Lecture 10主要讲解了循环神经网络模型的结构、前向传播与反向传播,并由此引出了Attention机制、LSTM(长短期记忆网络)等,除此之外还介绍了图像标注、视觉问答等前沿问题。
文章目录
RNN网络结构
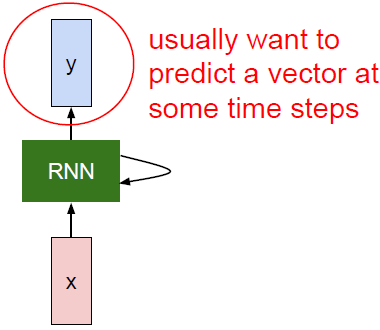
RNN通常用来预测一个时间序列向量。每个RNN网络都有如上图所示这样一个小小的循环核心单元。X为输入,将其传入RNN,RNN有一个内部隐藏态(internal hidden state),这一隐藏态会在RNN每次读取新的输入时更新。当模型下一次读取输入时,隐藏状态同时将结果反馈至模型。
循环神经网络隐藏状态
更新公式:
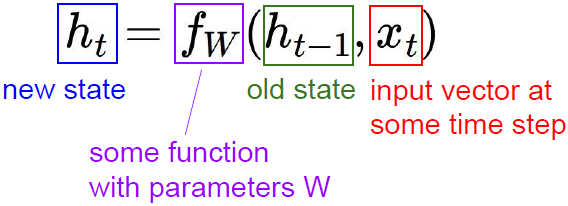
我们对某种循环关系用函数
进行计算。函数
依赖于权重
,接收输入隐藏态
和输入
,然后输出下一个隐藏态
。如果我们想要在网络的每一步都产生一些输出,那么我们可以增加全连接层,根据每一步的隐藏态做出决策。
(注意,每一时间步的函数
和参数
都是相同的。)
Vanilla RNN 络结构图与更新公式:
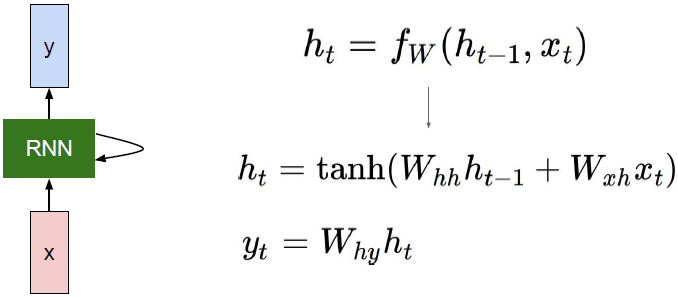
Vanilla RNN 计算图:
为初始状态,一般
。由上图可以看出每一时间步都在使用相同的
和
。由反向传播原理可知,
最后的梯度是所有时间步下独立计算出的梯度之和。
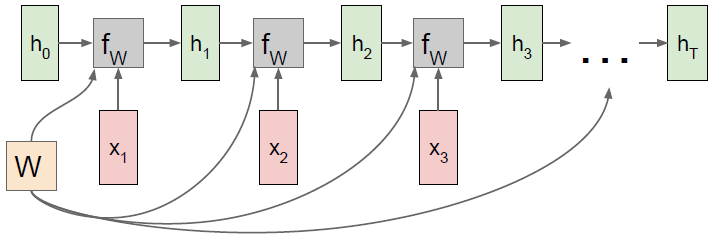
Many to many
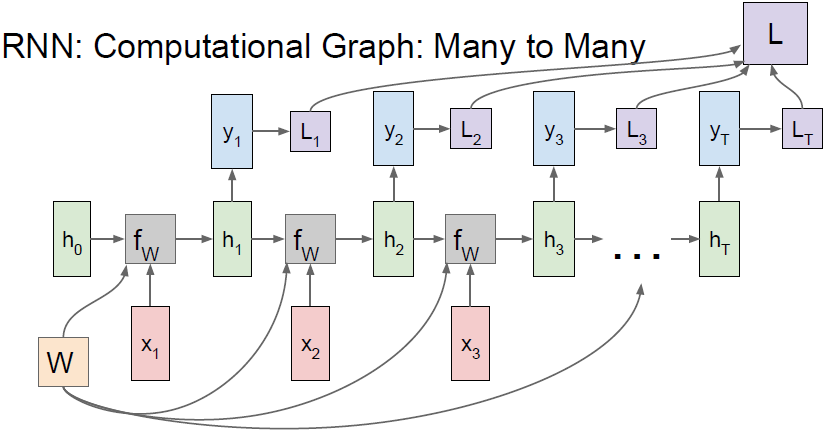
可以是每个时间步的类别得分,
是对应时间步下的损失(如softmax等),计算
需要序列在每个时间步下都有与之对应的真实标签。所有
相加就得到了最终的Loss
。在反向传播中我们需要计算
,而
