论文全文翻译。
论文下载:点击此处
论文期刊:EMNLP 2014
论文年份:2014
论文被引:6900(04/20/20)
文章目录
Abstract
We report on a series of experiments with convolutional neural networks (CNN) trained on top of pre-trained word vectors for sentence-level classification tasks. We show that a simple CNN with little hyperparameter tuning and static vectors achieves excellent results on multiple benchmarks. Learning task-specific vectors through fine-tuning offers further gains in performance. We additionally propose a simple modification to the architecture to allow for the use of both task-specific and static vectors. The CNN models discussed herein improve upon the state of the art on 4 out of 7 tasks, which include sentiment analysis and question classification.
我们进行了一系列在预先训练的词向量上训练卷积神经网络(CNN)用于句子级分类任务的实验。通过实验证明了:一个简单的CNN,只需要很少的超参数调整和静态向量,就可以在多个基准上获得很好的结果;通过微调学习特定于任务的向量可以进一步提高性能。此外,我们还建议对体系结构进行简单的修改,以允许同时使用特定于任务的向量和静态向量。本文讨论的CNN模型改进了7项任务中的4项,包括情感分析和问题分类。
1. Introduction
Deep learning models have achieved remarkable results in computer vision (Krizhevsky et al., 2012) and speech recognition (Graves et al., 2013) in recent years. Within natural language processing, much of the work with deep learning methods has involved learning word vector representations through neural language models (Bengio et al., 2003; Yih et al., 2011; Mikolov et al., 2013) and performing composition over the learned word vectors for classification (Collobert et al., 2011). Word vectors, wherein words are projected from a sparse, 1-of-V encoding (here V is the vocabulary size) onto a lower dimensional vector space via a hidden layer, are essentially feature extractors that encode semantic features of words in their dimensions. In such dense representations, semantically close words are likewise close—in euclidean or cosine distance—in the lower dimensional vector space.
近年来,深度学习模型在计算机视觉(Krizhevsky et al.,2012)和语音识别(Graves et al.,2013)方面取得了显著的效果。在自然语言处理中,许多使用深度学习方法的工作涉及通过神经语言模型学习词向量表示(Bengio等人,2003;Yih等人,2011;Mikolov等人,2013)和对学习到的词向量进行构图以进行分类(Collobert等人,2011)。单词向量,其中单词通过隐藏层从稀疏的1/V编码(这里V是词汇大小)投影到低维向量空间,本质上是对单词的语义特征进行维度编码的特征提取器。在这种稠密的表示中,语义相近的词在低维向量空间中的欧几里德距离或余弦距离上同样相近。
Convolutional neural networks (CNN) utilize layers with convolving filters that are applied to local features (LeCun et al., 1998). Originally invented for computer vision, CNN models have subsequently been shown to be effective for NLP and have achieved excellent results in semantic parsing (Yih et al., 2014), search query retrieval (Shen et al., 2014), sentence modeling (Kalchbrenner et al., 2014), and other traditional NLP tasks (Collobert et al., 2011).
卷积神经网络(CNN)利用应用于局部特征的带卷积滤波器的层(LeCun等人,1998)。CNN模型最初是为计算机视觉而发明的,后来被证明对NLP有效,并在语义分析(Yih等人,2014)、搜索查询检索(Shen等人,2014)、句子建模(Kalchbrenner等人,2014)和其他传统NLP任务(Collobert等人,2011)方面取得了优异的结果。
In the present work, we train a simple CNN with one layer of convolution on top of word vectors obtained from an unsupervised neural language model. These vectors were trained by Mikolov et al. (2013) on 100 billion words of Google News, and are publicly available.1We initially keep the word vectors static and learn only the other parameters of the model. Despite little tuning of hyperparameters, this simple model achieves excellent results on multiple benchmarks, suggesting that the pre-trained vectors are ‘universal’ feature extractors that can be utilized for various classification tasks. Learning task-specific vectors through fine-tuning results in further improvements. We finally describe a simple modification to the architecture to allow for the use of both pre-trained and task-specific vectors by having multiple channels.
