概率论与数理统计(Probability & Statistics I) 概率论与数理统计(Probability & Statistics II)
数理统计是以概率论为基础, 关于实验数据的收集、整理、分析与推断的一门科学与艺术。
总体 (population):研究对象的全体;个体 (individual):总体中的每一个具体对象称为个体;总体的容量 (capacity):总体中包含的个体数;有限总体 (finite population):容量有限的总体;无限总体 (infinite population):容量无限的总体。通常将容量非常大的有限总体也按无限总体处理。
为了采用数理统计方法进行分析,首先要收集数据,数据收集方法一般有两种。
实际中人们通常只关注总体的某个(或几个)指标。
总体的某个指标
X
X
X
X
X
X
有时候直接将
X
X
X
X
X
X
F
(
x
)
F(x)
F ( x )
X
X
X
F
(
x
)
F(x)
F ( x )
X
∼
F
(
x
)
X∼ F(x)
X ∼ F ( x )
如何推断总体分布的未知参数(或分布)?样本 (sample)。
简单随机样本 (simple random sample):满足以下两个条件的随机样本
(
X
1
,
X
2
,
…
,
X
n
)
(X_1,X_2,…,X_n)
( X 1 , X 2 , … , X n )
n
n
n
X
i
X_i
X i
X
X
X
(
X
1
,
X
2
,
…
,
X
n
)
(X_1,X_2,…,X_n)
( X 1 , X 2 , … , X n )
获得简单随机样本的抽样称为简单随机抽样。
对于有限总体,采用放回抽样.
但当总体容量很大的时候,放回抽样有时候很不方便, 因此在实际中当总体容量比较大时,通常将不放回抽样所得到的样本近似当作简单随机样本来处理.
对于无限总体, 一般采取不放回抽样.
对样本
X
1
,
X
2
,
…
,
X
n
X_1,X_2,…,X_n
X 1 , X 2 , … , X n
x
1
,
x
2
,
…
,
x
n
x_1,x_2,…,x_n
x 1 , x 2 , … , x n 样本观测值 (observed value)
X
1
,
X
2
,
…
,
X
n
X_1,X_2,…,X_n
X 1 , X 2 , … , X n
x
1
,
x
2
,
…
,
x
n
x_1,x_2,…,x_n
x 1 , x 2 , … , x n
样本的联合分布 :设总体
X
∼
F
(
x
)
X∼ F(x)
X ∼ F ( x )
X
1
,
X
2
,
…
,
X
n
X_1,X_2,…,X_n
X 1 , X 2 , … , X n
F
(
x
1
,
x
2
,
…
,
x
n
)
=
P
{
X
1
⩽
x
1
,
…
,
X
n
⩽
x
n
}
=
∏
i
=
1
n
F
(
x
i
)
F(x_1,x_2,…,x_n)=P\{X_1⩽ x_1,…,X_n⩽ x_n\}=\displaystyle\prod_{i=1}^{n}F(x_i)
F ( x 1 , x 2 , … , x n ) = P { X 1 ⩽ x 1 , … , X n ⩽ x n } = i = 1 ∏ n F ( x i )
X
X
X
f
(
x
)
f(x)
f ( x )
X
1
,
X
2
,
…
,
X
n
X_1,X_2,…,X_n
X 1 , X 2 , … , X n
f
(
x
1
,
x
2
,
…
,
x
n
)
=
∏
i
=
1
n
f
(
x
i
)
f(x_1,x_2,…,x_n)=\displaystyle\prod_{i=1}^{n}f(x_i)
f ( x 1 , x 2 , … , x n ) = i = 1 ∏ n f ( x i )
X
X
X
P
{
X
=
a
k
}
=
p
k
P\{X=a_k\}=p_k
P { X = a k } = p k
X
1
,
X
2
,
…
,
X
n
X_1,X_2,…,X_n
X 1 , X 2 , … , X n
P
{
X
1
=
x
1
,
…
,
X
n
=
x
n
}
=
∏
i
=
1
n
P
{
X
=
x
i
}
P\{X_1=x_1,…,X_n=x_n\}=\displaystyle\prod_{i=1}^{n}P\{X=x_i\}
P { X 1 = x 1 , … , X n = x n } = i = 1 ∏ n P { X = x i }
从样本中提取有用的信息来研究总体的分布及各种特征数——构造统计量.统计量 (statistic):设
X
1
,
X
2
,
…
,
X
n
X_1,X_2,…,X_n
X 1 , X 2 , … , X n
X
∼
F
(
x
)
X∼ F(x)
X ∼ F ( x )
g
(
x
1
,
x
2
,
…
,
x
n
)
g(x_1,x_2,…,x_n)
g ( x 1 , x 2 , … , x n )
n
n
n
g
(
x
1
,
x
2
,
…
,
x
n
)
g(x_1,x_2,…,x_n)
g ( x 1 , x 2 , … , x n )
g
(
X
1
,
X
2
,
…
,
X
n
)
g(X_1,X_2,…,X_n)
g ( X 1 , X 2 , … , X n )
X
ˉ
=
1
n
∑
i
=
1
n
X
i
\bar X=\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}X_i
X ˉ = n 1 i = 1 ∑ n X i
S
2
=
1
n
−
1
∑
i
=
1
n
(
X
i
−
X
ˉ
)
2
S^2=\dfrac{1}{n-1}\displaystyle\sum_{i=1}^{n}(X_i-\bar X)^2
S 2 = n − 1 1 i = 1 ∑ n ( X i − X ˉ ) 2
S
=
S
2
S=\sqrt{S^2}
S = S 2
A
k
=
1
n
∑
i
=
1
n
X
i
k
A_k=\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}X_i^k
A k = n 1 i = 1 ∑ n X i k
B
k
=
1
n
∑
i
=
1
n
(
X
i
−
X
ˉ
)
k
B_k=\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}(X_i-\bar X)^k
B k = n 1 i = 1 ∑ n ( X i − X ˉ ) k
X
(
1
)
⩽
X
(
2
)
⩽
…
⩽
X
(
n
)
X_{(1)}⩽ X_{(2)}⩽ …⩽ X_{(n)}
X ( 1 ) ⩽ X ( 2 ) ⩽ … ⩽ X ( n )
X
(
1
)
,
X
(
2
)
,
…
,
X
(
n
)
X_{(1)}, X_{(2)}, …, X_{(n)}
X ( 1 ) , X ( 2 ) , … , X ( n )
X
(
1
)
=
min
{
X
(
1
)
,
X
(
2
)
,
…
,
X
(
n
)
}
X_{(1)}=\min \{X_{(1)}, X_{(2)}, …, X_{(n)}\}
X ( 1 ) = min { X ( 1 ) , X ( 2 ) , … , X ( n ) }
X
(
n
)
=
max
{
X
(
1
)
,
X
(
2
)
,
…
,
X
(
n
)
}
X_{(n)}=\max \{X_{(1)}, X_{(2)}, …, X_{(n)}\}
X ( n ) = max { X ( 1 ) , X ( 2 ) , … , X ( n ) }
R
n
=
X
(
n
)
−
X
(
1
)
R_n=X_{(n)}-X_{(1)}
R n = X ( n ) − X ( 1 )
样本均值与样本方差的数字特征 :设
X
1
,
X
2
,
…
,
X
n
X_1,X_2,…,X_n
X 1 , X 2 , … , X n
X
X
X
E
(
X
)
=
μ
,
D
(
X
)
=
σ
2
E(X)=μ,D(X)=σ^2
E ( X ) = μ , D ( X ) = σ 2
E
(
X
ˉ
)
=
E
(
1
n
∑
i
=
1
n
X
i
)
=
1
n
∑
i
=
1
n
E
(
X
i
)
=
μ
E(\bar X)=E(\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}X_i)=\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}E(X_i)=μ
E ( X ˉ ) = E ( n 1 i = 1 ∑ n X i ) = n 1 i = 1 ∑ n E ( X i ) = μ
D
(
X
ˉ
)
=
D
(
1
n
∑
i
=
1
n
X
i
)
=
1
n
2
∑
i
=
1
n
D
(
X
i
)
=
σ
2
/
n
D(\bar X)=D(\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}X_i)=\dfrac{1}{n^2}\displaystyle\sum_{i=1}^{n}D(X_i)=σ^2/n
D ( X ˉ ) = D ( n 1 i = 1 ∑ n X i ) = n 2 1 i = 1 ∑ n D ( X i ) = σ 2 / n
E
(
S
2
)
=
σ
2
E(S^2)=σ^2
E ( S 2 ) = σ 2
X
∼
N
(
μ
,
σ
2
)
X∼ N(μ,σ^2)
X ∼ N ( μ , σ 2 )
D
(
S
2
)
=
2
σ
4
n
−
1
D(S^2)=\dfrac{2σ^4}{n-1}
D ( S 2 ) = n − 1 2 σ 4
抽样分布 (sampling distribution):统计量的分布被称为抽样分布
X
X
X
X
X
X
X
ˉ
,
S
2
\bar X,S^2
X ˉ , S 2
χ
2
χ^2
χ 2
X
1
,
X
2
,
…
,
X
n
X_1,X_2,…,X_n
X 1 , X 2 , … , X n
N
(
0
,
1
)
N(0, 1)
N ( 0 , 1 )
χ
2
=
∑
i
=
1
n
X
i
2
χ^2=\displaystyle\sum_{i=1}^{n}X_i^2
χ 2 = i = 1 ∑ n X i 2
n
n
n
χ
2
χ^2
χ 2
χ
2
∼
χ
2
(
n
)
χ^2∼ χ^2(n)
χ 2 ∼ χ 2 ( n )
χ
2
χ^2
χ 2
f
n
(
x
)
=
{
1
2
Γ
(
n
/
2
)
(
x
2
)
n
/
2
−
1
e
−
x
/
2
,
x
>
0
0
,
x
⩽
0
f_n(x)=\begin{cases} \dfrac{1}{2Γ(n/2)}(\dfrac{x}{2})^{n/2-1}e^{-x/2},\quad x>0 \\ 0,\quad x⩽0 \end{cases}
f n ( x ) = ⎩ ⎨ ⎧ 2 Γ ( n / 2 ) 1 ( 2 x ) n / 2 − 1 e − x / 2 , x > 0 0 , x ⩽ 0
Γ
(
x
)
=
∫
0
+
∞
t
x
−
1
e
−
t
d
t
Γ(x)=\displaystyle\int_{0}^{+∞}t^{x-1}e^{-t}\mathrm{d}t
Γ ( x ) = ∫ 0 + ∞ t x − 1 e − t d t
Y
∼
χ
2
(
n
)
Y∼ χ^2(n)
Y ∼ χ 2 ( n )
E
(
Y
)
=
n
,
D
(
Y
)
=
2
n
E(Y)=n,D(Y)=2n
E ( Y ) = n , D ( Y ) = 2 n
Y
1
∼
χ
2
(
n
1
)
,
Y
2
∼
χ
2
(
n
2
)
Y_1∼ χ^2(n_1),Y_2∼ χ^2(n_2)
Y 1 ∼ χ 2 ( n 1 ) , Y 2 ∼ χ 2 ( n 2 )
Y
1
,
Y
2
Y_1,Y_2
Y 1 , Y 2
Y
1
+
Y
2
∼
χ
2
(
n
1
+
n
2
)
Y_1+Y_2∼ χ^2(n_1+n_2)
Y 1 + Y 2 ∼ χ 2 ( n 1 + n 2 )
Y
1
,
Y
2
,
⋯
,
Y
m
Y_1,Y_2,\cdots,Y_m
Y 1 , Y 2 , ⋯ , Y m
Y
i
∼
χ
2
(
n
i
)
Y_i∼ χ^2(n_i)
Y i ∼ χ 2 ( n i )
∑
i
=
1
m
Y
i
∼
χ
2
(
∑
i
=
1
m
n
i
)
\displaystyle\sum_{i=1}^{m}Y_i∼ χ^2(\sum_{i=1}^{m}n_i)
i = 1 ∑ m Y i ∼ χ 2 ( i = 1 ∑ m n i )
t 分布 (t-distribution):设
X
∼
N
(
0
,
1
)
,
Y
∼
χ
2
(
n
)
X∼ N(0,1),Y∼ χ^2(n)
X ∼ N ( 0 , 1 ) , Y ∼ χ 2 ( n )
T
=
X
Y
/
n
T=\dfrac{X}{\sqrt{Y/n}}
T = Y / n
X
T
∼
t
(
n
)
T∼ t(n)
T ∼ t ( n )
t
(
n
)
t(n)
t ( n )
f
n
(
x
)
=
Γ
(
n
+
1
2
)
n
π
Γ
(
n
2
)
(
1
+
x
2
n
)
−
n
+
1
2
,
x
∈
R
f_n(x)=\dfrac{Γ(\frac{n+1}{2})}{\sqrt{nπ}Γ(\frac{n}{2})}(1+\dfrac{x^2}{n})^{-\frac{n+1}{2}},\quad x\in\R
