剧增大…
How to build a neural Language Model?
- 重新思考语言模型任务
- 输入:词序列
- 输出:下一个单词的概率
- 回想起Lecture 3中的NER,我们是否能构建一个基于固定大小window的神经语言模型
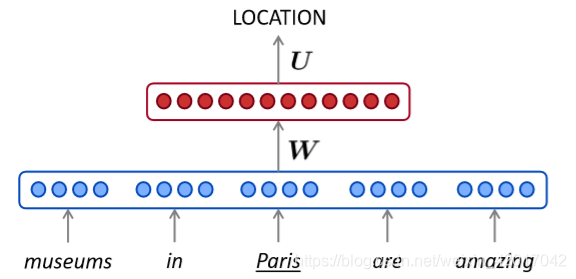
A fixed-window neural Language Model
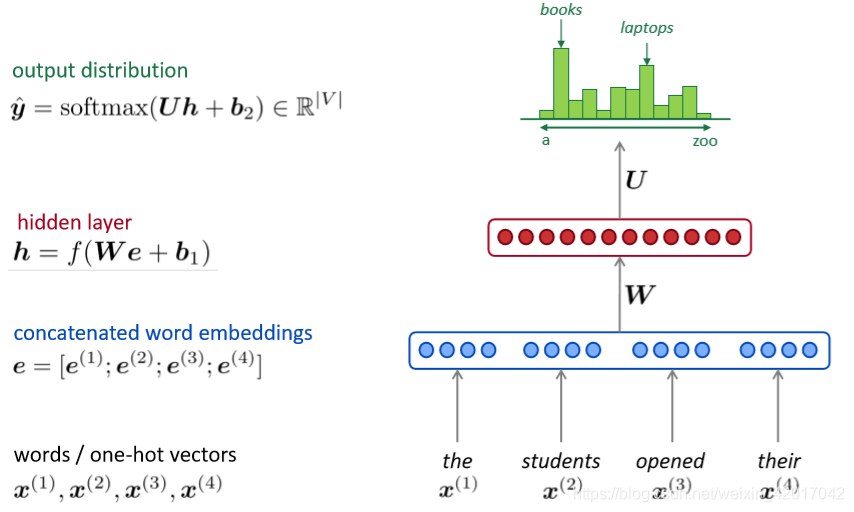
相比n-gram的改进
- 没有稀疏问题
- 不需要存储所有的n-grams
遗留的问题 - 固定窗口太小了
- 增大窗口增大了权重矩阵W
- 窗口不可能很大
- 且 与与W的不同列相乘,没有任何可共享的参数。
Recurrent Neural Networks (RNN)
核心思想:重复使用相同的权重矩阵W
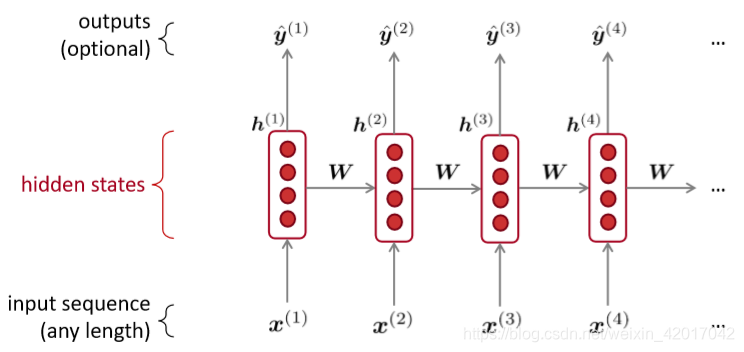
A RNN Language Model