在本研究中,我们训练一个简单的CNN,在无监督神经语言模型所得到的字向量上加上一层卷积。这些载体由Mikolov等人在1000亿字的公开的谷歌新闻上训练(2013)。我们最初保持字向量不变,只学习模型的其他参数。尽管超参数的调整很少,这个简单的模型在多个基准上取得了很好的结果,这表明预先训练的向量是“通用”的特征抽取器,可以用于各种分类任务。通过微调学习特定于任务的向量可以进一步改进。最后,我们描述了对体系结构的一个简单修改,允许通过多个通道使用预先训练的向量和任务特定的向量。
Our work is philosophically similar to Razavian et al. (2014) which showed that for image classification, feature extractors obtained from a pretrained deep learning model perform well on a variety of tasks—including tasks that are very different from the original task for which the feature extractors were trained.
我们的工作在哲学上类似于Razavine等人(2014)。这表明,对于图像分类,从预训练的深度学习模型获得的特征提取器在各种任务上表现良好,包括与训练特征提取器的原始任务非常不同的任务。
2. Model

图1所示模型架构是 Collobert 等人提出的 CNN架构 的微小变体(2011年)。设
为与句子中第
个词相对应的
维词向量。长度为
的句子(不足时填充)表示为:
其中
是 串联运算符(concatenation operator)。通常,让
指单词
,…,
的串联。卷积运算涉及一个滤波器(filters)
,该滤波器被应用于
个单词的窗口以产生新的特征。例如,特征词
是根据单词
的窗口通过下式生成的:
其中,
是一个偏差项,
是一个非线性函数,例如双曲正切。将此过滤器应用于句子
生成 特征图(feature map):
。然后,我们对特征映射应用max-overtime池化操作(Collobert等人,2011),并将最大值
作为与此特定过滤器对应的特征。其思想是捕捉最重要的特征,即每个特征映射值最高的特征。这种池机制自然可以用于处理可变长度的句子。
我们已经描述了从一个过滤器中提取一个特征的过程。该模型使用多个过滤器(窗口大小不同)来获取多个特征。这些特征形成倒数第二层,并传递到完全连接的softmax层,其输出是标签的概率分布。
在一种模型变体中,我们尝试使用两个单词向量的“通道”,一个在整个训练过程中保持静态,另一个通过反向传播进行微调(第3.2节)。在多通道架构中,如图1所示。 将每个滤波器应用于两个通道,并将结果相加以使用公式(2)计算 。该模型在其它方面等效于单通道体系结构。
2.1 Regularization
为了进行正则化,我们在倒数第二层采用了权重向量
范数约束(Hinton等人,2012)。删除通过在回滚传播过程中以
的比例随机删除隐藏单元(即设置为零)来防止隐藏单元的共适应。也就是说,给定倒数第二层
(注意:这里有
个过滤器),而不是使用:
对于正向传播中的输出单元
,dropout 使用:
其中,◦ 是逐元素乘法运算符, 是伯努利随机变量的 “掩膜(masking)” 向量,概率 为1。使用无屏蔽单元的反向传播算法计算梯度。在测试时,将学习的权重向量按 进行缩放,使得 ,并且 用于(不使用 dropout)给未见的句子评分。在梯度下降步骤之后,每当 时,通过将 重新缩放为 ,我们进一步限制了权向量的 -范数。
3. Datasets and Experimental Setup
在各种基准数据集上测试模型。数据集的摘要统计信息如表1所示。

表1:标记化后数据集的摘要统计量。
:目标类别的数量。
:平均句子长度。
:数据集大小。
:词汇量。
:一组预训练词向量中存在的词数。Test:测试集大小(CV表示没有标准的训练/测试拆分,因此使用10折交叉验证(Cross Validation,CV))。
- MR: Movie reviews with one sentence per review. Classification involves detecting positive/negative reviews (Pang and Lee, 2005).^3
- SST-1: Stanford Sentiment Treebank—an extension of MR but with train/dev/test splits provided and fine-grained labels (very positive, positive, neutral, negative, very negative), re-labeled by Socher et al. (2013).^4
- SST-2: Same as SST-1 but with neutral reviews removed and binary labels.
