1.本文解决了什么问题?
本文以预训练好的词向量矩阵表示一个句子,并且将其作为卷积神经网络的输入层,再通过标记好的
数据训练出神经网络模型从而达到预测数据类别的效果。
本文于14年发表,至今已被引用了1400多次。其核心意义是将“词向量”与“深度学习”结合在一起(从大的方向上可以说是将NLP与卷积神经网络结合在一起),并且通过实验证明了“词的向量表示”是NLP领域的重要组成部分,应该引起研究者的重视。
2. 本文运用了什么方法?
2.1 卷积神经网络模型
本文所用到的卷积神经网络结构比较简单, 与普通卷积神经网络并无二异。本文所提出的模型区别在
于卷积操作(文章里称滤波操作)和池化操作,神经网络结构如图1所示。
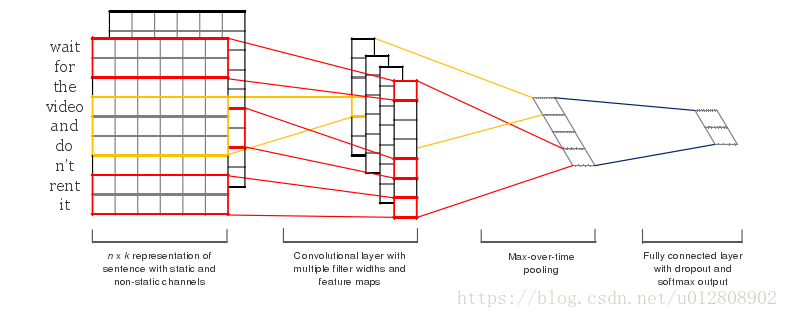
图1 CNN句子分类模型
- 输入层:输入层接收一个句子的两个词向量矩阵(由“单词—词向量”构成的矩阵)。这两个矩阵
起初是一模一样的,其中一个定义为static另一个定义为non-static,其区别在于non-static中的词向量会在模型训练过程中通过“反向传播”改变,而static矩阵则不会。这样做的目的是更好的使词向量适应数据集从而提高分类效率,但是在数据集较小的情况下不推荐这么做。
- 卷积层:与图像领域中的卷积层不同,在图像领域中的卷积层的卷积核一般是一个正方形的矩阵,
如图2所示,其计算轨迹是从左至右、从上至下的对特征矩阵中所覆盖的区域进行带权求和。而本文模型的输入是一个句子,其不同于图片的地方是词向量矩阵的两个维度代表的是两中不同的概念,所以作者提出了一种矩形卷积核(如图1中的红色矩形框),其大小为word_size * embedding_size,word_size为卷积核所涵盖的单词数(即认为句子中相邻的word_size个词有潜在关系),embedding_size则是词向量的维度(由训练词向量的时候人为给定)。另外,卷积核的移动轨迹也因此有所改变,是一个从上至下的移动过程,最后得到的是一个长度为word_num-word_size+1的向量作为卷积后的特征面。
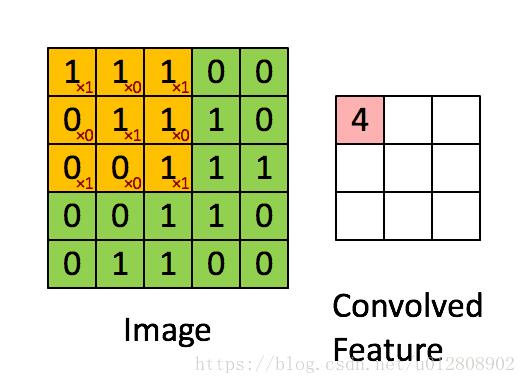

图2 图像识别领域中的卷积核
- 池化层:本文池化层选取的是max-pooling的方法,其只保留每个特征面中最大的
特征项,并将其拼接成一条向量作为该句子的最终表示。这么做看似简单粗暴,但是在实际情况中,很多的句子所包含的单词数不同,所以其卷积后得到的特征面的长度也不同,为了能归一化作者才想到的这么个办法。
- 全连接层:为了输出分类结果而加的softmax层,与其它卷积神经网络中并无二异。
本文基于电影评价数据集做的实验,其最后输出的是一个二分类结果,即评价的好与坏。
2.2 正则化
正则化即为了防止过拟合而采用的策略,其主要思想是通过在损失函数中加入一个正则项(通常由各权重w的带权和表示)学习到更小的权重,从而使得模型对数据的变化不那么敏感(此处的敏感是指对噪音项而言,常见的有L1、L2正则化)。本文提到的DroupOut属于另一种正则化,其区别在于DropOut针对的是神经网络结构而不是损失函数。
1)DropOut过程
DropOut可以简述为在神经网络开始正向传播时,随机删掉隐藏层(对应本文的卷积层与池化层)中一半的节点(如图3所示),而后对剩下的一半神经元进行一轮训练学习,然后在第二轮开始时继续所有隐藏层节点中挑选一般删除,学习另一半节点的权重值,当所有隐藏层节点都被学习到一次后把隐藏层所有节点的权重除以2,重复这个过程直到训练结束。
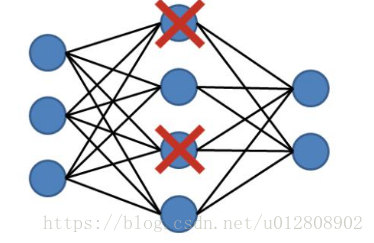
图3 DropOut过程
2)为什么DropOut可以避免过拟合?
引用文章https://blog.csdn.net/u014696921/article/details/54410166中的话就是
一般情况下,对于同一组训练数据,利用不同的神经网络训练之后,求其输出的平均值可以减少过拟合。Dropout就是利用这个原理,每次丢掉一半的一隐藏层神经元,相当于在不同的神经网络上进行训练,这样就减少了神经元之间的依赖性,即每个神经元不能依赖于某几个其他的神经元(指层与层之间相连接的神经元),使神经网络更加能学习到与其他神经元之间的更加健壮的特征。在Dropout的作者文章中,测试手写数字的准确率达到了98.7%!所以Dropout不仅减少overfitting,还能提高准确率。
2.3 代码实现
打算用keras还原作者提出的模型,并且在电影评价数据集上做实验,争取本周搞定后上传Github。
3. 本文还有什么可改进的地方?
这篇文章算是NLP在卷积神经网络领域的开山之作,其不足的地方一定有,待我多看几篇文献后再回来一一总结。