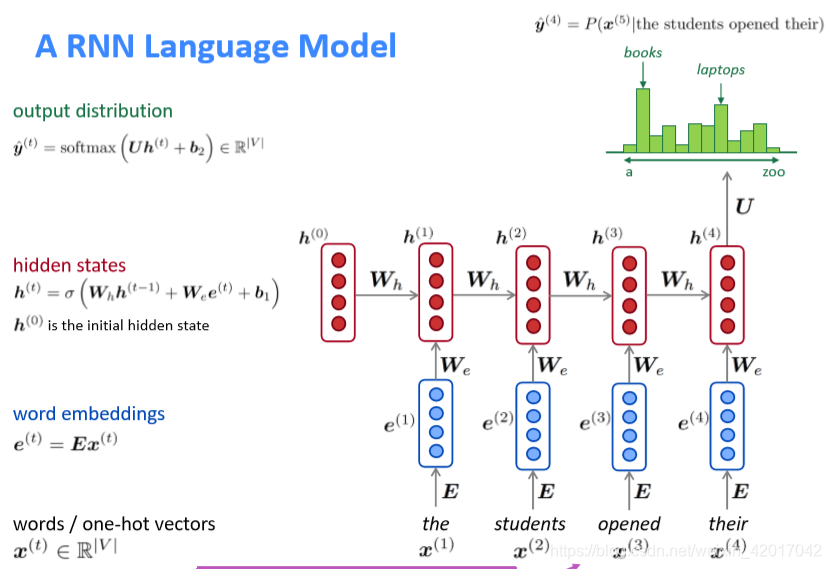
RNN的优点
- 可以处理任意商都的输入
- 计算step t时(理论上)可以使用之前的所有信息
- 输入长度增加,模型大小并不增大
- 每一步都是用相同的权重,所以处理上具有对称性
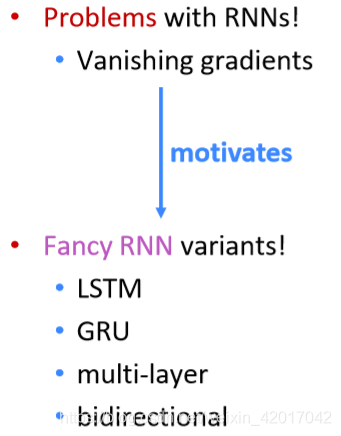
RNN的缺点:
- 循环计算很慢(无法并行)
- 实际上,很难获取之前的太多信息(梯度消失引起的)
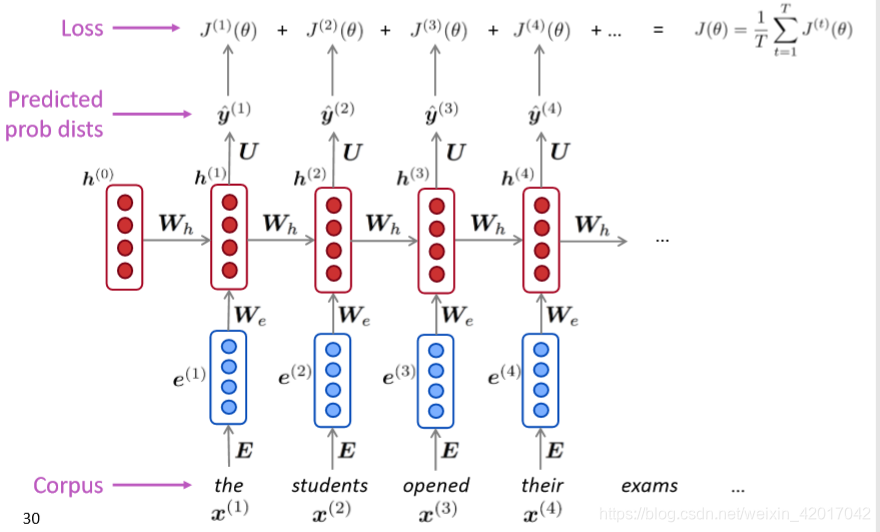
Training a RNN Language Model
- 获得一个大规模语料
- 喂进RNN-LM中,计算每个时间步t的输出分布 ,即在给定目前的序列下,预测每一个词出现的概率
- 在时间步t的损失函数是预测概率分布
和下一个词真实分布
的交叉熵。(即真实分布为one-hot向量,正确词所在位置(t+1)为1)
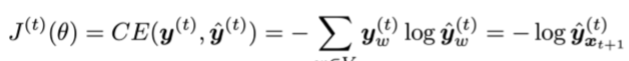