Subj: Subjectivity dataset where the task is to classify a sentence as being subjective or objective (Pang and Lee, 2004). - TREC: TREC question dataset—task involves classifying a question into 6 question types (whether the question is about person, location, numeric information, etc.) (Li and Roth, 2002).^5
- CR: Customer reviews of various products (cameras, MP3s etc.). Task is to predict positive/negative reviews (Hu and Liu, 2004).^6
- MPQA: Opinion polarity detection subtask of the MPQA dataset (Wiebe et al., 2005).^7
3.1 Hyperparameters and Training
对于所有数据集,使用:校正线性单元(rectified linear units,RELU);3、4、5的每个过滤器窗口(
)具有 100 个特征图;dropout rate(
)设为 0.5;
约束(
)设为 3,batch_size设为 50。这些值是通过SST-2数据集使用网格搜索选择的。
3.2 Pre-trained Word Vectors
使用从无监督神经语言模型获得的词向量进行初始化的词向量是一种在缺乏大型有监督训练集的情况下提高性能的流行方法(Collobert等,2011; Socher等,2011; Iyyer等,2014) 。我们使用可公开获得的经过Google新闻的1000亿个单词的训练 的
向量。向量的维数为 300,并使用连续词袋架构进行了训练(Mikolov等,2013)。预先训练的词集合中不存在的词是随机初始化的。
3.3 Model Variations
我们对模型的几种变体进行了实验。
- CNN-rand:我们的基线模型中,所有单词都随机初始化,然后在训练期间进行修改。
- CNN-static:word2vec 中预训练向量的模型。所有单词(包括随机初始化的未知单词)均保持静态,并且仅学习模型的其他参数。
- CNN-non-static:与上述相同,但针对每个任务微调了预训练向量。
- CNN-multichannel:具有两组词向量的模型。每组向量都被视为一个“通道”,并且每个滤波器都应用到两个通道,但是渐变仅通过其中一个通道反向传播。因此,该模型能够微调一组矢量,同时保持另一组静态。两个通道都使用word2vec初始化。

表2:我们的CNN模型与其他方法的对比结果。RAE:具有来自维基百科的预训练词向量的递归自动编码器(Socher等人,2011)。MV-RNN:带解析树的矩阵-向量递归神经网络(Socher等人,2012)。RNTN:基于张量特征函数和解析树的递归神经张量网络(Socher等人,2013)。DCNN:具有k-max池的动态卷积神经网络(Kalchbrenner等人,2014)。段落向量:段落向量顶部的逻辑回归(Le和Mikolov,2014)。CCAE:具有组合类别语法运算符的组合类别自动编码器(Hermann和Blunsom,2013)。Sent-Parser:情绪分析专用解析器(Dong等人,2014)。NBSVM,MNB:Wang和Manning(2012)的Naive Bayes SVM和具有单子图的多项式Naive Bayes。G-Dropout, F-Dropout:Wang和Manning的高斯辍学和快速辍学(2013)。Tree-CRF:具有条件随机字段的依赖树(Nakagawa等人,2010)。CRF-PR:具有后验正则化的条件随机场(Yang and Cardie,2014)。SVM:支持向量机,具有统一的双三元组、wh-word、head-word、POS、parser、hypernyms和Silva等人的60条手工编码规则(2011年)。
为了理清上述变化对其它随机因素的影响,我们消除了随机性CV折叠分配的其他来源、未知词向量的初始化、CNN参数的初始化,使它们在每个数据集中保持一致。
4. Results and Discussion
