Bag of Tricks for Image Classification with Convolutional Neural Networks,李沐大神18年12月的新作,用卷积神经网络进行图像分类的一些技巧。
论文:Bag of Tricks for Image Classification with Convolutional Neural Networks
本文主要讨论训练神经网络过程中的一些tricks,通过定量分析这些tricks对最终分类网络性能的贡献,主要从三个方面着手:高效训练、网络微调和训练优化。最后将这些tricks推广到目标检测和语义分割任务中。
1 Efficient Training(高效训练)
batch size在较小的时候对模型精度有增益,但是使用一个较大的batch size可能导致模型退化。
1-1-1 Linear scaling learning rate(学习率线性比例缩放)
增大batch size不会改变随机梯度的期望,但是会减少它的方差。因此可以考虑沿着梯度相反的方向线性增大学习率。
本文选择:
initial learning rate × batch size / initial batch size
如 0.1 × b/ 256
引用: Accurate, large minibatch SGD: training imagenet in 1 hour
1-2 Learning rate warmup(学习率热启动)
训练过程中,参数都是随机选择的,因此会明显偏离最优解。使用过大的学习率,会使模型不稳定,使用过小的学习率,训练时间加长,而且容易得到局部最优解(鞍点)。
热启动机制线性增加学习率从0到初始学习率,
batch order number * initial learning rate / first m batches
如 i*η/m
1-3 Zero (BN层 )
批归一化 (BN)首先对输入数据x做归一化操作,即 x_norm = (x-u)/std,然后对归一化后的x进行比例缩放和位移 y= × x_norm + ,(即caffe中的scale层)。一般情况下, 和 分别初始化为1和0。这里BN层 将所有跟在残差块后的BN层的 全部初始化为0,即网络进过scale后返回原始数据,网络参数层变少,使得网络在开始阶段变的更容易训练。
1-4 No bias decay(bias无衰减)
权重衰减(weight decay)广泛应用于weights 和 bias中,一定程度上减少模型过拟合的问题。bias无衰减仅仅在卷积和全连接层的权重中使用权重衰减。BN层的 和 不使用权重衰减。
2 Model Tweaks(网络微调)
网络微调通常是对网络做小的修改,如修改特定卷积层的步长。网络微调很少改变计算复杂度,但对网络性能会有明显影响。作者用ResNet的downsampling block和Input stem作为实验对象,修改了三个版本,分别为ResNet-B、ResNet-C和ResNet-D。实验测试在ResNet-50上进行,三者加起来,能使ResNet-50有接近1%的性能提升。
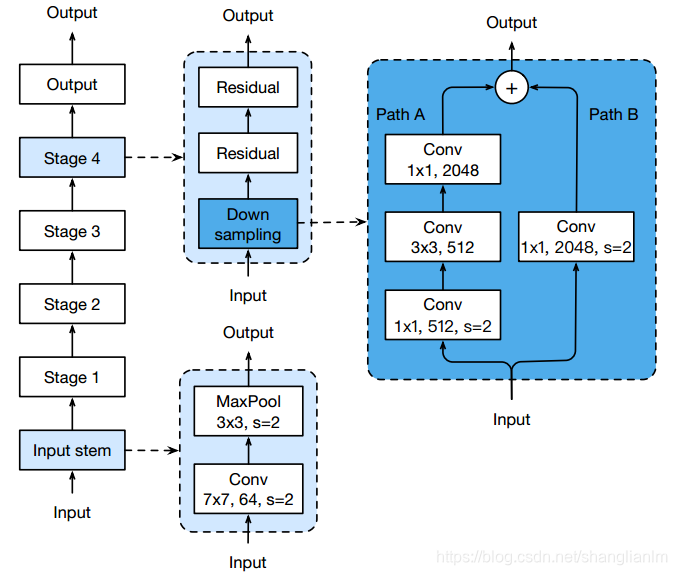
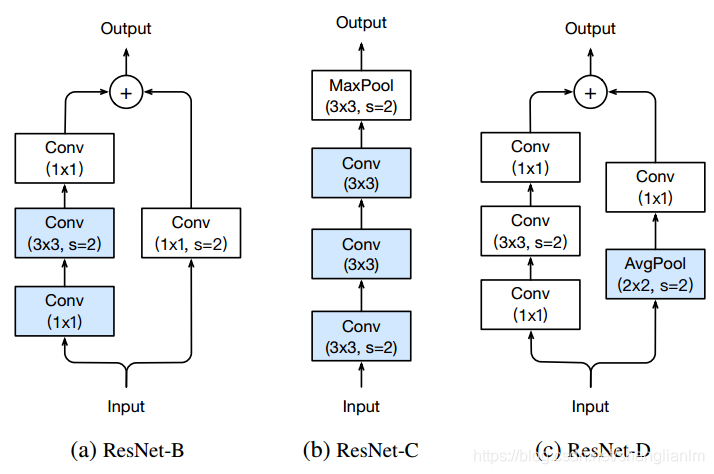
2-1 ResNet-B
Path A的第一个1 x 1卷积层使用了strde=2的步长,会导致3/4的信息丢失。因此ResNet-B将第一二个卷积层的步长交换。
