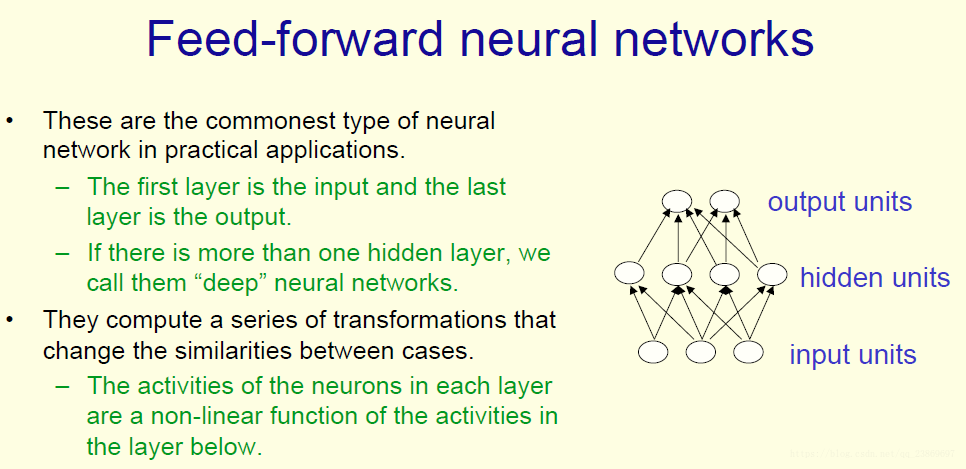
Types of neural network architectures
feed-forward neural network
最常见的一种结构是前馈神经网络.
在该结构中,信息从输入层流入,沿着一个方向通过隐含层直到输出层.
Recurrent neural network
RNN的连接图中包含了有向环路.这意味着如果从一个神经元开始,沿着箭头移动,有时候可能又回到了开始的神经元.RNN参数的动态变化非常复杂,很难训练.RNN是对序列数据非常自然的建模方式 .
RNN在每个时间步都使用相同的权重.
隐层单元决定了它的下一个状态
在每一步都是一样的,它们在每个时间戳获取输入,同时产生输出,而且使用相同的权重矩阵。
RNN具有在隐藏单元中长时间记忆信息的能力。

对称连接网络
在对称连接网络中, 单元间的连接在两个方向权重相同.
不能建模环路.
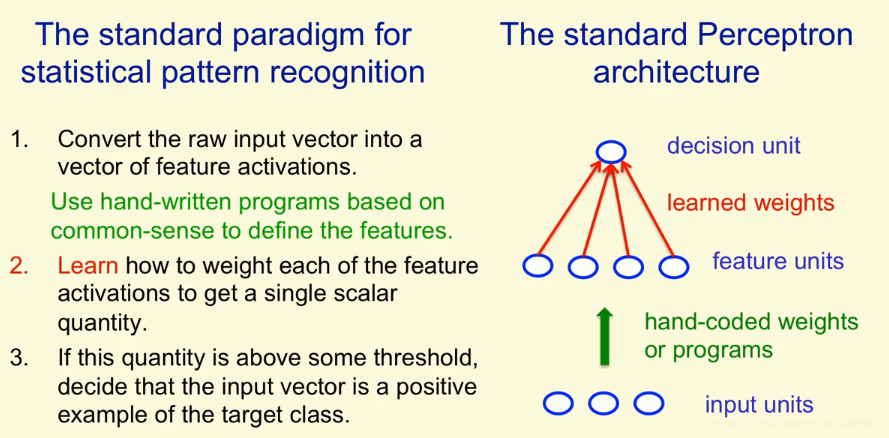
Perceptrons: The first generation of neural networks
在统计模式识别中,使用统计的方式进行模式识别。我们获取原始数据,然后将其转为一组特征向量。比如在手写数字识别的案例中,我们不断尝试不同的特征,最后选出一个能够很好反映原始输入的特征。
在这个过程中,其实就是学习如何去给每一个特征赋予不同的权重。不同的权重反映了特征给你多少证据认为当前的输入是你想识别的输入。当我们把所有的权重加起来,当和大于某一个阈值时,我们认为这是一个正例。
感知机就是一个统计模式识别系统。
把特征向量作为输入,当输出的类别是正确的,那么权重不发生改变。
当输出的类别0,真正的类别是1时,这个分类是错误的,我们所要做的就是把输入向量与权重向量相加;
相反地如果输出的类别是1,真正的类别是0时,分类也是错误的,我们要做的是,将权重向量减去输入特征。
A geometrical view of perceptrons
感知器在学习时发生了什么?