又会回溯到每一个时间步的损失,然后每一时间步又会各自计算出当下
,其总和就是权重
的最终梯度。
Many to one
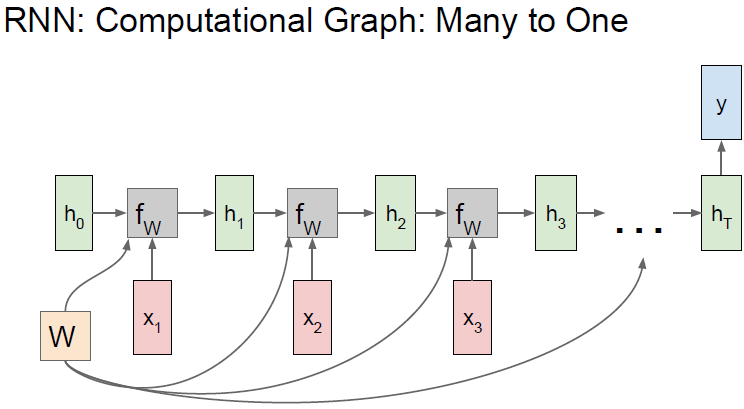
此种结构通常用于情感分析等问题。我们会根据网络的最终
做出决策,因为其整合了序列中包含的所有情况。
One to many
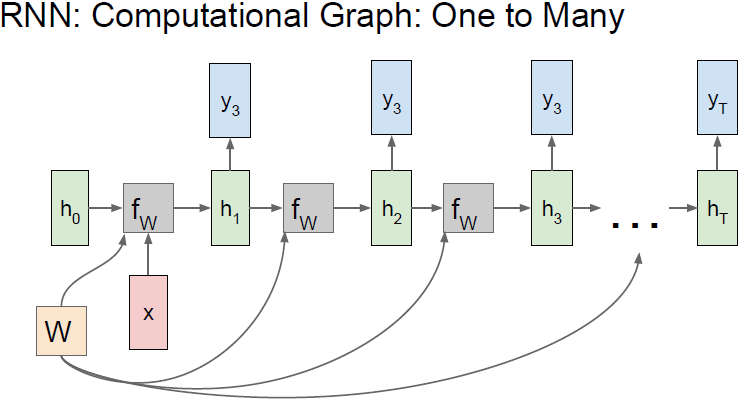
此种结构通常用于自动生成图片描述等问题。
Sequence to sequence
Many-to-one+One-to-many
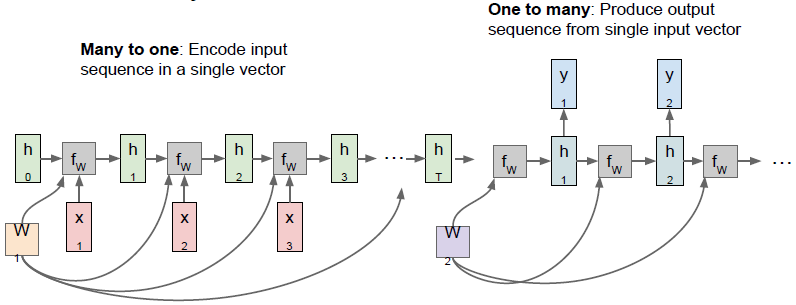
此种结构通常用于机器翻译。编码阶段会接收到一个不定长的输入序列(如一个句子),然后整个句子会被编码器网络最终的隐层状态编码成一个单独的向量。解码阶段每一个时间步下会做出一个预测,将其还原成一个句子。
示例:字符级别语言模型
现在有vocabulary:[h, e, l, o],example training sequence:“hello”。我们希望输入前一个字母后网络能够预测出下一个字母是什么。
训练过程如下:
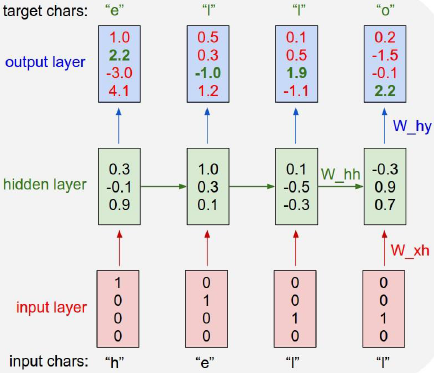
我们可以看到第一个时间步输入“h”,应该输出“e”,但预测结果score最高的是“o”。
测试过程如下所示:
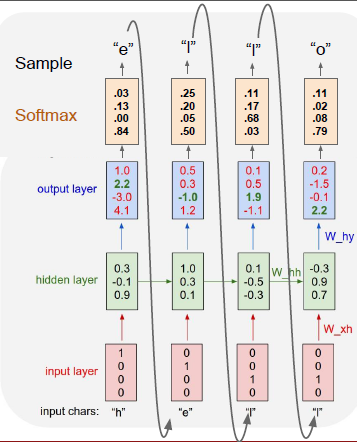
在测试时,一次输入一个样本字符,将输出的字符反馈给模型(这里先不用去看数值,虽然h后面o的可能性最大,但是这里假设就是e)。
接下来我们就要利用Loss来backpropagation修正整个网路,RNN通过时间进行反向传播过程如下图所示:
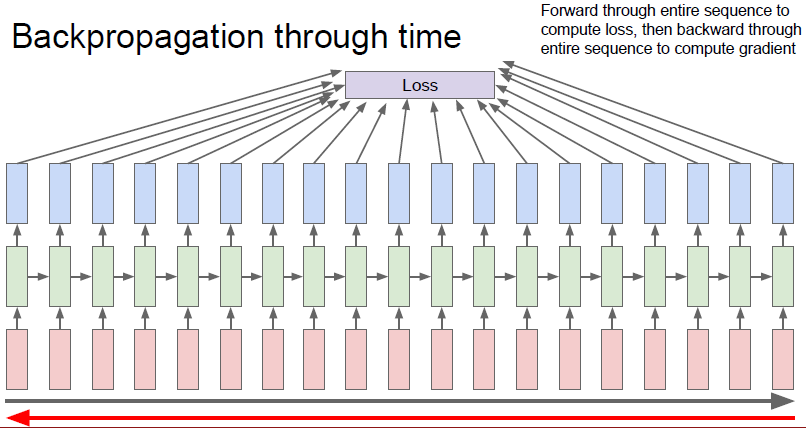