f n ( x ) = n π
Γ ( 2 n ) Γ ( 2 n + 1 ) ( 1 + n x 2 ) − 2 n + 1 , x ∈ R
n
=
1
n=1
n = 1
f
(
x
)
=
1
π
(
1
+
x
2
)
,
x
∈
R
f(x)=\dfrac{1}{π(1+x^2)},x\in\R
f ( x ) = π ( 1 + x 2 ) 1 , x ∈ R
lim
n
→
∞
f
n
(
x
)
=
1
2
π
e
−
x
2
/
2
,
x
∈
R
\lim\limits_{n\to∞}f_n(x)=\dfrac{1}{\sqrt{2π}}e^{-x^2/2},x\in\R
n → ∞ lim f n ( x ) = 2 π
1 e − x 2 / 2 , x ∈ R
F 分布 (F-distribution):设
X
∼
χ
2
(
n
1
)
,
Y
∼
χ
2
(
n
2
)
X∼ χ^2(n_1),Y∼ χ^2(n_2)
X ∼ χ 2 ( n 1 ) , Y ∼ χ 2 ( n 2 )
F
=
X
/
n
1
Y
/
n
2
F=\dfrac{X/n_1}{Y/n_2}
F = Y / n 2 X / n 1
(
n
1
,
n
2
)
(n_1,n_2)
( n 1 , n 2 )
F
∼
F
(
n
1
,
n
2
)
F∼ F(n_1,n_2)
F ∼ F ( n 1 , n 2 )
n
1
n_1
n 1
n
2
n_2
n 2
F
(
n
1
,
n
2
)
F(n_1,n_2)
F ( n 1 , n 2 )
f
(
x
)
=
{
(
n
1
/
n
2
)
n
1
2
B
(
n
1
2
,
n
2
2
)
x
n
1
2
−
1
(
1
+
n
1
n
2
x
)
−
n
1
+
n
2
2
,
x
>
0
0
,
x
⩽
0
f(x)=\begin{cases} \dfrac{(n_1/n_2)^{\frac{n_1}{2}}}{B(\frac{n_1}{2},\frac{n_2}{2})}x^{\frac{n_1}{2}-1}(1+\frac{n_1}{n_2}x)^{-\frac{n_1+n_2}{2}},x>0 \\ 0,\quad x⩽ 0 \end{cases}
f ( x ) = ⎩ ⎪ ⎨ ⎪ ⎧ B ( 2 n 1 , 2 n 2 ) ( n 1 / n 2 ) 2 n 1 x 2 n 1 − 1 ( 1 + n 2 n 1 x ) − 2 n 1 + n 2 , x > 0 0 , x ⩽ 0
B
(
a
,
b
)
=
∫
0
1
x
a
−
1
(
1
−
x
)
b
−
1
d
x
=
Γ
(
a
)
Γ
(
b
)
Γ
(
a
+
b
)
B(a,b)=\displaystyle\int_0^1x^{a-1}(1-x)^{b-1}\mathrm{d}x=\dfrac{Γ(a)Γ(b)}{Γ(a+b)}
B ( a , b ) = ∫ 0 1 x a − 1 ( 1 − x ) b − 1 d x = Γ ( a + b ) Γ ( a ) Γ ( b )
F
∼
F
(
n
1
,
n
2
)
F∼ F(n_1,n_2)
F ∼ F ( n 1 , n 2 )
1
F
∼
F
(
n
2
,
n
1
)
\dfrac{1}{F}∼ F(n_2,n_1)
F 1 ∼ F ( n 2 , n 1 )
正态总体的抽样分布
X
1
,
X
2
,
…
,
X
n
X_1,X_2,…,X_n
X 1 , X 2 , … , X n
N
(
μ
,
σ
2
)
N(μ,σ^2)
N ( μ , σ 2 )
X
ˉ
=
1
n
∑
i
=
1
n
X
i
\bar X=\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}X_i
X ˉ = n 1 i = 1 ∑ n X i
S
2
=
1
n
−
1
∑
i
=
1
n
(
X
i
−
X
ˉ
)
2
S^2=\dfrac{1}{n-1}\displaystyle\sum_{i=1}^{n}(X_i-\bar X)^2
S 2 = n − 1 1 i = 1 ∑ n ( X i − X ˉ ) 2
X
ˉ
∼
N
(
μ
,
σ
2
/
n
)
\bar X∼ N(μ,σ^2/n)
X ˉ ∼ N ( μ , σ 2 / n )
(
n
−
1
)
S
2
σ
2
∼
χ
2
(
n
−
1
)
\dfrac{(n-1)S^2}{σ^2}∼χ^2(n-1)
σ 2 ( n − 1 ) S 2 ∼ χ 2 ( n − 1 )
X
ˉ
\bar X
X ˉ
S
2
S^2
S 2
X
ˉ
−
μ
S
/
n
∼
t
(
n
−
1
)
\dfrac{\bar X-μ}{S/\sqrt{n}}∼ t(n-1)
S / n
X ˉ − μ ∼ t ( n − 1 )
设
X
1
,
X
2
,
…
,
X
n
1
X_1,X_2,…,X_{n_1}
X 1 , X 2 , … , X n 1
Y
1
,
Y
2
,
…
,
Y
n
2
Y_1,Y_2,…,Y_{n_2}
Y 1 , Y 2 , … , Y n 2
N
(
μ
1
,
σ
1
2
)
N(μ_1,σ_1^2)
N ( μ 1 , σ 1 2 )
N
(
μ
2
,
σ
2
2
)
N(μ_2,σ_2^2)
N ( μ 2 , σ 2 2 )
X
ˉ
,
Y
ˉ
\bar X,\bar Y
X ˉ , Y ˉ
S
1
2
,
S
2
2
S_1^2,S_2^2
S 1 2 , S 2 2
S
1
2
/
S
2
2
σ
1
2
/
σ
2
2
∼
F
(
n
1
−
1
,
n
2
−
1
)
\dfrac{S_1^2/S_2^2}{σ_1^2/σ_2^2}∼ F(n_1-1,n_2-1)
σ 1 2 / σ 2 2 S 1 2 / S 2 2 ∼ F ( n 1 − 1 , n 2 − 1 )
(2)
(
X
ˉ
−
Y
ˉ
)
−
(
μ
1
−
μ
2
)
σ
1
2
n
1
+
σ
2
2
n
2
∼
N
(
0
,
1
)
\dfrac{(\bar X-\bar Y)-(μ_1-μ_2)}{\sqrt{\dfrac{σ_1^2}{n_1}+\dfrac{σ_2^2}{n_2}}}∼ N(0,1)
n 1 σ 1 2 + n 2 σ 2 2
( X ˉ − Y ˉ ) − ( μ 1 − μ 2 ) ∼ N ( 0 , 1 )
σ
1
2
=
σ
2
2
=
σ
2
σ_1^2=σ_2^2=σ^2
σ 1 2 = σ 2 2 = σ 2
(
X
ˉ
−
Y
ˉ
)
−
(
μ
1
−
μ
2
)
S
w
1
n
1
+
1
n
2
∼
t
(
n
1
+
n
2
−
2
)
\dfrac{(\bar X-\bar Y)-(μ_1-μ_2)}{S_w\sqrt{\dfrac{1}{n_1}+\dfrac{1}{n_2}}}∼ t(n_1+n_2-2)
S w n 1 1 + n 2 1
( X ˉ − Y ˉ ) − ( μ 1 − μ 2 ) ∼ t ( n 1 + n 2 − 2 )
S
w
2
=
(
n
1
−
1
)
S
1
2
+
(
n
2
−
1
)
S
2
2
n
1
+
n
2
−
2
,
S
w
=
S
w
2
S_w^2=\dfrac{(n_1-1)S_1^2+(n_2-1)S_2^2}{n_1+n_2-2},S_w=\sqrt{S_w^2}
S w 2 = n 1 + n 2 − 2 ( n 1 − 1 ) S 1 2 + ( n 2 − 1 ) S 2 2 , S w = S w 2
参数通常是刻画总体某些概率特征的数量。例如正态分布
N
(
μ
,
σ
2
)
N(μ,σ^2)
N ( μ , σ 2 )
μ
μ
μ
假设总体
X
∼
F
(
x
;
θ
1
,
θ
2
,
…
,
θ
m
)
X ∼ F(x; θ_1, θ_2,…, θ_m)
X ∼ F ( x ; θ 1 , θ 2 , … , θ m )
F
F
F
θ
1
,
θ
2
,
…
,
θ
m
θ_1, θ_2,…, θ_m
θ 1 , θ 2 , … , θ m
θ
=
(
θ
1
,
θ
2
,
…
,
θ
m
)
θ = (θ_1, θ_2,…, θ_m)
θ = ( θ 1 , θ 2 , … , θ m )
X
∼
F
(
x
;
θ
)
X∼ F(x; θ)
X ∼ F ( x ; θ )
θ
θ
θ 参数空间 (parameter space),记为
Θ
Θ
Θ
X
1
,
X
2
,
…
,
X
n
X_1,X_2,…,X_n
X 1 , X 2 , … , X n
X
∼
F
(
x
;
θ
1
,
θ
2
,
…
,
θ
m
)
X ∼ F(x; θ_1, θ_2,…, θ_m)
X ∼ F ( x ; θ 1 , θ 2 , … , θ m )
θ
1
,
θ
2
,
…
,
θ
m
θ_1, θ_2,…, θ_m
θ 1 , θ 2 , … , θ m
随
机
变
量
{
θ
^
1
(
X
1
,
X
2
,
…
,
X
n
)
θ
^
2
(
X
1
,
X
2
,
…
,
X
n
)
⋮
θ
^
m
(
X
1
,
X
2
,
…
,
X
n
)
随机变量\begin{cases} \hat θ_1(X_1,X_2,…,X_n) \\ \hat θ_2(X_1,X_2,…,X_n) \\ \quad\vdots\\ \hat θ_m(X_1,X_2,…,X_n) \end{cases}
随 机 变 量 ⎩ ⎪ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎪ ⎧ θ ^ 1 ( X 1 , X 2 , … , X n ) θ ^ 2 ( X 1 , X 2 , … , X n ) ⋮ θ ^ m ( X 1 , X 2 , … , X n )
x
1
,
x
2
,
…
,
x
n
x_1,x_2,…,x_n
x 1 , x 2 , … , x n
数
值
{
θ
^
1
(
x
1
,
x
2
,
…
,
x
n
)
θ
^
2
(
x
1
,
x
2
,
…
,
x
n
)
⋮
θ
^
m
(
x
1
,
x
2
,
…
,
x
n
)
数值\begin{cases} \hat θ_1(x_1,x_2,…,x_n) \\ \hat θ_2(x_1,x_2,…,x_n) \\ \quad\vdots\\ \hat θ_m(x_1,x_2,…,x_n) \end{cases}
数 值 ⎩ ⎪ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎪ ⎧ θ ^ 1 ( x 1 , x 2 , … , x n ) θ ^ 2 ( x 1 , x 2 , … , x n ) ⋮ θ ^ m ( x 1 , x 2 , … , x n )
θ
^
k
(
X
1
,
X
2
,
…
,
X
n
)
\hat θ_k(X_1,X_2,…,X_n)
θ ^ k ( X 1 , X 2 , … , X n )
θ
k
θ_k
θ k 估计量 (estimate),
θ
^
1
(
x
1
,
x
2
,
…
,
x
n
)
\hat θ_1(x_1,x_2,…,x_n)
θ ^ 1 ( x 1 , x 2 , … , x n )
θ
k
θ_k
θ k 估计值 (estimator)。
常用的估计方法:矩估计法,极大似然估计法,最小二乘估计法,贝叶斯方法
矩估计法 (Moment Estimation)
A
k
=
1
n
∑
i
=
1
n
X
i
k
→
P
μ
k
(
θ
1
,
θ
2
,
…
,
θ
m
)
(
n
→
∞
)
A_k=\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}X_i^k\xrightarrow{P}μ_k(θ_1, θ_2,…, θ_m)\quad (n\to∞)
A k = n 1 i = 1 ∑ n X i k P
μ k ( θ 1 , θ 2 , … , θ m ) ( n → ∞ )
A
k
≈
μ
k
(
θ
1
,
θ
2
,
…
,
θ
m
)
A_k\approx μ_k(θ_1, θ_2,…, θ_m)
A k ≈ μ k ( θ 1 , θ 2 , … , θ m )
A
k
=
μ
k
(
θ
1
,
θ
2
,
…
,
θ
m
)
,
k
=
1
,
2
,
⋯
,
m
A_k=μ_k(θ_1, θ_2,…, θ_m),k=1,2,\cdots,m
A k = μ k ( θ 1 , θ 2 , … , θ m ) , k = 1 , 2 , ⋯ , m
θ
^
k
(
X
1
,
X
2
,
…
,
X
n
)
\hat θ_k(X_1,X_2,…,X_n)
θ ^ k ( X 1 , X 2 , … , X n )
θ
k
θ_k
θ k
总体均值和方差的矩估计量表达式不因不同的总体分布而异,设总体
X
X
X
μ
μ
μ
σ
2
σ^2
σ 2
μ
^
=
X
ˉ
,
σ
^
2
=
1
n
∑
i
=
1
n
(
X
i
−
X
ˉ
)
2
≜
S
~
2
\hat μ=\bar X,\hatσ^2=\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}(X_i-\bar X)^2 \triangleq \tilde S^2
μ ^ = X ˉ , σ ^ 2 = n 1 i = 1 ∑ n ( X i − X ˉ ) 2 ≜ S ~ 2
X
∼
U
(
a
,