引入权值空间的概念。
对于权值来说,高维空间中的每一个点都对应了一个特定的设定。

由于高维空间大且复杂,我们思考权值空间。在这个空间中,每一个维度对应一个权值。空间中的每一个点表示所有权重的一个特定的设定。加入我们不考虑阈值,我们能够把每一个训练案例表示成一个穿过原点的超平面。所以空间中的点对应着权值向量,而所有的训练案例对应平面。而且,对于特定的训练案例,权重必须位于该超平面的一侧,以便为该训练案例获得正确的答案。
上面说了,一个训练案例代表一个超平面,在二维图中显示为一条黑线。这个超平面经过原点并垂直于输入向量,如图中的蓝线。
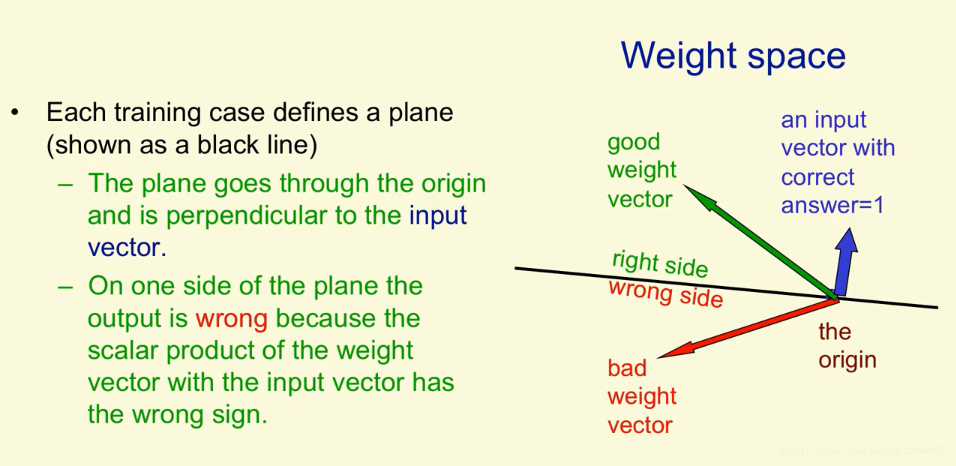
考虑训练案例的正确答案为1。对于这个训练案例,他的权重向量必须在超平面正确的一边才能得到正确的答案。只有当权重向量和输入向量的夹角小于90°时(绿色箭头表示的权重向量),他们的数量积才会大于0, 这时我们说得到的结果是正确的。当夹角大于90°时(红色的权重向量),他们的数量积小于0, 我们说得到的结果是错误的。
再举一个例子:
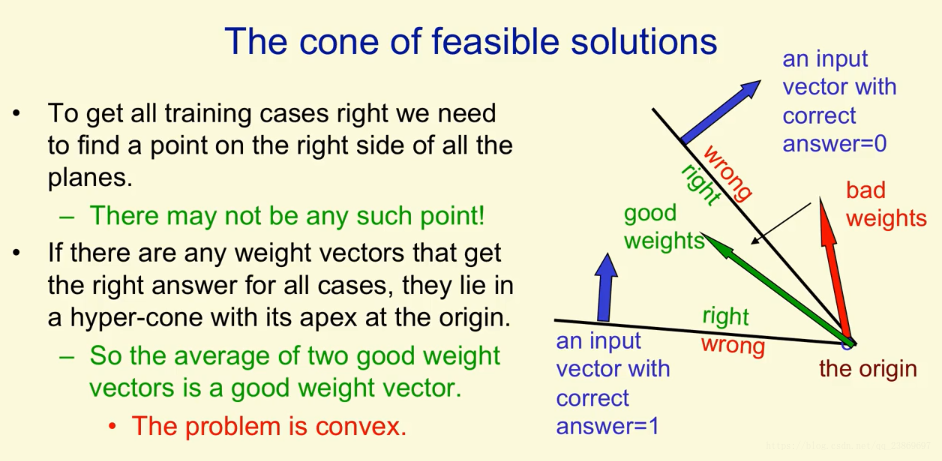
我们可能找不到对于所有的训练数据都正确的那个点,即权重空间向量。如上图中绿色的箭头就表示满足了两个训练数据。权重向量与标注为0的输出向量夹角大于90°,与标注为1 的输入向量夹角小于90°。
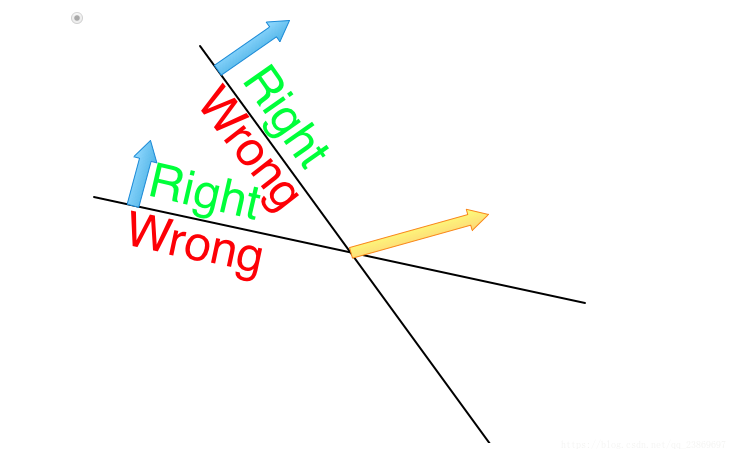
Consider two inputs that both have a label of 1. In the pictures below they are represented as hyperplanes and the feasible region for an input is any point within the region labelled “Right”. Which of the following weight vectors, represented by a yellow arrow, will correctly classify the two inputs?