由上图可以看出如果直接是在全局计算的话,会发现显存或内存不够,而且计算过程十分耗时,因为每计算一次梯度都必须做一次前向计算,遍历所有的训练集,然后反向传播每次也会遍历一遍训练集。
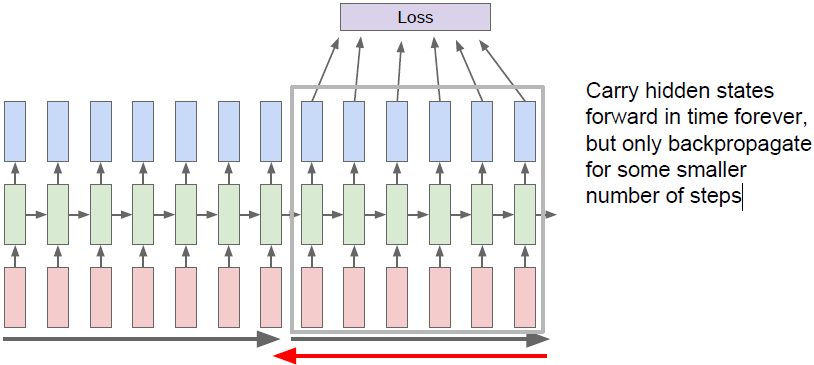
在实际中人们通常采用一种近似方法,我们称之为延时间的截断(Truncated)反向传播方法。在训练模型时,前向计算若干步(如100),仅计算这个子序列的Loss,然后沿子序列反向传播并计算梯度更新参数,如下图所示。
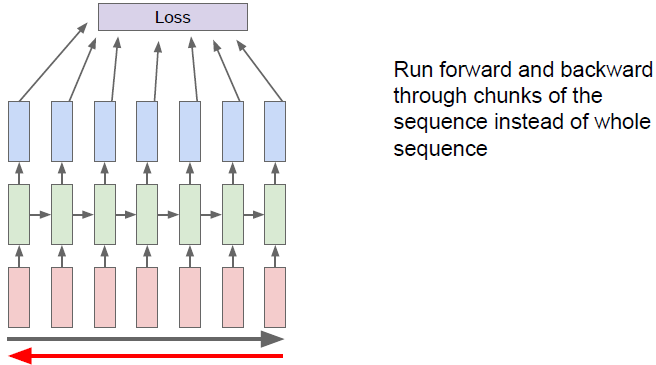
重复上述batch的计算过程(进入下一个100步),前向传播与第一个batch无异(需导入上一个batch最后得到的隐藏状态
),但是在计算梯度时,我们仅根据第二批数据反向传播误差,仅更新该batch中的参数(如下图所示)。
Andrej Karpathy写了一个Vanilla RNN简单的示例程序:min-char-rnn.py,顺便给大家推荐该代码作者写的详解 karpathy’blog。
RNN的可解释性
[Karpathy, Johnson, and Fei-Fei: Visualizing and Understanding Recurrent Networks, ICLR Workshop 2016]
该论文中作者训练了一个字符层级的语言模型循环神经网络,然后从隐藏向量中选取一个元素,通过一个序列过程来看这个隐藏向量的值,试图了解这些不同隐藏状态正在寻找的东西。

从向量中选择一个元素,然后让句子继续向前运行通过训练好的模型,接下来每个字符的颜色对应于隐藏矢量在读取序列时的每个时间步长的单个标量元素的大小。
图像标注问题
[Karpathy A, Li F F. Deep visual-semantic alignments for generating image descriptions, CVPR 2015]
