概率论与数理统计(Probability & Statistics I) 概率论与数理统计(Probability & Statistics II)
Cheat Sheets: Probability Cheatsheet v2.0 Probability Cheat Sheet
基本概念 概率论 (Theory of Probability): 是一门揭示随机现象统计规律性的数学学科统计学 (Statistics):是一门通过收集、整理、分析数据等手段以达到推断或预测考察对象本质或未来的学科.随机现象 (random phenomenon):个别实验结果呈现不确定性,大量重复实验又具有统计规律性的现象随机试验 (random experiment):对随机现象的观测样本和样本空间 :试验的每一个结果称为一个样本(sample),记为s随机事件 (random event):实际问题中,通常会关心随机试验一些特定的结果,它们是S的(可测)子集,称为事件(event),通常用大写字母A, B,…表示。可列集 (countable):是指一个无穷集S,其元素可与自然数形成一一对应,因此可表为
S
=
{
s
1
,
s
2
,
…
}
S=\{s_1,s_2,…\}
S = { s 1 , s 2 , … }
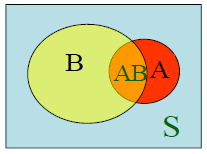
事件的关系与运算 :设以下大写英文字母均为样本空间S中的事件
s
∈
A
⟺
s\in A\iff
s ∈ A ⟺
A
⊂
B
⟺
A⊂ B\iff
A ⊂ B ⟺
A
=
B
⟺
A
⊂
B
且
B
⊂
A
A=B\iff A⊂ B且B⊂ A
A = B ⟺ A ⊂ B 且 B ⊂ A
A
∪
B
⟺
A∪ B\iff
A ∪ B ⟺
A
∩
B
⟺
A∩ B\iff
A ∩ B ⟺
A
−
B
⟺
A-B\iff
A − B ⟺
A
ˉ
=
S
−
A
⟺
\bar A=S-A \iff
A ˉ = S − A ⟺
S
S
S
∅
\varnothing
∅
{
s
}
\{s\}
{ s }
A
B
=
∅
AB=\varnothing
A B = ∅
交换律
A
∪
B
=
B
∪
A
A
∩
B
=
B
∩
A
A∪ B=B∪ A\\ A∩ B=B∩ A
A ∪ B = B ∪ A A ∩ B = B ∩ A
结合律
(
A
∪
B
)
∪
C
=
A
∪
(
B
∪
C
)
(
A
∩
B
)
∩
C
=
A
∩
(
B
∩
C
)
(A∪ B)∪ C=A∪ (B∪ C)\\ (A∩ B)∩ C=A∩ (B∩ C)
( A ∪ B ) ∪ C = A ∪ ( B ∪ C ) ( A ∩ B ) ∩ C = A ∩ ( B ∩ C )
分配律
A
∪
(
B
∩
C
)
=
(
A
∪
B
)
∩
(
A
∪
B
)
A
∩
(
B
∪
C
)
=
(
A
∩
B
)
∪
(
A
∩
B
)
A∪ (B∩ C)=(A∪ B)∩ (A∪ B)\\ A∩ (B∪ C)=(A∩ B)∪ (A∩ B)
A ∪ ( B ∩ C ) = ( A ∪ B ) ∩ ( A ∪ B ) A ∩ ( B ∪ C ) = ( A ∩ B ) ∪ ( A ∩ B )
对偶律(De Morgan)
A
∪
B
‾
=
A
ˉ
∩
B
ˉ
,
A
∩
B
‾
=
A
ˉ
∪
B
ˉ
⋃
i
=
1
n
A
i
‾
=
⋂
i
=
1
n
A
i
ˉ
,
⋂
i
=
1
n
A
i
‾
=
⋃
i
=
1
n
A
i
ˉ
\overline{ A∪ B}=\bar A∩\bar B ,\quad \overline{ A∩ B}=\bar A∪\bar B \\ \overline{\displaystyle\bigcup_{i=1}^{n}A_i}=\displaystyle\bigcap_{i=1}^{n}\bar{A_i} ,\quad \overline{\displaystyle\bigcap_{i=1}^{n}A_i}=\displaystyle\bigcup_{i=1}^{n}\bar{A_i}
A ∪ B = A ˉ ∩ B ˉ , A ∩ B = A ˉ ∪ B ˉ i = 1 ⋃ n A i = i = 1 ⋂ n A i ˉ , i = 1 ⋂ n A i = i = 1 ⋃ n A i ˉ
频率 (frequency):
f
n
(
A
)
=
n
A
n
f_n(A)=\dfrac{n_A}{n}
f n ( A ) = n n A
n
A
n_A
n A
f
n
(
A
)
f_n(A)
f n ( A ) 频率的性质
1
°
0
⩽
f
n
(
A
)
⩽
1
1\degree\quad 0⩽ f_n(A) ⩽ 1
1 ° 0 ⩽ f n ( A ) ⩽ 1
2
°
f
n
(
S
)
=
1
2\degree\quad f_n(S)= 1
2 ° f n ( S ) = 1
3
°
f
n
(
⋃
i
=
1
k
A
i
)
=
∑
i
=
1
k
f
n
(
A
i
)
,
A
1
,
A
2
,
⋯
,
A
k
3\degree\quad f_n(\displaystyle\bigcup_{i=1}^{k}A_i)=\displaystyle\sum_{i=1}^{k}f_n(A_i),\ A_1,A_2,\cdots,A_k
3 ° f n ( i = 1 ⋃ k A i ) = i = 1 ∑ k f n ( A i ) , A 1 , A 2 , ⋯ , A k
概率 (probability)
P
(
A
)
=
p
P(A)=p
P ( A ) = p
P
(
A
)
⩾
0
P(A)⩾ 0
P ( A ) ⩾ 0
P
(
S
)
=
1
P(S)=1
P ( S ) = 1
A
i
A
j
=
∅
,
(
i
≠
j
)
⟹
P
(
⋃
i
=
1
∞
A
i
)
=
∑
i
=
1
∞
P
(
A
i
)
A_iA_j=\varnothing,(i\neq j)\implies P(\displaystyle\bigcup_{i=1}^{∞}A_i)=\displaystyle\sum_{i=1}^{∞}P(A_i)
A i A j = ∅ , ( i = j ) ⟹ P ( i = 1 ⋃ ∞ A i ) = i = 1 ∑ ∞ P ( A i ) 概率的性质
1
°
P
(
∅
)
=
0
1\degree\quad P(\varnothing)= 0
1 ° P ( ∅ ) = 0
2
°
P
(
A
)
=
1
−
P
(
A
ˉ
)
2\degree\quad P(A)=1-P(\bar A)
2 ° P ( A ) = 1 − P ( A ˉ )
3
°
A
i
A
j
=
∅
,
(
i
≠
j
)
⟹
P
(
⋃
i
=
1
k
A
i
)
=
∑
i
=
1
k
P
(
A
i
)
3\degree\quad A_iA_j=\varnothing,(i\neq j)\implies P(\displaystyle\bigcup_{i=1}^{k}A_i)=\displaystyle\sum_{i=1}^{k}P(A_i)
3 ° A i A j = ∅ , ( i = j ) ⟹ P ( i = 1 ⋃ k A i ) = i = 1 ∑ k P ( A i )
4
°
A
⊂
B
⟹
P
(
B
−
A
)
=
P
(
B
)
−
P
(
A
)
,
P
(
B
)
⩾
P
(
A
)
4\degree\quad A⊂ B\implies P(B-A)=P(B)-P(A),\ P(B)⩾ P(A)
4 ° A ⊂ B ⟹ P ( B − A ) = P ( B ) − P ( A ) , P ( B ) ⩾ P ( A )
5
°
P
(
A
∪
B
)
=
P
(
A
)
+
P
(
B
)
−
P
(
A
B
)
5\degree\quad P(A∪ B)=P(A)+P(B)-P(AB)
5 ° P ( A ∪ B ) = P ( A ) + P ( B ) − P ( A B )
等可能概型 (classical probability):若试验满足,样本空间S中样本点有限(有限性),出现每一个样本点的概率相等(等可能性),称这种试验为等可能概型(或古典概型)。
P
(
A
)
=
k
n
P(A)=\dfrac{k}{n}
P ( A ) = n k
几何概型 (geometric probability):(将等可能的原理进一步拓广)
R
n
\R^n
R n
R
n
\R^n
R n
条件概率 (conditional probability):设A,B为事件,P(A)>0,定义
P
(
B
∣
A
)
=
P
(
A
B
)
P
(
A
)
P(B|A)=\frac{P(AB)}{P(A)}
P ( B ∣ A ) = P ( A ) P ( A B ) A 发生条件下B 发生的概率
S
→
A
S\to A
S → A
P
(
⋅
)
→
P
(
⋅
∣
A
)
P(\cdot)\to P(\cdot|A)
P ( ⋅ ) → P ( ⋅ ∣ A )
条件概率性质 :
P
(
⋅
∣
A
)
P(\cdot|A)
P ( ⋅ ∣ A )
P
(
B
∣
A
)
⩾
0
P(B|A)⩾ 0
P ( B ∣ A ) ⩾ 0
P
(
S
∣
A
)
=
1
P(S|A)=1
P ( S ∣ A ) = 1
B
i
B
j
=
∅
,
(
i
≠
j
)
⟹
P
(
⋃
i
=
1
∞
B
i
∣
A
)
=
∑
i
=
1
∞
P
(
B
i
∣
A
)
B_iB_j=\varnothing,(i\neq j)\implies P(\displaystyle\bigcup_{i=1}^{∞}B_i|A)=\displaystyle\sum_{i=1}^{∞}P(B_i|A)
B i B j = ∅ , ( i = j ) ⟹ P ( i = 1 ⋃ ∞ B i ∣ A ) = i = 1 ∑ ∞ P ( B i ∣ A ) 乘法公式
P
(
A
B
)
=
P
(
A
)
P
(
B
∣
A
)
=
P
(
B
)
P
(
A
∣
B
)
P(AB)=P(A)P(B|A)=P(B)P(A|B)
P ( A B ) = P ( A ) P ( B ∣ A ) = P ( B ) P ( A ∣ B )
P
(
A
B
C
)
=
P
(
A
)
P
(
B
∣
A
)
P
(
C
∣
A
B
)
P(ABC)=P(A)P(B|A)P(C|AB)
P ( A B C ) = P ( A ) P ( B ∣ A ) P ( C ∣ A B )
P
(
A
1
A
2
⋯
A
n
)
=
P
(
A
1
)
P
(
A
2
∣
A
1
)
P
(
A
3
∣
A
1
A
2
)
⋯
P
(
A
n
∣
A
1
A
2
⋯
A
n
−
1
)
P(A_1A_2\cdots A_n)=P(A_1)P(A_2|A_1)P(A_3|A_1A_2)\cdots P(A_n|A_1A_2\cdots A_{n-1})
P ( A 1 A 2 ⋯ A n ) = P ( A 1 ) P ( A 2 ∣ A 1 ) P ( A 3 ∣ A 1 A 2 ) ⋯ P ( A n ∣ A 1 A 2 ⋯ A n − 1 )
事件独立性 (independent):设A,B是两随机事件,若
P
(
A
B
)
=
P
(
A
)
P
(
B
)
P(AB)=P(A)P(B)
P ( A B ) = P ( A ) P ( B )
A
A
A
B
B
B
⟺
A
ˉ
\iff \bar A
⟺ A ˉ
B
B
B
⟺
A
\iff A
⟺ A
B
ˉ
\bar B
B ˉ
⟺
A
ˉ
\iff \bar A
⟺ A ˉ
B
ˉ
\bar B
B ˉ
{
P
(
A
B
)
=
P
(
A
)
P
(
B
)
P
(
B
C
)
=
P
(
C
)
P
(
C
)
P
(
A
C
)
=
P
(
A
)
P
(
C
)
P
(
A
B
C
)
=
P
(
A
)
P
(
B
)
P
(
C
)
\begin{cases} P(AB)=P(A)P(B) \\ P(BC)=P(C)P(C) \\ P(AC)=P(A)P(C) \\ P(ABC)=P(A)P(B)P(C) \end{cases}
⎩ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎧ P ( A B ) = P ( A ) P ( B ) P ( B C ) = P ( C ) P ( C ) P ( A C ) = P ( A ) P ( C ) P ( A B C ) = P ( A ) P ( B ) P ( C ) 推广 :事件
A
1
,
A
2
,
⋯
,
A
n
A_1,A_2,\cdots,A_n
A 1 , A 2 , ⋯ , A n
2
⩽
k
⩽
n
2⩽ k ⩽ n
2 ⩽ k ⩽ n
P
(
A
i
1
A
i
2
⋯
A
i
k
)
=
∏
j
=
1
k
P
(
A
i
j
)
P(A_{i_1}A_{i_2}\cdots A_{i_k})=\displaystyle\prod_{j=1}^{k}P(A_{i_j})
P ( A i 1 A i 2 ⋯ A i k ) = j = 1 ∏ k P ( A i j )
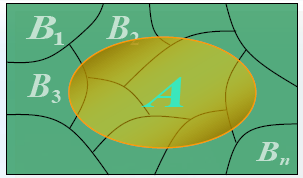
全概率公式 (complete probability formula):一个用于计算概率的公式,先化整为零,再聚零为整
B
1
,
⋯
,
B
n
B_1,\cdots,B_n
B 1 , ⋯ , B n
S
S
S
A
A
A
P
(
A
)
=
∑
i
=
1
n
P
(
A
∣
B
i
)
P
(
B
i
)
P(A)=\displaystyle\sum_{i=1}^{n}P(A|B_i)P(B_i)
P ( A ) = i = 1 ∑ n P ( A ∣ B i ) P ( B i )
S
S
S
B
1
,
⋯
,
B
n
B_1,\cdots,B_n
B 1 , ⋯ , B n
(
1
)
⋃
i
=
1
n
B
i
=
S
(
2
)
B
i
B
j
=
∅
,
(
i
,
j
=
1
,
2
,
⋯
,
n
;
i
≠
j
)
(1)\ \displaystyle\bigcup_{i=1}^{n}B_i=S\quad (2)\ B_iB_j=\varnothing,(i,j=1,2,\cdots,n;\ i\neq j)
( 1 ) i = 1 ⋃ n B i = S ( 2 ) B i B j = ∅ , ( i , j = 1 , 2 , ⋯ , n ; i = j )
贝叶斯公式(Bayes formula) :全概率公式通过划分
{
B
i
∣
i
=
1
,
⋯
,
n
}
\{B_i |i=1,\cdots,n\}
{ B i ∣ i = 1 , ⋯ , n }
A
A
A
B
i
B_i
B i
B
1
,
⋯
,
B
n
B_1,\cdots,B_n
B 1 , ⋯ , B n
S
S
S
A
A
A
i
=
1
,
⋯
,
n
i=1,\cdots,n
i = 1 , ⋯ , n
P
(
B
i
∣
A
)
=
P
(
A
∣
B
i
)
P
(
B
i
)
∑
i
=
1
n
P
(
A
∣
B
i
)
P
(
B
i
)
P(B_i|A)=\dfrac{P(A|B_i)P(B_i)}{\displaystyle\sum_{i=1}^{n}P(A|B_i)P(B_i)}
P ( B i ∣ A ) = i = 1 ∑ n P ( A ∣ B i ) P ( B i ) P ( A ∣ B i ) P ( B i )
贝叶斯公式是关于随机事件
A
A
A
B
B
B
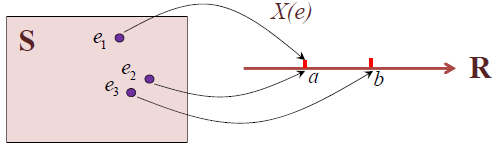
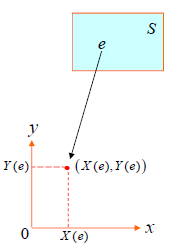
随机变量 :设随机试验的样本空间为
S
S
S
X
=
X
(
e
)
X=X(e)
X = X ( e )
S
S
S
X
(
e
)
X(e)
X ( e )
X
X
X
X
(
e
)
:
S
→
R
X(e):S\to R
X ( e ) : S → R
A
=
{
e
:
X
(
e
)
∈
I
}
=
{
X
∈
I
}
,
I
⊂
R
A=\{e : X(e)\in I\}=\{X\in I\}, I⊂ \R
A = { e : X ( e ) ∈ I } = { X ∈ I } , I ⊂ R
S
=
{
H
H
H
,
H
H
T
,
H
T
H
,
H
T
T
,
T
H
H
,
T
H
T
,
T
T
H
,
T
T
T
}
S=\{HHH,HHT,HTH,HTT,THH,THT,TTH,TTT\}
S = { H H H , H H T , H T H , H T T , T H H , T H T , T T H , T T T }
X
X
X
X
⩾
1
X⩾ 1
X ⩾ 1
i
≠
j
i\neq j
i = j
{
X
=
i
}
∩
{
X
=
j
}
=
∅
\{X=i\}∩\{X=j\}=\varnothing
{ X = i } ∩ { X = j } = ∅
ξ
,
η
ξ,η
ξ , η
定义 :若随机变量X的取值为有限个或可数 , 则称 X 为离散(discrete)型随机变量。分布律 (distribution law):离散随机变量在各特定取值上的概率,也称概率质量函数(probability mass function, PMF)
P
{
X
=
x
k
}
=
p
k
,
k
=
1
,
2
,
⋯
P\{X=x_k\}=p_k,\ k=1,2,\cdots
P { X = x k } = p k , k = 1 , 2 , ⋯
X
X
X
x
1
x
2
⋯
x
k
⋯
x_1\quad x_2 \quad \cdots\quad x_k\quad \cdots
x 1 x 2 ⋯ x k ⋯ 随机变量的所有可能取值
P
P
P
p
1
p
2
⋯
p
k
⋯
p_1\quad p_2 \quad \cdots\quad p_k\quad \cdots
p 1 p 2 ⋯ p k ⋯ 取每个可能取值相应的概率
分布律满足:
p
k
⩾
0
,
∑
k
=
1
+
∞
p
k
=
1
p_k⩾ 0,\ \displaystyle\sum_{k=1}^{+∞}p_k=1
p k ⩾ 0 , k = 1 ∑ + ∞ p k = 1
几种重要的离散型随机变量 0-1分布 :随机变量X只能取0和1,又称两点分布或伯努利(Bernoulli)分布,记为
X
∼
B
(
1
,
p
)
X∼ B(1,p)
X ∼ B ( 1 , p )
P
{
X
=
k
}
=
p
k
(
1
−
p
)
1
−
k
,
k
=
0
,
1
P\{X=k\}=p^k(1-p)^{1-k},\ k=0,1
P { X = k } = p k ( 1 − p ) 1 − k , k = 0 , 1
S
=
{
s
1
,
s
2
}
,
X
(
s
1
)
=
1
,
X
(
s
2
)
=
0
S=\{s_1,s_2\},\quad X(s_1)=1,X(s_2)=0
S = { s 1 , s 2 } , X ( s 1 ) = 1 , X ( s 2 ) = 0 二项分布 (Binomial):将上述伯努利试验独立地做n次,称为n重伯努利试验。设状态
s
1
,
s
2
s_1, s_2
s 1 , s 2
s
1
s_1
s 1
0
,
1
,
⋯
,
n
0, 1, \cdots , n
0 , 1 , ⋯ , n
X
=
k
X=k
X = k
(
n
k
)
{n \choose k}
( k n )
P
{
X
=
k
}
=
∁
n
k
p
k
(
1
−
p
)
n
−
k
,
k
=
1
,
2
,
⋯
,
n
P\{X=k\}=∁^k_np^k(1-p)^{n-k},k=1,2,\cdots,n
P { X = k } = ∁ n k p k ( 1 − p ) n − k , k = 1 , 2 , ⋯ , n
X
∼
B
(
n
,
p
)
X∼ B(n,p)
X ∼ B ( n , p ) 泊松分布 (Poisson):若的概率分布律为
P
{
X
=
k
}
=
λ
k
e
−
λ
k
!