- 对整个训练集进行平均得到总体loss
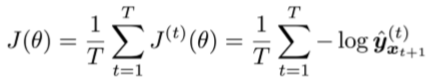
- 然而,计算整个语料的loss和梯度,计算量太大了。
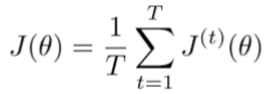
- 实际中,计算一个句子(或者实际上是一批句子)的loss,并计算梯度更新权重矩阵,然后重复。
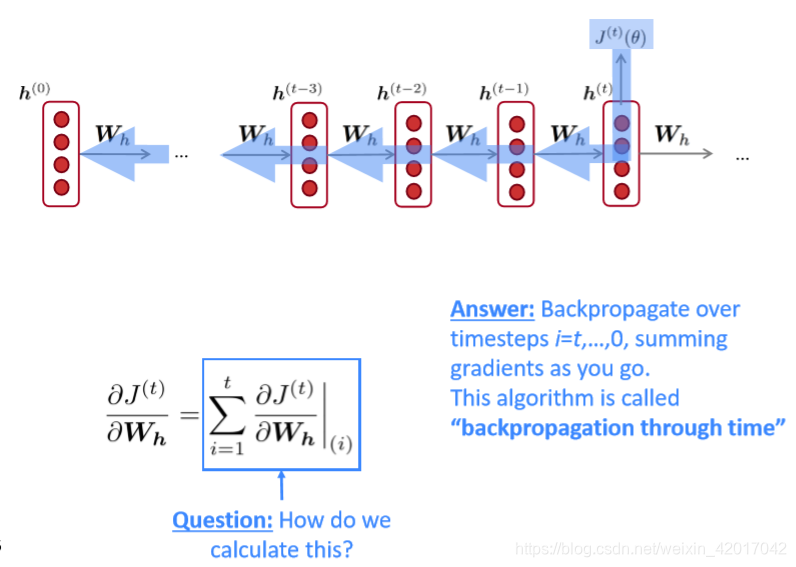
Backpropagation for RNNs
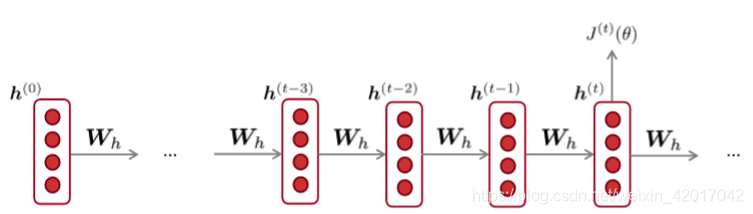
如何计算
关于
的梯度,这里
是重复出现的。
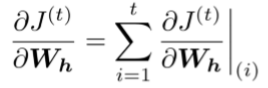
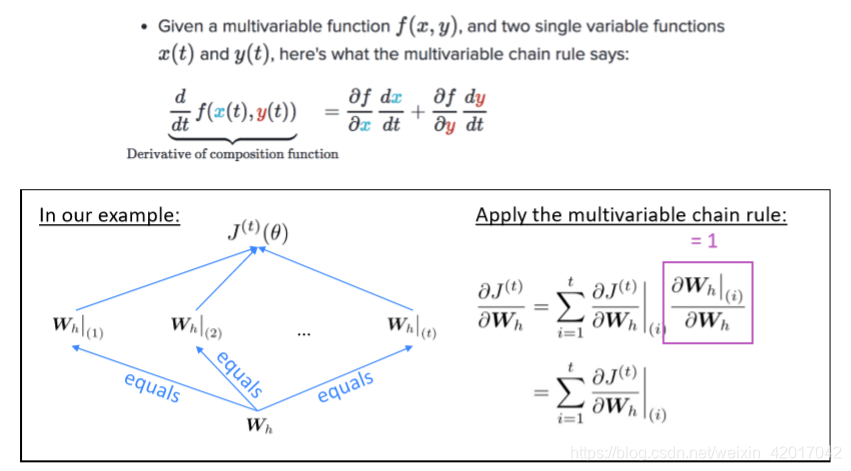
该梯度是每次出现时的梯度求和得来
解释如下:
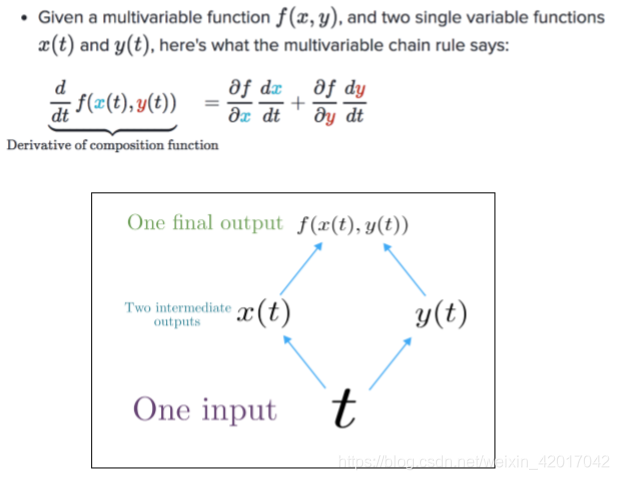