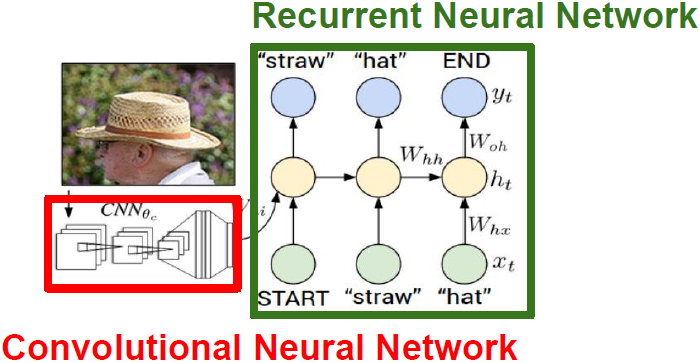
我们希望输入一个图像,然后输出自然语言的图像语义信息。
模型中有一部分卷积神经网络用来处理输入的图像信息,它将产生图像的特征向量,然后输入到循环神经网络语言模型的第一个时间步中,一次一个地生成标题的单词。

我们把输入图像输入到卷积神经网络中,但是我们不是使用这个图像网络模型中最后得到的softmax值,而是使用模型末端的4096维向量,我们用这个向量来概述整个图像的内容。
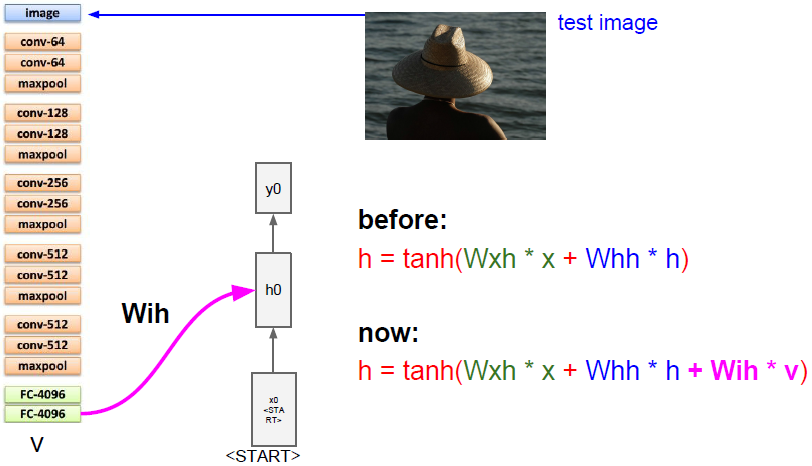
当我们讨论递归神经网络语言模型时,我们需要知道模型的第一个初始化输入,来告诉它开始生成文字。本论文中作者给它了一些特殊的开始记号。在之前的递归神经网络语言模型中我们已经了解了这些矩阵的计算公式,即把当前时间步的输入以及前一个时间步的隐藏状态结合到下一个时间步的隐藏状态。但我们现在还需要添加图片信息,需要用完全不同的方法来整合这些信息,一个简单的方式是加入第三个权重矩阵,它在每个时间步中添加图像信息来计算下一个隐藏状态(如上图所示)。
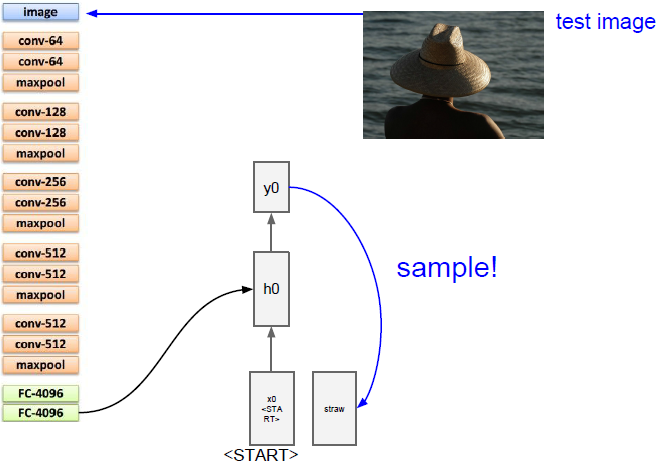
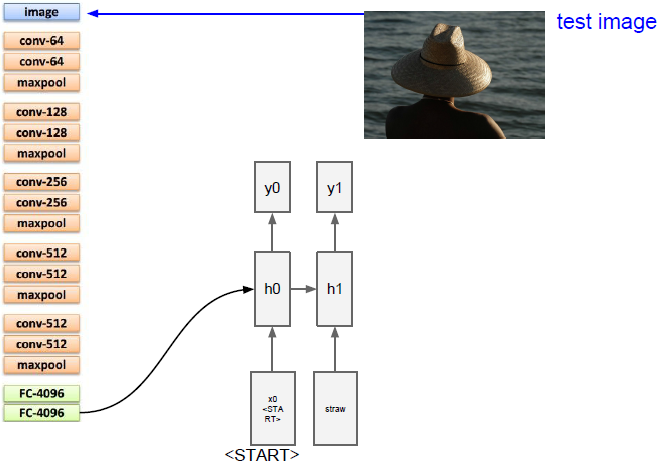
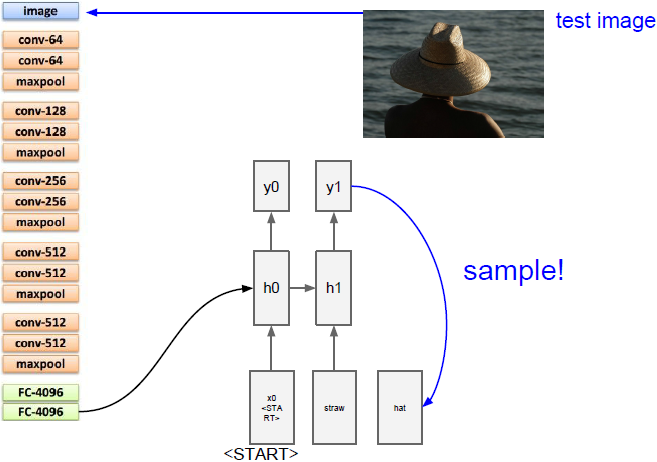
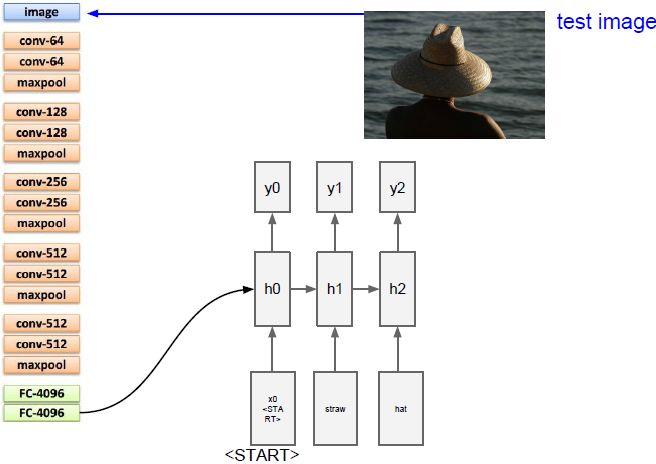
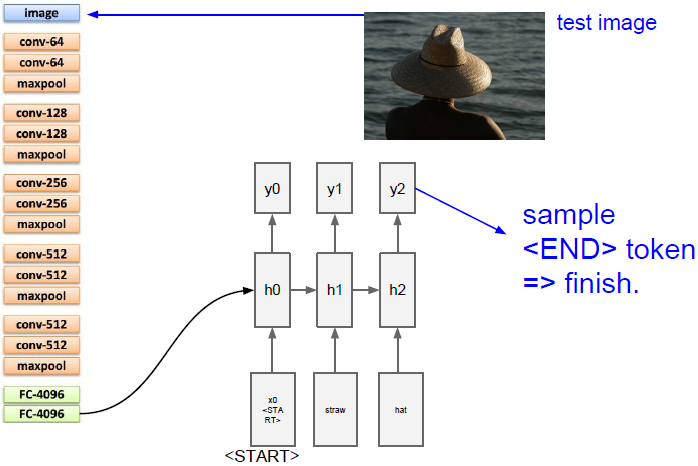
上面五幅图演示了生成句子的过程。
现在我们需要计算词汇表中所有scores的分布,在这里我们的词汇表是类似所有英语词汇的东西,所以他可能会相当大,我们将从分布中采样并在下一次时间步时当做输入传入。依次重复上述步骤,我们将生成完整的句子。一旦我们采样到特殊停止标记(类似于句号)就停止生成。在训练时,我们在每个标题末尾都放上结束的标志,这样在训练过程中结束标记就出现在序列的末尾。在测试时,它倾向于在完成生成句子后对这些结束标记进行采样。