,
k
=
0
,
1
,
2
,
⋯
P\{X=k\}=\dfrac{λ^ke^{-λ}}{k!},k=0,1,2,\cdots
P { X = k } = k ! λ k e − λ , k = 0 , 1 , 2 , ⋯
λ
>
0
λ>0
λ > 0
λ
λ
λ
X
∼
π
(
λ
)
X∼ π(λ)
X ∼ π ( λ )
X
∼
P
(
λ
)
X∼ P(λ)
X ∼ P ( λ ) 几何分布 (geometric):在重复多次的伯努利试验中, 试验进行到某种结果首次出现 为止, 此时X 的分布律为
P
{
X
=
k
}
=
p
(
1
−
p
)
k
−
1
,
k
=
1
,
2
,
⋯
P\{X=k\}=p(1-p)^{k-1},k=1,2,\cdots
P { X = k } = p ( 1 − p ) k − 1 , k = 1 , 2 , ⋯
X
∼
Geom
(
p
)
X∼ \text{Geom}(p)
X ∼ Geom ( p )
分布函数 (distribution function):对于随机变量X,定义函数
F
(
x
)
=
P
{
X
⩽
x
}
,
∀
x
∈
R
F(x)=P\{X⩽ x\},∀ x\in \R
F ( x ) = P { X ⩽ x } , ∀ x ∈ R 分布函数的基本性质 :
0
⩽
F
(
x
)
⩽
1
0⩽ F(x) ⩽ 1
0 ⩽ F ( x ) ⩽ 1
F
(
x
)
F(x)
F ( x )
F
(
−
∞
)
=
lim
x
→
−
∞
F
(
x
)
=
0
F
(
+
∞
)
=
lim
x
→
+
∞
F
(
x
)
=
1
F(-∞)=\lim\limits_{x\to-∞}F(x)=0\\ F(+∞)=\lim\limits_{x\to+∞}F(x)=1
F ( − ∞ ) = x → − ∞ lim F ( x ) = 0 F ( + ∞ ) = x → + ∞ lim F ( x ) = 1
F
(
x
)
F(x)
F ( x )
F
(
x
)
=
F
(
x
+
0
)
=
lim
y
→
x
+
F
(
y
)
F(x)=F(x+0)=\lim\limits_{y\to x^+}F(y)
F ( x ) = F ( x + 0 ) = y → x + lim F ( y )
连续型随机变量 (continuous random variable):设随机变量 X 的分布函数 F(x) 可表成其中
F
(
x
)
=
∫
−
∞
x
f
(
t
)
d
t
F(x)=\int_{-∞}^{x}f(t)\mathrm{d}t
F ( x ) = ∫ − ∞ x f ( t ) d t
f
(
x
)
⩾
0
f(x)⩾ 0
f ( x ) ⩾ 0
f
(
x
)
f(x)
f ( x ) 概率密度 。概率密度的性质 :
f
(
x
)
⩾
0
f(x)⩾ 0
f ( x ) ⩾ 0
∫
−
∞
+
∞
f
(
t
)
d
t
=
1
\int_{-∞}^{+∞}f(t)\mathrm{d}t=1
∫ − ∞ + ∞ f ( t ) d t = 1
∀
x
1
<
x
2
,
P
{
x
1
<
X
⩽
x
2
}
=
F
(
X
2
)
−
F
(
x
1
)
=
∫
x
1
x
2
f
(
t
)
d
t
∀ x_1<x_2,P\{x_1<X⩽ x_2\}=F(X_2)-F(x_1)=\int_{x_1}^{x_2}f(t)\mathrm{d}t
∀ x 1 < x 2 , P { x 1 < X ⩽ x 2 } = F ( X 2 ) − F ( x 1 ) = ∫ x 1 x 2 f ( t ) d t
F
(
x
)
F(x)
F ( x )
f
(
x
)
=
F
′
(
x
)
f(x)=F'(x)
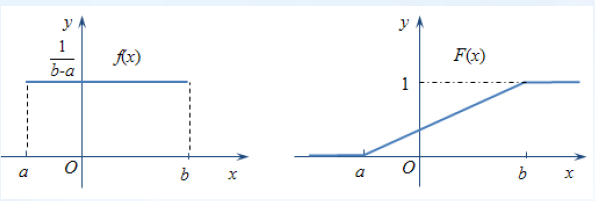
f ( x ) = F ′ ( x ) 几种重要的连续型分布 均匀分布 (uniformly):若X的概率密度函数为
f
(
x
)
=
{
1
b
−
a
,
x
∈
[
a
,
b
]
0
,
x
∈
(
−
∞
,
a
)
∪
(
b
,
+
∞
)
f(x)=\begin{cases}\dfrac{1}{b-a},x\in[a,b] \\ 0,x\in(-∞,a)∪(b,+∞) \end{cases}
f ( x ) = ⎩ ⎨ ⎧ b − a 1 , x ∈ [ a , b ] 0 , x ∈ ( − ∞ , a ) ∪ ( b , + ∞ )
a
<
b
a<b
a < b
[
a
,
b
]
[a,b]
[ a , b ]
X
∼
U
(
a
,
b
)
X∼ U(a,b)
X ∼ U ( a , b )
F
(
x
)
=
{
0
,
x
<
a
x
−
a
b
−
a
,
x
∈
[
a
,
b
]
1
,
x
>
b
F(x)=\begin{cases} 0,\quad x<a \\ \dfrac{x-a}{b-a},x\in[a,b] \\ 1,\quad x>b \end{cases}
F ( x ) = ⎩ ⎪ ⎪ ⎨ ⎪ ⎪ ⎧ 0 , x < a b − a x − a , x ∈ [ a , b ] 1 , x > b 指数分布 (exponential):若X的概率密度函数为
f
(
x
)
=
{
1
θ
e
−
x
/
θ
,
x
>
0
0
,
x
⩽
0
f(x)=\begin{cases} \frac{1}{θ}e^{-x/θ},x>0 \\ 0,\quad x⩽ 0 \end{cases}
f ( x ) = { θ 1 e − x / θ , x > 0 0 , x ⩽ 0
θ
>
0
θ>0
θ > 0
θ
θ
θ
X
∼
E
(
θ
)
X∼ E(θ)
X ∼ E ( θ )
X
∼
E
x
p
(
θ
)
X∼ Exp(θ)
X ∼ E x p ( θ )
F
(
x
)
=
{
1
−
e
−
x
/
θ
,
x
>
0
0
,
x
⩽
0
F(x)=\begin{cases} 1-e^{-x/θ},&x>0 \\ 0,&x⩽ 0 \end{cases}
F ( x ) = { 1 − e − x / θ , 0 , x > 0 x ⩽ 0
t
0
>
0
,
t
>
0
,
P
{
X
>
t
0
+
t
∣
X
>
t
0
}
=
P
{
X
>
t
}
t_0>0,t>0,P\{X>t_0+t|X>t_0\}=P\{X>t\}
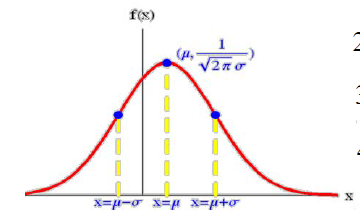
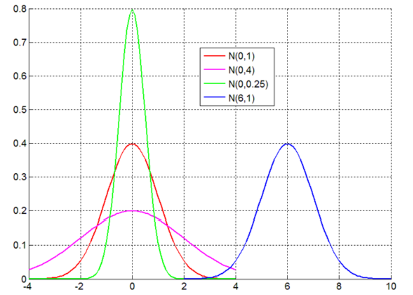
t 0 > 0 , t > 0 , P { X > t 0 + t ∣ X > t 0 } = P { X > t } 正态分布 (normal distribution):连续型随机变量 X 如果有如下形式的概率密度函数
f
(
x
)
=
1
2
π
σ
e
−
(
x
−
μ
)
2
2
σ
2
(
μ
∈
R
,
σ
>
0
)
f(x)=\dfrac{1}{\sqrt{2π}σ}e^{-\frac{(x-μ)^2}{2σ^2}}\quad (μ\in\R,σ>0)
f ( x ) = 2 π
σ 1 e − 2 σ 2 ( x − μ ) 2 ( μ ∈ R , σ > 0 )
(
μ
,
σ
2
)
(μ,σ^2)
( μ , σ 2 )
X
∼
N
(
μ
,
σ
2
)
X∼ N(μ,σ^2)
X ∼ N ( μ , σ 2 )
f
(
x
)
f(x)
f ( x )
x
=
μ
x=μ
x = μ
f
max
=
f
(
μ
)
=
1
2
π
σ
f_{\max}=f(μ)=\dfrac{1}{\sqrt{2π}σ}
f max = f ( μ ) = 2 π
σ 1
x
⩽
μ
x⩽ μ
x ⩽ μ
f
(
x
)
f(x)
f ( x )
x
=
μ
±
σ
x=μ± σ
x = μ ± σ
f
(
x
)
f(x)
f ( x )
lim
∣
x
−
μ
∣
→
+
∞
f
(
x
)
=
0
\lim\limits_{|x-μ|\to+∞}f(x)=0
∣ x − μ ∣ → + ∞ lim f ( x ) = 0
若
X
∼
N
(
μ
,
σ
2
)
,
X
X∼ N(μ,σ^2), X
X ∼ N ( μ , σ 2 ) , X
F
(
x
)
=
P
{
X
⩽
x
}
=
∫
−
∞
x
f
(
t
)
d
t
F(x)=P\{X⩽ x\}=\int_{-∞}^{x}f(t)\mathrm{d}t
F ( x ) = P { X ⩽ x } = ∫ − ∞ x f ( t ) d t
标准正态分布 (standard normal distribution):若
Z
∼
N
(
0
,
1
)
Z∼ N(0,1)
Z ∼ N ( 0 , 1 )
ϕ
(
z
)
=
1
2
π
e
−
z
2
2
ϕ(z)=\dfrac{1}{\sqrt{2π}}e^{-\frac{z^2}{2}}
ϕ ( z ) = 2 π
1 e − 2 z 2
Φ
(
z
)
=
∫
−
∞
z
1
2
π
e
−
t
2
2
d
t
Φ(z)=\int_{-∞}^{z}\dfrac{1}{\sqrt{2π}}e^{-\frac{t^2}{2}}\mathrm{d}t
Φ ( z ) = ∫ − ∞ z 2 π
1 e − 2 t 2 d t
Φ
(
−
z
0
)
=
1
−
Φ
(
z
0
)
Φ(-z_0)=1-Φ(z_0)
Φ ( − z 0 ) = 1 − Φ ( z 0 )
X
∼
N
(
μ
,
σ
2
)
X∼ N(μ,σ^2)
X ∼ N ( μ , σ 2 )
X
−
μ
σ
∼
N
(
0
,
1
)
\frac{X-μ}{σ}∼ N(0,1)
σ X − μ ∼ N ( 0 , 1 )
∀
a
∈
R
,
F
X
(
a
)
=
P
{
X
⩽
a
}
=
P
{
X
−
μ
σ
⩽
a
−
μ
σ
}
=
Φ
(
a
−
μ
σ
)
∀ a\in\R,F_X(a)=P\{X⩽ a\}=P\{\frac{X-μ}{σ} ⩽ \frac{a-μ}{σ}\}=Φ(\frac{a-μ}{σ})
∀ a ∈ R , F X ( a ) = P { X ⩽ a } = P { σ X − μ ⩽ σ a − μ } = Φ ( σ a − μ )
常采用的3σ原则:
P
{
∣
X
−
μ
∣
⩽
3
σ
}
≈
0.9974
P\{|X-μ|⩽ 3σ\}\approx 0.9974
P { ∣ X − μ ∣ ⩽ 3 σ } ≈ 0 . 9 9 7 4
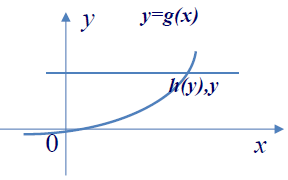
有时我们关心的随机变量不是直接观测得到的随机变量,而是它的函数。
X
∼
N
(
μ
,
σ
2
)
X∼ N(μ,σ^2)
X ∼ N ( μ , σ 2 )
一般地,设 X 为一随机变量, 分布已知.。
Y
=
g
(
X
)
Y=g(X)
Y = g ( X )
g
(
x
1
)
,
g
(
x
2
)
,
⋯
g(x_1), g(x_2), \cdots
g ( x 1 ) , g ( x 2 ) , ⋯
g
(
x
k
)
g(x_k)
g ( x k )
p
k
p_k
p k
g
(
x
k
)
g(x_k)
g ( x k )
p
k
p_k
p k
f
X
(
x
)
f_X (x)
f X ( x )
Y
=
g
(
X
)
Y=g(X)
Y = g ( X )
f
Y
(
y
)
f_Y(y)
f Y ( y )
F
Y
(
y
)
=
P
{
Y
⩽
y
}
=
P
{
g
(
X
)
⩽
y
}
=
∫
D
f
X
(
x
)
d
x
F_Y(y)=P\{Y⩽ y\}=P\{g(X)⩽ y\}=\int_Df_X(x)\mathrm{d}x
F Y ( y ) = P { Y ⩽ y } = P { g ( X ) ⩽ y } = ∫ D f X ( x ) d x
D
=
{
x
∣
g
(
x
)
⩽
y
}
D=\{x|g(x)⩽ y \}
D = { x ∣ g ( x ) ⩽ y }
定理 :设随机变量
X
∼
F
X
(
x
)
,
x
∈
R
,
Y
=
g
(
X
)
,
g
′
(
X
)
>
0
或
g
′
(
X
)
<
0
X∼ F_X(x),x\in\R,\ Y=g(X),g'(X)>0或g'(X)<0
X ∼ F X ( x ) , x ∈ R , Y = g ( X ) , g ′ ( X ) > 0 或 g ′ ( X ) < 0
f
Y
(
y
)
=
{
f
X
[
h
(
y
)
]
⋅
∣
h
′
(
y
)
∣
,
y
∈
[
a
,
b
]
0
,
y
∈
(
−
∞
,
a
)
∪
(
b
,
+
∞
)
f_Y(y)=\begin{cases} f_X[h(y)]\cdot |h'(y)|,\ y\in[a,b] \\ 0,y\in(-∞,a)∪(b,+∞) \end{cases}
f Y ( y ) = { f X [ h ( y ) ] ⋅ ∣ h ′ ( y ) ∣ , y ∈ [ a , b ] 0 , y ∈ ( − ∞ , a ) ∪ ( b , + ∞ )
[
a
,
b
]
[a,b]
[ a , b ]
h
(
y
)
=
x
h(y)=x
h ( y ) = x
一般地,若随机变量
X
∼
N
(
μ
,
σ
2
)
X∼ N(μ,σ^2)
X ∼ N ( μ , σ 2 )
Y
=
a
X
+
b
⟹
Y
∼
N
(
a
μ
+
b
,
a
2
σ
2
)
Y=aX+b\implies Y∼ N(aμ+b,a^2σ^2)
Y = a X + b ⟹ Y ∼ N ( a μ + b , a 2 σ 2 )
二维随机变量 :设E是一个随机试验,样本空间
S
=
e
S={e}
S = e
X
=
X
(
e
)
X=X(e)
X = X ( e )
Y
=
Y
(
e
)
Y=Y(e)
Y = Y ( e )
(
X
,
Y
)
(X,Y)
( X , Y ) 二维随机变量分布函数 :设
(
X
,
Y
)
(X,Y)
( X , Y )
(
x
,
y
)
∈
R
2
(x,y)\in\R^2
( x , y ) ∈ R 2
F
(
x
,
y
)
=
P
{
{
X
⩽
x
}
∩
{
Y
⩽
y
}
}
≜
P
{
X
⩽
x
,
Y
⩽
y
}
F(x,y)=P\{\{X⩽ x\}∩\{Y⩽ y\}\}\triangleq P\{X⩽ x,Y⩽ y\}