Why the learning works?
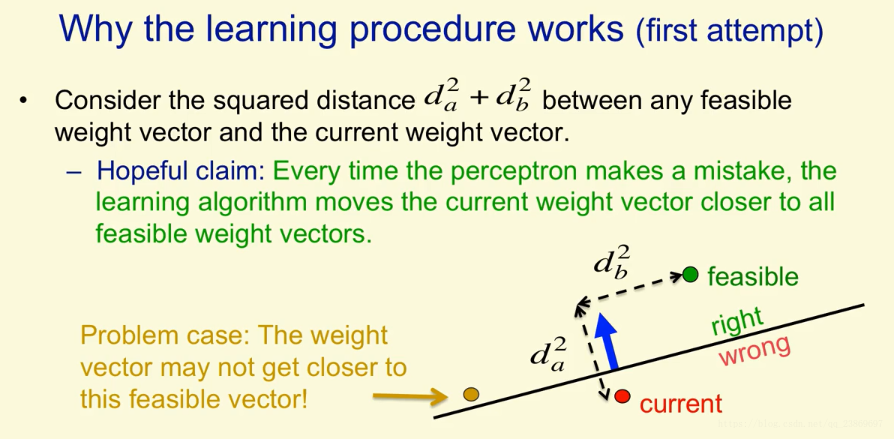
这里使用几何知识解释在学习过程中权重空间发生了什么。我们假设权重空间存在这么一个向量叫feasible vector. 它对于所有的训练数据都能落在正确的那一边。如图中绿色的点。如果出现了一个错误的训练案例,我们更新当前的权重。我们可以把当前权重向量与feasible vector的平方距离表示出来。我们希望每犯一次错,我们当前的权重就越靠近所有的feasible vector。不幸的是,当我们把金色的点当做feasible vector,在超平面正确的那边有一个输入向量,那么那个红色的当前权重向量在错误的一边。此时我们把输入向量加上权重向量去更新当前向量实际上会使权重更加远离金色的feasible weight vector。这样我们的Hopeful clain就无效了,但是我们能修正它,让它始终有效。
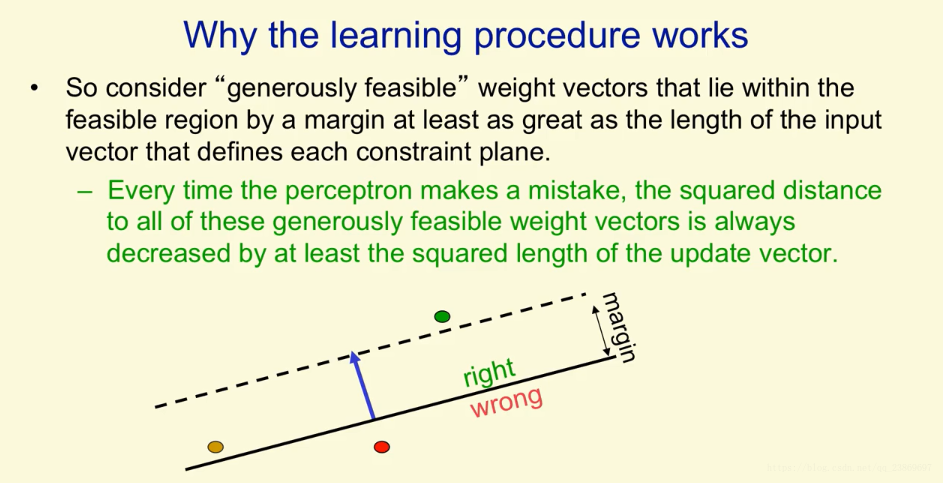
我们定义一个通用的feasible weight factor。这个权重向量不仅对于每一个输入都是中正确的,而且它还有一些余量。这余量至少很输入向量的长度一样。

what percetron cannot do
如果输入特征选得对,那么感知机几乎能做任何事情。当特征选得不好,它的能力很大程度受限。