Attention机制
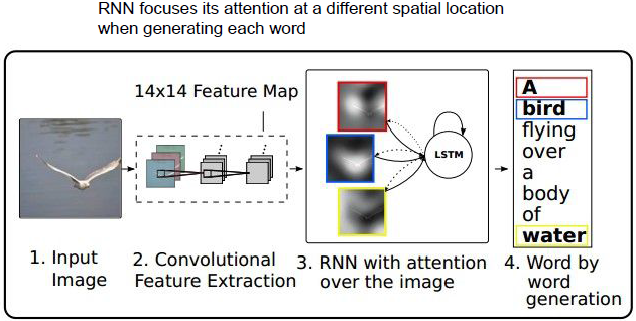
当我们生成这个图片标题的文字时,我们允许模型来引导它们的注意到图像不同的部分。
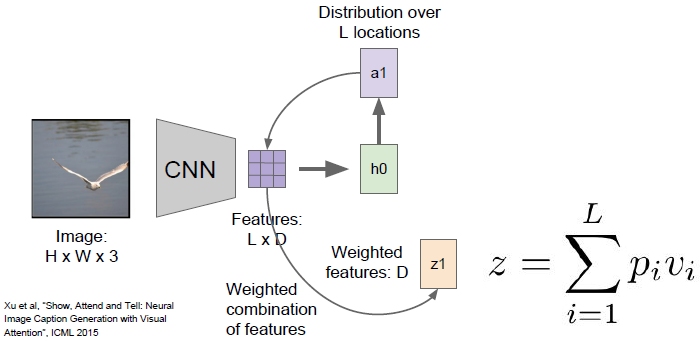
通常的做法是,相比于产生一个单独的向量来整合整个图像,该方法的卷积神经网络倾向于产生由向量构成的网络给每幅图片中特殊的地方都用一个向量表示。当我们在前向传播时,除了在每一时间步中对词汇表进行采样外,还会在图像中想要查看的位置上产生一个分布。图像位置的分布可以看成是一种模型在训练过程中应该关注哪里的张量。因此第一个隐藏状态
计算在图片位置上的分布
,它将会回到向量集合,给出一个概要向量
,把注意力集中在图像的某一部分上。
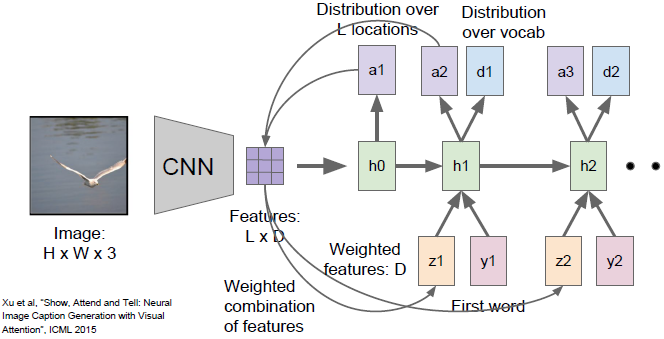
现在这个概要向量得到了反馈,作为神经网络下一时间步的额外输入。接着
将产生两个输出,一个是我们在词汇表上的分布
,一个是图像位置的分布
,整个过程将会继续下去,它在每个时间步都会做这两件不同的事情。
Ps:软注意力机制采用的是加权组合,所有图像位置中的所有特征。硬注意力机制中,我们限制模型在每一步只选择一个位置来观察图片。在硬注意力的情况下选择图像的位置有点复杂,因为这不是一个可微函数,所以需要使用一些比vanilla反向传播算法高级一点的算法,以便能够在那样的情况下训练模型。
视觉问答:RNNs with Attention

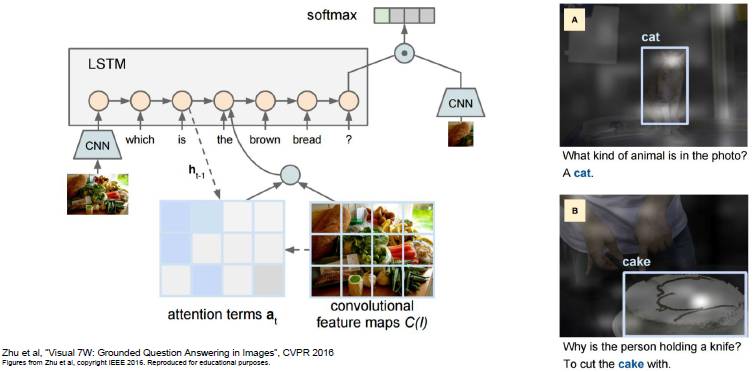