F ( x , y ) = P { { X ⩽ x } ∩ { Y ⩽ y } } ≜ P { X ⩽ x , Y ⩽ y } 联合分布函数 ( joint distribution function,JDF)。
F
(
x
,
y
)
F(x, y)
F ( x , y )
∀
x
,
y
,
0
⩽
F
(
x
,
y
)
⩽
1
,
F
(
+
∞
,
+
∞
)
=
1
,
F
(
−
∞
,
y
)
=
F
(
x
,
−
∞
)
=
F
(
−
∞
,
−
∞
)
=
0
∀ x,y,\ 0⩽ F(x, y) ⩽ 1, \\ F(+∞,+∞)=1,F(-∞,y)=F(x,-∞)=F(-∞,-∞)=0
∀ x , y , 0 ⩽ F ( x , y ) ⩽ 1 , F ( + ∞ , + ∞ ) = 1 , F ( − ∞ , y ) = F ( x , − ∞ ) = F ( − ∞ , − ∞ ) = 0
F
(
x
,
y
)
F(x, y)
F ( x , y )
x
,
y
x,y
x , y
lim
ϵ
→
0
+
F
(
x
+
ϵ
,
y
)
=
lim
ϵ
→
0
+
F
(
x
,
y
+
ϵ
)
=
F
(
x
,
y
)
\lim\limits_{ϵ\to 0^+}F(x+ϵ,y)=\lim\limits_{ϵ\to 0^+}F(x,y+ϵ)=F(x,y)
ϵ → 0 + lim F ( x + ϵ , y ) = ϵ → 0 + lim F ( x , y + ϵ ) = F ( x , y )
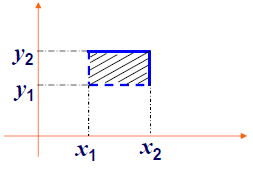
x
1
<
x
2
,
y
1
<
y
2
⟹
P
{
x
1
<
X
⩽
x
2
,
y
1
<
Y
⩽
y
2
}
=
F
(
x
2
,
y
2
)
−
F
(
x
1
,
y
2
)
−
F
(
x
2
,
y
1
)
+
F
(
x
1
,
y
1
)
⩾
0
x_1<x_2,y_1<y_2\\ \implies P\{x_1<X ⩽ x_2,y_1<Y ⩽ y_2\}=F(x_2,y_2)-F(x_1,y_2)-F(x_2,y_1)+F(x_1,y_1) ⩾ 0
x 1 < x 2 , y 1 < y 2 ⟹ P { x 1 < X ⩽ x 2 , y 1 < Y ⩽ y 2 } = F ( x 2 , y 2 ) − F ( x 1 , y 2 ) − F ( x 2 , y 1 ) + F ( x 1 , y 1 ) ⩾ 0
二维离散型随机变量 :若二维随机变量
(
X
,
Y
)
(X,Y)
( X , Y )
(
X
,
Y
)
(X,Y)
( X , Y ) 联合分布律 :设
(
X
,
Y
)
(X,Y)
( X , Y )
(
X
i
,
Y
i
)
(X_i,Y_i)
( X i , Y i )
P
{
X
=
x
i
,
Y
=
y
j
}
=
p
i
j
,
i
,
j
=
1
,
2
,
⋯
P\{X=x_i,Y=y_j\}=p_{ij},i,j=1,2,\cdots
P { X = x i , Y = y j } = p i j , i , j = 1 , 2 , ⋯
(
X
,
Y
)
(X,Y)
( X , Y )
(
1
)
0
⩽
p
i
j
⩽
1
;
(
2
)
∑
i
=
1
∞
∑
j
=
1
∞
p
i
j
=
1
(1)\ 0 ⩽ p_{ij} ⩽ 1;\quad (2)\ \displaystyle\sum_{i=1}^{∞}\sum_{j=1}^{∞}p_{ij}=1
( 1 ) 0 ⩽ p i j ⩽ 1 ; ( 2 ) i = 1 ∑ ∞ j = 1 ∑ ∞ p i j = 1
二维连续型随机变量 :设二维随机变量
(
X
,
Y
)
(X, Y)
( X , Y )
F
(
x
,
y
)
,
∃
f
(
x
,
y
)
⩾
0
,
∀
(
x
,
y
)
∈
R
2
F(x,y), ∃ f(x,y)⩾0,∀ (x,y)\in\R^2
F ( x , y ) , ∃ f ( x , y ) ⩾ 0 , ∀ ( x , y ) ∈ R 2
F
(
x
,
y
)
=
∫
−
∞
x
∫
−
∞
y
f
(
u
,
v
)
d
u
d
v
F(x,y)=\int_{-∞}^{x}\int_{-∞}^{y}f(u,v)\mathrm{d}u\mathrm{d}v
F ( x , y ) = ∫ − ∞ x ∫ − ∞ y f ( u , v ) d u d v
(
X
,
Y
)
(X, Y)
( X , Y ) 二维连续型随机变量 ,
f
(
x
,
y
)
f(x,y)
f ( x , y )
(
X
,
Y
)
(X, Y)
( X , Y ) 联合概率密度(函数) 。
f
(
x
,
y
)
⩾
0
f(x,y)⩾0
f ( x , y ) ⩾ 0
∫
−
∞
+
∞
∫
−
∞
+
∞
f
(
x
,
y
)
d
x
d
y
=
1
\int_{-∞}^{+∞}\int_{-∞}^{+∞}f(x,y)\mathrm{d}x\mathrm{d}y=1
∫ − ∞ + ∞ ∫ − ∞ + ∞ f ( x , y ) d x d y = 1
f
(
x
,
y
)
f ( x , y )
f ( x , y )
∂
F
(
x
,
y
)
∂
x
∂
y
=
f
(
x
,
y
)
\dfrac{∂ F(x,y)}{∂ x∂ y}=f(x,y)
∂ x ∂ y ∂ F ( x , y ) = f ( x , y )
R
2
\R^2
R 2
P
{
(
X
,
Y
)
∈
G
}
=
∬
G
f
(
u
,
v
)
d
u
d
v
P\{(X,Y)\in G\}=\iint_G f(u,v)\mathrm{d}u\mathrm{d}v
P { ( X , Y ) ∈ G } = ∬ G f ( u , v ) d u d v
边缘分布律 :对分布律为
P
{
X
=
x
i
,
Y
=
y
j
}
=
p
i
j
P\{X=x_i,Y=y_j\}=p_{ij}
P { X = x i , Y = y j } = p i j
P
{
X
=
x
i
}
=
P
{
X
=
x
i
,
⋃
j
=
1
∞
{
Y
=
y
j
}
}
=
∑
j
=
1
∞
p
i
j
≜
p
i
∙
\displaystyle P\{X=x_i\}=P\{X=x_i,\bigcup^{∞}_{j=1}\{Y=y_j\}\}=\sum_{j=1}^{∞}p_{ij}\triangleq p_{i\bullet}
P { X = x i } = P { X = x i , j = 1 ⋃ ∞ { Y = y j } } = j = 1 ∑ ∞ p i j ≜ p i ∙
P
{
Y
=
y
j
}
=
P
{
⋃
i
=
1
∞
{
X
=
x
i
}
,
Y
=
y
j
}
=
∑
i
=
1
∞
p
i
j
≜
p
∙
j
\displaystyle P\{Y=y_j\}=P\{\bigcup^{∞}_{i=1}\{X=x_i\},Y=y_j\}=\sum_{i=1}^{∞}p_{ij}\triangleq p_{\bullet j}
P { Y = y j } = P { i = 1 ⋃ ∞ { X = x i } , Y = y j } = i = 1 ∑ ∞ p i j ≜ p ∙ j
X
/
Y
y
1
y
2
⋯
y
j
⋯
P
{
X
=
x
i
}
x
1
p
11
p
12
⋯
p
1
j
⋯
p
1
∙
x
2
p
21
p
22
⋯
p
2
j
⋯
p
2
∙
⋮
⋯
⋯
⋯
⋮
x
i
p
i
1
p
i
2
⋯
p
i
j
⋯
p
i
∙
⋮
⋯
⋯
⋯
⋮
P
{
Y
=
y
j
}
p
∙
1
p
∙
2
⋯
p
∙
j
⋯
1
\begin{array}{c|ccccc|c} X/Y &y_1&y_2&\cdots&y_j&\cdots &P\{X=x_i\} \\ \hline x_1 &p_{11}&p_{12}&\cdots&p_{1j}&\cdots &p_{1 \bullet} \\ x_2 &p_{21}&p_{22}&\cdots&p_{2j}&\cdots &p_{2 \bullet} \\ \vdots &\cdots&&\cdots&&\cdots &\vdots \\ x_i&p_{i1}&p_{i2}&\cdots&p_{ij}&\cdots &p_{i \bullet} \\ \vdots &\cdots&&\cdots&&\cdots &\vdots \\ \hline P\{Y=y_j\} &p_{\bullet 1}&p_{\bullet 2}&\cdots&p_{\bullet j}&\cdots &1 \end{array}
X / Y x 1 x 2 ⋮ x i ⋮ P { Y = y j } y 1 p 1 1 p 2 1 ⋯ p i 1 ⋯ p ∙ 1 y 2 p 1 2 p 2 2 p i 2 p ∙ 2 ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ y j p 1 j p 2 j p i j p ∙ j ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ P { X = x i } p 1 ∙ p 2 ∙ ⋮ p i ∙ ⋮ 1
边缘概率密度 :对概率密度为
f
(
x
,
y
)
f(x,y)
f ( x , y )
f
X
(
x
)
=
∫
−
∞
+
∞
f
(
x
,
y
)
d
y
f
Y
(
y
)
=
∫
−
∞
+
∞
f
(
x
,
y
)
d
x
f_X(x)=\int_{-∞}^{+∞}f(x,y)\mathrm{d}y\\ f_Y(y)=\int_{-∞}^{+∞}f(x,y)\mathrm{d}x
f X ( x ) = ∫ − ∞ + ∞ f ( x , y ) d y f Y ( y ) = ∫ − ∞ + ∞ f ( x , y ) d x
边缘分布函数 :可以由
(
X
,
Y
)
(X,Y)
( X , Y )
F
X
(
x
)
≜
P
{
X
⩽
x
,
Y
<
+
∞
}
=
F
(
x
,
+
∞
)
=
lim
y
→
+
∞
F
(
x
,
y
)
F_X(x)\triangleq P\{X ⩽ x,Y<+∞\}=F(x,+∞)=\lim\limits_{y\to +∞}F(x,y)
F X ( x ) ≜ P { X ⩽ x , Y < + ∞ } = F ( x , + ∞ ) = y → + ∞ lim F ( x , y )
F
Y
(
y
)
≜
P
{
X
<
+
∞
,
Y
⩽
y
}
=
F
(
+
∞
,
y
)
=
lim
x
→
+
∞
F
(
x
,
y
)
F_Y(y)\triangleq P\{X<+∞,Y ⩽ y\}=F(+∞,y)=\lim\limits_{x\to +∞}F(x,y)
F Y ( y ) ≜ P { X < + ∞ , Y ⩽ y } = F ( + ∞ , y ) = x → + ∞ lim F ( x , y )
相互独立 (mutual independence):
∀
x
,
y
,
F
(
x
,
y
)
=
F
X
(
x
)
F
Y
(
y
)
∀ x,y,F(x,y)=F_X(x)F_Y(y)
∀ x , y , F ( x , y ) = F X ( x ) F Y ( y )
⟺
p
i
j
=
p
i
∙
p
∙
j
\iff p_{ij}=p_{i \bullet}p_{\bullet j}
⟺ p i j = p i ∙ p ∙ j
⟺
f
(
x
,
y
)
=
f
X
(
x
)
f
Y
(
y
)
\iff f(x,y)=f_X(x)f_Y(y)
⟺ f ( x , y ) = f X ( x ) f Y ( y )
条件分布 (conditional distribution):对二维离散型随机变量
(
X
,
Y
)
(X,Y)
( X , Y )
P
{
X
=
x
i
∣
Y
=
y
j
}
=
P
{
X
=
x
i
,
Y
=
y
j
}
P
{
Y
=
y
j
}
=
p
i
j
p
∙
j
P\{X=x_i|Y=y_j\}=\dfrac{P\{X=x_i,Y=y_j\}}{P\{Y=y_j\}}=\dfrac{p_{ij}}{p_{\bullet j}}
P { X = x i ∣ Y = y j } = P { Y = y j } P { X = x i , Y = y j } = p ∙ j p i j
P
{
Y
=
y
j
∣
X
=
x
i
}
=
P
{
X
=
x
i
,
Y
=
y
j
}
P
{
X
=
x
i
}
=
p
i
j
p
i
∙
P\{Y=y_j|X=x_i\}=\dfrac{P\{X=x_i,Y=y_j\}}{P\{X=x_i\}}=\dfrac{p_{ij}}{p_{i \bullet}}
P { Y = y j ∣ X = x i } = P { X = x i } P { X = x i , Y = y j } = p i ∙ p i j
条件概率密度 :对二维连续型随机变量
(
X
,
Y
)
(X,Y)
( X , Y )
Y
=
y
Y=y
Y = y
f
X
∣
Y
(
x
∣
y
)
=
f
(
x
,
y
)
f
Y
(
y
)
f_{X|Y}(x|y)=\dfrac{f(x,y)}{f_Y(y)}
f X ∣ Y ( x ∣ y ) = f Y ( y ) f ( x , y )
f
Y
∣
X
(
y
∣
x
)
=
f
(
x
,
y
)
f
X
(
x
)
f_{Y|X}(y|x)=\dfrac{f(x,y)}{f_X(x)}
f Y ∣ X ( y ∣ x ) = f X ( x ) f ( x , y )
条件分布函数 :
F
X
∣
Y
(
x
∣
y
)
=
P
{
X
⩽
x
∣
Y
=
y
}
=
{
P
{
X
⩽
x
,
Y
=
y
}
P
{
Y
=
y
}
,
P
{
Y
=
y
}
>
0
,
即
Y
为
离
散
型
随
机
变
量
lim
ϵ
→
0
+
P
{
X
⩽
x
,
y
<
Y
⩽
y
+
ϵ
}
P
{
y
<
Y
⩽
y
+
ϵ
}
,
P
{
Y
=
y
}
=
0
,
即
Y
为
连
续
型
随
机
变
量