考虑一个简单例子,这里只有2个正例和2个反例。输入特征是1bit的特征,表示特征取值要么为0要么为1.二值阈值神经元甚至不能告诉两个1bit的特征是一样的。下面对其做了改进:

要想正确分类,他们的权重必须满足上面的权重。我们可以看到,根本不能够满足。
从下面的图理解为什么不能分
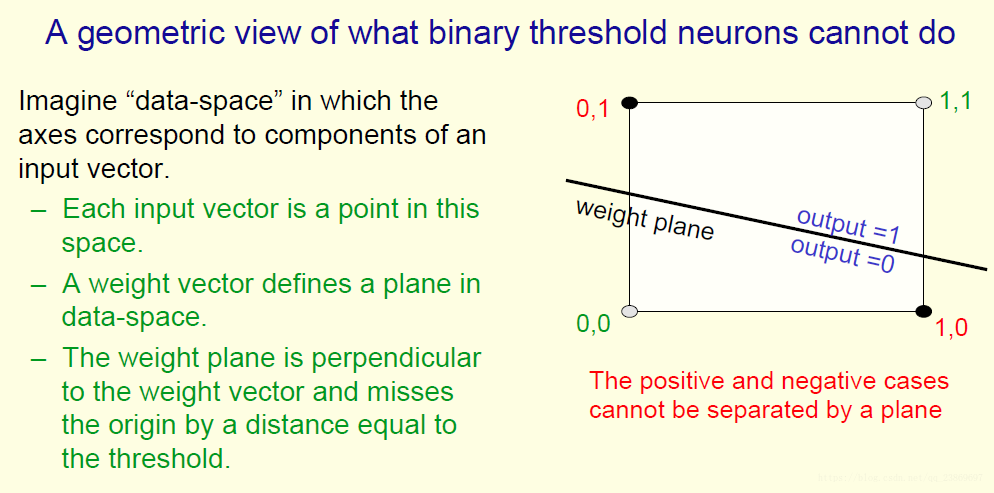
我们也称这种问题为线性不可分问题。
下面来讨论另外一个问题,环绕转换问题。就是说一个图片发生了平移,我们怎么识别它为同一个目标的问题。
如果我们把像素当做特征,当发生转换时,这个神经元是分不出来的。
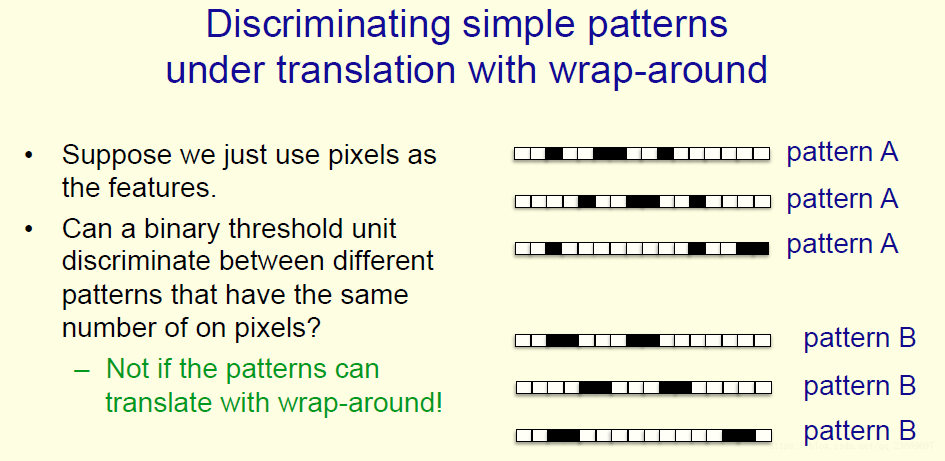
对于模式A和B,他们发生了转换之后,我们视网膜上的每一个像素会被4个转移后不同的位置像素激活,神经网络上不同的单元会被不用的权重激活。所以我们的感知机不能识别发生了转移的模式。

暂时的结论是我们的感知机不足够好,神经网络不够好。长远的结论是神经网络只有在我们能够学习到特征感知机(feature detector)的时候变得很强大。学习权重和的特征感知机(feature detector)是不足够的,我们必须学习特征感知机(feature detector)本身。
第二代神经网络全部都是关于怎么学习的特征感知机(feature detector)。我们添加隐藏层,使用不同激活函数,但是问题在于如何训练这样的网络。

Coursera:Neural Networks for Machine Learning
Hinton