b
)
⟹
a
^
=
X
ˉ
−
3
S
~
,
b
^
=
X
ˉ
+
3
S
~
X∼ U(a,b)\implies\hat a=\bar X-\sqrt{3}\tilde S,\hat b=\bar X+\sqrt{3}\tilde S
X ∼ U ( a , b ) ⟹ a ^ = X ˉ − 3
S ~ , b ^ = X ˉ + 3
S ~
极大似然估计法 (Maximum Likelihood Estimate,MLE)
X
X
X
P
{
X
=
x
}
=
p
(
x
;
θ
)
,
θ
∈
Θ
P\{X=x\}=p(x;θ),θ\in Θ
P { X = x } = p ( x ; θ ) , θ ∈ Θ
X
1
,
X
2
,
…
,
X
n
X_1,X_2,…,X_n
X 1 , X 2 , … , X n
x
1
,
x
2
,
…
,
x
n
x_1,x_2,…,x_n
x 1 , x 2 , … , x n
{
X
1
=
x
1
,
X
2
=
x
2
,
⋯
,
X
n
=
x
n
}
\{X_1=x_1,X_2=x_2,\cdots,X_n=x_n\}
{ X 1 = x 1 , X 2 = x 2 , ⋯ , X n = x n }
L
(
θ
)
=
L
(
x
1
,
x
2
,
…
,
x
n
;
θ
)
=
∏
i
=
1
n
p
(
x
i
;
θ
)
,
θ
∈
Θ
L(θ)=L(x_1,x_2,…,x_n;θ)=\displaystyle\prod_{i=1}^{n} p(x_i;θ),θ\in Θ
L ( θ ) = L ( x 1 , x 2 , … , x n ; θ ) = i = 1 ∏ n p ( x i ; θ ) , θ ∈ Θ
L
(
θ
)
L(θ)
L ( θ ) 似然函数 (likelihood function),方程
L
(
θ
^
)
=
max
θ
∈
Θ
L
(
θ
)
,
θ
^
=
θ
^
(
x
1
,
x
2
,
…
,
x
n
)
L(\hat θ)=\displaystyle\max_{θ\in Θ} L(θ),\hat θ=\hat θ(x_1,x_2,…,x_n)
L ( θ ^ ) = θ ∈ Θ max L ( θ ) , θ ^ = θ ^ ( x 1 , x 2 , … , x n )
θ
^
\hat θ
θ ^
θ
^
=
θ
^
(
X
1
,
X
2
,
…
,
X
n
)
\hat θ=\hat θ(X_1,X_2,…,X_n)
θ ^ = θ ^ ( X 1 , X 2 , … , X n ) 极大似然估计量 (MLE)
X
X
X
f
(
x
;
θ
)
,
θ
∈
Θ
f(x;θ),θ\in Θ
f ( x ; θ ) , θ ∈ Θ
L
(
θ
)
=
L
(
x
1
,
x
2
,
…
,
x
n
;
θ
)
=
∏
i
=
1
n
f
(
x
i
;
θ
)
,
θ
∈
Θ
L(θ)=L(x_1,x_2,…,x_n;θ)=\displaystyle\prod_{i=1}^{n} f(x_i;θ),θ\in Θ
L ( θ ) = L ( x 1 , x 2 , … , x n ; θ ) = i = 1 ∏ n f ( x i ; θ ) , θ ∈ Θ
在许多情况下,
p
(
x
;
θ
)
,
f
(
x
;
θ
)
p(x;θ),f(x;θ)
p ( x ; θ ) , f ( x ; θ )
θ
^
\hat θ
θ ^
d
d
θ
L
(
θ
)
=
0
\dfrac{\mathrm{d}}{\mathrm{d}θ}L(θ)=0
d θ d L ( θ ) = 0
L
(
θ
)
L(θ)
L ( θ )
ln
L
(
θ
)
\ln L(θ)
ln L ( θ )
θ
^
\hat θ
θ ^
d
d
θ
ln
L
(
θ
)
=
0
\dfrac{\mathrm{d}}{\mathrm{d}θ}\ln L(θ)=0
d θ d ln L ( θ ) = 0 对数似然方程 。
θ
1
,
θ
2
,
…
,
θ
m
θ_1, θ_2,…, θ_m
θ 1 , θ 2 , … , θ m
∂
∂
θ
i
L
=
0
,
i
=
1
,
2
,
⋯
,
m
\dfrac{∂}{∂θ_i}L=0,i=1,2,\cdots,m
∂ θ i ∂ L = 0 , i = 1 , 2 , ⋯ , m
∂
∂
θ
i
ln
L
=
0
,
i
=
1
,
2
,
⋯
,
m
\dfrac{∂}{∂θ_i}\ln L=0,i=1,2,\cdots,m
∂ θ i ∂ ln L = 0 , i = 1 , 2 , ⋯ , m 对数似然方程组 。
X
∼
N
(
μ
,
σ
2
)
⟹
μ
^
=
X
ˉ
,
σ
^
2
=
1
n
∑
i
=
1
n
(
X
i
−
X
ˉ
)
2
≜
S
~
2
X∼ N(μ,σ^2)\implies\hat μ=\bar X,\hatσ^2=\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}(X_i-\bar X)^2 \triangleq \tilde S^2
X ∼ N ( μ , σ 2 ) ⟹ μ ^ = X ˉ , σ ^ 2 = n 1 i = 1 ∑ n ( X i − X ˉ ) 2 ≜ S ~ 2
X
∼
U
(
a
,
b
)
⟹
a
^
=
min
{
X
1
,
X
2
,
⋯
,
X
n
}
=
X
(
1
)
,
b
^
=
max
{
X
1
,
X
2
,
⋯
,
X
n
}
=
X
(
n
)
X∼ U(a,b)\implies\hat a=\min\{X_1,X_2,\cdots,X_n\}=X_{(1)},\hat b=\max\{X_1,X_2,\cdots,X_n\}=X_{(n)}
X ∼ U ( a , b ) ⟹ a ^ = min { X 1 , X 2 , ⋯ , X n } = X ( 1 ) , b ^ = max { X 1 , X 2 , ⋯ , X n } = X ( n )
极大似然估计的不变性 :设
θ
^
\hat θ
θ ^
θ
θ
θ
u
=
u
(
θ
)
u=u(θ)
u = u ( θ )
θ
=
θ
(
u
)
θ=θ(u)
θ = θ ( u )
u
(
θ
^
)
u(\hat θ)
u ( θ ^ )
u
u
u
对同一个参数,不同方法得到的估计量可能不同。用什么标准来评价一个估计量的好坏?无偏性 (unbiased):设
X
1
,
X
2
,
…
,
X
n
X_1,X_2,…,X_n
X 1 , X 2 , … , X n
X
∼
F
(
x
;
θ
)
(
θ
∈
Θ
)
X∼ F(x;θ) \quad (θ\inΘ)
X ∼ F ( x ; θ ) ( θ ∈ Θ )
θ
θ
θ
θ
^
=
θ
^
(
X
1
,
X
2
,
…
,
X
n
)
\hat θ=\hat θ(X_1,X_2,…,X_n)
θ ^ = θ ^ ( X 1 , X 2 , … , X n )
E
(
θ
^
)
=
θ
E(\hat θ)=θ
E ( θ ^ ) = θ
θ
^
\hat θ
θ ^
θ
θ
θ
E
(
θ
^
)
≠
θ
E(\hat θ)\neq θ
E ( θ ^ ) = θ
∣
E
(
θ
^
)
−
θ
∣
|E(\hat θ)-θ|
∣ E ( θ ^ ) − θ ∣
θ
θ
θ
lim
n
→
∞
E
(
θ
^
)
=
θ
\lim\limits_{n\to∞}E(\hat θ)= θ
n → ∞ lim E ( θ ^ ) = θ
θ
^
\hat θ
θ ^
θ
θ
θ
估计量
θ
^
(
X
1
,
X
2
,
…
,
X
n
)
\hat θ(X_1,X_2,…,X_n)
θ ^ ( X 1 , X 2 , … , X n )
设
X
1
,
X
2
,
…
,
X
n
X_1,X_2,…,X_n
X 1 , X 2 , … , X n
X
X
X
μ
k
μ_k
μ k
μ
,
σ
2
μ,σ^2
μ , σ 2
E
(
A
k
)
=
μ
k
E(A_k)=μ_k
E ( A k ) = μ k
E
(
X
ˉ
)
=
μ
,
E
(
S
2
)
=
σ
2
E(\bar X)=μ,E(S^2)=σ^2
E ( X ˉ ) = μ , E ( S 2 ) = σ 2
E
(
S
~
2
)
=
n
−
1
n
E
(
S
2
)
=
n
−
1
n
σ
2
E(\tilde S^2)=\dfrac{n-1}{n}E(S^2)=\dfrac{n-1}{n}σ^2
E ( S ~ 2 ) = n n − 1 E ( S 2 ) = n n − 1 σ 2
lim
n
→
∞
E
(
S
~
2
)
=
σ
2
\lim\limits_{n\to∞}E(\tilde S^2)=σ^2
n → ∞ lim E ( S ~ 2 ) = σ 2
S
~
2
\tilde S^2
S ~ 2
纠偏方法:若
θ
^
\hat θ
θ ^
E
(
θ
^
)
=
a
θ
+
b
(
a
≠
0
,
θ
∈
Θ
)
E(\hat θ)=aθ+b\quad (a\neq 0,θ\inΘ)
E ( θ ^ ) = a θ + b ( a = 0 , θ ∈ Θ )
θ
−
b
a
\dfrac{θ-b}{a}
a θ − b
(2) 有效性 (effective):设
θ
^
1
,
θ
^
2
\hat θ_1,\hat θ_2
θ ^ 1 , θ ^ 2
∀
θ
∈
Θ
,
D
(
θ
^
1
)
⩽
D
(
θ
^
2
)
∀ θ\inΘ,D(\hat θ_1) ⩽ D(\hat θ_2)
∀ θ ∈ Θ , D ( θ ^ 1 ) ⩽ D ( θ ^ 2 )
θ
∈
Θ
θ\inΘ
θ ∈ Θ
θ
^
1
\hat θ_1
θ ^ 1
θ
^
1
\hat θ_1
θ ^ 1
均方误差准则 :定义
E
(
θ
^
−
θ
)
2
E(\hat θ-θ)^2
E ( θ ^ − θ ) 2
θ
^
\hat θ
θ ^
M
s
e
(
θ
^
)
Mse(\hat θ)
M s e ( θ ^ )
θ
^
\hat θ
θ ^
M
s
e
(
θ
^
)
=
D
(
θ
^
)
Mse(\hat θ)=D(\hat θ)
M s e ( θ ^ ) = D ( θ ^ )
θ
^
1
,
θ
^
2
\hat θ_1,\hat θ_2
θ ^ 1 , θ ^ 2
∀
θ
∈
Θ
,
M
s
e
(
θ
^
1
)
⩽
M
s
e
(
θ
^
2
)
∀ θ\inΘ,Mse(\hat θ_1) ⩽ Mse(\hat θ_2)
∀ θ ∈ Θ , M s e ( θ ^ 1 ) ⩽ M s e ( θ ^ 2 )
θ
∈
Θ
θ\inΘ
θ ∈ Θ
θ
^
1
\hat θ_1
θ ^ 1
θ
^
1
\hat θ_1
θ ^ 1
(3) 相合性 (consistence):设
θ
^
(
X
1
,
X
2
,
…
,
X
n
)
\hat θ(X_1,X_2,…,X_n)
θ ^ ( X 1 , X 2 , … , X n )
∀
θ
∈
Θ
,
∀
ϵ
>
0
,
lim
n
→
∞
P
{
∣
θ
^
−
θ
∣
<
ϵ
}
=
1
∀ θ\inΘ,∀ϵ>0,\lim\limits_{n\to∞}P\{|\hat θ-θ|<ϵ\}=1
∀ θ ∈ Θ , ∀ ϵ > 0 , n → ∞ lim P { ∣ θ ^ − θ ∣ < ϵ } = 1
θ
^
n
→
P
θ
(
n
→
∞
)
\hat θ_n\xrightarrow{P}θ\quad (n\to∞)
θ ^ n P
θ ( n → ∞ )
θ
^
\hat θ
θ ^
相合性的相关结论:
A
k
A_k
A k
μ
k
μ_k
μ k
S
2
,
S
~
2
S^2,\tilde S^2
S 2 , S ~ 2
应用
X
∼
N
(
μ
,
σ
2
)
⟹
M
s
e
(
S
2
)
=
D
(
S
2
)
=
2
σ
4
n
−
1
,
M
s
e
(
S
~
2
)
=
2
n
−
1
n
2
σ
4
X∼ N(μ,σ^2)\implies Mse(S^2)=D(S^2)=\dfrac{2σ^4}{n-1},Mse(\tilde S^2)=\dfrac{2n-1}{n^2}σ^4
X ∼ N ( μ , σ 2 ) ⟹ M s e ( S 2 ) = D ( S 2 ) = n − 1 2 σ 4 , M s e ( S ~ 2 ) = n 2 2 n − 1 σ 4
n
>
1
n>1
n > 1
M
s
e
(
S
2
)
>
M
s
e
(
S
~
2
)
Mse(S^2)>Mse(\tilde S^2)
M s e ( S 2 ) > M s e ( S ~ 2 )
S
~
2
\tilde S^2
S ~ 2
S
2
S^2
S 2
(2) 设
X
1
,
X
2
,
…
,
X
n
X_1,X_2,…,X_n
X 1 , X 2 , … , X n
X
∼
E
x
p
(
θ
)
X∼ Exp(θ)
X ∼ E x p ( θ )
X
ˉ
\bar X
X ˉ
n
Z
,
Z
=
min
{
X
1
,
X
2
,
…
,
X
n
}
nZ,Z=\min\{X_1,X_2,…,X_n\}
n Z , Z = min { X 1 , X 2 , … , X n }
D
(
X
ˉ
)
=
θ
2
/
n
,
D
(
n
Z
)
=
θ
2
D(\bar X)=θ^2/n,D(nZ)=θ^2
D ( X ˉ ) = θ 2 / n , D ( n Z ) = θ 2