F_{X|Y}(x|y)=P\{X⩽ x|Y=y\}= \\ \begin{cases} \dfrac{P\{X⩽ x,Y=y\}}{P\{Y=y\}}, & P\{Y=y\}>0,即Y为离散型随机变量 \\ \\ \lim\limits_{ϵ\to 0^+}\dfrac{P\{X⩽ x,y<Y⩽ y+ϵ\}}{P\{y<Y⩽ y+ϵ\}},&P\{Y=y\}=0,即Y为连续型随机变量 \end{cases}
F X ∣ Y ( x ∣ y ) = P { X ⩽ x ∣ Y = y } = ⎩ ⎪ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎪ ⎧ P { Y = y } P { X ⩽ x , Y = y } , ϵ → 0 + lim P { y < Y ⩽ y + ϵ } P { X ⩽ x , y < Y ⩽ y + ϵ } , P { Y = y } > 0 , 即 Y 为 离 散 型 随 机 变 量 P { Y = y } = 0 , 即 Y 为 连 续 型 随 机 变 量
二维均匀分布 :概率密度函数
f
(
x
,
y
)
=
{
1
/
A
,
(
x
,
y
)
∈
D
0
,
(
x
,
y
)
∉
D
,
其
中
A
为
D
的
面
积
f(x,y)=\begin{cases} 1/A,&(x,y)\in D \\ 0,&(x,y) \not\in D \end{cases},其中A为D的面积
f ( x , y ) = { 1 / A , 0 , ( x , y ) ∈ D ( x , y ) ∈ D , 其 中 A 为 D 的 面 积
二维正态分布 :
Z
1
,
Z
2
Z_1, Z_2
Z 1 , Z 2
N
(
0
,
1
)
N(0,1)
N ( 0 , 1 )
Z
1
,
Z
2
Z_1, Z_2
Z 1 , Z 2
f
(
z
1
,
z
2
)
=
1
2
π
e
−
1
2
(
z
1
2
+
z
2
2
)
f(z_1,z_2)=\frac{1}{2π}e^{-\frac{1}{2}(z_1^2+z_2^2)}
f ( z 1 , z 2 ) = 2 π 1 e − 2 1 ( z 1 2 + z 2 2 )
{
X
=
σ
1
Z
1
+
μ
1
Y
=
σ
2
(
ρ
Z
1
+
1
−
ρ
2
Z
2
)
+
μ
2
(
σ
1
,
σ
2
>
0
,
∣
ρ
∣
<
1
)
\begin{cases} X=σ_1Z_1+μ _1 \\ Y=σ_2(ρZ_1+\sqrt{1-ρ^2}Z_2)+μ _2 \end{cases}\quad (σ_1,σ_2>0,|ρ|<1)
{ X = σ 1 Z 1 + μ 1 Y = σ 2 ( ρ Z 1 + 1 − ρ 2
Z 2 ) + μ 2 ( σ 1 , σ 2 > 0 , ∣ ρ ∣ < 1 )
(
X
,
Y
)
(X ,Y)
( X , Y )
(
μ
1
,
μ
2
,
σ
1
2
,
σ
2
2
,
ρ
)
(μ _1,μ _2,σ_1^2,σ_2^2,ρ)
( μ 1 , μ 2 , σ 1 2 , σ 2 2 , ρ )
(
X
,
Y
)
∼
N
(
μ
1
,
μ
2
,
σ
1
2
,
σ
2
2
,
ρ
)
(X ,Y)∼ N(μ _1,μ _2,σ_1^2,σ_2^2,ρ)
( X , Y ) ∼ N ( μ 1 , μ 2 , σ 1 2 , σ 2 2 , ρ )
(
X
Y
)
=
A
(
Z
1
Z
2
)
+
(
μ
1
μ
2
)
\begin{pmatrix} X\\ Y\end{pmatrix} =A \begin{pmatrix} Z_1\\ Z_2\end{pmatrix}+ \begin{pmatrix} μ _1\\ μ _2\end{pmatrix}
( X Y ) = A ( Z 1 Z 2 ) + ( μ 1 μ 2 )
A
=
(
σ
1
0
σ
2
ρ
σ
2
1
−
ρ
2
)
A=\begin{pmatrix} σ_1&0\\ σ_2ρ&σ_2\sqrt{1-ρ^2}\end{pmatrix}
A = ( σ 1 σ 2 ρ 0 σ 2 1 − ρ 2
)
(
Z
1
Z
2
)
=
A
−
1
(
X
−
μ
1
Y
−
μ
2
)
\begin{pmatrix} Z_1\\ Z_2\end{pmatrix} =A^{-1} \begin{pmatrix} X-μ _1\\ Y-μ _2\end{pmatrix}
( Z 1 Z 2 ) = A − 1 ( X − μ 1 Y − μ 2 )
Z
1
,
Z
2
Z_1, Z_2
Z 1 , Z 2
∣
J
∣
=
det
A
−
1
=
1
σ
1
σ
2
1
−
ρ
2
|J|=\det A^{-1}=\dfrac{1}{σ_1σ_2\sqrt{1-ρ^2}}
∣ J ∣ = det A − 1 = σ 1 σ 2 1 − ρ 2
1
(
X
,
Y
)
(X ,Y)
( X , Y )
f
(
x
,
y
)
f(x,y)
f ( x , y )
由定义知若
ρ
=
0
ρ=0
ρ = 0
X
=
σ
1
Z
1
+
μ
1
,
Y
=
σ
2
Z
2
+
μ
2
X=σ_1Z_1+μ _1,Y=σ_2Z_2+μ _2
X = σ 1 Z 1 + μ 1 , Y = σ 2 Z 2 + μ 2 边缘概率密度 :因
X
=
σ
1
Z
1
+
μ
1
X=σ_1Z_1+μ _1
X = σ 1 Z 1 + μ 1
X
∼
N
(
μ
1
,
σ
1
2
)
X∼ N(μ _1,σ_1^2)
X ∼ N ( μ 1 , σ 1 2 )
Y
∼
N
(
μ
2
,
σ
2
2
)
Y∼ N(μ _2,σ_2^2)
Y ∼ N ( μ 2 , σ 2 2 ) 条件概率密度 :由于
Z
1
=
x
−
μ
1
σ
1
Z_1=\frac{x-μ _1}{σ_1}
Z 1 = σ 1 x − μ 1
Y
∣
X
=
x
∼
N
(
σ
2
ρ
σ
1
(
x
−
μ
1
)
,
σ
2
2
(
1
−
ρ
2
)
)
Y|_{X=x}∼ N(\frac{σ_2ρ}{σ_1}(x-μ _1),σ_2^2(1-ρ^2))
Y ∣ X = x ∼ N ( σ 1 σ 2 ρ ( x − μ 1 ) , σ 2 2 ( 1 − ρ 2 ) )
X
∣
Y
=
y
∼
N
(
σ
1
ρ
σ
2
(
y
−
μ
2
)
,
σ
1
2
(
1
−
ρ
2
)
)
X|_{Y=y}∼ N(\frac{σ_1ρ}{σ_2}(y-μ _2),σ_1^2(1-ρ^2))
X ∣ Y = y ∼ N ( σ 2 σ 1 ρ ( y − μ 2 ) , σ 1 2 ( 1 − ρ 2 ) )
二维离散 :设二维离散型随机变量
(
X
,
Y
)
(X ,Y)
( X , Y )
P
{
X
=
x
i
,
Y
=
y
j
}
=
p
i
j
P\{X=x_i,Y=y_j\}=p_{ij}
P { X = x i , Y = y j } = p i j
U
=
u
(
X
,
Y
)
U=u(X,Y)
U = u ( X , Y )
U
U
U
U
U
U
u
i
u_i
u i
P
{
U
=
u
i
}
=
P
{
(
X
,
Y
)
∈
D
}
P\{U=u_i\}=P\{(X,Y)\in D\}
P { U = u i } = P { ( X , Y ) ∈ D }
U
=
u
(
X
,
Y
)
,
V
=
v
(
X
,
Y
)
U=u(X,Y),V=v(X,Y)
U = u ( X , Y ) , V = v ( X , Y )
(
U
,
V
)
(U,V)
( U , V )
(
U
,
V
)
(U,V)
( U , V )
(
u
i
,
v
i
)
(u_i,v_i)
( u i , v i )
P
{
U
=
u
i
,
V
=
v
i
}
=
P
{
(
X
,
Y
)
∈
D
}
P\{U=u_i,V=v_i\}=P\{(X,Y)\in D\}
P { U = u i , V = v i } = P { ( X , Y ) ∈ D }
二维连续 :设二维连续型随机变量
(
X
,
Y
)
(X ,Y)
( X , Y )
f
(
x
,
y
)
f(x,y)
f ( x , y )
Z
=
g
(
X
,
Y
)
Z=g(X,Y)
Z = g ( X , Y )
Z
Z
Z
F
Z
(
z
)
=
P
{
Z
⩽
z
}
=
P
{
g
(
X
,
Y
)
⩽
z
}
=
∬
g
(
x
,
y
)
⩽
z
f
(
x
,
y
)
d
x
d
y
\displaystyle F_Z(z)=P\{Z⩽ z\}=P\{g(X,Y)⩽ z\}=\iint_{g(x,y)⩽ z}f(x,y)\mathrm{d}x\mathrm{d}y
F Z ( z ) = P { Z ⩽ z } = P { g ( X , Y ) ⩽ z } = ∬ g ( x , y ) ⩽ z f ( x , y ) d x d y
f
Z
(
z
)
=
F
Z
′
(
z
)
f_Z(z)=F'_Z(z)
f Z ( z ) = F Z ′ ( z )
(
U
,
V
)
(U,V)
( U , V )
(
X
,
Y
)
(X,Y)
( X , Y )
(
U
,
V
)
(U,V)
( U , V )
(
U
,
V
)
(U,V)
( U , V )
(
X
,
Y
)
(X,Y)
( X , Y )
X
=
x
(
U
,
V
)
,
Y
=
y
(
U
,
V
)
X=x(U,V),Y=y(U,V)
X = x ( U , V ) , Y = y ( U , V )
(
U
,
V
)
(U,V)
( U , V )
G
(
u
,
v
)
=
P
{
U
⩽
u
,
V
⩽
v
}
=
∬
U
⩽
u
,
V
⩽
v
f
(
x
,
y
)
d
x
d
y
\displaystyle G(u,v)=P\{U⩽ u,V⩽ v\}=\iint_{U⩽ u,V⩽ v}f(x,y)\mathrm{d}x\mathrm{d}y
G ( u , v ) = P { U ⩽ u , V ⩽ v } = ∬ U ⩽ u , V ⩽ v f ( x , y ) d x d y
G
(
u
,
v
)
=
∫
−
∞
u
∫
−
∞
v
f
[
x
(
s
,
t
)
,
y
(
s
,
t
)
]
∣
J
(
s
,
t
)
∣
d
s
d
t
\displaystyle G(u,v)=\int_{-∞}^{u}\int_{-∞}^{v}f[x(s,t),y(s,t)]|J(s,t)|\mathrm{d}s\mathrm{d}t
G ( u , v ) = ∫ − ∞ u ∫ − ∞ v f [ x ( s , t ) , y ( s , t ) ] ∣ J ( s , t ) ∣ d s d t
g
(
u
,
v
)
=
∂
2
G
(
u
,
v
)
∂
u
∂
v
=
f
[
x
(
s
,
t
)
,
y
(
s
,
t
)
]
∣
J
(
s
,
t
)
∣
g(u,v)=\dfrac{∂^2G(u,v)}{∂ u ∂ v}=f[x(s,t),y(s,t)]|J(s,t)|
g ( u , v ) = ∂ u ∂ v ∂ 2 G ( u , v ) = f [ x ( s , t ) , y ( s , t ) ] ∣ J ( s , t ) ∣
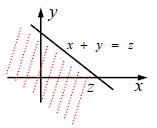
连续型随机变量
Z
=
X
+
Y
Z=X+Y
Z = X + Y
F
Z
(
z
)
=
∫
−
∞
z
f
Z
(
u
)
d
u
F_Z(z)=\int_{-∞}^{z}f_Z(u)\mathrm{d}u
F Z ( z ) = ∫ − ∞ z f Z ( u ) d u
f
Z
(
z
)
=
∫
−
∞
+
∞
f
(
z
−
y
,
y
)
d
y
=
∫
−
∞
+
∞
f
(
x
,
z
−
x
)
d
x
f_Z(z)=\int_{-∞}^{+∞}f(z-y,y)\mathrm{d}y=\int_{-∞}^{+∞}f(x,z-x)\mathrm{d}x
f Z ( z ) = ∫ − ∞ + ∞ f ( z − y , y ) d y = ∫ − ∞ + ∞ f ( x , z − x ) d x
f
Z
(
z
)
=
∫
−
∞
+
∞
f
X
(
z
−
y
)
f
Y
(
y
)
d
y
=
∫
−
∞
+
∞
f
Y
(
z
−
x
)
f
X
(
x
)
d
x
f_Z(z)=\int_{-∞}^{+∞}f_X(z-y)f_Y(y)\mathrm{d}y=\int_{-∞}^{+∞}f_Y(z-x)f_X(x)\mathrm{d}x
f Z ( z ) = ∫ − ∞ + ∞ f X ( z − y ) f Y ( y ) d y = ∫ − ∞ + ∞ f Y ( z − x ) f X ( x ) d x
f
Z
f_Z
f Z
f
X
f_X
f X
f
Y
f_Y
f Y 卷积 ,记为
f
Z
=
f
X
∗
f
Y
f_Z=f_X * f_Y
f Z = f X ∗ f Y
X
∼
N
(
μ
1
,
σ
1
2
)
,
Y
∼
N
(
μ
2
,
σ
2
2
)
⟹
Z
=
X
+
Y
∼
N
(
μ
1
+
μ
2
,
σ
1
2
+
σ
2
2
)
X∼ N(μ _1,σ_1^2),Y∼ N(μ _2,σ_2^2)\implies Z=X+Y∼ N(μ _1+μ _2,σ_1^2+σ_2^2)
X ∼ N ( μ 1 , σ 1 2 ) , Y ∼ N ( μ 2 , σ 2 2 ) ⟹ Z = X + Y ∼ N ( μ 1 + μ 2 , σ 1 2 + σ 2 2 )
独立的离散型变量的和分布
X
1
,
X
2
,
⋯
,
X
n
X_1,X_2,\cdots,X_n
X 1 , X 2 , ⋯ , X n
B
(
1
,
p
)
B(1,p)
B ( 1 , p )
X
1
+
X
2
+
⋯
+
X
n
∼
B
(
n
,
p
)
X_1+X_2+\cdots+X_n∼ B(n,p)
X 1 + X 2 + ⋯ + X n ∼ B ( n , p )
X
1
∼
B
(
n
1
,
p
)
,
X
2
∼
B
(
n
2
,
p
)
X_1∼ B(n_1,p),X_2∼ B(n_2,p)
X 1 ∼ B ( n 1 , p ) , X 2 ∼ B ( n 2 , p )
X
1
+
X
2
∼
B
(
n
1
+
n
2
,
p
)
X_1+X_2∼ B(n_1+n_2,p)