- 使用了多变量链式规则
在RNN中即为
该如何计算呢?backpropagation through time
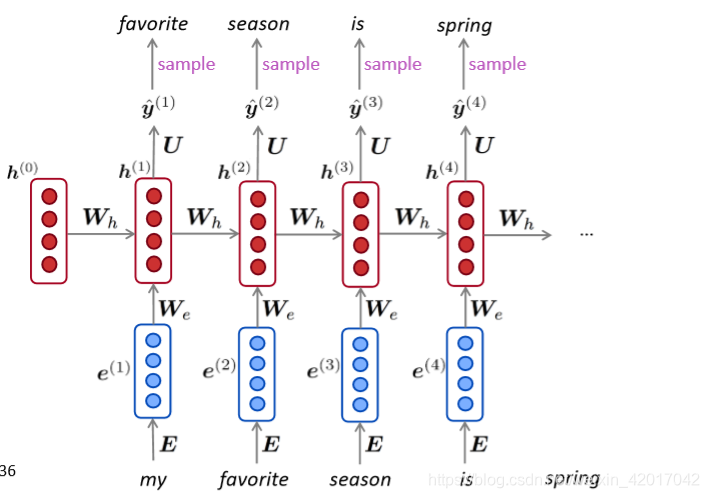
使用RNN-LM生成文本
就和n-gram语言模型类似,可以使用RNN语言模型通过重复采样生成文本。采样输出是下一步的输入。
语言模型的评价
- 标准评价工具时困惑度(perplexity)

这等于交叉熵损失的指数
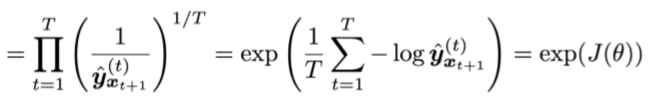
困惑度越小越好
RNNs have greatly improved perplexity

Why should we care about Language Modeling?
- 语言建模是一个能够帮助我们衡量我们在理解语言上进步的benchmark任务
- 语言建模是许多NLP任务的子组件,特别是那些涉及生成文本或估计文本概率的任务

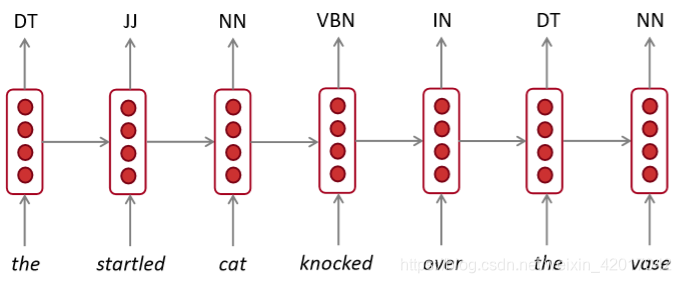