n
>
1
n>1
n > 1
D
(
X
ˉ
)
<
D
(
n
Z
)
D(\bar X)<D(nZ)
D ( X ˉ ) < D ( n Z )
X
ˉ
\bar X
X ˉ
n
Z
nZ
n Z
对于一个未知量,根据具体样本观测值,点估计提供一个明确的数值。还希望根据所给的样本确定一个随机区间, 使其包含参数真值的概率达到指定的要求。
置信区间 (Confidence Intervals):设总体
X
∼
F
(
x
;
θ
)
,
θ
∈
Θ
X∼ F(x;θ),θ\inΘ
X ∼ F ( x ; θ ) , θ ∈ Θ
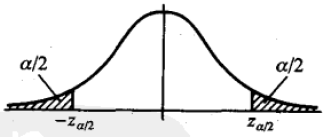
α
(
0
<
α
<
1
)
α(0<α<1)
α ( 0 < α < 1 )
X
X
X
θ
^
L
=
θ
^
L
(
X
1
,
X
2
,
…
,
X
n
)
,
θ
^
U
=
θ
^
U
(
X
1
,
X
2
,
…
,
X
n
)
(
θ
^
L
<
θ
^
U
)
\hat θ_L=\hat θ_L(X_1,X_2,…,X_n),\hat θ_U=\hat θ_U(X_1,X_2,…,X_n)(\hatθ_L<\hatθ_U)
θ ^ L = θ ^ L ( X 1 , X 2 , … , X n ) , θ ^ U = θ ^ U ( X 1 , X 2 , … , X n ) ( θ ^ L < θ ^ U )
∀
θ
∈
Θ
∀ θ\inΘ
∀ θ ∈ Θ
P
{
θ
^
L
<
θ
<
θ
^
U
}
⩾
1
−
α
P\{\hatθ_L<θ<\hatθ_U\}⩾ 1-α
P { θ ^ L < θ < θ ^ U } ⩾ 1 − α
(
θ
^
L
,
θ
^
U
)
(\hatθ_L,\hatθ_U)
( θ ^ L , θ ^ U )
1
−
α
1-α
1 − α 置信区间 (confidence interval)。
θ
^
L
,
θ
^
U
\hatθ_L,\hatθ_U
θ ^ L , θ ^ U
1
−
α
1-α
1 − α 置信度 或置信水平 (confidence level)。
(
θ
^
L
,
θ
^
U
)
(\hatθ_L,\hatθ_U)
( θ ^ L , θ ^ U )
1
−
α
1-α
1 − α
(
θ
^
L
,
θ
^
U
)
(\hatθ_L,\hatθ_U)
( θ ^ L , θ ^ U )
E
(
θ
^
U
−
θ
^
L
)
E(\hatθ_U-\hatθ_L)
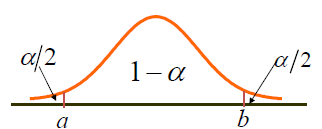
E ( θ ^ U − θ ^ L ) 精确度 (accuracy)(长度最短,精度最高),精确度的一半为误差限 (error limit)。在给定的样本容量下,置信水平和精确度是相互制约的。
1
−
α
1-α
1 − α
求解置信区间的一般方法
G
=
G
(
X
1
,
X
2
,
…
,
X
n
;
θ
)
G=G(X_1,X_2,…,X_n;θ)
G = G ( X 1 , X 2 , … , X n ; θ ) 枢轴量 (pivot)。
1
−
α
1-α
1 − α
a
,
b
a,b
a , b
P
{
a
<
G
<
b
}
⩾
1
−
α
P\{a<G<b\}⩾ 1-α
P { a < G < b } ⩾ 1 − α
a
<
G
<
b
a<G<b
a < G < b
θ
^
L
<
θ
<
θ
^
U
\hatθ_L<θ<\hatθ_U
θ ^ L < θ < θ ^ U
(
θ
^
L
,
θ
^
U
)
(\hatθ_L,\hatθ_U)
( θ ^ L , θ ^ U )
1
−
α
1-α
1 − α 分位点 (percentile point):设连续型随机变量
X
X
X
f
(
x
)
f(x)
f ( x )
α
(
0
<
α
<
1
)
α (0<α<1)
α ( 0 < α < 1 )
P
{
X
>
x
α
}
=
∫
x
α
∞
f
(
x
)
d
x
=
α
P\{X>x_α\}=\displaystyle\int_{x_α}^{∞}f(x)\mathrm{d}x=α
P { X > x α } = ∫ x α ∞ f ( x ) d x = α
x
α
x_α
x α
N
(
0
,
1
)
N(0,1)
N ( 0 , 1 )
z
α
,
z
α
=
−
z
1
−
α
z_α,z_α=-z_{1-α}
z α , z α = − z 1 − α
χ
2
(
n
)
χ^2(n)
χ 2 ( n )
χ
α
2
(
n
)
χ_α^2(n)
χ α 2 ( n )
t
(
n
)
t(n)
t ( n )
t
α
(
n
)
,
t
α
(
n
)
=
−
t
1
−
α
(
n
)
t_α(n),t_α(n)=-t_{1-α}(n)
t α ( n ) , t α ( n ) = − t 1 − α ( n )
F
(
n
1
,
n
2
)
F(n_1,n_2)
F ( n 1 , n 2 )
F
α
(
n
1
,
n
2
)
F_α(n_1,n_2)
F α ( n 1 , n 2 )
单侧置信区间 (one-sided confidence interval)
P
{
θ
^
L
<
θ
}
⩾
1
−
α
P\{\hatθ_L<θ\}⩾ 1-α
P { θ ^ L < θ } ⩾ 1 − α
θ
^
L
\hatθ_L
θ ^ L
1
−
α
1-α
1 − α 单侧置信下限 (one-side confidence lower limit)。
P
{
θ
<
θ
^
U
}
⩾
1
−
α
P\{θ<\hatθ_U\}⩾ 1-α
P { θ < θ ^ U } ⩾ 1 − α
θ
^
U
\hatθ_U
θ ^ U
1
−
α
1-α
1 − α 单侧置信上限 (two-side confidence lower limit)。
正态总体参数的区间估计示例
X
∼
N
(
μ
,
σ
2
)
,
X
1
,
X
2
,
…
,
X
n
X∼ N(μ,σ^2),X_1,X_2,…,X_n
X ∼ N ( μ , σ 2 ) , X 1 , X 2 , … , X n
X
ˉ
,
S
2
\bar X,S^2
X ˉ , S 2
1
−
α
1-α
1 − α
σ
2
σ^2
σ 2
X
ˉ
\bar X
X ˉ
G
=
X
ˉ
−
μ
σ
/
n
∼
N
(
0
,
1
)
G=\dfrac{\bar X-μ}{σ/\sqrt{n}}∼ N(0,1)
G = σ / n
X ˉ − μ ∼ N ( 0 , 1 )
a
,
b
a,b
a , b
P
{
a
<
G
<
b
}
⩾
1
−
α
P\{a<G<b\}⩾ 1-α
P { a < G < b } ⩾ 1 − α
P
{
X
ˉ
−
σ
n
b
<
μ
<
X
ˉ
−
σ
n
a
}
⩾
1
−
α
P\{\bar X-\dfrac{σ}{\sqrt{n}}b<μ<\bar X-\dfrac{σ}{\sqrt{n}}a\}⩾ 1-α
P { X ˉ − n
σ b < μ < X ˉ − n
σ a } ⩾ 1 − α
(
b
−
a
)
σ
/
n
(b-a)σ/\sqrt{n}
( b − a ) σ / n
a
=
−
b
=
−
z
α
/
2
a=-b=-z_{α/2}
a = − b = − z α / 2
L
=
z
α
/
2
σ
/
n
L=z_{α/2}σ/\sqrt{n}
L = z α / 2 σ / n
1
−
α
1-α
1 − α
z
α
/
2
z_{α/2}
z α / 2
L
L
L
(
X
ˉ
−
σ
n
z
α
/
2
,
X
ˉ
+
σ
n
z
α
/
2
)
(\bar X-\dfrac{σ}{\sqrt{n}}z_{α/2},\bar X+\dfrac{σ}{\sqrt{n}}z_{α/2})
( X ˉ − n
σ z α / 2 , X ˉ + n
σ z α / 2 )
X
ˉ
−
σ
n
z
α
\bar X-\dfrac{σ}{\sqrt{n}}z_{α}
X ˉ − n
σ z α
X
ˉ
+
σ
n
z
α
\bar X+\dfrac{σ}{\sqrt{n}}z_{α}
X ˉ + n
σ z α
σ
2
σ^2
σ 2
S
2
S^2
S 2
σ
2
σ^2
σ 2
G
=
X
ˉ
−
μ
S
/
n
∼
t
(
n
−
1
)
G=\dfrac{\bar X-μ}{S/\sqrt{n}}∼ t(n-1)
G = S / n
X ˉ − μ ∼ t ( n − 1 )
(
X
ˉ
−
S
n
t
α
/
2
(
n
−
1
)
,
X
ˉ
+
S
n
t
α
/
2
(
n
−
1
)
)
(\bar X-\dfrac{S}{\sqrt{n}}t_{α/2}(n-1),\bar X+\dfrac{S}{\sqrt{n}}t_{α/2}(n-1))
( X ˉ − n
S t α / 2 ( n − 1 ) , X ˉ + n
S t α / 2 ( n − 1 ) )
X
ˉ
−
σ
n
t
α
(
n
−
1
)
\bar X-\dfrac{σ}{\sqrt{n}}t_{α}(n-1)
X ˉ − n
σ t α ( n − 1 )
X
ˉ
+
σ
n
t
α
(
n
−
1
)
\bar X+\dfrac{σ}{\sqrt{n}}t_{α}(n-1)
X ˉ + n
σ t α ( n − 1 )
X
ˉ
−
μ
σ
/
n
∼
N
(
0
,
1
)
\dfrac{\bar X-μ}{σ/\sqrt{n}}∼ N(0,1)
σ / n
X ˉ − μ ∼ N ( 0 , 1 )
正态总体的均值、方差的置信区间和单侧置信限(置信水平为
1
−
α
1-α
1 − α
一个正态总体
待估参数
其他参数
枢轴量G的分布
置信区间
单侧置信上/下限
μ
μ
μ
σ
2
σ^2
σ 2
X
ˉ
−
μ
σ
/
n
∼
N
(
0
,
1
)
\dfrac{\bar X-μ}{σ/\sqrt{n}}∼ N(0,1)
σ / n
X ˉ − μ ∼ N ( 0 , 1 )
(
X
ˉ
±
σ
n
z
α
/
2
)
(\bar X±\dfrac{σ}{\sqrt{n}}z_{α/2})
( X ˉ ± n
σ z α / 2 )
X
ˉ
±
σ
n
z
α
/
2
\bar X±\dfrac{σ}{\sqrt{n}}z_{α/2}
X ˉ ± n
σ z α / 2
μ
μ
μ
σ
2
σ^2
σ 2
X
ˉ
−
μ
S
/
n
∼
t
(
n
−
1
)
\dfrac{\bar X-μ}{S/\sqrt{n}}∼ t(n-1)
S / n
X ˉ − μ ∼ t ( n − 1 )
(
X
ˉ
±
S
n
t
α
/
2
(
n
−
1
)
)
\left(\bar X± \dfrac{S}{\sqrt{n}}t_{α/2}(n-1)\right)
( X ˉ ± n
S t α / 2 ( n − 1 ) )
X
ˉ
±
σ
n
t
α
(
n
−
1
)
\bar X±\dfrac{σ}{\sqrt{n}}t_{α}(n-1)
X ˉ ± n
σ t α ( n − 1 )
σ
2
σ^2
σ 2
μ
μ
μ
(
n
−
1
)
S
2
σ
2
∼
χ
2
(
n
−
1
)
\dfrac{(n-1)S^2}{σ^2}∼χ^2(n-1)
σ 2 ( n − 1 ) S 2 ∼ χ 2 ( n − 1 )
(
(
n
−
1
)
S
2
χ
α
/
2
2
(
n
−
1
)
,
(
n
−
1
)
S
2
χ
1
−
α
/
2
2
(
n
−
1
)
)
\left(\dfrac{(n-1)S^2}{χ^2_{α/2}(n-1)},\dfrac{(n-1)S^2}{χ^2_{1-α/2}(n-1)}\right)
( χ α / 2 2 ( n − 1 ) ( n − 1 ) S 2 , χ 1 − α / 2 2 ( n − 1 ) ( n − 1 ) S 2 )
(
n
−
1
)
S
2
χ
α
/
2
2
(
n
−
1
)
\dfrac{(n-1)S^2}{χ^2_{α/2}(n-1)}
χ α / 2 2 ( n − 1 ) ( n − 1 ) S 2
(
n
−
1
)
S
2
χ
1
−
α
/
2
2
(
n
−
1
)
\dfrac{(n-1)S^2}{χ^2_{1-α/2}(n-1)}
χ 1 − α / 2 2 ( n − 1 ) ( n − 1 ) S 2
两个正态总体
待估参数
其他参数
枢轴量G的分布
置信区间
单侧置信上/下限
μ
1
−
μ
2
μ_1-μ_2
μ 1 − μ 2
σ
1
2
,
σ
2
2
σ^2_1,σ^2_2
σ 1 2 , σ 2 2
(
X
ˉ
−
Y
ˉ
)
−
(
μ
1
−
μ
2
)
σ
1
2
n
1
+
σ
2
2
n
2
∼
N
(
0
,
1
)
\dfrac{(\bar X-\bar Y)-(μ_1-μ_2)}{\sqrt{\dfrac{σ_1^2}{n_1}+\dfrac{σ_2^2}{n_2}}}∼ N(0,1)
n 1 σ 1 2 + n 2 σ 2 2
( X ˉ − Y ˉ ) − ( μ 1 − μ 2 ) ∼ N ( 0 , 1 )
(
(
X
ˉ
−
Y
ˉ
)
±
z
α
/
2
σ
1
2
n
1
+
σ
2
2
n
2
)
\left((\bar X-\bar Y)± z_{α/2}\sqrt{\dfrac{σ_1^2}{n_1}+\dfrac{σ_2^2}{n_2}}\right)