X 1 + X 2 ∼ B ( n 1 + n 2 , p )
X
1
∼
π
(
θ
1
)
,
X
2
∼
π
(
θ
2
)
X_1∼ π(θ_1),X_2∼ π(θ_2)
X 1 ∼ π ( θ 1 ) , X 2 ∼ π ( θ 2 )
X
1
+
X
2
∼
π
(
1
/
θ
1
+
1
/
θ
2
)
X_1+X_2∼ π(1/θ_1+1/θ_2)
X 1 + X 2 ∼ π ( 1 / θ 1 + 1 / θ 2 )
连续型随机变量
Z
=
X
/
Y
Z=X/Y
Z = X / Y
f
Z
(
z
)
=
{
(
1
+
z
)
−
2
,
z
>
0
0
,
z
⩽
0
f_Z(z)=\begin{cases} (1+z)^{-2},&z>0 \\ 0,&z⩽ 0 \end{cases}
f Z ( z ) = { ( 1 + z ) − 2 , 0 , z > 0 z ⩽ 0
极值分布 (extreme-value distribution):设 X, Y 独立,分别有分布函数
F
X
(
x
)
,
F
Y
(
y
)
F_X(x),F_Y(y)
F X ( x ) , F Y ( y )
max
{
X
,
Y
}
\max\{X, Y\}
max { X , Y }
F
m
a
x
(
z
)
=
F
X
(
x
)
F
Y
(
y
)
F_{max}(z)=F_X(x)F_Y(y)
F m a x ( z ) = F X ( x ) F Y ( y )
min
{
X
,
Y
}
\min\{X, Y\}
min { X , Y }
F
m
i
n
(
z
)
=
1
−
(
1
−
F
X
(
x
)
)
(
1
−
F
Y
(
y
)
)
F_{min}(z)=1-(1-F_X(x))(1-F_Y(y))
F m i n ( z ) = 1 − ( 1 − F X ( x ) ) ( 1 − F Y ( y ) )
上述结论容易推广到 n 个随机变量:即设
X
i
X_i
X i
F
i
(
x
i
)
,
i
=
1
,
⋯
,
n
F_i(x_i), i=1,\cdots,n
F i ( x i ) , i = 1 , ⋯ , n
max
{
X
1
,
⋯
,
X
n
}
,
min
{
X
1
,
⋯
,
X
n
}
\max\{X_1,\cdots,X_n\}, \min\{X_1,\cdots,X_n\}
max { X 1 , ⋯ , X n } , min { X 1 , ⋯ , X n }
F
max
(
z
)
=
∏
i
=
1
n
F
i
(
z
)
;
F
min
(
z
)
=
1
−
∏
i
=
1
n
(
1
−
F
i
(
z
)
)
\displaystyle F_{\max}(z)=\prod_{i=1}^{n}F_i(z); \quad F_{\min}(z)=1-\prod_{i=1}^{n}(1-F_i(z))
F max ( z ) = i = 1 ∏ n F i ( z ) ; F min ( z ) = 1 − i = 1 ∏ n ( 1 − F i ( z ) )
数学期望 (mathematical expectation):设离散型随机变量 X的分布律为
P
{
X
=
x
k
}
=
p
k
P\{X=x_k\}=p_k
P { X = x k } = p k
x
ˉ
=
1
n
∑
k
x
k
n
k
=
∑
k
x
k
f
k
\displaystyle\bar x=\frac{1}{n}\sum_kx_kn_k=\sum_kx_kf_k
x ˉ = n 1 k ∑ x k n k = k ∑ x k f k
f
k
f_k
f k
{
X
=
x
k
}
\{X=x_k\}
{ X = x k }
n
→
∞
,
f
k
→
p
k
n\to ∞,f_k\to p_k
n → ∞ , f k → p k
x
ˉ
\bar x
x ˉ
∑
k
x
k
p
k
\displaystyle\sum_kx_kp_k
k ∑ x k p k
E
(
X
)
=
∑
k
=
1
∞
x
k
p
k
E(X)=\displaystyle\sum_{k=1}^{∞}x_kp_k
E ( X ) = k = 1 ∑ ∞ x k p k
E
(
X
)
E(X)
E ( X )
X
X
X
X
X
X
f
(
x
)
f(x)
f ( x )
E
(
X
)
=
∫
−
∞
+
∞
x
f
(
x
)
d
x
E(X)=\int_{-∞}^{+∞}xf(x)\mathrm{d}x
E ( X ) = ∫ − ∞ + ∞ x f ( x ) d x Y=g(X) 的数学期望
E
(
Y
)
=
E
(
g
(
X
)
)
=
∑
k
=
1
∞
g
(
x
k
)
p
k
E(Y)=E(g(X))=\displaystyle\sum_{k=1}^{∞}g(x_k)p_k
E ( Y ) = E ( g ( X ) ) = k = 1 ∑ ∞ g ( x k ) p k
E
(
Y
)
=
E
(
g
(
X
)
)
=
∫
−
∞
+
∞
g
(
x
)
f
(
x
)
d
x
E(Y)=E(g(X))=\displaystyle\int_{-∞}^{+∞}g(x)f(x)\mathrm{d}x
E ( Y ) = E ( g ( X ) ) = ∫ − ∞ + ∞ g ( x ) f ( x ) d x Z=h(X,Y) 的数学期望
E
(
Z
)
=
E
(
h
(
X
,
Y
)
)
=
∑
i
=
1
∞
∑
j
=
1
∞
h
(
x
i
,
y
j
)
p
i
j
E(Z)=E(h(X,Y))=\displaystyle\sum_{i=1}^{∞}\sum_{j=1}^{∞}h(x_i,y_j)p_{ij}
E ( Z ) = E ( h ( X , Y ) ) = i = 1 ∑ ∞ j = 1 ∑ ∞ h ( x i , y j ) p i j
E
(
Z
)
=
E
(
h
(
X
,
Y
)
)
=
∫
−
∞
+
∞
∫
−
∞
+
∞
h
(
x
,
y
)
f
(
x
,
y
)
d
x
d
y
E(Z)=E(h(X,Y))=\displaystyle\int_{-∞}^{+∞}\int_{-∞}^{+∞}h(x,y)f(x,y)\mathrm{d}x\mathrm{d}y
E ( Z ) = E ( h ( X , Y ) ) = ∫ − ∞ + ∞ ∫ − ∞ + ∞ h ( x , y ) f ( x , y ) d x d y
E
(
X
)
=
∫
−
∞
+
∞
∫
−
∞
+
∞
x
f
(
x
,
y
)
d
x
d
y
E(X)=\displaystyle\int_{-∞}^{+∞}\int_{-∞}^{+∞}xf(x,y)\mathrm{d}x\mathrm{d}y
E ( X ) = ∫ − ∞ + ∞ ∫ − ∞ + ∞ x f ( x , y ) d x d y
E
(
Y
)
=
∫
−
∞
+
∞
∫
−
∞
+
∞
y
f
(
x
,
y
)
d
x
d
y
E(Y)=\displaystyle\int_{-∞}^{+∞}\int_{-∞}^{+∞}yf(x,y)\mathrm{d}x\mathrm{d}y
E ( Y ) = ∫ − ∞ + ∞ ∫ − ∞ + ∞ y f ( x , y ) d x d y 期望的性质 (c为常数)
E
(
c
)
=
c
E(c)=c
E ( c ) = c
E
(
c
X
)
=
c
E
(
X
)
E(cX)=cE(X)
E ( c X ) = c E ( X )
E
(
X
+
Y
)
=
E
(
X
)
+
E
(
Y
)
E(X+Y)=E(X)+E(Y)
E ( X + Y ) = E ( X ) + E ( Y )
X
,
Y
X,Y
X , Y
E
(
X
Y
)
=
E
(
X
)
E
(
Y
)
E(XY)=E(X)E(Y)
E ( X Y ) = E ( X ) E ( Y )
方差 (variance):设X是一个随机变量
D
(
X
)
=
V
a
r
(
X
)
=
E
[
(
X
−
E
(
X
)
)
2
]
D(X)=Var(X)=E[(X-E(X))^2]
D ( X ) = V a r ( X ) = E [ ( X − E ( X ) ) 2 ]
σ
(
X
)
=
D
(
X
)
σ(X)=\sqrt{D(X)}
σ ( X ) = D ( X )
方差的计算
g
(
X
)
=
(
X
−
E
(
X
)
)
2
,
D
(
X
)
=
E
(
g
(
X
)
)
g(X)=(X-E(X))^2,\ D(X)=E(g(X))
g ( X ) = ( X − E ( X ) ) 2 , D ( X ) = E ( g ( X ) )
D
(
X
)
=
E
(
X
2
)
−
[
E
(
X
)
]
2
D(X)=E(X^2)-[E(X)]^2
D ( X ) = E ( X 2 ) − [ E ( X ) ] 2 方差的性质 (c为常数)
D
(
c
)
=
0
D(c)=0
D ( c ) = 0
D
(
c
X
)
=
c
2
D
(
X
)
D(cX)=c^2D(X)
D ( c X ) = c 2 D ( X )
D
(
X
+
Y
)
=
D
(
X
)
+
D
(
Y
)
+
2
E
[
(
X
−
E
(
X
)
)
(
Y
−
E
(
Y
)
)
]
D(X+Y)=D(X)+D(Y)+2E[(X-E(X))(Y-E(Y))]
D ( X + Y ) = D ( X ) + D ( Y ) + 2 E [ ( X − E ( X ) ) ( Y − E ( Y ) ) ]
X
,
Y
X,Y
X , Y
D
(
X
+
Y
)
=
D
(
X
)
+
D
(
Y
)
D(X+Y)=D(X)+D(Y)
D ( X + Y ) = D ( X ) + D ( Y )
E
(
X
)
=
μ
,
D
(
X
)
=
σ
2
,
P
{
∣
X
−
μ
∣
⩾
ϵ
}
⩽
σ
2
ϵ
2
E(X)=μ,D(X)=σ^2,P\{|X-μ|⩾ ϵ\}⩽ \dfrac{σ^2}{ϵ^2}
E ( X ) = μ , D ( X ) = σ 2 , P { ∣ X − μ ∣ ⩾ ϵ } ⩽ ϵ 2 σ 2
P
{
∣
X
−
μ
∣
<
ϵ
}
>
1
−
σ
2
ϵ
2
P\{|X-μ|< ϵ\}>1-\dfrac{σ^2}{ϵ^2}
P { ∣ X − μ ∣ < ϵ } > 1 − ϵ 2 σ 2
ϵ
=
3
σ
ϵ=3σ
ϵ = 3 σ
P
{
∣
X
−
μ
∣
<
3
σ
}
>
1
−
1
9
≈
88.0
%
P\{|X-μ|< 3σ\}>1-\frac{1}{9}\approx 88.0\%
P { ∣ X − μ ∣ < 3 σ } > 1 − 9 1 ≈ 8 8 . 0 %
(
μ
−
3
σ
,
μ
+
3
σ
)
(μ-3σ,μ+3σ)
( μ − 3 σ , μ + 3 σ )
变异系数 (Coefficient of Variance,CV): 标准差与期望的比值
C
V
=
D
(
X
)
E
(
X
)
=
σ
(
X
)
E
(
X
)
CV=\dfrac{\sqrt{D(X)}}{E(X)}=\dfrac{σ(X)}{E(X)}
C V = E ( X ) D ( X )
= E ( X ) σ ( X )
分位数(Quantile),亦称分位点,是指将一个随机变量的概率分布范围分为几个等份的数值点
P
{
x
⩽
x
α
}
=
α
P\{x⩽ x_α\}=α
P { x ⩽ x α } = α
x
α
x_α
x α
α
α
α
协方差 (covariance):由方差性质(3)的意义,定义
C
o
v
(
X
,
Y
)
=
E
[
(
X
−
E
(
X
)
)
(
Y
−
E
(
Y
)
)
]
\mathrm{Cov}(X,Y)=E[(X-E(X))(Y-E(Y))]
C o v ( X , Y ) = E [ ( X − E ( X ) ) ( Y − E ( Y ) ) ]
X
,
Y
X,Y
X , Y 协方差 。协方差的基本性质 :(其中 a , b 为常数)
X
,
Y
X,Y
X , Y
C
o
v
(
X
,
Y
)
=
0
\mathrm{Cov}(X,Y )=0
C o v ( X , Y ) = 0
C
o
v
(
X
,
Y
)
=
C
o
v
(
Y
,
X
)
\mathrm{Cov}(X,Y )=\mathrm{Cov}(Y,X)
C o v ( X , Y ) = C o v ( Y , X )
D
(
X
)
=
E
[
(
X
−
E
(
X
)
)
2
]
=
C
o
v
(
X
,
X
)
D(X)=E[(X-E(X))^2]=\mathrm{Cov}(X,X)
D ( X ) = E [ ( X − E ( X ) ) 2 ] = C o v ( X , X )
C
o
v
(
a
X
,
b
Y
)
=
a
b
C
o
v
(
X
,
Y
)
\mathrm{Cov}(aX,bY )=ab \mathrm{Cov}(X,Y)
C o v ( a X , b Y ) = a b C o v ( X , Y )
C
o
v
(
X
1
+
X
2
,
Y
)
=
C
o
v
(
X
1
,
Y
)
+
C
o
v
(
X
2
,
Y
)
\mathrm{Cov}(X_1+X_2,Y )=\mathrm{Cov}(X_1,Y)+\mathrm{Cov}(X_2,Y)
C o v ( X 1 + X 2 , Y ) = C o v ( X 1 , Y ) + C o v ( X 2 , Y )
D
(
X
+
Y
)
=
D
(
X
)
+
D
(
Y
)
+
2
C
o
v
(
X
,
Y
)
D(X+Y)=D(X)+D(Y)+2 \mathrm{Cov}(X,Y)
D ( X + Y ) = D ( X ) + D ( Y ) + 2 C o v ( X , Y )
C
o
v
(
X
,
Y
)
=
E
(
X
Y
)
−
E
(
X
)
E
(
Y
)
\mathrm{Cov}(X,Y)=E(XY)-E(X)E(Y)
C o v ( X , Y ) = E ( X Y ) − E ( X ) E ( Y )
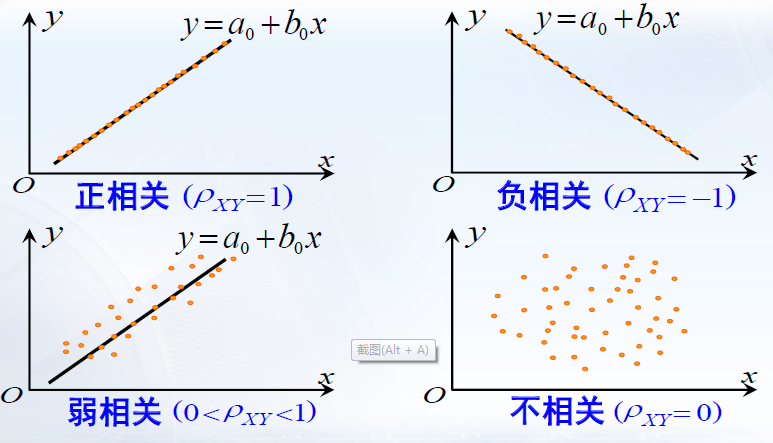
相关系数 (correlation coefficient):协方差反映了随机变量X与Y的相关性(这种关系是什么关系?)。但协方差是有量纲的数字特征,为了消除其量纲的影响,考虑单位化 的随机变量,令