我们的模型与其他方法的对比结果如表2所示。我们的基线模型中包含所有随机初始化的单词(CNN-rand)本身并没有很好的表现。虽然我们通过使用预先训练的向量来预期性能的提高,但是我们对这种提高的幅度感到惊讶。即使是一个带有静态向量的简单模型(CNN static)也表现出色,与使用复杂池方案(Kalchbrenner等人,2014年)或要求预先计算解析树(Socher等人,2013年)的更为复杂的深度学习模型相比,它的结果具有竞争力。这些结果表明,预训练向量是很好的通用特征提取工具,可以跨数据集使用。对每个任务的预训练向量进行微调可以进一步改进(CNN非静态)。

4.2 Static vs. Non-static Representations
As is the case with the single channel non-static model, the multichannel model is able to fine-tune the non-static channel to make it more specific to the task-at-hand. For example, good is most similar to bad in word2vec, presumably because they are (almost) syntactically equivalent. But for vectors in the non-static channel that were finetuned on the SST-2 dataset, this is no longer the case (table 3). Similarly, good is arguably closer to nice than it is to great for expressing sentiment, and this is indeed reflected in the learned vectors.
与单通道非静态模型一样,多通道模型能够微调非静态通道,使其更适合手头的任务。例如,在word2vec中,好与坏最相似,大概是因为它们在语法上几乎是等效的。但是对于在SST-2数据集上微调的非静态通道中的矢量,情况就不再如此(表3)。同样,可以说善感比表达情感要好得多,这确实体现在学习的向量中。
For (randomly initialized) tokens not in the set of pre-trained vectors, fine-tuning allows them to learn more meaningful representations: the network learns that exclamation marks are associated with effusive expressions and that commas are conjunctive (table 3).
对于不在预先训练向量集中的(随机初始化的)标记,微调允许它们学习更有意义的表示:网络学习感叹号与溢出表达式关联,逗号是连接的(表3)。
4.3 Further Observations
我们报告了一些进一步的实验和观察:
- Kalchbrenner等人(2014)用CNN得到了更糟糕的结果,CNN的架构基本上与我们的单一频道模型相同。例如,他们随机初始化单词的Max-TDNN(时滞神经网络)在SST-1数据集上得到37.4%,而我们的模型得到45.0%。我们将这种差异归因于我们的CNN拥有更大的容量(多个过滤器宽度和特征图)。
- Dropout 被证明是一个很好的正则化,使用大于必要网络的网络并直接让其进行正则化是很好的。Dropout持续增加2%-4%的相对性能。
- 在对非word2vec中的单词进行随机初始化时,我们通过对U[−a, a]中的每个维度进行抽样,使随机初始化的向量与预先训练的向量具有相同的方差,从而获得了轻微的改进。如果在初始化过程中使用更复杂的方法来反映预训练向量的分布是否会带来进一步的改进,这将是很有趣的。
- 我们简短地试验了另一组由Collobert等人(2011年)在维基百科上训练的公开可用的词向量,发现word2vec的表现要好得多。尚不清楚这是由于Mikolov等人(2013)的架构还是1000亿字的谷歌新闻数据集。
- Adadelta (Zeiler, 2012)对Adagrad (Duchi et al.,2011)给出了类似的结果,但需要更少的epoch。
5. Conclusion
在本文中,我们描述了一系列基于word2vec的卷积神经网络的实验。尽管超参数的调整很小,但是一个简单的CNN加上一层卷积就表现得非常好。我们的研究结果进一步证明了无监督预训练是NLP深度学习的重要组成部分。
Acknowledgments
We would like to thank Yann LeCun and the anonymous reviewers for their helpful feedback and suggestions.