( ( X ˉ − Y ˉ ) ± z α / 2 n 1 σ 1 2 + n 2 σ 2 2
)
(
X
ˉ
−
Y
ˉ
)
±
z
α
/
2
σ
1
2
n
1
+
σ
2
2
n
2
(\bar X-\bar Y)± z_{α/2}\sqrt{\dfrac{σ_1^2}{n_1}+\dfrac{σ_2^2}{n_2}}
( X ˉ − Y ˉ ) ± z α / 2 n 1 σ 1 2 + n 2 σ 2 2
μ
1
−
μ
2
μ_1-μ_2
μ 1 − μ 2
σ
1
2
=
σ
2
2
=
σ
2
σ^2_1=σ^2_2=σ^2
σ 1 2 = σ 2 2 = σ 2
(
X
ˉ
−
Y
ˉ
)
−
(
μ
1
−
μ
2
)
S
w
1
n
1
+
1
n
2
∼
t
(
n
1
+
n
2
−
2
)
\dfrac{(\bar X-\bar Y)-(μ_1-μ_2)}{S_w\sqrt{\dfrac{1}{n_1}+\dfrac{1}{n_2}}}∼ t(n_1+n_2-2)
S w n 1 1 + n 2 1
( X ˉ − Y ˉ ) − ( μ 1 − μ 2 ) ∼ t ( n 1 + n 2 − 2 )
S
w
2
=
(
n
1
−
1
)
S
1
2
+
(
n
2
−
1
)
S
2
2
n
1
+
n
2
−
2
S_w^2=\dfrac{(n_1-1)S_1^2+(n_2-1)S_2^2}{n_1+n_2-2}
S w 2 = n 1 + n 2 − 2 ( n 1 − 1 ) S 1 2 + ( n 2 − 1 ) S 2 2
(
(
X
ˉ
−
Y
ˉ
)
±
t
α
/
2
t
(
n
1
+
n
2
−
2
)
S
w
1
n
1
+
1
n
2
)
\left((\bar X-\bar Y)± t_{α/2}t(n_1+n_2-2)S_w\sqrt{\dfrac{1}{n_1}+\dfrac{1}{n_2}}\right)
( ( X ˉ − Y ˉ ) ± t α / 2 t ( n 1 + n 2 − 2 ) S w n 1 1 + n 2 1
)
(
X
ˉ
−
Y
ˉ
)
±
t
α
/
2
t
(
n
1
+
n
2
−
2
)
S
w
1
n
1
+
1
n
2
(\bar X-\bar Y)± t_{α/2}t(n_1+n_2-2)S_w\sqrt{\dfrac{1}{n_1}+\dfrac{1}{n_2}}
( X ˉ − Y ˉ ) ± t α / 2 t ( n 1 + n 2 − 2 ) S w n 1 1 + n 2 1
σ
1
2
/
σ
1
2
σ^2_1/σ^2_1
σ 1 2 / σ 1 2
μ
μ
μ
S
1
2
/
S
2
2
σ
1
2
/
σ
2
2
∼
F
(
n
1
−
1
,
n
2
−
1
)
\dfrac{S_1^2/S_2^2}{σ_1^2/σ_2^2}∼ F(n_1-1,n_2-1)
σ 1 2 / σ 2 2 S 1 2 / S 2 2 ∼ F ( n 1 − 1 , n 2 − 1 )
(
S
1
2
/
S
2
2
F
α
/
2
(
n
1
−
1
,
n
2
−
1
)
,
S
1
2
/
S
2
2
F
1
−
α
/
2
(
n
1
−
1
,
n
2
−
1
)
)
\left(\dfrac{S_1^2/S_2^2}{F_{α/2}(n_1-1,n_2-1)},\dfrac{S_1^2/S_2^2}{F_{1-α/2}(n_1-1,n_2-1)}\right)
( F α / 2 ( n 1 − 1 , n 2 − 1 ) S 1 2 / S 2 2 , F 1 − α / 2 ( n 1 − 1 , n 2 − 1 ) S 1 2 / S 2 2 )
S
1
2
/
S
2
2
F
α
(
n
1
−
1
,
n
2
−
1
)
,
S
1
2
/
S
2
2
F
1
−
α
(
n
1
−
1
,
n
2
−
1
)
\dfrac{S_1^2/S_2^2}{F_{α}(n_1-1,n_2-1)},\dfrac{S_1^2/S_2^2}{F_{1-α}(n_1-1,n_2-1)}
F α ( n 1 − 1 , n 2 − 1 ) S 1 2 / S 2 2 , F 1 − α ( n 1 − 1 , n 2 − 1 ) S 1 2 / S 2 2
假设检验是抽样推断中的一项重要内容。它是根据原资料作出一个总体指标是否等于某一个数值,某一随机变量是否服从某种概率分布的假设,然后利用样本资料采用一定的统计方法计算出有关检验的统计量,依据一定的概率原则,以较小的风险来判断估计数值与总体数值(或者估计分布与实际分布)是否存在显著差异,是否应当接受原假设选择的一种检验方法。
某工厂生产袋装葡萄糖,每袋糖的净重是个随机变量,服从正态分布,机器正常时,每袋糖净重
μ
0
μ_0
μ 0
σ
σ
σ
x
1
,
x
2
,
⋯
,
x
n
x_1,x_2,\cdots,x_n
x 1 , x 2 , ⋯ , x n
X
∼
N
(
μ
,
σ
2
)
X∼ N(μ,σ^2)
X ∼ N ( μ , σ 2 )
μ
=
μ
0
μ=μ_0
μ = μ 0
μ
≠
μ
0
μ\neqμ_0
μ = μ 0
(1) 为此我们提出两个完全对立的假设:
H
0
:
μ
=
μ
0
,
H
1
:
μ
≠
μ
0
H_0: μ=μ_0,\quad H_1: μ\neqμ_0
H 0 : μ = μ 0 , H 1 : μ = μ 0
X
ˉ
\bar X
X ˉ
μ
μ
μ
H
0
H_0
H 0
∣
X
ˉ
−
μ
0
∣
|\bar X-μ_0|
∣ X ˉ − μ 0 ∣
Z
=
X
ˉ
−
μ
0
σ
/
n
∼
N
(
0
,
1
)
Z=\dfrac{\bar X-μ_0}{σ/\sqrt{n}}∼ N(0,1)
Z = σ / n
X ˉ − μ 0 ∼ N ( 0 , 1 )
k
k
k
∣
X
ˉ
−
μ
0
σ
/
n
∣
⩾
k
\left|\dfrac{\bar X-μ_0}{σ/\sqrt{n}}\right|⩾ k
∣ ∣ ∣ ∣ σ / n
X ˉ − μ 0 ∣ ∣ ∣ ∣ ⩾ k
H
0
H_0
H 0
H
0
H_0
H 0
P
μ
∈
H
0
{
拒
绝
H
0
}
=
P
{
t
y
p
e
I
e
r
r
o
r
}
P_{μ\in H_0}\{拒绝H_0\}=P\{\rm type\ I\ error\}
P μ ∈ H 0 { 拒 绝 H 0 } = P { t y p e I e r r o r }
k
k
k
α
∈
(
0
,
1
)
α\in(0,1)
α ∈ ( 0 , 1 )
P
{
t
y
p
e
I
e
r
r
o
r
}
=
P
{
∣
X
ˉ
−
μ
0
σ
/
n
∣
⩾
k
}
=
α
P\{\rm type\ I\ error\}=P\{\left|\dfrac{\bar X-μ_0}{σ/\sqrt{n}}\right|⩾ k\}=α
P { t y p e I e r r o r } = P { ∣ ∣ ∣ ∣ σ / n
X ˉ − μ 0 ∣ ∣ ∣ ∣ ⩾ k } = α
H
0
H_0
H 0
Z
=
X
ˉ
−
μ
0
σ
/
n
∼
N
(
0
,
1
)
Z=\dfrac{\bar X-μ_0}{σ/\sqrt{n}}∼ N(0,1)
Z = σ / n
X ˉ − μ 0 ∼ N ( 0 , 1 )
k
=
z
α
/
2
k=z_{α/2}
k = z α / 2
∣
z
∣
⩾
z
α
/
2
|z|⩾ z_{α/2}
∣ z ∣ ⩾ z α / 2
综述
Z
=
X
ˉ
−
μ
0
σ
/
n
Z=\dfrac{\bar X-μ_0}{σ/\sqrt{n}}
Z = σ / n
X ˉ − μ 0 检验统计量 (test statistic),数
α
α
α 显著水平 (significance level),一般
α
α
α
(
α
=
0.01
,
α
=
0.05
,
α
=
0.1
)
(α=0.01,α=0.05,α=0.1)
( α = 0 . 0 1 , α = 0 . 0 5 , α = 0 . 1 ) 拒绝域 (rejection region),他的补集称为接受域,拒绝域的边界点称为临界点 (critical point)。
α
α
α
H
0
:
μ
=
μ
0
,
H
1
:
μ
≠
μ
0
H_0: μ=μ_0,\quad H_1: μ\neqμ_0
H 0 : μ = μ 0 , H 1 : μ = μ 0
H
0
H_0
H 0 原假设(零假设 null hypothesis) ,
H
1
H_1
H 1 备择假设(对立假设 alternative hypothesis) 。
原假设与备择假设是不对称的!决定谁是原假设,依赖于立场、惯例、方便性。参数假设的形式 :设θ是反映总体指标某方面特征的量, 一般参数θ的假设有三种情形:
H
0
:
θ
=
θ
0
,
H
1
:
θ
<
θ
0
H_0: θ=θ_0,\quad H_1: θ<θ_0
H 0 : θ = θ 0 , H 1 : θ < θ 0
H
0
:
θ
=
θ
0
,
H
1
:
θ
>
θ
0
H_0: θ=θ_0,\quad H_1: θ>θ_0
H 0 : θ = θ 0 , H 1 : θ > θ 0
H
0
:
θ
=
θ
0
,
H
1
:
θ
≠
θ
0
H_0: θ=θ_0,\quad H_1: θ\neq θ_0
H 0 : θ = θ 0 , H 1 : θ = θ 0
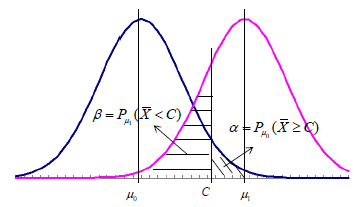
任一检验规则在应用时,都有可能发生错误的判断——两类错误 。显著性检验 (significance test)。犯两类错误的概率记为
P
μ
∈
H
0
{
拒
绝
H
0
}
=
P
{
t
y
p
e
I
e
r
r
o
r
}
P_{μ\in H_0}\{拒绝H_0\}=P\{\rm type\ I\ error\}
P μ ∈ H 0 { 拒 绝 H 0 } = P { t y p e I e r r o r }
P
μ
∈
H
1
{
接
受
H
0
}
=
P
{
t
y
p
e
I
I
e
r
r
o
r
}
P_{μ\in H_1}\{接受H_0\}=P\{\rm type\ II\ error\}
P μ ∈ H 1 { 接 受 H 0 } = P { t y p e I I e r r o r }
\quad
原假设为真
原假设不真
根据样本拒绝 原假设
type Ⅰ error 正确
根据样本接受 原假设
正确
type Ⅱ error
设总体服从
X
∼
N
(
μ
,
1
)
X∼ N(μ,1)
X ∼ N ( μ , 1 )
X
ˉ
∼
N
(
μ
,
1
/
n
)
\bar X∼ N(μ,1/n)
X ˉ ∼ N ( μ , 1 / n )
H
0
:
μ
=
μ
0
,
H
1
:
μ
=
μ
1
>
μ
0
H_0: μ=μ_0,\quad H_1: μ=μ_1>μ_0
H 0 : μ = μ 0 , H 1 : μ = μ 1 > μ 0
X
ˉ
⩾
C
\bar X⩾ C
X ˉ ⩾ C
正态总体均值和方差的检验法 (显著性水平为
α
α
α
假设检验
原假设
H
0
H_0
H 0
检验统计量
备择假设
H
1
H_1
H 1
拒绝域
Z 检验
σ
2
σ^2
σ 2
μ
=
μ
0
μ
⩽
μ
0
μ
⩾
μ
0
μ=μ_0 \\ μ⩽ μ_0 \\ μ⩾μ_0
μ = μ 0 μ ⩽ μ 0 μ ⩾ μ 0
Z
=
X
ˉ
−
μ
0
σ
/
n
Z=\dfrac{\bar X-μ_0}{σ/\sqrt{n}}
Z = σ / n
X ˉ − μ 0
μ
≠
μ
0
μ
>
μ
0
μ
<
μ
0
μ\neq μ_0 \\ μ> μ_0 \\ μ<μ_0
μ = μ 0 μ > μ 0 μ < μ 0
∣
z
∣
⩾
z
α
/
2
z
⩾
z
α
z
⩽
−
z
α
\vert z\vert ⩾ z_{α/2} \\ z ⩾ z_{α} \\ z ⩽ -z_{α}
∣ z ∣ ⩾ z α / 2 z ⩾ z α z ⩽ − z α
t 检验
σ
2
σ^2
σ 2
μ
=
μ
0
μ
⩽
μ
0
μ
⩾
μ
0
μ=μ_0 \\ μ⩽ μ_0 \\ μ⩾μ_0
μ = μ 0 μ ⩽ μ 0 μ ⩾ μ 0
t
=
X
ˉ
−
μ
0
S
/
n
t=\dfrac{\bar X-μ_0}{S/\sqrt{n}}
t = S / n
X ˉ − μ 0
μ
≠
μ
0
μ
>
μ
0
μ
<
μ
0
μ\neq μ_0 \\ μ> μ_0 \\ μ<μ_0
μ = μ 0 μ > μ 0 μ < μ 0
∣
t
∣
⩾
t
α
/
2
(
n
−
1
)
t
⩾
t
α
(
n
−
1
)
t
⩽
−
t
α
(
n
−
1
)
\vert t\vert ⩾ t_{α/2}(n-1) \\ t ⩾ t_{α}(n-1) \\ t ⩽ -t_{α}(n-1)
∣ t ∣ ⩾ t α / 2 ( n − 1 ) t ⩾ t α ( n − 1 ) t ⩽ − t α ( n − 1 )
Z 检验
σ
1
2
,
σ
2
2
σ_1^2,σ_2^2
σ 1 2 , σ 2 2
μ
1
−
μ
2
=
δ
μ
1
−
μ
2
⩽
δ
μ
1
−
μ
2
⩾
δ
μ_1-μ_2=δ \\ μ_1-μ_2⩽ δ \\ μ_1-μ_2⩾δ
μ 1 − μ 2 = δ μ 1 − μ 2 ⩽ δ μ 1 − μ 2 ⩾ δ
Z
=
(
X
ˉ
−
Y
ˉ
)
−
δ
σ
1
2