X
∗
=
X
−
E
(
X
)
D
(
X
)
,
Y
∗
=
Y
−
E
(
Y
)
D
(
Y
)
X^*=\dfrac{X-E(X)}{\sqrt{D(X)}},Y^*=\dfrac{Y-E(Y)}{\sqrt{D(Y)}}
X ∗ = D ( X )
X − E ( X ) , Y ∗ = D ( Y )
Y − E ( Y )
ρ
X
Y
=
C
o
v
(
X
∗
,
Y
∗
)
=
C
o
v
(
X
,
Y
)
D
(
X
)
D
(
Y
)
ρ_{XY}=\mathrm{Cov}(X^*,Y^*)=\dfrac{\mathrm{Cov}(X,Y)}{\sqrt{D(X)}\sqrt{D(Y)}}
ρ X Y = C o v ( X ∗ , Y ∗ ) = D ( X )
D ( Y )
C o v ( X , Y )
X
,
Y
X,Y
X , Y 相关系数
进一步考虑
X
,
Y
X,Y
X , Y
X
,
Y
X,Y
X , Y
Y
^
=
a
+
b
X
\hat Y=a+bX
Y ^ = a + b X
Y
Y
Y
e
=
E
[
(
Y
−
Y
^
)
2
]
=
E
[
(
Y
−
(
a
+
b
X
)
)
2
]
e=E[(Y-\hat Y)^2]=E[(Y-(a+bX))^2]
e = E [ ( Y − Y ^ ) 2 ] = E [ ( Y − ( a + b X ) ) 2 ]
min
{
e
}
\min\{e\}
min { e }
∂
e
∂
a
=
0
,
∂
e
∂
b
=
0
\dfrac{∂ e}{∂ a}=0,\dfrac{∂ e}{∂ b}=0
∂ a ∂ e = 0 , ∂ b ∂ e = 0
b
0
=
C
o
v
(
X
,
Y
)
D
(
X
)
,
a
0
=
E
(
Y
)
−
b
0
E
(
X
)
b_0=\dfrac{\mathrm{Cov}(X,Y)}{D(X)},a_0=E(Y)-b_0E(X)
b 0 = D ( X ) C o v ( X , Y ) , a 0 = E ( Y ) − b 0 E ( X )
min
{
e
}
=
D
(
Y
)
(
1
−
ρ
X
Y
2
)
\min\{e\}=D(Y)(1-ρ^2_{XY})
min { e } = D ( Y ) ( 1 − ρ X Y 2 )
相关系数的性质 :
ρ
X
Y
⩽
1
ρ_{XY}⩽ 1
ρ X Y ⩽ 1
ρ
X
Y
=
1
⟺
∃
a
,
b
∈
R
,
Y
=
a
X
+
b
ρ_{XY}=1\iff ∃ a,b\in\R,Y=aX+b
ρ X Y = 1 ⟺ ∃ a , b ∈ R , Y = a X + b
相关系数的实际意义
ρ
X
Y
ρ_{XY}
ρ X Y
ρ
X
Y
ρ_{XY}
ρ X Y
∣
ρ
X
Y
∣
=
1
|ρ_{XY}|=1
∣ ρ X Y ∣ = 1
ρ
X
Y
=
0
ρ_{XY}=0
ρ X Y = 0
⟹
\implies
⟹
参考链接:https://www.zhihu.com/question/23236070/answer/143316942
物理意义 :数学中矩的概念来自物理学。在物理学中,矩是表示距离和物理量乘积的物理量,表征物体的空间分布。由其定义,矩通常需要一个参考点(基点或参考系)来定义距离。如力和参考点距离乘积得到的力矩(或扭矩),原则上任何物理量和距离相乘都会产生力矩,质量,电荷分布等。
ν
k
=
∫
r
k
ρ
(
r
)
d
r
ν_k=\displaystyle\int r^kρ(r)\mathrm{d}r
ν k = ∫ r k ρ ( r ) d r
数学意义 :矩是物体形状识别的重要参数指标。在统计学中,矩是对变量分布和形态特点的一组度量。定义在实数域的实函数相对于值c的k阶矩为:
ν
k
=
∫
−
∞
+
∞
(
x
−
c
)
k
f
(
x
)
d
x
ν_k = \int_{-∞}^{+∞} (x - c)^k\,f(x)\,\mathrm{d}x
ν k = ∫ − ∞ + ∞ ( x − c ) k f ( x ) d x
(1) k阶(原点)矩 (origin moment):随机变量
X
X
X
μ
k
=
E
(
X
k
)
μ_k=E(X^k)
μ k = E ( X k )
连续型:
μ
k
=
∫
−
∞
+
∞
x
k
f
(
x
)
d
x
=
∫
−
∞
+
∞
x
k
d
F
(
x
)
μ_k =\displaystyle \int_{-∞}^{+∞} x^k\,f(x)\,\mathrm{d}x= \int_{-∞}^{+∞} x^k\,\mathrm{d}F(x)
μ k = ∫ − ∞ + ∞ x k f ( x ) d x = ∫ − ∞ + ∞ x k d F ( x )
f
(
x
)
f(x)
f ( x )
μ
k
=
∑
i
=
1
∞
x
i
k
p
i
μ_k=\displaystyle\sum_{i=1}^{∞}x_i^kp_i
μ k = i = 1 ∑ ∞ x i k p i
P
{
X
=
x
i
}
=
p
i
P\{X=x_i\}=p_i
P { X = x i } = p i k 阶中心矩 (central moment):移除均值后计算的矩被称为中心矩。 对于二阶及更高阶的矩,通常使用中心矩(围绕平均值的矩,均值是一阶矩),而不是原点矩,因为中心矩能更清楚的体现关于分布形状的信息。
ν
k
=
E
[
(
X
−
E
(
X
)
)
k
]
ν_k=E[(X-E(X))^k]
ν k = E [ ( X − E ( X ) ) k ]
连续型:
ν
k
=
∫
−
∞
+
∞
[
x
−
E
(
X
)
]
k
f
(
x
)
d
x
ν_k = \displaystyle\int_{-∞}^{+∞} [x-E(X)]^k\,f(x)\,\mathrm{d}x
ν k = ∫ − ∞ + ∞ [ x − E ( X ) ] k f ( x ) d x
f
(
x
)
f(x)
f ( x )
ν
k
=
∑
i
=
1
∞
[
x
i
−
E
(
X
)
]
k
p
i
ν_k=\displaystyle\sum_{i=1}^{∞}[x_i-E(X)]^kp_i
ν k = i = 1 ∑ ∞ [ x i − E ( X ) ] k p i
P
{
X
=
x
i
}
=
p
i
P\{X=x_i\}=p_i
P { X = x i } = p i 期望和方差 :随机变量的数学期望(expectation)即为其一阶原点矩
E
(
X
)
E(X)
E ( X )
V
a
r
(
X
)
=
E
[
x
−
E
(
X
)
]
2
Var(X)=E [x-E(X)]^2
V a r ( X ) = E [ x − E ( X ) ] 2
(3)
(
k
+
l
)
(k+l)
( k + l )
(
X
,
Y
)
(X,Y)
( X , Y )
(
k
+
l
)
(k+l)
( k + l )
μ
k
l
′
=
E
(
X
k
Y
l
)
μ'_{kl}=E(X^kY^l)
μ k l ′ = E ( X k Y l )
连续型:
μ
k
l
′
=
∫
−
∞
+
∞
∫
−
∞
+
∞
x
k
y
l
f
(
x
,
y
)
d
x
d
y
\displaystyle μ'_{kl}= \int_{-∞}^{+∞}\int_{-∞}^{+∞} x^ky^lf(x,y)\,\mathrm{d}x\mathrm{d}y
μ k l ′ = ∫ − ∞ + ∞ ∫ − ∞ + ∞ x k y l f ( x , y ) d x d y
f
(
x
,
y
)
f(x,y)
f ( x , y )
μ
k
l
′
=
∑
i
=
1
∞
∑
j
=
1
∞
x
i
k
y
j
l
p
i
j
μ'_{kl}=\displaystyle\sum_{i=1}^{∞}\sum_{j=1}^{∞}x_i^ky_j^lp_{ij}
μ k l ′ = i = 1 ∑ ∞ j = 1 ∑ ∞ x i k y j l p i j
P
{
X
=
x
i
,
Y
=
y
j
}
=
p
i
j
P\{X=x_i,Y=y_j\}=p_{ij}
P { X = x i , Y = y j } = p i j
(
k
+
l
)
(k+l)
( k + l )
(
X
,
Y
)
的
(
k
+
l
)
(X,Y)的(k+l)
( X , Y ) 的 ( k + l )
μ
k
l
′
=
E
[
(
X
−
E
(
X
)
)
k
(
Y
−
E
(
Y
)
)
l
]
μ'_{kl}=E[(X-E(X))^k(Y-E(Y))^l]
μ k l ′ = E [ ( X − E ( X ) ) k ( Y − E ( Y ) ) l ]
连续型:
μ
k
l
′
=
∫
−
∞
+
∞
∫
−
∞
+
∞
[
x
−
E
(
X
)
]
k
[
y
−
E
(
Y
)
]
l
f
(
x
,
y
)
d
x
d
y
μ'_{kl}= \displaystyle\int_{-∞}^{+∞}\int_{-∞}^{+∞} [x-E(X)]^k[y-E(Y)]^lf(x,y)\,\mathrm{d}x\mathrm{d}y
μ k l ′ = ∫ − ∞ + ∞ ∫ − ∞ + ∞ [ x − E ( X ) ] k [ y − E ( Y ) ] l f ( x , y ) d x d y
f
(
x
,
y
)
f(x,y)
f ( x , y )
μ
k
l
′
=
∑
i
=
1
∞
∑
j
=
1
∞
[
x
i
−
E
(
X
)
]
k
[
y
j
−
E
(
Y
)
]
l
p
i
j
μ'_{kl}=\displaystyle\sum_{i=1}^{∞}\sum_{j=1}^{∞}[x_i-E(X)]^k[y_j-E(Y)]^lp_{ij}
μ k l ′ = i = 1 ∑ ∞ j = 1 ∑ ∞ [ x i − E ( X ) ] k [ y j − E ( Y ) ] l p i j
P
{
X
=
x
i
,
Y
=
y
j
}
=
p
i
j
P\{X=x_i,Y=y_j\}=p_{ij}
P { X = x i , Y = y j } = p i j
(1+1) 阶混合中心矩即为协方差。
矩母函数 (moment generating function, MFG):在统计学中,矩母函数是一个关于随机变量的实值函数,它可以替代密度函数来描述分布。也就是说,出了概率密度函数外,我们也可以通过矩母函数来描述分布。对于某些概率密度函数和累计密度函数比较复杂的情况,我们使用矩母函数分析分布会大大降低复杂性,尤其是对于随机变量的加权求和来说,矩母函数可以提供非常简单的计算。当然,矩母函数出了是基于实值函数,也可以是基于向量和矩阵的,扩展性很好。但是,并不是所有的分布都存在矩母函数。
定义随机变量
e
t
X
e^{tX}
e t X
X
X
X
M
X
(
t
)
=
E
(
e
t
X
)
,
t
∈
R
M_X(t)=E(e^{tX}),t\in\R
M X ( t ) = E ( e t X ) , t ∈ R
连续型:
M
X
(
t
)
=
∫
−
∞
+
∞
exp
(
t
x
)
f
(
x
)
d
x
M_X(t)=\displaystyle\int_{-∞}^{+∞}\exp(tx)f(x)\mathrm{d}x
M X ( t ) = ∫ − ∞ + ∞ exp ( t x ) f ( x ) d x
f
(
x
)
f(x)
f ( x )
M
X
(
t
)
=
∑
exp
(
t
x
i
)
p
i
M_X(t)=\displaystyle\sum \exp(tx_i)p_i
M X ( t ) = ∑ exp ( t x i ) p i
P
{
X
=
x
i
}
=
p
i
P\{X=x_i\}=p_i
P { X = x i } = p i
R
X
(
t
)
=
ln
M
X
(
t
)
R_X(t)=\ln M_X(t)
R X ( t ) = ln M X ( t ) 矩母函数的性质
M
Y
(
t
)
=
M
X
(
t
)
⟺
F
X
(
x
)
=
F
Y
(
y
)
M_Y(t)=M_X(t) \iff F_X(x)=F_Y(y)
M Y ( t ) = M X ( t ) ⟺ F X ( x ) = F Y ( y )
X
1
,
X
2
,
⋯
,
X
n
X_1,X_2,\cdots,X_n
X 1 , X 2 , ⋯ , X n
Y
=
X
1
+
X
2
+
⋯
,
X
n
Y=X_1+X_2+\cdots,X_n
Y = X 1 + X 2 + ⋯ , X n
M
Y
(
t
)
=
M
X
1
(
t
)
M
X
1
(
t
)
⋯
M
X
1
(
t
)
M_Y(t)=M_{X_1}(t)M_{X_1}(t)\cdots M_{X_1}(t)
M Y ( t ) = M X 1 ( t ) M X 1 ( t ) ⋯ M X 1 ( t )
Y
=
a
+
b
X
Y=a+bX
Y = a + b X
M
Y
(
t
)
=
e
a
t
M
X
(
b
t
)
M_Y(t)=e^{at}M_X(bt)
M Y ( t ) = e a t M X ( b t )
矩母函数的特征 :以连续随机变量为例,离散型随机变量可做相同变换。
e
x
=
1
+
x
+
x
2
2
!
+
⋯
+
x
n
n
!
+
⋯
e^x=1+x+\dfrac{x^2}{2!}+\cdots+\dfrac{x^n}{n!}+\cdots
e x = 1 + x + 2 ! x 2 + ⋯ + n ! x n + ⋯
M
X
(
t
)
=
E
(
e
t
X
)
=
∫
−
∞
+
∞
[
1
+
t
x
+
(
t
x
)
2
2
!
+
⋯
+
(
t
x
)
n
n
!
+
⋯
]
f
(
x
)
d
x
M_X(t)=E(e^{tX})=\displaystyle\int_{-∞}^{+∞}[1+tx+\dfrac{(tx)^2}{2!}+\cdots+\dfrac{(tx)^n}{n!}+\cdots] f(x)\mathrm{d}x
M X ( t ) = E ( e t X ) = ∫ − ∞ + ∞ [ 1 + t x + 2 ! ( t x ) 2 + ⋯ + n ! ( t x ) n + ⋯ ] f ( x ) d x
M
X
(
t
)
=
1
+
t
M
1
+
t
2
2
!
M
2
+
⋯
+
t
n
n
!