实验表明ResNet-B 有0.5%的性能提升。
2-2 ResNet-C
因为卷积的代价会随着卷积核的长和宽增大而接近平方增加,因此ResNet-C使用3个连续的3 x 3 卷积替换Input stem的7 x 7 卷积。
实验表明ResNet-C 有0.2%的性能提升。
2-3 ResNet-D
ResNet-D在ResNet-B的基础上进一步调整,在Path B的1 x 1卷积前面,加入2 x 2 stride 2的pooling层,将下采样提前,避免了3/4的信息丢失。
实验表明ResNet-D 有0.3%的性能提升。
3 Training Refinements(训练优化)
ResNet-50-D, Inception-V3 和 MobileNet 在ImageNet上训练,并逐渐添加下面这些优化。
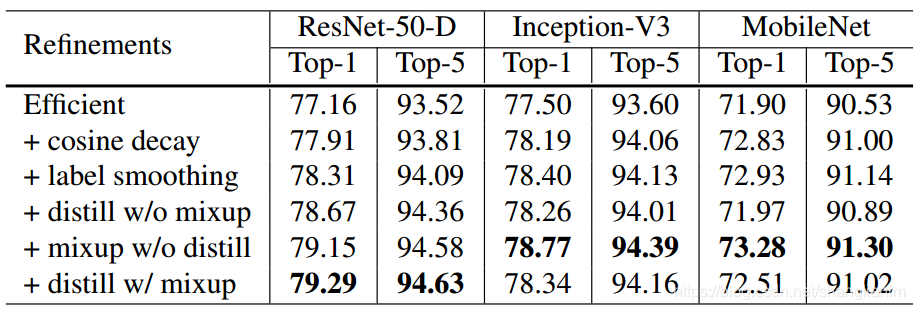
3-1 Cosine Learning Rate Decay(余弦学习速率衰减)
总批次数为T,初始化学习率为η ,在第t批时的学习率ηt为:
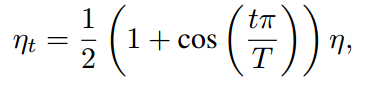
学习率逐步衰减 和 余弦学习率衰减的对比如下:
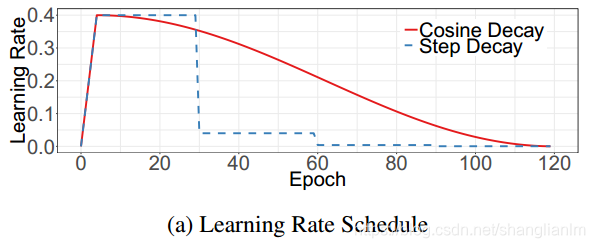
引用:I. Loshchilov and F. Hutter. SGDR: stochastic gradient descent with restarts.
3-2 Label Smoothing(标签平滑)
分类网络最后的全连接层softmax存在过拟合风险,标签平滑修改原来的softmax函数为
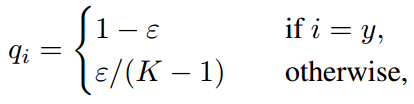
因此,最后的最优解变为:
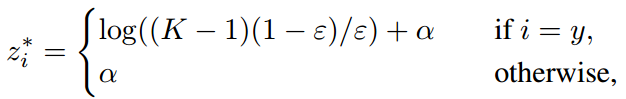
其中α为任意实数。
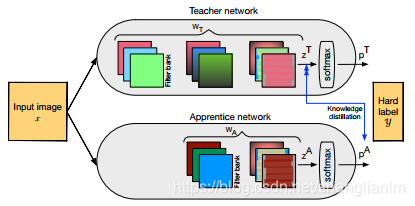
3-3 Knowledge Distillation(知识蒸馏)
通过引入与教师网络(teacher network:复杂、但推理性能优越)相关的软目标(soft-target)作为total loss的一部分,以诱导学生网络(student network:精简、低复杂度)的训练,实现知识迁移(knowledge transfer)。
知识蒸馏目标优化函数:
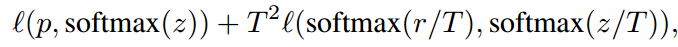
其中p为样本概率分布,z和r分别为学生和教师网络的输出,‘(p; softmax(z)) 为负交叉熵损失,T为超参数。
引用:G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network.
3-4 Mixup Training(混合训练)
混合训练每次从随机抽取的两个样本 (xi, yi) 和 (xj, yj)中通过线性权值组合形成一个新样本
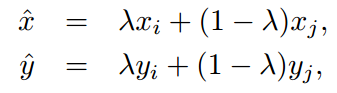
其中,0
λ
1服从 Beta(α, α) 分布,混合训练只使用新生成的样本训练网络。
引用:H. Zhang, M. Cisse, Y. N. Dauphin, and D. Lopez- ´ Paz. mixup: Beyond empirical risk minimization