n
1
+
σ
2
2
n
2
Z=\dfrac{(\bar X-\bar Y)-δ}{\sqrt{\dfrac{σ_1^2}{n_1}+\dfrac{σ_2^2}{n_2}}}
Z = n 1 σ 1 2 + n 2 σ 2 2
( X ˉ − Y ˉ ) − δ
μ
1
−
μ
2
≠
δ
μ
1
−
μ
2
>
δ
μ
1
−
μ
2
<
δ
μ_1-μ_2\neqδ \\ μ_1-μ_2> δ \\ μ_1-μ_2<δ
μ 1 − μ 2 = δ μ 1 − μ 2 > δ μ 1 − μ 2 < δ
∣
z
∣
⩾
z
α
/
2
z
⩾
z
α
z
⩽
−
z
α
\vert z\vert ⩾ z_{α/2} \\ z ⩾ z_{α} \\ z ⩽ -z_{α}
∣ z ∣ ⩾ z α / 2 z ⩾ z α z ⩽ − z α
t 检验
σ
1
2
=
σ
2
2
=
σ
2
σ_1^2=σ_2^2=σ^2
σ 1 2 = σ 2 2 = σ 2
μ
1
−
μ
2
=
δ
μ
1
−
μ
2
⩽
δ
μ
1
−
μ
2
⩾
δ
μ_1-μ_2=δ \\ μ_1-μ_2⩽ δ \\ μ_1-μ_2⩾δ
μ 1 − μ 2 = δ μ 1 − μ 2 ⩽ δ μ 1 − μ 2 ⩾ δ
t
=
(
X
ˉ
−
Y
ˉ
)
−
δ
S
w
1
n
1
+
1
n
2
t=\dfrac{(\bar X-\bar Y)-δ}{S_w\sqrt{\dfrac{1}{n_1}+\dfrac{1}{n_2}}}
t = S w n 1 1 + n 2 1
( X ˉ − Y ˉ ) − δ
S
w
2
=
(
n
1
−
1
)
S
1
2
+
(
n
2
−
1
)
S
2
2
n
1
+
n
2
−
2
S_w^2=\dfrac{(n_1-1)S_1^2+(n_2-1)S_2^2}{n_1+n_2-2}
S w 2 = n 1 + n 2 − 2 ( n 1 − 1 ) S 1 2 + ( n 2 − 1 ) S 2 2
μ
1
−
μ
2
≠
δ
μ
1
−
μ
2
>
δ
μ
1
−
μ
2
<
δ
μ_1-μ_2\neqδ \\ μ_1-μ_2> δ \\ μ_1-μ_2<δ
μ 1 − μ 2 = δ μ 1 − μ 2 > δ μ 1 − μ 2 < δ
∣
t
∣
⩾
t
α
/
2
(
n
1
+
n
2
−
2
)
t
⩾
t
α
(
n
1
+
n
2
−
2
)
t
⩽
−
t
α
(
n
1
+
n
2
−
2
)
\vert t\vert ⩾ t_{α/2}(n_1+n_2-2) \\ t ⩾ t_{α}(n_1+n_2-2) \\ t ⩽ -t_{α}(n_1+n_2-2)
∣ t ∣ ⩾ t α / 2 ( n 1 + n 2 − 2 ) t ⩾ t α ( n 1 + n 2 − 2 ) t ⩽ − t α ( n 1 + n 2 − 2 )
χ
2
χ^2
χ 2
μ
μ
μ
σ
2
=
σ
0
2
σ
2
⩽
σ
0
2
σ
2
⩾
σ
0
2
σ^2=σ_0^2 \\ σ^2⩽ σ^2_0 \\ σ^2⩾σ^2_0
σ 2 = σ 0 2 σ 2 ⩽ σ 0 2 σ 2 ⩾ σ 0 2
χ
2
=
(
n
−
1
)
S
2
σ
2
χ^2=\dfrac{(n-1)S^2}{σ^2}
χ 2 = σ 2 ( n − 1 ) S 2
σ
2
≠
σ
0
2
σ
2
>
σ
0
2
σ
2
<
σ
0
2
σ^2\neq σ^2_0 \\ σ^2> σ^2_0 \\ σ^2<σ^2_0
σ 2 = σ 0 2 σ 2 > σ 0 2 σ 2 < σ 0 2
χ
2
⩾
χ
α
/
2
2
(
n
−
1
)
或
χ
2
⩽
χ
1
−
α
/
2
2
(
n
−
1
)
χ
2
⩾
χ
α
2
(
n
−
1
)
χ
2
⩽
−
χ
α
2
(
n
−
1
)
χ^2 ⩾ χ^2_{α/2}(n-1) 或\\ χ^2 ⩽ χ^2_{1-α/2}(n-1) \\ χ^2 ⩾ χ^2_{α}(n-1) \\ χ^2 ⩽ -χ^2_{α}(n-1)
χ 2 ⩾ χ α / 2 2 ( n − 1 ) 或 χ 2 ⩽ χ 1 − α / 2 2 ( n − 1 ) χ 2 ⩾ χ α 2 ( n − 1 ) χ 2 ⩽ − χ α 2 ( n − 1 )
F检验
μ
1
,
μ
2
μ_1,μ_2
μ 1 , μ 2
σ
2
=
σ
0
2
σ
2
⩽
σ
0
2
σ
2
⩾
σ
0
2
σ^2=σ_0^2 \\ σ^2⩽ σ^2_0 \\ σ^2⩾σ^2_0
σ 2 = σ 0 2 σ 2 ⩽ σ 0 2 σ 2 ⩾ σ 0 2
F
=
S
1
2
S
2
2
F=\dfrac{S_1^2}{S_2^2}
F = S 2 2 S 1 2
σ
2
≠
σ
0
2
σ
2
>
σ
0
2
σ
2
<
σ
0
2
σ^2\neq σ^2_0 \\ σ^2> σ^2_0 \\ σ^2<σ^2_0
σ 2 = σ 0 2 σ 2 > σ 0 2 σ 2 < σ 0 2
F
⩾
F
α
/
2
(
n
1
−
1
,
n
2
−
1
)
或
F
⩽
F
1
−
α
/
2
(
n
1
−
1
,
n
2
−
1
)
F
⩾
F
α
(
n
1
−
1
,
n
2
−
1
)
F
⩽
−
F
α
(
n
1
−
1
,
n
2
−
1
)
F ⩾ F_{α/2}(n_1-1,n_2-1) 或\\ F ⩽ F_{1-α/2}(n_1-1,n_2-1) \\ F ⩾ F_{α}(n_1-1,n_2-1) \\ F ⩽ -F_{α}(n_1-1,n_2-1)
F ⩾ F α / 2 ( n 1 − 1 , n 2 − 1 ) 或 F ⩽ F 1 − α / 2 ( n 1 − 1 , n 2 − 1 ) F ⩾ F α ( n 1 − 1 , n 2 − 1 ) F ⩽ − F α ( n 1 − 1 , n 2 − 1 )
t 检验
μ
D
=
0
μ
D
⩽
0
μ
D
⩾
0
μ_D=0 \\ μ_D⩽ 0 \\ μ_D⩾ 0
μ D = 0 μ D ⩽ 0 μ D ⩾ 0
t
=
D
ˉ
−
0
S
D
/
n
t=\dfrac{\bar D-0}{S_D/\sqrt{n}}
t = S D / n
D ˉ − 0
μ
D
≠
0
μ
D
>
0
μ
D
<
0
μ_D\neq 0 \\ μ_D> 0 \\ μ_D<0
μ D = 0 μ D > 0 μ D < 0
∣
t
∣
⩾
t
α
/
2
(
n
−
1
)
t
⩾
t
α
(
n
−
1
)
t
⩽
−
t
α
(
n
−
1
)
\vert t\vert ⩾ t_{α/2}(n-1) \\ t ⩾ t_{α}(n-1) \\ t ⩽ -t_{α}(n-1)
∣ t ∣ ⩾ t α / 2 ( n − 1 ) t ⩾ t α ( n − 1 ) t ⩽ − t α ( n − 1 )
置信区间和假设检验之间有明显的关联,先考察置信区间和双边检验的关系
X
∼
F
(
x
;
θ
)
,
θ
∈
Θ
X∼ F(x;θ),θ\inΘ
X ∼ F ( x ; θ ) , θ ∈ Θ
X
1
,
X
2
,
⋯
,
X
n
X_1,X_2,\cdots,X_n
X 1 , X 2 , ⋯ , X n
x
1
,
x
2
,
⋯
,
x
n
x_1,x_2,\cdots,x_n
x 1 , x 2 , ⋯ , x n
(
θ
^
L
,
θ
^
U
)
(\hatθ_L,\hatθ_U)
( θ ^ L , θ ^ U )
1
−
α
1-α
1 − α
∀
θ
∈
Θ
∀ θ\inΘ
∀ θ ∈ Θ
P
{
θ
^
L
<
θ
<
θ
^
U
}
⩾
1
−
α
(1)
P\{\hatθ_L<θ<\hatθ_U\}⩾ 1-α \tag{1}
P { θ ^ L < θ < θ ^ U } ⩾ 1 − α ( 1 )
θ
^
L
=
θ
^
L
(
X
1
,
X
2
,
…
,
X
n
)
,
θ
^
U
=
θ
^
U
(
X
1
,
X
2
,
…
,
X
n
)
(
θ
^
L
<
θ
^
U
)
\hat θ_L=\hat θ_L(X_1,X_2,…,X_n),\hat θ_U=\hat θ_U(X_1,X_2,…,X_n)(\hatθ_L<\hatθ_U)
θ ^ L = θ ^ L ( X 1 , X 2 , … , X n ) , θ ^ U = θ ^ U ( X 1 , X 2 , … , X n ) ( θ ^ L < θ ^ U )
α
α
α
H
0
:
θ
=
θ
0
,
H
1
:
θ
≠
θ
0
H_0: θ=θ_0,\quad H_1: θ\neq θ_0
H 0 : θ = θ 0 , H 1 : θ = θ 0
P
{
θ
0
⩽
θ
^
L
∪
θ
0
⩾
θ
^
U
}
⩽
α
P\{θ_0⩽ \hatθ_L∪ θ_0⩾ \hatθ_U\}⩽ α
P { θ 0 ⩽ θ ^ L ∪ θ 0 ⩾ θ ^ U } ⩽ α
θ
0
⩽
θ
^
L
∪
θ
0
⩾
θ
^
U
θ_0⩽ \hatθ_L∪ θ_0⩾ \hatθ_U
θ 0 ⩽ θ ^ L ∪ θ 0 ⩾ θ ^ U
θ
^
L
<
θ
0
<
θ
^
U
\hatθ_L<θ_0<\hatθ_U
θ ^ L < θ 0 < θ ^ U
θ
0
∈
(
θ
^
L
,
θ
^
U
)
θ_0\in(\hatθ_L,\hatθ_U)
θ 0 ∈ ( θ ^ L , θ ^ U )
H
0
H_0
H 0
θ
0
∉
(
θ
^
L
,
θ
^
U
)
θ_0\not\in(\hatθ_L,\hatθ_U)
θ 0 ∈ ( θ ^ L , θ ^ U )
H
0
H_0
H 0
α
α
α
1
−
α
1-α
1 − α
结论
1
−
α
1-α
1 − α
(
θ
^
L
,
θ
^
U
)
(\hatθ_L,\hatθ_U)
( θ ^ L , θ ^ U )
α
α
α
H
0
:
θ
=
θ
0
,
H
1
:
θ
≠
θ
0
H_0: θ=θ_0,\quad H_1: θ\neq θ_0
H 0 : θ = θ 0 , H 1 : θ = θ 0
1
−
α
1-α
1 − α
(
−
∞
,
θ
^
U
)
(-∞,\hatθ_U)
( − ∞ , θ ^ U )
α
α
α
H
0
:
θ
⩾
θ
0
,
H
1
:
θ
<
θ
0
H_0: θ⩾ θ_0,\quad H_1: θ< θ_0
H 0 : θ ⩾ θ 0 , H 1 : θ < θ 0
1
−
α
1-α
1 − α
(
θ
^
L
,
+
∞
)
(\hatθ_L,+∞)
( θ ^ L , + ∞ )
α
α
α
H
0
:
θ
⩽
θ
0
,
H
1
:
θ
>
θ
0
H_0: θ⩽ θ_0,\quad H_1: θ> θ_0
H 0 : θ ⩽ θ 0 , H 1 : θ > θ 0
前面介绍的各种检验都是在总体服从正态分布前提下,对参数进行假设检验的。但是,在数据分析过程中,由于种种原因,总体服从何种理论分布并不知道,此时参数检验的方法就不再适用了。
百度百科:非参数检验
Pearson
χ
2
χ^2
χ 2 (Goodness of Fit Test)
设总体
X
∼
F
(
x
)
,
F
(
x
)
X∼ F(x), F(x)
X ∼ F ( x ) , F ( x )
H
0
:
F
(
x
)
=
F
0
(
x
)
∀
x
∈
R
H_0:F(x)=F_0(x)\quad ∀ x\in\R
H 0 : F ( x ) = F 0 ( x ) ∀ x ∈ R
F
0
(
x
)
F_0(x)
F 0 ( x )
拟合优度检验的基本原理和步骤:
H
0
H_0
H 0
X
X
X
A
1
,
⋯
,
A
k
A_1,\cdots,A_k
A 1 , ⋯ , A k
n
i
(
i
=
1
,
⋯
,
k
)
n_i(i=1,\cdots,k)
n i ( i = 1 , ⋯ , k )
x
1
,
⋯
,
x
n
x_1,\cdots,x_n
x 1 , ⋯ , x n
A
i
A_i
A i
H
0
H_0
H 0
F
0
(
x
)
F_0(x)
F 0 ( x )
A
i
A_i
A i
p
i
=
P
{
X
=
a
i
}
p_i=P\{X=a_i\}
p i = P { X = a i }
F
0
(
x
)
F_0(x)
F 0 ( x )
r
r
r
r
r
r
p
i
p_i
p i
p
^
i
\hat p_i
p ^ i
n
p
i
np_i
n p i
n
p
^
i
n\hat p_i
n p ^ i
F
0
(
x
)
F_0(x)
F 0 ( x )
n
i
n
→
p
i
(
n
→
∞
)
\dfrac{n_i}{n}\to p_i\quad(n\to∞)
n n i → p i ( n → ∞ )
⟹
∣
n
i
−
n
p
i
∣
\implies |n_i-np_i|
⟹ ∣ n i − n p i ∣
⟹
∑
i
=
1
k
C
i
(
n
i
/
n
−
p
i
)
2
\implies \displaystyle\sum^{k}_{i=1}C_i(n_i/n-p_i)^2
⟹ i = 1 ∑ k C i ( n i / n − p i ) 2
其中
C
i
C_i
C i
C
i
=
n
/
p
i
C_i=n/p_i
C i = n / p i
χ
2
=
∑
i
=
1
k
n
p
i
(
n
i
n
−
p
i
)
2
=
∑
i
=
1
k
(
n
i
2
n
p
i
−
n
)