M
n
+
⋯
M_X(t)=1+tM_1+\dfrac{t^2}{2!}M_2+\cdots+\dfrac{t^n}{n!}M_n+\cdots
M X ( t ) = 1 + t M 1 + 2 ! t 2 M 2 + ⋯ + n ! t n M n + ⋯
M
i
M_i
M i
X
X
X
i
i
i
M
X
(
−
t
)
M_X(-t)
M X ( − t )
M
X
(
t
)
=
∫
−
∞
+
∞
e
t
x
d
F
(
x
)
M_X(t)=\displaystyle\int_{-∞}^{+∞}e^{tx}\mathrm{d}F(x)
M X ( t ) = ∫ − ∞ + ∞ e t x d F ( x )
F
(
x
)
F(x)
F ( x )
特征函数 (characteristic function):定义复随机变量
e
i
t
X
e^{itX}
e i t X
X
X
X
φ
X
(
t
)
=
E
(
e
i
t
X
)
,
t
∈
R
φ_X(t)=E(e^{itX}),t\in\R
φ X ( t ) = E ( e i t X ) , t ∈ R
φ
X
(
t
)
=
M
X
(
i
t
)
φ_X(t)=M_X(it)
φ X ( t ) = M X ( i t )
求随机变量的矩 :如果随机变量
X
X
X
E
(
X
k
)
=
M
X
(
k
)
(
0
)
=
d
k
M
X
d
t
k
∣
t
=
0
E(X^k)=M_X^{(k)}(0)=\dfrac{\mathrm{d}^kM_X}{\mathrm{d}t^k}|_{t=0}
E ( X k ) = M X ( k ) ( 0 ) = d t k d k M X ∣ t = 0
E
(
X
)
=
M
X
′
(
0
)
,
V
a
r
(
X
)
=
M
X
′
′
(
0
)
−
[
M
X
′
(
0
)
]
2
E(X)=M'_X(0),Var(X)=M''_X(0)-[M'_X(0)]^2
E ( X ) = M X ′ ( 0 ) , V a r ( X ) = M X ′ ′ ( 0 ) − [ M X ′ ( 0 ) ] 2
偏度 (skewness):随机变量的偏度(衡量分布不对称性)定义为
S
(
X
)
=
ν
3
ν
2
3
/
2
=
E
[
X
−
E
(
X
)
]
3
[
V
a
r
(
x
)
]
3
/
2
S(X)=\dfrac{ν_3}{ν_{2}^{3/2}}=\dfrac{E[X-E(X)]^3}{[Var(x)]^{3/2}}
S ( X ) = ν 2 3 / 2 ν 3 = [ V a r ( x ) ] 3 / 2 E [ X − E ( X ) ] 3
S
<
0
S<0
S < 0
S
>
0
S>0
S > 0 峰度 (kurtosis):一般随机变量的峰度定义为其四阶中心矩与方差平方的比值再减3,减3是为了让正态分布峰度为0,这也被称为超值峰度。
K
(
X
)
=
ν
4
ν
2
2
−
3
=
E
[
x
−
E
(
X
)
]
4
V
a
r
2
(
X
)
−
3
K(X)=\dfrac{ν_4}{ν_{2}^{2}}-3=\dfrac{E[x-E(X)]^4}{Var^2(X)}-3
K ( X ) = ν 2 2 ν 4 − 3 = V a r 2 ( X ) E [ x − E ( X ) ] 4 − 3
K
>
0
K>0
K > 0
K
<
0
K<0
K < 0
协方差矩阵 (Covariance matrix):设n维随机变量
X
=
(
X
1
,
X
2
,
⋯
,
X
n
)
\mathbf{X}=(X_1,X_2,\cdots,X_n)
X = ( X 1 , X 2 , ⋯ , X n )
c
i
j
=
C
o
v
(
X
i
,
X
j
)
(
i
,
j
=
1
,
2
,
⋯
,
n
)
c_{ij}=\mathrm{Cov}(X_i,X_j)\ (i,j=1,2,\cdots,n)
c i j = C o v ( X i , X j ) ( i , j = 1 , 2 , ⋯ , n )
C
=
(
c
i
j
)
n
×
n
C=(c_ij)_{n× n}
C = ( c i j ) n × n
X
\mathbf{X}
X
C
=
C
T
C=C^T
C = C T
C
⩾
0
C⩾ 0
C ⩾ 0 定理 :设
(
X
,
Y
)
∼
N
(
μ
1
,
μ
2
,
σ
1
,
σ
2
,
ρ
)
(X,Y)∼ N(μ_1,μ_2,σ_1,σ_2,ρ)
( X , Y ) ∼ N ( μ 1 , μ 2 , σ 1 , σ 2 , ρ )
X
,
Y
X,Y
X , Y
ρ
X
Y
=
ρ
ρ_{XY}=ρ
ρ X Y = ρ
X
,
Y
X,Y
X , Y
C
=
(
σ
1
2
ρ
σ
1
σ
2
ρ
σ
1
σ
2
σ
2
)
C=\begin{pmatrix} σ_1^2&ρσ_1σ_2 \\ ρσ_1σ_2&σ_2 \end{pmatrix}
C = ( σ 1 2 ρ σ 1 σ 2 ρ σ 1 σ 2 σ 2 )
X
,
Y
X,Y
X , Y
⟺
ρ
X
Y
=
ρ
=
0
\iff ρ_{XY}=ρ=0
⟺ ρ X Y = ρ = 0
⟺
X
,
Y
\iff X,Y
⟺ X , Y
f
(
x
)
=
1
2
π
∣
C
∣
1
/
2
exp
{
−
1
2
(
x
−
μ
)
C
−
1
(
x
−
μ
)
T
}
f(\mathbf{x})=\dfrac{1}{2π|C|^{1/2}}\exp\{-\dfrac{1}{2}(\mathbf{x-μ})C^{-1}(\mathbf{x-μ})^T\}
f ( x ) = 2 π ∣ C ∣ 1 / 2 1 exp { − 2 1 ( x − μ ) C − 1 ( x − μ ) T }
x
=
(
x
,
y
)
,
μ
=
(
μ
1
,
μ
2
)
,
C
\mathbf{x}=(x,y),\mathbf{μ}=(μ_1,μ_2),C
x = ( x , y ) , μ = ( μ 1 , μ 2 ) , C
n维正态随机变量 :设
C
C
C
μ
=
(
μ
1
,
μ
2
,
⋯
,
μ
n
)
μ=(μ_1,μ_2,\cdots,μ_n)
μ = ( μ 1 , μ 2 , ⋯ , μ n )
x
=
(
x
1
,
x
2
,
⋯
,
x
n
)
∈
R
n
\mathbf{x}=(x_1,x_2,\cdots,x_n)\in\R^n
x = ( x 1 , x 2 , ⋯ , x n ) ∈ R n
X
=
(
X
1
,
X
2
,
⋯
,
X
n
)
\mathbf{X}=(X_1,X_2,\cdots,X_n)
X = ( X 1 , X 2 , ⋯ , X n )
f
(
x
)
=
1
(
2
π
)
n
/
2
∣
C
∣
1
/
2
exp
{
−
1
2
(
x
−
μ
)
C
−
1
(
x
−
μ
)
T
}
f(\mathbf{x})=\dfrac{1}{(2π)^{n/2}|C|^{1/2}}\exp\{-\dfrac{1}{2}(\mathbf{x-μ})C^{-1}(\mathbf{x-μ})^T\}
f ( x ) = ( 2 π ) n / 2 ∣ C ∣ 1 / 2 1 exp { − 2 1 ( x − μ ) C − 1 ( x − μ ) T }
X
\mathbf{X}
X
X
=
(
X
1
,
X
2
,
⋯
,
X
n
)
∼
N
(
μ
,
C
)
\mathbf{X}=(X_1,X_2,\cdots,X_n)∼ N(μ,C)
X = ( X 1 , X 2 , ⋯ , X n ) ∼ N ( μ , C )
n 维正态分布的性质 :
X
=
(
X
1
,
X
2
,
⋯
,
X
n
)
∼
N
(
μ
,
C
)
\mathbf{X}=(X_1,X_2,\cdots,X_n)∼ N(μ,C)
X = ( X 1 , X 2 , ⋯ , X n ) ∼ N ( μ , C )
f
(
x
)
>
0
f(\mathbf{x})>0
f ( x ) > 0
∫
−
∞
+
∞
⋯
∫
−
∞
+
∞
f
(
x
1
,
x
2
,
⋯
,
x
n
)
d
x
1
d
x
2
⋯
d
x
n
=
1
\displaystyle\int_{-∞}^{+∞}\cdots\int_{-∞}^{+∞}f(x_1,x_2,\cdots,x_n)\mathrm{d}x_1\mathrm{d}x_2\cdots\mathrm{d}x_n=1
∫ − ∞ + ∞ ⋯ ∫ − ∞ + ∞ f ( x 1 , x 2 , ⋯ , x n ) d x 1 d x 2 ⋯ d x n = 1
μ
i
=
E
(
x
i
)
(
1
=
1
,
2
,
⋯
,
n
)
μ_i=E(x_i)\quad (1=1,2,\cdots,n)
μ i = E ( x i ) ( 1 = 1 , 2 , ⋯ , n )
C
=
(
c
i
j
)
n
×
n
C=(c_{ij})_{n× n}
C = ( c i j ) n × n
(
X
1
,
X
2
,
⋯
,
X
n
)
(X_1,X_2,\cdots,X_n)
( X 1 , X 2 , ⋯ , X n )
D
(
X
i
)
=
c
i
i
(
1
=
1
,
2
,
⋯
,
n
)
C
o
v
(
X
i
,
X
j
)
=
c
i
j
(
1
=
1
,
2
,
⋯
,
n
)
D(X_i)=c_{ii} \quad (1=1,2,\cdots,n) \\ \mathrm{Cov}(X_i,X_j)=c_{ij}\quad (1=1,2,\cdots,n)
D ( X i ) = c i i ( 1 = 1 , 2 , ⋯ , n ) C o v ( X i , X j ) = c i j ( 1 = 1 , 2 , ⋯ , n )
X
i
∼
N
(
μ
i
,
c
i
i
)
(
1
=
1
,
2
,
⋯
,
n
)
X_i∼ N(μ_i,c_{ii})\quad (1=1,2,\cdots,n)
X i ∼ N ( μ i , c i i ) ( 1 = 1 , 2 , ⋯ , n )
X
1
,
X
2
,
⋯
,
X
n
X_1,X_2,\cdots,X_n
X 1 , X 2 , ⋯ , X n
X
i
∼
N
(
μ
i
,
σ
i
2
)
X_i∼ N(μ_i,σ_i^2)
X i ∼ N ( μ i , σ i 2 )
(
X
1
,
X
2
,
⋯
,
X
n
)
∼
N
(
μ
,
C
)
(X_1,X_2,\cdots,X_n)∼ N(μ,C)
( X 1 , X 2 , ⋯ , X n ) ∼ N ( μ , C )
μ
=
(
μ
1
,
μ
2
,
⋯
,
μ
n
)
,
C
=
d
i
a
g
(
σ
1
2
,
σ
1
2
⋯
,
σ
n
2
)
μ=(μ_1,μ_2,\cdots,μ_n),C=\mathrm{diag}(σ_1^2,σ_1^2\cdots,σ_n^2)
μ = ( μ 1 , μ 2 , ⋯ , μ n ) , C = d i a g ( σ 1 2 , σ 1 2 ⋯ , σ n 2 )
重要定理
X
=
(
X
1
,
X
2
,
⋯
,
X
n
)
∼
N
(
μ
,
C
)
\mathbf{X}=(X_1,X_2,\cdots,X_n)∼ N(μ,C)
X = ( X 1 , X 2 , ⋯ , X n ) ∼ N ( μ , C )
k
(
1
⩽
k
⩽
n
)
k(1⩽ k⩽ n)
k ( 1 ⩽ k ⩽ n )
X
=
(
X
1
,
X
2
,
⋯
,
X
n
)
∼
N
(
μ
,
C
)
⟺
X
1
,
X
2
,
⋯
,
X
n
\mathbf{X}=(X_1,X_2,\cdots,X_n)∼ N(μ,C) \iff X_1,X_2,\cdots,X_n
X = ( X 1 , X 2 , ⋯ , X n ) ∼ N ( μ , C ) ⟺ X 1 , X 2 , ⋯ , X n
l
1
X
1
+
l
2
X
2
+
⋯
l
n
X
n
l_1X_1+l_2X_2+\cdots l_nX_n
l 1 X 1 + l 2 X 2 + ⋯ l n X n
Y
=
X
A
Y=XA
Y = X A
A
=
(
a
i
j
)
n
×
m
A=(a_{ij})_{n× m}
A = ( a i j ) n × m
Y
=
(
Y
1
,
Y
2
,
⋯
,
Y
m
)
Y=(Y_1,Y_2,\cdots,Y_m)
Y = ( Y 1 , Y 2 , ⋯ , Y m )
X
1
,
X
2
,
⋯
,
X
n
X_1,X_2,\cdots,X_n
X 1 , X 2 , ⋯ , X n
⟺
X
1
,
X
2
,
⋯
,
X
n
\iff X_1,X_2,\cdots,X_n
⟺ X 1 , X 2 , ⋯ , X n
⟺
C
=
d
i
a
g
(
c
11
,
c
22
,
⋯
,
c
n
n
)
\iff C=\mathrm{diag}(c_{11},c_{22},\cdots,c_{nn})
⟺ C = d i a g ( c 1 1 , c 2 2 , ⋯ , c n n )
依概率收敛 (convergence in probability):回顾概率的概念是如何产生的?