这是一个多对一的情形(选出正确的答案)。我们的模型需要将自然语言序列作为输入,我们可以设想针对输入问题的每个元素,建立一个递归神经网络,从而将输入问题概括为一个向量。然后我们可以用CNN将图像也概括为一个向量。现在把CNN得出的向量和输入问题的向量结合,通过RNN编程来预测答案的概率分布。有时候会将soft spatial attention结合到视觉问答中,所以在这里可以看到这个模型在试图确定这些问题的答案时它在图像上仍具有spatial attention。
Q:如何将编码图像向量和编码问题向量组合起来?
A:最简单的一种做法是将他们连接起来然后粘贴进FC中。有时也会用一些高级的方法,即在这两个向量之间做乘法从而得到更为强大的函数。
Multilayers RNNs
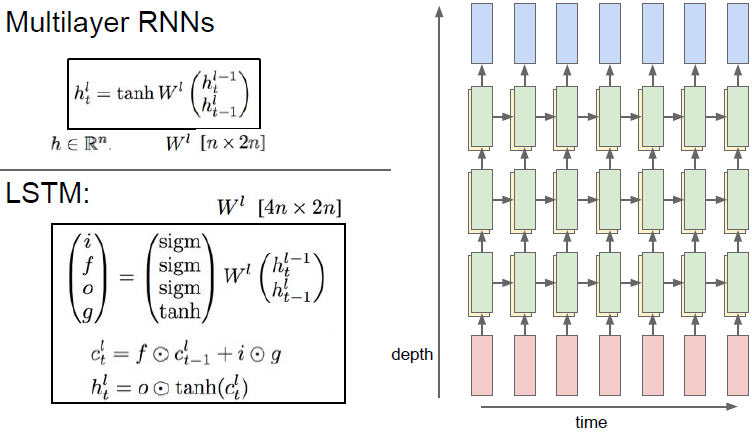
如上所示是一个三层循环神经网络结构图,现在将输入传进模型,然后在第一层的RNN中产生一系列的隐藏状态。在我们运行了RNN的一层之后得到了所有的隐藏状态序列。我们可以将这些隐藏状态序列作为第二层RNN的输入序列,以此类推。
(RNN一般2-4层就足够了)
Vanilla RNN 梯度流
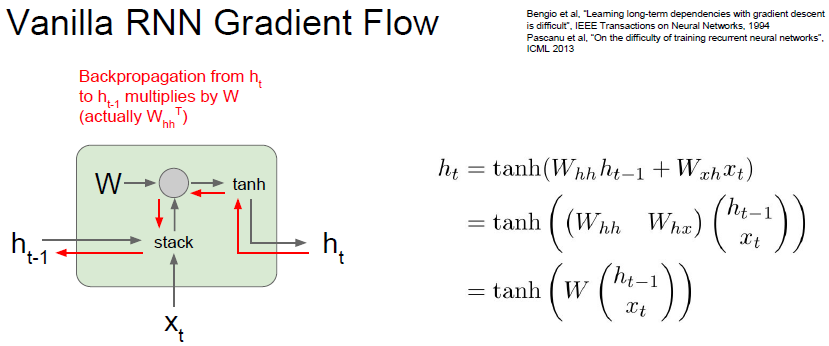
上图中可以看出隐藏状态
的计算过程。计算梯度时,我们会得到
,最后我们需要计算的是
。当我们进行反向传播时,梯度会沿红线反向流动。但是当反向传播流过矩阵乘法门时,实际上是用权重矩阵的转置来做矩阵乘法,这意味着每一次BP经过一个vanilla RNN单元时就需要和权重矩阵相乘一次。
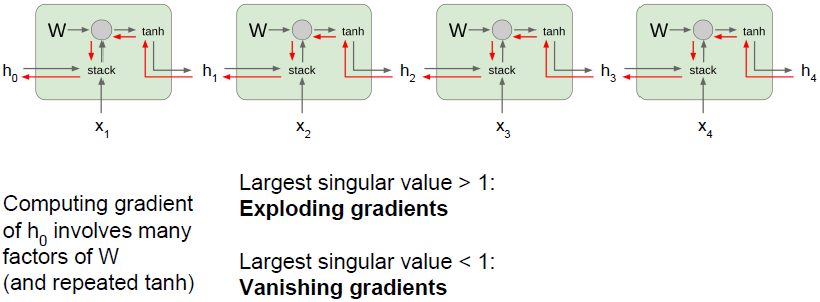
当我们把很多网络单元连接成一个序列,梯度反向流动穿过一些这样的层时,都要乘以一个权重矩阵的转置,这意味着最终
的梯度表达式将会包含很多权重矩阵因子。(再强调一下,每一个单元的
是相同的)