关于该论文的网络架构说明:
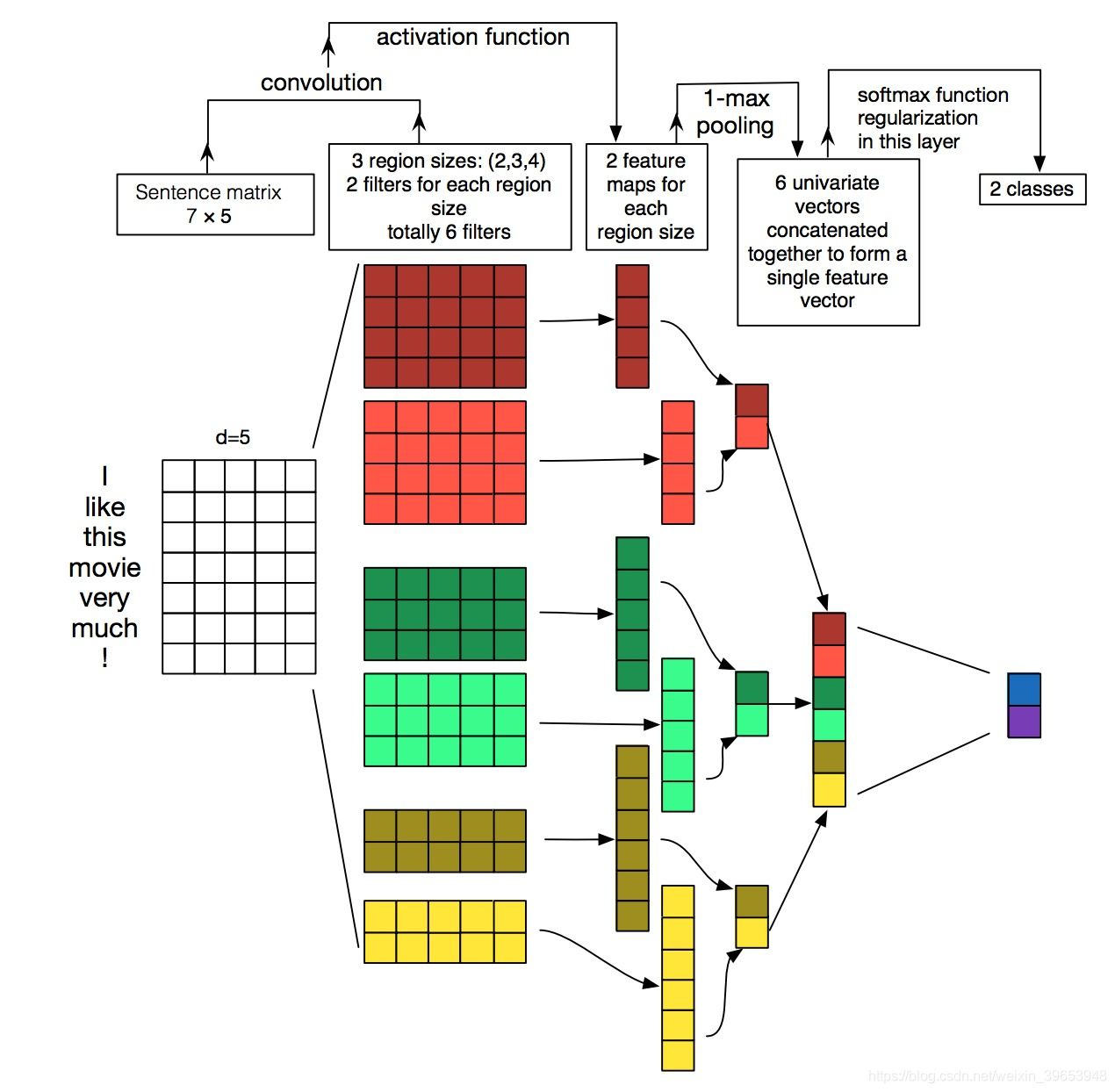
该图来自知乎回答。