n
n
n
A
A
A
n
A
n_A
n A
n
n
n
∀
ϵ
>
0
,
lim
n
→
∞
P
{
∣
n
A
n
−
p
∣
⩾
ϵ
}
=
0
∀ ϵ>0,\lim\limits_{n\to∞}P\{|\dfrac{n_A}{n}-p|⩾ ϵ\}=0
∀ ϵ > 0 , n → ∞ lim P { ∣ n n A − p ∣ ⩾ ϵ } = 0
定义 :设
Y
1
,
Y
2
,
⋯
,
Y
n
,
⋯
Y_1,Y_2,\cdots,Y_n,\cdots
Y 1 , Y 2 , ⋯ , Y n , ⋯
∀
ϵ
>
0
∀ ϵ>0
∀ ϵ > 0
lim
n
→
∞
P
{
∣
Y
n
−
c
∣
⩾
ϵ
}
=
0
\lim\limits_{n\to∞}P\{|Y_n-c|⩾ ϵ\}=0
n → ∞ lim P { ∣ Y n − c ∣ ⩾ ϵ } = 0 依概率收敛 于c,记为
Y
n
→
P
c
(
n
→
∞
)
Y_n\xrightarrow{P}c\quad (n\to∞)
Y n P
c ( n → ∞ )
性质 :若
X
n
→
P
a
,
Y
n
→
P
b
(
n
→
∞
)
X_n\xrightarrow{P}a,Y_n\xrightarrow{P}b\quad (n\to∞)
X n P
a , Y n P
b ( n → ∞ )
g
(
x
,
y
)
g(x,y)
g ( x , y )
(
a
,
b
)
(a,b)
( a , b )
g
(
X
n
,
Y
n
)
→
P
g
(
a
,
b
)
(
n
→
∞
)
g(X_n,Y_n)\xrightarrow{P}g(a,b)\quad (n\to∞)
g ( X n , Y n ) P
g ( a , b ) ( n → ∞ )
X
n
→
P
a
(
n
→
∞
)
X_n\xrightarrow{P}a\quad (n\to∞)
X n P
a ( n → ∞ )
f
(
x
)
f(x)
f ( x )
a
a
a
f
(
X
n
)
→
P
f
(
a
)
(
n
→
∞
)
f(X_n)\xrightarrow{P}f(a)\quad (n\to∞)
f ( X n ) P
f ( a ) ( n → ∞ )
大数定律 (Law of Large Numbers)
Bernoulli 大数定律 设
n
A
n_A
n A
n
n
n
A
A
A
P
(
A
)
=
p
P(A)=p
P ( A ) = p
∀
ϵ
>
0
∀ ϵ>0
∀ ϵ > 0
lim
n
→
∞
P
{
∣
n
A
n
−
p
∣
⩾
ϵ
}
=
0
\lim\limits_{n\to∞}P\{|\dfrac{n_A}{n}-p|⩾ ϵ\}=0
n → ∞ lim P { ∣ n n A − p ∣ ⩾ ϵ } = 0
n
A
n
→
P
p
(
n
→
∞
)
\dfrac{n_A}{n}\xrightarrow{P}p\quad (n\to∞)
n n A P
p ( n → ∞ ) 频率稳定于概率
Chebyshev 大数定律 设
X
1
,
X
2
,
⋯
,
X
n
,
⋯
X_1,X_2,\cdots,X_n,\cdots
X 1 , X 2 , ⋯ , X n , ⋯
μ
μ
μ
σ
2
σ^2
σ 2
∀
ϵ
>
0
∀ ϵ>0
∀ ϵ > 0
lim
n
→
∞
P
{
∣
1
n
∑
i
=
1
n
X
i
−
μ
∣
⩾
ϵ
}
=
0
\lim\limits_{n\to∞}P\{|\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}X_i-μ|⩾ ϵ\}=0
n → ∞ lim P { ∣ n 1 i = 1 ∑ n X i − μ ∣ ⩾ ϵ } = 0
1
n
∑
i
=
1
n
X
i
→
P
μ
(
n
→
∞
)
\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}X_i\xrightarrow{P}μ\quad (n\to∞)
n 1 i = 1 ∑ n X i P
μ ( n → ∞ ) 平均值稳定于期望
Sinchin 大数定律 设
X
1
,
X
2
,
⋯
,
X
n
,
⋯
X_1,X_2,\cdots,X_n,\cdots
X 1 , X 2 , ⋯ , X n , ⋯
μ
μ
μ
σ
2
σ^2
σ 2
∀
ϵ
>
0
∀ ϵ>0
∀ ϵ > 0
lim
n
→
∞
P
{
∣
1
n
∑
i
=
1
n
X
i
−
μ
∣
⩾
ϵ
}
=
0
\lim\limits_{n\to∞}P\{|\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}X_i-μ|⩾ ϵ\}=0
n → ∞ lim P { ∣ n 1 i = 1 ∑ n X i − μ ∣ ⩾ ϵ } = 0
1
n
∑
i
=
1
n
X
i
→
P
μ
(
n
→
∞
)
\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}X_i\xrightarrow{P}μ\quad (n\to∞)
n 1 i = 1 ∑ n X i P
μ ( n → ∞ )
大数定律的意义
中心极限定理 (Central Limit Theorem)
有许多随机变量,它们是由大量的相互独立的随机变量的综合影响所形成的,而其中每个个别的因素作用都很小,这种随机变量往往服从或近似服从正态分布,或者说它的极限分布是正态分布,中心极限定理正是从数学上论证了这一现象,它在长达两个世纪的时期内曾是概率论研究的中心课题。
独立同分布的中心极限定理 设
X
1
,
X
2
,
⋯
,
X
n
,
⋯
X_1,X_2,\cdots,X_n,\cdots
X 1 , X 2 , ⋯ , X n , ⋯
μ
μ
μ
σ
2
σ^2
σ 2
Y
n
=
∑
i
=
1
n
X
i
Y_n=\displaystyle\sum_{i=1}^{n}X_i
Y n = i = 1 ∑ n X i
Z
n
=
Y
n
−
E
(
Y
n
)
D
(
Y
n
)
=
∑
i
=
1
n
X
i
−
n
μ
n
σ
Z_n=\dfrac{Y_n-E(Y_n)}{\sqrt{D(Y_n)}}=\dfrac{\displaystyle\sum_{i=1}^{n}X_i-nμ}{\sqrt{n}σ}
Z n = D ( Y n )
Y n − E ( Y n ) = n
σ i = 1 ∑ n X i − n μ
F
n
(
x
)
F_n(x)
F n ( x )
∀
x
∈
R
∀ x\in\R
∀ x ∈ R
lim
n
→
∞
F
n
(
x
)
=
lim
n
→
∞
P
{
∑
i
=
1
n
X
i
−
n
μ
n
σ
⩽
x
}
=
∫
−
∞
x
1
2
π
e
−
t
2
/
2
d
t
=
Φ
(
x
)
\begin{aligned} \lim\limits_{n\to∞}F_n(x)&=\lim\limits_{n\to∞}P\left\{\dfrac{\displaystyle\sum_{i=1}^{n}X_i-nμ}{\sqrt{n}σ}⩽ x\right\} \\ &=\displaystyle\int_{-∞}^{x}\dfrac{1}{\sqrt{2π}}e^{-t^2/2}\mathrm{d}t=Φ(x) \end{aligned}
n → ∞ lim F n ( x ) = n → ∞ lim P ⎩ ⎪ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎪ ⎧ n
σ i = 1 ∑ n X i − n μ ⩽ x ⎭ ⎪ ⎪ ⎪ ⎪ ⎬ ⎪ ⎪ ⎪ ⎪ ⎫ = ∫ − ∞ x 2 π
1 e − t 2 / 2 d t = Φ ( x )
lim
n
→
∞
∑
i
=
1
n
X
i
∼
N
(
n
μ
,
n
σ
2
)
\lim\limits_{n\to∞}\displaystyle\sum_{i=1}^{n}X_i∼ N(nμ,nσ^2)
n → ∞ lim i = 1 ∑ n X i ∼ N ( n μ , n σ 2 )
lim
n
→
∞
X
ˉ
−
μ
σ
/
n
∼
N
(
0
,
1
)
\lim\limits_{n\to∞}\dfrac{\bar X-μ}{σ/\sqrt{n}}∼ N(0,1)
n → ∞ lim σ / n
X ˉ − μ ∼ N ( 0 , 1 )
lim
n
→
∞
X
ˉ
∼
N
(
μ
,
σ
2
/
n
)
\lim\limits_{n\to∞}\bar X∼ N(μ,σ^2/n)
n → ∞ lim X ˉ ∼ N ( μ , σ 2 / n )
李雅普诺夫(Lyapunov)中心极限定理 设 随机变量
X
1
,
X
2
,
⋯
,
X
n
,
⋯
X_1,X_2,\cdots,X_n,\cdots
X 1 , X 2 , ⋯ , X n , ⋯
E
(
X
k
)
=
μ
k
E(X_k)=μ_k
E ( X k ) = μ k
D
(
X
k
)
=
σ
k
2
D(X_k)=σ_k^2
D ( X k ) = σ k 2
B
n
2
=
∑
k
=
1
n
σ
k
2
B_n^2=\displaystyle\sum_{k=1}^{n}σ_k^2
B n 2 = k = 1 ∑ n σ k 2
∃
δ
>
0
,
1
B
n
2
+
δ
∑
k
=
1
n
E
(
∣
X
k
−
μ
k
∣
2
+
δ
)
→
0
(
n
→
∞
)
∃ δ>0,\dfrac{1}{B_n^{2+δ}}\displaystyle\sum_{k=1}^{n}E(|X_k-μ_k|^{2+δ})\to0\quad (n\to∞)
∃ δ > 0 , B n 2 + δ 1 k = 1 ∑ n E ( ∣ X k − μ k ∣ 2 + δ ) → 0 ( n → ∞ )
Y
n
=
∑
k
=
1
n
X
k
Y_n=\displaystyle\sum_{k=1}^{n}X_k
Y n = k = 1 ∑ n X k
Z
n
=
Y
n
−
E
(
Y
n
)
D
(
Y
n
)
=
∑
k
=
1
n
X
k
−
∑
k
=
1
n
μ
k
B
n
Z_n=\dfrac{Y_n-E(Y_n)}{\sqrt{D(Y_n)}}=\dfrac{\displaystyle\sum_{k=1}^{n}X_k-\sum_{k=1}^{n}μ_k}{B_n}
Z n = D ( Y n )
Y n − E ( Y n ) = B n k = 1 ∑ n X k − k = 1 ∑ n μ k
F
n
(
x
)
F_n(x)
F n ( x )
∀
x
∈
R
∀ x\in\R
∀ x ∈ R
lim
n
→
∞
F
n
(
x
)
=
lim
n
→
∞
P
{
∑
k
=
1
n
X
k
−
∑
k
=
1
n
μ
k
B
n
⩽
x
}
=
∫
−
∞
x
1
2
π
e
−
t
2
/
2
d
t
=
Φ
(
x
)
\begin{aligned} \lim\limits_{n\to∞}F_n(x)&=\lim\limits_{n\to∞}P\left\{\dfrac{\displaystyle\sum_{k=1}^{n}X_k-\sum_{k=1}^{n}μ_k}{B_n}⩽ x\right\} \\ &=\displaystyle\int_{-∞}^{x}\dfrac{1}{\sqrt{2π}}e^{-t^2/2}\mathrm{d}t=Φ(x) \end{aligned}
n → ∞ lim F n ( x ) = n → ∞ lim P ⎩ ⎪ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎪ ⎧ B n k = 1 ∑ n X k − k = 1 ∑ n μ k ⩽ x ⎭ ⎪ ⎪ ⎪ ⎪ ⎬ ⎪ ⎪ ⎪ ⎪ ⎫ = ∫ − ∞ x 2 π
1 e − t 2 / 2 d t = Φ ( x )
lim
n
→
∞
∑
k
=
1
n
X
k
∼
N
(
∑
k
=
1
n
μ
k
,
B
n
2
)
\lim\limits_{n\to∞}\displaystyle\sum_{k=1}^{n}X_k∼ N(\sum_{k=1}^{n}μ_k,B_n^2)
n → ∞ lim k = 1 ∑ n X k ∼ N ( k = 1 ∑ n μ k , B n 2 )
棣莫弗-拉普拉斯(De Moivre-Laplace)中心极限定理 :若随机变量序列
η
n
∼
B
(
n
,
p
)
(
n
=
1
,
2
,
⋯
)
η_n∼ B(n,p)\quad(n=1,2,\cdots)
η n ∼ B ( n , p ) ( n = 1 , 2 , ⋯ )
∀
x
∈
R
∀ x\in\R
∀ x ∈ R
lim
n
→
∞
P
{
η
n
−
n
p
n
p
(
1
−
p
)
⩽
x
}
=
∫
−
∞
x
1
2
π
e
−
t
2
/
2
d
t
=
Φ
(
x
)
\lim\limits_{n\to∞}P\left\{\dfrac{η_n-np}{\sqrt{np(1-p)}}⩽ x\right\} \\ =\displaystyle\int_{-∞}^{x}\dfrac{1}{\sqrt{2π}}e^{-t^2/2}\mathrm{d}t=Φ(x)
n → ∞ lim P { n p ( 1 − p )
η n − n p ⩽ x } = ∫ − ∞ x 2 π
1 e − t 2 / 2 d t = Φ ( x )
lim
n
→
∞
η
n
∼
N
(
n
p
,
n
p
(
1
−
p
)
)
\lim\limits_{n\to∞}η_n∼ N(np,np(1-p))
n → ∞ lim η n ∼ N ( n p , n p ( 1 − p ) )
中心极限定理的意义 :在实际问题中,如果某随机指标满足
在实际问题中,所考虑的随机变量可以表示成多个独立的随机变量之和,如在任意指定时刻,一城市的耗电量是大量用户耗电量的总和;一个物理实验的测量误差是由许多观察不到的、可叠加的微小误差所合成的;它们往往近似服从正态分布。
常见的离散型随机变量
分布
概率分布
累积分布函数
期望
方差
矩母函数
伯努利分布
B
(
1
,
p
)
B(1,p)
B ( 1 , p )
p
(
1
−
p
)
p(1-p)
p ( 1 − p )
p
p
p
p
(
1
−
p
)
p(1-p)
p ( 1 − p )
1
−
p
+
p
e
t
1-p+pe^t
1 − p + p e t
二项分布
B
(
n
,
p
)
B(n,p)
B ( n , p )
∁
n
k
p
k
(
1
−
p
)
n
−
k
∁^k_np^k(1-p)^{n-k}
∁ n k p k ( 1 − p ) n − k
(
k
=
1
,
2
,
⋯
,
n
)
(k=1,2,\cdots,n)
( k = 1 , 2 , ⋯ , n )
∑
i
=
1
k
∁
n
i
p
i
(
1
−
p
)
n
−
i
\displaystyle\sum_{i=1}^{k} ∁^i_np^i(1-p)^{n-i}
i = 1 ∑ k ∁ n i p i ( 1 − p ) n − i
n
p
np
n p
n
p
(
1
−
p
)
np(1-p)
n p ( 1 − p )
(
1
−
p
+
p
e
t
)
n
(1-p+pe^t)^n
( 1 − p + p e t ) n
几何分布
G
e
o
m
(
p
)
Geom(p)
G e o m ( p )
p
(
1
−
p
)
k
−
1
p(1-p)^{k-1}
p ( 1 − p ) k − 1
(
k
∈
N
)
(k\in\N)
( k ∈ N )
1
−
(
1
−
p
)
k
1-(1-p)^k
1 − ( 1 − p ) k
1
p
\dfrac{1}{p}
p 1
1
−
p
p
2
\dfrac{1-p}{p^2}
p 2 1 − p
p
e
t
1
−
(
1
−
p
)
e
t
\dfrac{pe^t}{1-(1-p)e^t}
1 − ( 1 − p ) e t p e t
泊松分布
P
(
λ
)
P(λ)
P ( λ )
λ
k
e
−
λ
k
!
\dfrac{λ^ke^{-λ}}{k!}
k ! λ k e − λ
(
k
∈
N
)
(k\in\N)
( k ∈ N )
e
−
λ
∑
i
=
1
k
λ
i
i
!
\displaystyle e^{-λ}\sum_{i=1}^{k}\dfrac{λ^i}{i!}
e − λ i = 1 ∑ k i ! λ i
λ
λ
λ
λ
λ
λ
exp
(
λ
(
e
t
−
1
)
)
\exp(λ(e^t-1))
exp ( λ ( e t − 1 ) )
常见的连续型随机变量
分布
概率密度
累积分布函数
期望
方差
矩母函数
均匀分布
U
(
a
,
b
)
U(a,b)
U ( a , b )
1
b
−
a
\dfrac{1}{b-a}
b − a 1
(
x
∈
[
a
,
b
]
)
(x\in[a,b])
( x ∈ [ a , b ] )
x
−
a
b
−
a
\dfrac{x-a}{b-a}
b − a x − a
a
+
b
2
\dfrac{a+b}{2}
2 a + b
(
b
−
a
)
2
12
\dfrac{(b-a)^2}{12}
1 2 ( b − a ) 2
e
b
t
−
e
a
t
t
(
b
−
a
)
\dfrac{e^{bt}-e^{at}}{t(b-a)}
t ( b − a ) e b t − e a t
指数分布
E
x
p
(
θ
)
Exp(θ)
E x p ( θ )
1
θ
e
−
x
/
θ
\frac{1}{θ}e^{-x/θ}
θ 1 e − x / θ
(
x
>
0
)
(x>0)
( x > 0 )
1
−
e
−
x
/
θ
1-e^{-x/θ}
1 − e − x / θ
θ
θ
θ
θ
2
θ^2
θ 2
1
1
−
θ
t
\dfrac{1}{1-θt}
1 − θ t 1
正态分布
N
(
μ
,
σ
2
)
N(μ,σ^2)
N ( μ , σ 2 )
1
2
π
σ
e
−
(
x
−
μ
)
2
2
σ
2
\dfrac{1}{\sqrt{2π}σ}e^{-\frac{(x-μ)^2}{2σ^2}}
2 π
σ 1 e − 2 σ 2 ( x − μ ) 2
(
μ
∈
R
,
σ
>
0
)
(μ\in\R,σ>0)
( μ ∈ R , σ > 0 )
μ
μ
μ
σ
2
σ^2
σ 2
exp
(
μ
t
+
1
2
σ
2
t
2
)
\exp(μt+\frac{1}{2}σ^2t^2)
exp ( μ t + 2 1 σ 2 t 2 )
伽马分布
G
a
m
m
a
(
k
,
θ
)
Gamma(k,θ)
G a m m a ( k , θ )
θ
k
Γ
(
k
)
x
k
−
1
e
−
θ
x
\dfrac{θ^k}{Γ(k)}x^{k-1}e^{-θx}
Γ ( k ) θ k x k − 1 e − θ x
(
x
>
0
)
(x>0)
( x > 0 )
Γ
(
k
)
=
∫
0
∞
x
k
−
1
e
−
x
d
x
\displaystyleΓ(k)=\int_0^{∞}x^{k-1}e^{-x}\mathrm{d}x
Γ ( k ) = ∫ 0 ∞ x k − 1 e − x d x
k
θ
kθ
k θ
k
θ
2
kθ^2
k θ 2
(
1
−
θ
t
)
−
k
(1-θt)^{-k}
( 1 − θ t ) − k
(
t
<
1
/
θ
)
(t<1/θ)
( t < 1 / θ )