为了便于理解,我们可以将权重矩阵简化为标量。假如我们有一些标量,我们不断地对同一个数值与这些标量做乘法,当有几百时间步时,情况将非常糟糕。在标量的情形中,它要么在这些标量绝对值大于1时发生梯度爆炸,要么当这些标量绝对值小于1时发生梯度消失。唯一能够让这不发生的情况是这些标量值刚好是1。延伸到矩阵的情况时,标量的绝对值替换为权重矩阵的最大奇异值。
解决梯度爆炸的方法:梯度截断
判断梯度的L2范数是否大于某个值。

解决梯度消失的方法:改变RNN结构
引出了下面介绍的LSTM。
长短期记忆网络(LSTM)
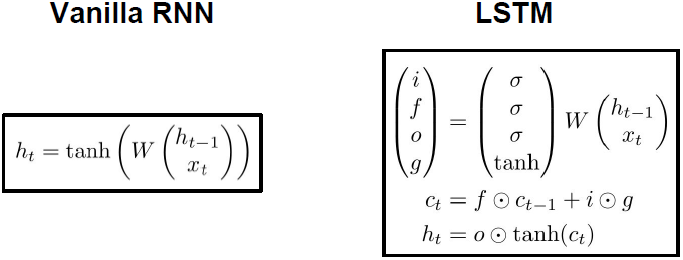
如上图所示,LSTM每个时间步都维持两个隐藏状态。我们称
为隐藏状态,
为单元状态,
相当于保留在LSTM内部的隐藏状态,不会完全暴露到外部去。首先我们传入两个输入来计算四个门i、f、o、g,使用这些门来更新单元状态
,然后将这些单元状态作为参数来计算下一时间步中的隐藏状态。
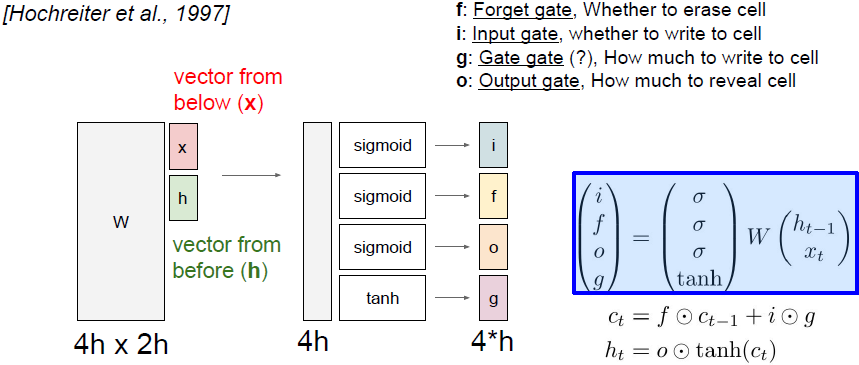
将上一时间步的隐藏状态和当前时间步的输入堆叠在一起,然后乘上一个非常大的权重矩阵w,计算得到四个不同的门向量,每个门向量的大小和隐藏状态一样。
i代表输入门,表示LSTM要接受多少新的输入信息;f是遗忘门,表示要遗忘多少之前的单元记忆(上一时间步的记忆信息);o是输出门,表示我们要展现多少信息给外部;G是门中门,表示我们有多少信息要写到输入单元中去。四个门中i、f、o都用了sigmoid,这意味着输出值都在0和1之间。G用了tanh函数,这意味着输出都在-1到1之间。
从上图公式中我们可以看出单元状态是经过遗忘门逐项相乘的。遗忘门可以看做是由0和1组成的向量,F中0表示我们忘记这个单元状态中的这个元素值,1说明我们想要记住这个单元状态中的这个值。使用遗忘门来断开部分单元状态的值后,我们接下来需要输入门和门中门逐元素相乘。