RNN可以用于
-
序列标注:词性标注、命名实体识别等
-
情感分析
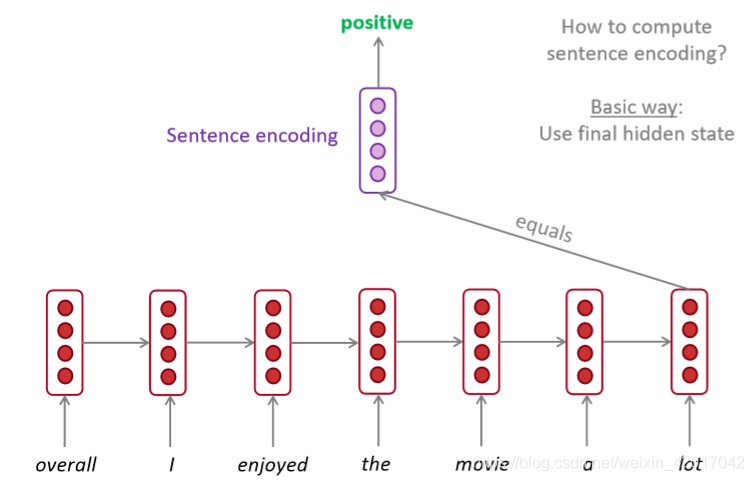
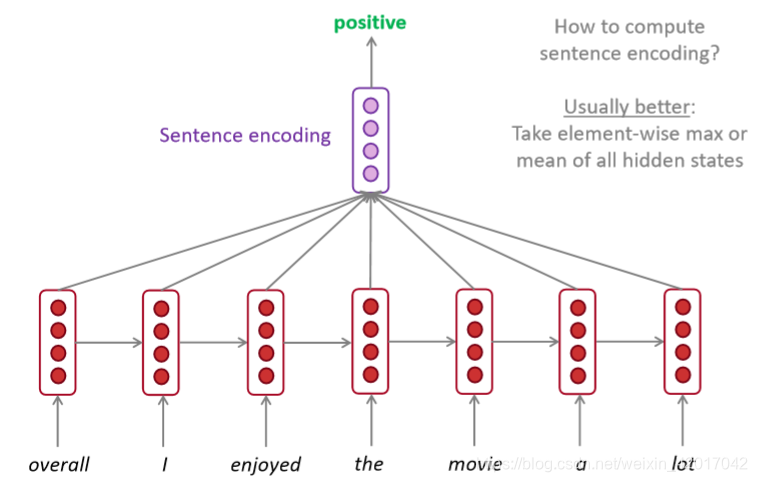
-
可用作编码器模块
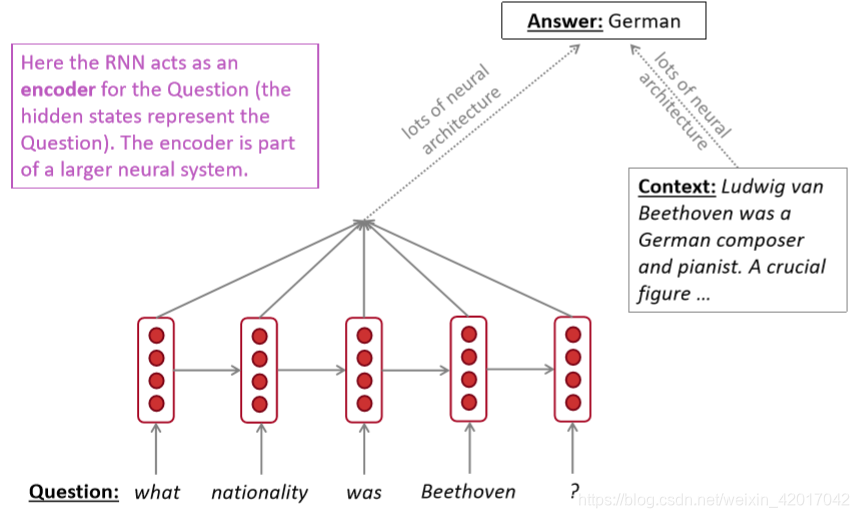
这里RNN用作了问答系统中问题的编码模块 -
RNN-LMs可以用于文本生成:语音识别、机器翻译、文本摘要等
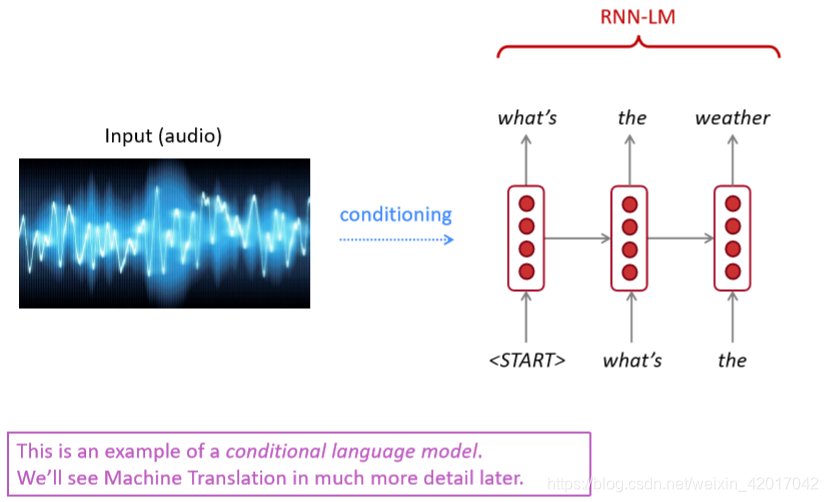
RNN和其他变体的一个比喻

下节课
总结
- 本文讲了如何构建一个语言模型
- n-gram
- fixed-window
- RNN
- 构建一个语言模型有什么好处:benchmark任务
只要某个任务涉及到关于计算字序列是一个合理句子的概率,则可以考虑使用语言模型 - RNN能做什么
特点:可以接收任意长度的输入–>适合处理序列- 序列标注任务
- 文本生成任务
- 编码器和解码器