χ^2=\displaystyle\sum^{k}_{i=1}\frac{n}{p_i}(\frac{n_i}{n}-p_i)^2=\displaystyle\sum^{k}_{i=1}(\frac{n_i^2}{np_i}-n)
χ 2 = i = 1 ∑ k p i n ( n n i − p i ) 2 = i = 1 ∑ k ( n p i n i 2 − n )
定理 :不论总体服从什么分布,若 n充分大,当
H
0
H_0
H 0
χ
2
=
∑
i
=
1
k
(
n
i
2
n
p
i
−
n
)
χ^2=\displaystyle\sum^{k}_{i=1}(\frac{n_i^2}{np_i}-n)
χ 2 = i = 1 ∑ k ( n p i n i 2 − n )
χ
2
(
k
−
1
)
χ^2(k-1)
χ 2 ( k − 1 )
χ
2
⩾
χ
α
2
(
k
−
1
)
χ^2⩾ χ^2_{α}(k-1)
χ 2 ⩾ χ α 2 ( k − 1 )
χ
2
=
∑
i
=
1
k
(
n
i
2
n
p
^
i
−
n
)
χ^2=\displaystyle\sum^{k}_{i=1}(\frac{n_i^2}{n\hat p_i}-n)
χ 2 = i = 1 ∑ k ( n p ^ i n i 2 − n )
χ
2
(
k
−
r
−
1
)
χ^2(k-r-1)
χ 2 ( k − r − 1 )
χ
2
⩾
χ
α
2
(
k
−
r
−
1
)
χ^2⩾ χ^2_{α}(k-r-1)
χ 2 ⩾ χ α 2 ( k − r − 1 )
r
r
r
F
0
(
x
)
F_0(x)
F 0 ( x )
α
α
α
n
⩾
50
,
n
p
i
(
或
n
p
^
i
)
⩾
5
n⩾ 50,np_i(或n\hat p_i)⩾ 5
n ⩾ 5 0 , n p i ( 或 n p ^ i ) ⩾ 5
Pearson
χ
2
χ^2
χ 2 (test of independence)
(
X
,
Y
)
∼
F
(
x
,
y
)
(X,Y)∼ F(x,y)
( X , Y ) ∼ F ( x , y )
X
∼
F
1
(
x
)
,
Y
∼
F
2
(
y
)
X∼ F_1(x),Y∼ F_2(y)
X ∼ F 1 ( x ) , Y ∼ F 2 ( y )
(
X
1
,
Y
1
)
,
(
X
2
,
Y
2
)
,
⋯
,
(
X
n
,
Y
n
)
(X_1,Y_1),(X_2,Y_2),\cdots,(X_n,Y_n)
( X 1 , Y 1 ) , ( X 2 , Y 2 ) , ⋯ , ( X n , Y n )
H
0
:
X
,
Y
独
立
H
1
:
X
,
Y
不
独
立
H_0:X,Y独立\quad H_1:X,Y不独立
H 0 : X , Y 独 立 H 1 : X , Y 不 独 立
H
0
:
F
(
x
,
y
)
=
F
1
(
x
)
F
2
(
y
)
H
1
:
F
(
x
,
y
)
≠
F
1
(
x
)
F
2
(
y
)
H_0:F(x,y)=F_1(x)F_2(y)\quad H_1:F(x,y)\neq F_1(x)F_2(y)
H 0 : F ( x , y ) = F 1 ( x ) F 2 ( y ) H 1 : F ( x , y ) = F 1 ( x ) F 2 ( y )
(1) 将两个指标
X
,
Y
X , Y
X , Y
A
1
,
A
2
,
⋯
,
A
r
A_1,A_2,\cdots,A_r
A 1 , A 2 , ⋯ , A r
B
1
,
B
2
,
⋯
,
B
s
B_1,B_2,\cdots,B_s
B 1 , B 2 , ⋯ , B s
X
/
Y
B
1
B
2
⋯
B
j
⋯
B
s
{
X
∈
A
i
}
A
1
n
11
n
12
⋯
n
1
j
⋯
n
1
s
n
1
∙
A
2
n
21
n
22
⋯
n
2
j
⋯
n
2
s
n
2
∙
⋮
⋯
⋯
⋯
⋮
A
i
n
i
1
n
i
2
⋯
n
i
j
⋯
n
i
s
n
i
∙
⋮
⋯
⋯
⋯
⋮
A
r
n
r
1
n
r
2
⋯
n
r
j
⋯
n
r
s
n
r
∙
{
Y
∈
B
j
}
n
∙
1
n
∙
2
⋯
p
∙
j
⋯
n
∙
s
n
\begin{array}{c|cccccc|c} X/Y &B_1&B_2&\cdots&B_j&\cdots &B_s&\{X\in A_i\} \\ \hline A_1 &n_{11}&n_{12}&\cdots&n_{1j}&\cdots &n_{1s}&n_{1 \bullet} \\ A_2 &n_{21}&n_{22}&\cdots&n_{2j}&\cdots &n_{2s}&n_{2 \bullet} \\ \vdots &\cdots&&\cdots&&\cdots& &\vdots \\ A_i&n_{i1}&n_{i2}&\cdots&n_{ij}&\cdots &n_{is}&n_{i \bullet} \\ \vdots &\cdots&&\cdots&&\cdots &&\vdots \\ A_r&n_{r1}&n_{r2}&\cdots&n_{rj}&\cdots &n_{rs}&n_{r \bullet} \\ \hline \{Y\in B_j\} &n_{\bullet 1}&n_{\bullet 2}&\cdots&p_{\bullet j}&\cdots &n_{\bullet s}&n \end{array}
X / Y A 1 A 2 ⋮ A i ⋮ A r { Y ∈ B j } B 1 n 1 1 n 2 1 ⋯ n i 1 ⋯ n r 1 n ∙ 1 B 2 n 1 2 n 2 2 n i 2 n r 2 n ∙ 2 ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ B j n 1 j n 2 j n i j n r j p ∙ j ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ B s n 1 s n 2 s n i s n r s n ∙ s { X ∈ A i } n 1 ∙ n 2 ∙ ⋮ n i ∙ ⋮ n r ∙ n
(2) 记
p
i
j
p_{ij}
p i j
(
X
,
Y
)
( X , Y )
( X , Y )
(
i
,
j
)
( i , j )
( i , j )
p
i
∙
=
∑
j
=
1
s
p
i
j
,
p
∙
j
=
∑
i
=
1
r
p
i
j
p_{i\bullet}=\displaystyle\sum^{s}_{j=1}p_{ij},\quad p_{\bullet j}=\displaystyle\sum^{r}_{i=1}p_{ij}
p i ∙ = j = 1 ∑ s p i j , p ∙ j = i = 1 ∑ r p i j
H
0
:
p
i
j
=
p
i
∙
⋅
p
∙
j
H_0:p_{ij}=p_{i\bullet}\cdot p_{\bullet j}
H 0 : p i j = p i ∙ ⋅ p ∙ j
p
i
∙
,
p
∙
j
p_{i\bullet}, p_{\bullet j}
p i ∙ , p ∙ j
p
^
∙
j
=
n
i
∙
n
,
p
^
∙
j
=
n
∙
j
n
\hat p_{\bullet j}=\dfrac{n_{i\bullet}}{n},\quad \hat p_{\bullet j}=\dfrac{n_{\bullet j}}{n}
p ^ ∙ j = n n i ∙ , p ^ ∙ j = n n ∙ j
H
0
H_0
H 0
n
i
j
n
≈
p
^
i
∙
⋅
p
^
∙
j
\dfrac{n_{ij}}{n}\approx \hat p_{i\bullet}\cdot \hat p_{\bullet j}
n n i j ≈ p ^ i ∙ ⋅ p ^ ∙ j
χ
2
=
∑
i
=
1
r
∑
j
=
1
s
(
n
i
2
n
p
^
i
∙
⋅
p
^
∙
j
−
n
)
∼
χ
2
(
(
r
−
1
)
(
s
−
1
)
)
χ^2=\displaystyle\sum^{r}_{i=1}\sum^{s}_{j=1}(\frac{n_i^2}{n\hat p_{i\bullet}\cdot \hat p_{\bullet j}}-n)∼ χ^2((r-1)(s-1))
χ 2 = i = 1 ∑ r j = 1 ∑ s ( n p ^ i ∙ ⋅ p ^ ∙ j n i 2 − n ) ∼ χ 2 ( ( r − 1 ) ( s − 1 ) )
χ
2
⩾
χ
α
2
(
(
r
−
1
)
(
s
−
1
)
)
χ^2⩾ χ^2_{α}((r-1)(s-1))
χ 2 ⩾ χ α 2 ( ( r − 1 ) ( s − 1 ) )
偏度、峰度检验
χ
2
χ^2
χ 2
I
I
\mathrm{II}
I I 夏皮罗-威尔克检验(Shapiro–Wilk test) 最为有效。
随机变量
X
X
X
Y
=
[
X
−
E
(
X
)
]
/
D
(
X
)
Y=[X-E(X)]/\sqrt{D(X)}
Y = [ X − E ( X ) ] / D ( X )
ν
1
=
E
(
Y
3
)
=
B
3
B
2
3
/
2
,
ν
2
=
E
(
Y
4
)
=
B
4
B
2
2
ν_1=E(Y^3)=\dfrac{B_3}{B_2^{3/2}},\quad ν_2=E(Y^4)=\dfrac{B_4}{B_2^2}
ν 1 = E ( Y 3 ) = B 2 3 / 2 B 3 , ν 2 = E ( Y 4 ) = B 2 2 B 4
B
k
=
E
[
(
X
−
E
(
X
)
)
k
]
B_k=E[(X-E(X))^k]
B k = E [ ( X − E ( X ) ) k ]
X
X
X
X
∼
N
(
μ
,
σ
2
)
X∼ N(μ,σ^2)
X ∼ N ( μ , σ 2 )
ν
1
=
0
,
ν
2
=
3
ν_1=0,ν_2=3
ν 1 = 0 , ν 2 = 3
(1) 设
X
1
,
X
2
,
⋯
,
X
n
X_1,X_2,\cdots,X_n
X 1 , X 2 , ⋯ , X n
ν
1
,
ν
2
ν_1,ν_2
ν 1 , ν 2
G
1
,
G
2
G_1,G_2
G 1 , G 2
X
∼
N
(
μ
,
σ
2
)
X∼ N(μ,σ^2)
X ∼ N ( μ , σ 2 )
n
n
n
G
1
∼
N
(
0
,
σ
1
2
)
,
G
2
∼
N
(
μ
2
,
σ
2
2
)
G_1∼ N(0,σ_1^2) , G_2∼ N(μ_2,σ_2^2)
G 1 ∼ N ( 0 , σ 1 2 ) , G 2 ∼ N ( μ 2 , σ 2 2 )
σ
1
2
=
6
(
n
−
2
)
(
n
+
1
)
(
n
+
3
)
,
μ
2
=
3
−
6
n
+
1
,
σ
2
2
=
24
(
n
−
2
)
(
n
−
3
)
(
n
+
1
)
2
(
n
+
3
)
(
n
+
5
)
σ_1^2=\dfrac{6(n-2)}{(n+1)(n+3)},μ_2=3-\dfrac{6}{n+1},σ_2^2=\dfrac{24(n-2)(n-3)}{(n+1)^2(n+3)(n+5)}
σ 1 2 = ( n + 1 ) ( n + 3 ) 6 ( n − 2 ) , μ 2 = 3 − n + 1 6 , σ 2 2 = ( n + 1 ) 2 ( n + 3 ) ( n + 5 ) 2 4 ( n − 2 ) ( n − 3 )
(2) 现在来检验假设
H
0
:
X
∼
N
(
μ
,
σ
2
)
H_0:X∼ N(μ,σ^2)
H 0 : X ∼ N ( μ , σ 2 )
G
1
,
G
2
G_1,G_2
G 1 , G 2
U
1
=
G
1
/
σ
1
,
U
2
=
(
G
2
−
μ
2
)
/
σ
2
U_1=G_1/σ_1,U_2=(G_2-μ_2)/σ_2
U 1 = G 1 / σ 1 , U 2 = ( G 2 − μ 2 ) / σ 2
G
1
→
P
ν
1
(
n
→
∞
)
G_1\xrightarrow{P}ν_1\quad (n\to∞)
G 1 P
ν 1 ( n → ∞ )
G
2
→
P
ν
2
(
n
→
∞
)
G_2\xrightarrow{P}ν_2\quad (n\to∞)
G 2 P
ν 2 ( n → ∞ )
H
0
H_0
H 0
n
n
n
U
1
∼
N
(
0
,
1
)
,
U
2
∼
N
(
0
,
1
)
U_1∼ N(0,1),U_2∼ N(0,1)
U 1 ∼ N ( 0 , 1 ) , U 2 ∼ N ( 0 , 1 )
∣
U
1
∣
,
∣
U
2
∣
|U_1|,|U_2|
∣ U 1 ∣ , ∣ U 2 ∣
∣
u
1
∣
,
∣
u
2
∣
|u_1|,|u_2|
∣ u 1 ∣ , ∣ u 2 ∣
ν
1
=
0
,
ν
2
=
3
ν_1=0,ν_2=3
ν 1 = 0 , ν 2 = 3
α
α
α
∣
u
1
∣
⩾
z
α
/
4
或
∣
u
2
∣
⩾
z
α
/
4
|u_1|⩾ z_{α/4}或|u_2|⩾ z_{α/4}
∣ u 1 ∣ ⩾ z α / 4 或 ∣ u 2 ∣ ⩾ z α / 4
K-S 检验
秩和检验 (Rank Sum Test)
n
1
≠
n
2
n_1\ne n_2
n 1 = n 2
(1) 设两个总体
X
1
∼
F
1
(
x
)
,