i是由0和1构成的向量,对于单元状态的每个元素值,i的值为1表示我们想要保留单元状态的那个元素,i的值为0表示我们不想保留单元状态对应的那个元素。门中门中的这些值是当前时间步中我们可能会写入到单元状态中去的候选值。单元状态 在每个时间步中都可以被加一或减一。也就是说在单元状态的内部,我们可以保留或者遗忘之前的状态。所以可以把 中的每个元素看作是小的标量计数器。
经过tanh后被压缩到0~1,再用输出门逐元素相乘。输出门告诉我们对于单元状态中的每个元素,当我们在此时间步计算外部的隐藏状态时,是否希望单元状态中的此元素暴露出去。
LSTM示意图:
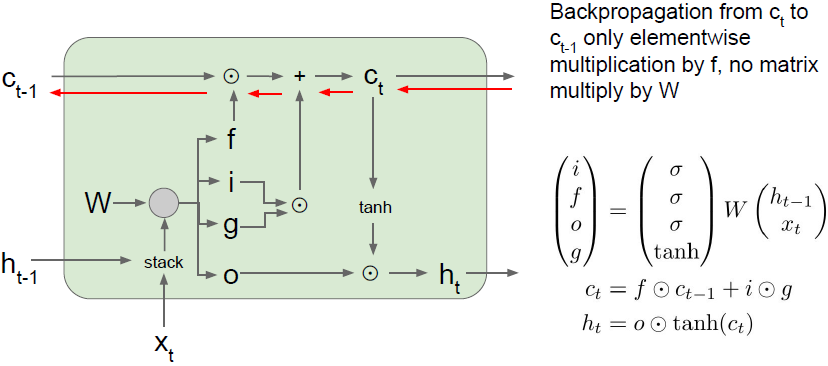
我们通过传输进来的单元获得了上游梯度
,然后通过加法运算向后进行方向传播,这个加法运算仅仅是将上游的梯度复制到这两个分支中,这样上游梯度直接被复制并且通过与遗忘门元素相乘的方式贯穿了反向传播过程。此方法的优点在于这里与遗忘门f相乘是矩阵元素相乘而不是矩阵相乘;另一点是矩阵元素相乘可能会在不同的时间点乘以一个不同的遗忘门(更容易避免梯度消失和梯度爆炸的问题),而在vanilla RNN中我们是不断地乘以相同的权重矩阵;最后一个优点是梯度从最后一个隐藏状态
传递到
只会经过一个tanh。
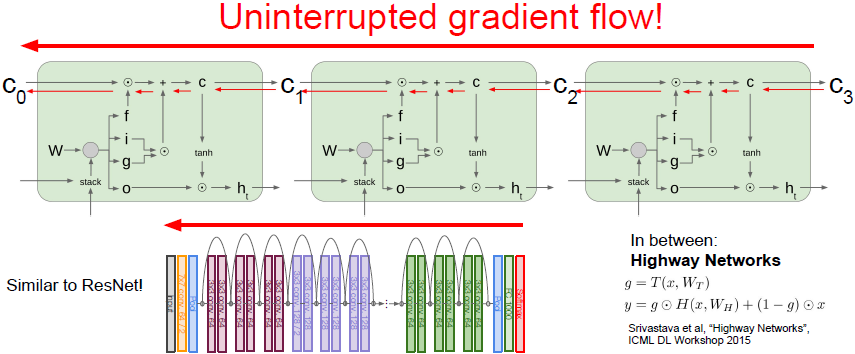
通过单元状态进行反向传播的路径是一种梯度高速公路,使梯度相对畅通无阻地从模型最末端的损失函数返回到模型最开始的初始单元状态(与ResNet类似)。
Q:遗忘门f是一个0~1的数,是否也会导致出现梯度消失的问题?
A:人们常会初始化遗忘门的偏置参数,进而使遗忘门总是非常接近于1。
这里推荐一篇论文: Greff et al. LSTM: A Search Space Odyssey, 2015,这篇论文详细研究了LSTM更新方程的每一个部分。
本博客与https://xuyunkun.com同步更新