X
2
∼
F
2
(
x
)
X_1∼ F_1(x),X_2∼ F_2(x)
X 1 ∼ F 1 ( x ) , X 2 ∼ F 2 ( x )
H
0
:
F
1
(
x
)
=
F
2
(
x
)
,
H
1
:
F
1
(
x
)
≠
F
2
(
x
)
H_0:F_1(x)=F_2(x),\quad H_1:F_1(x)\neq F_2(x)
H 0 : F 1 ( x ) = F 2 ( x ) , H 1 : F 1 ( x ) = F 2 ( x )
(2) 秩的定义 :设从总体
X
X
X
n
n
n
x
(
1
)
<
x
(
2
)
<
⋯
<
x
(
n
)
x_{(1)}<x_{(2)}<\cdots<x_{(n)}
x ( 1 ) < x ( 2 ) < ⋯ < x ( n )
x
(
i
)
x_{(i)}
x ( i )
i
(
i
=
1
,
2
,
⋯
,
n
)
i(i=1,2,\cdots,n)
i ( i = 1 , 2 , ⋯ , n )
X
1
,
X
2
X_1,X_2
X 1 , X 2
n
1
,
n
2
n_1,n_2
n 1 , n 2
n
1
⩽
n
2
n_1⩽ n_2
n 1 ⩽ n 2
n
1
+
n
2
n_1+n_2
n 1 + n 2
X
1
,
X
2
X_1,X_2
X 1 , X 2
R
1
,
R
2
R_1,R_2
R 1 , R 2
R
1
,
R
2
R_1,R_2
R 1 , R 2
R
1
+
R
2
=
1
2
(
n
1
+
n
2
)
(
n
1
+
n
2
+
1
)
R_1+R_2=\dfrac{1}{2}(n_1+n_2)(n_1+n_2+1)
R 1 + R 2 = 2 1 ( n 1 + n 2 ) ( n 1 + n 2 + 1 )
(3) 当
H
0
H_0
H 0
X
1
X_1
X 1
[
1
,
n
1
+
n
2
]
[1,n_1+n_2]
[ 1 , n 1 + n 2 ]
R
1
∈
[
1
2
n
1
(
n
1
+
1
)
,
1
2
n
1
(
n
1
+
2
n
2
+
1
)
]
R_1\in [\dfrac{1}{2}n_1(n_1+1),\dfrac{1}{2}n_1(n_1+2n_2+1)]
R 1 ∈ [ 2 1 n 1 ( n 1 + 1 ) , 2 1 n 1 ( n 1 + 2 n 2 + 1 ) ]
α
α
α
H
0
H_0
H 0
r
1
⩽
C
U
(
α
/
2
)
或
r
1
⩾
C
L
(
α
/
2
)
r_1⩽ C_U(α/2)或r_1⩾ C_L(α/2)
r 1 ⩽ C U ( α / 2 ) 或 r 1 ⩾ C L ( α / 2 )
r
1
r_1
r 1
R
1
R_1
R 1
C
U
(
α
/
2
)
C_U(α/2)
C U ( α / 2 )
P
{
R
1
⩽
C
U
(
α
/
2
)
}
⩽
α
/
2
P\{R_1⩽ C_U(α/2)\}⩽ α/2
P { R 1 ⩽ C U ( α / 2 ) } ⩽ α / 2
C
L
(
α
/
2
)
C_L(α/2)
C L ( α / 2 )
P
{
R
1
⩾
C
L
(
α
/
2
)
}
⩽
α
/
2
P\{R_1⩾ C_L(α/2)\}⩽ α/2
P { R 1 ⩾ C L ( α / 2 ) } ⩽ α / 2
I
\mathrm{I}
I
α
α
α
R
1
R_1
R 1
(4) 当
H
0
H_0
H 0
X
1
X_1
X 1
∁
n
1
+
n
2
n
1
∁_{n_1+n_2}^{n_1}
∁ n 1 + n 2 n 1
μ
R
1
=
E
(
R
1
)
=
1
2
n
1
(
n
1
+
n
2
+
1
)
,
σ
R
1
2
=
D
(
R
1
)
=
1
12
n
1
n
2
(
n
1
+
n
2
+
1
)
μ_{R_1}=E(R_1)=\dfrac{1}{2}n_1(n_1+n_2+1),σ^2_{R_1}=D(R_1)=\dfrac{1}{12}n_1n_2(n_1+n_2+1)
μ R 1 = E ( R 1 ) = 2 1 n 1 ( n 1 + n 2 + 1 ) , σ R 1 2 = D ( R 1 ) = 1 2 1 n 1 n 2 ( n 1 + n 2 + 1 )
n
1
,
n
2
⩾
10
n_1,n_2⩾ 10
n 1 , n 2 ⩾ 1 0
H
0
H_0
H 0
R
1
∼
N
(
μ
R
1
,
σ
R
1
2
)
R_1∼ N(μ_{R_1},σ^2_{R_1})
R 1 ∼ N ( μ R 1 , σ R 1 2 )
Z
=
(
R
1
−
μ
R
1
)
/
σ
R
1
2
Z=(R_1-μ_{R_1})/σ^2_{R_1}
Z = ( R 1 − μ R 1 ) / σ R 1 2
α
α
α
∣
z
∣
⩾
z
α
/
2
,
z
⩾
z
α
,
z
⩽
−
z
α
|z|⩾ z_{α/2},\quad z⩾ z_{α},\quad z⩽ -z_{α}
∣ z ∣ ⩾ z α / 2 , z ⩾ z α , z ⩽ − z α
z
z
z
Z
Z
Z
以上讨论的问题都是临界值法,在假设检验中常见到P值(P-Value,Probability,Pr),P值是进行检验决策的另一个依据。
为理解 p-value 从一个例子引入
X
∼
N
(
μ
,
σ
2
)
,
μ
X∼ N(μ,σ^2),μ
X ∼ N ( μ , σ 2 ) , μ
X
1
,
X
2
,
⋯
,
X
n
X_1,X_2,\cdots,X_n
X 1 , X 2 , ⋯ , X n
x
1
,
x
2
,
⋯
,
x
n
x_1,x_2,\cdots,x_n
x 1 , x 2 , ⋯ , x n
H
0
:
μ
=
μ
0
,
H
1
:
μ
≠
μ
0
H_0:μ=μ_0,\quad H_1:μ\neq μ_0
H 0 : μ = μ 0 , H 1 : μ = μ 0
Z
=
X
ˉ
−
μ
0
σ
/
n
Z=\dfrac{\bar X-μ_0}{σ/\sqrt{n}}
Z = σ / n
X ˉ − μ 0
z
0
=
x
ˉ
−
μ
0
σ
/
n
z_0=\dfrac{\bar x-μ_0}{σ/\sqrt{n}}
z 0 = σ / n
x ˉ − μ 0
P
{
Z
⩾
∣
z
0
∣
}
=
1
−
Φ
(
∣
z
0
∣
)
P\{Z⩾ |z_0|\}=1-Φ( |z_0|)
P { Z ⩾ ∣ z 0 ∣ } = 1 − Φ ( ∣ z 0 ∣ )
∣
z
0
∣
|z_0|
∣ z 0 ∣
α
⩾
p
α⩾ p
α ⩾ p
z
α
⩽
z
0
z_α⩽ z_0
z α ⩽ z 0
p-value 的定义 :假设检验的 p-value 由检验统计量的样本观察值得出的原假设可被拒绝的最小显著性水平。
p
⩽
α
p⩽ α
p ⩽ α
H
0
H_0
H 0
p
>
α
p> α
p > α
H
0
H_0
H 0
p
⩽
0.01
p⩽ 0.01
p ⩽ 0 . 0 1
0.01
<
p
⩽
0.05
0.01<p⩽ 0.05
0 . 0 1 < p ⩽ 0 . 0 5
0.05
<
p
⩽
0.1
0.05<p⩽ 0.1
0 . 0 5 < p ⩽ 0 . 1
p
>
0.1
p>0.1
p > 0 . 1
方差分析(ANOVA) ,是由英国统计学家费歇尔(Fisher)在20世纪20年代提出的,可用于推断两个或两个以上总体均值是否有差异的显著性检验。试验指标 (Test Indicators)。因素 (factor)。因素中各个不同状态称为水平 (level)。单因素试验 (Single-factor experiment),如果有多个因素改变称为多因素试验 (Multiple-factor experiment)。
设因素
A
A
A
r
r
r
A
1
,
A
2
,
⋯
,
A
r
A_1,A_2,\cdots,A_r
A 1 , A 2 , ⋯ , A r
A
i
A_i
A i
n
i
(
n
i
⩾
2
)
n_i(n_i⩾ 2)
n i ( n i ⩾ 2 )
水平
观察结果
样本均值
A
1
:
N
(
μ
1
,
σ
2
)
A_1: N(μ_1,σ^2)
A 1 : N ( μ 1 , σ 2 )
X
11
,
X
12
,
⋯
,
X
1
n
1
X_{11},X_{12},\cdots,X_{1n_1}
X 1 1 , X 1 2 , ⋯ , X 1 n 1
X
ˉ
1
∙
\bar X_{1\bullet}
X ˉ 1 ∙
A
2
:
N
(
μ
2
,
σ
2
)
A_2: N(μ_2,σ^2)
A 2 : N ( μ 2 , σ 2 )
X
21
,
X
22
,
⋯
,
X
2
n
2
X_{21},X_{22},\cdots,X_{2n_2}
X 2 1 , X 2 2 , ⋯ , X 2 n 2
X
ˉ
2
∙
\bar X_{2\bullet}
X ˉ 2 ∙
⋯
\cdots
⋯
⋯
\cdots
⋯
⋯
\cdots
⋯
A
r
:
N
(
μ
r
,
σ
2
)
A_r: N(μ_r,σ^2)
A r : N ( μ r , σ 2 )
X
r
1
,
X
r
2
,
⋯
,
X
r
n
r
X_{r1},X_{r2},\cdots,X_{rn_r}
X r 1 , X r 2 , ⋯ , X r n r
X
ˉ
r
∙
\bar X_{r\bullet}
X ˉ r ∙
由于
X
i
j
∼
N
(
μ
i
,
σ
2
)
X_{ij}∼ N(μ_i,σ^2)
X i j ∼ N ( μ i , σ 2 )
X
i
j
−
μ
i
∼
N
(
0
,
σ
2
)
X_{ij}-μ_i∼ N(0,σ^2)
X i j − μ i ∼ N ( 0 , σ 2 )
ϵ
i
j
=
X
i
j
−
μ
i
ϵ_{ij}=X_{ij}-μ_i
ϵ i j = X i j − μ i
{
X
i
j
=
μ
i
+
ϵ
i
j
ϵ
i
j
∼
N
(
0
,
σ
2
)
,
各
ϵ
i
j
独
立
i
=
1
,
2
,
⋯
,
r
j
=
1
,
2
,
⋯
,
n
i
\begin{cases} X_{ij}=μ_i+ϵ_{ij} \\ ϵ_{ij}∼ N(0,σ^2),\quad 各ϵ_{ij}独立 \\ i=1,2,\cdots,r \\ j=1,2,\cdots,n_i \end{cases}
⎩ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎧ X i j = μ i + ϵ i j ϵ i j ∼ N ( 0 , σ 2 ) , 各 ϵ i j 独 立 i = 1 , 2 , ⋯ , r j = 1 , 2 , ⋯ , n i
n
=
∑
i
=
1
r
n
i
n=\displaystyle\sum_{i=1}^{r}n_i
n = i = 1 ∑ r n i
方差分析的任务是对上述模型:
比较这
r
r
r
H
0
:
μ
1
=
μ
2
=
⋯
=
μ
r
,
H
1
:
μ
1
,
μ
2
,
⋯
,
μ
r
H_0:μ_1=μ_2=\cdots=μ_r,\quad H_1:μ_1,μ_2,\cdots,μ_r
H 0 : μ 1 = μ 2 = ⋯ = μ r , H 1 : μ 1 , μ 2 , ⋯ , μ r
作出未知参数
μ
1
,
μ
2
,
⋯
,
μ
r
,
σ
2
μ_1,μ_2,\cdots,μ_r,σ^2
μ 1 , μ 2 , ⋯ , μ r , σ 2
(1) 为了便于讨论,我们引入加权平均值
μ
=
1
n
∑
i
=
1
r
n
i
μ
i
μ=\displaystyle\frac{1}{n}\sum_{i=1}^{r}n_iμ_i
μ = n 1 i = 1 ∑ r n i μ i 总平均 (total mean)。
δ
i
=
μ
i
−
μ
δ_i=μ_i-μ
δ i = μ i − μ
A
i
A_i
A i 效应 (effect)。此时
∑
i
=
1
r
n
i
δ
i
=
0
\displaystyle\sum_{i=1}^{r}n_iδ_i=0
i = 1 ∑ r n i δ i = 0
{
X
i
j
=
μ
+
δ
i
+
ϵ
i
j
ϵ
i
j
∼
N
(
0
,
σ
2
)
,
各
ϵ
i
j
独
立
i
=
1
,
2
,
⋯
,
r
j
=
1
,
2
,
⋯
,
n
i
∑
i
=
1
r
n
i
δ
i
=
0
\begin{cases} X_{ij}=μ+δ_i+ϵ_{ij} \\ ϵ_{ij}∼ N(0,σ^2),\quad 各ϵ_{ij}独立 \\ i=1,2,\cdots,r \\ j=1,2,\cdots,n_i \\ \displaystyle\sum_{i=1}^{r}n_iδ_i=0 \end{cases}
⎩ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎧ X i j = μ + δ i + ϵ i j ϵ i j ∼ N ( 0 , σ 2 ) , 各 ϵ i j 独 立 i = 1 , 2 , ⋯ , r j = 1 , 2 , ⋯ , n i i = 1 ∑ r n i δ i = 0
H
0
:
δ
1
=
δ
2
=
⋯
=
δ
r
=
0
,
H
1
:
δ
1
,
δ
2
,
⋯
,
δ
r
H_0:δ_1=δ_2=\cdots=δ_r=0,\quad H_1:δ_1,δ_2,\cdots,δ_r
H 0 : δ 1 = δ 2 = ⋯ = δ r = 0 , H 1 : δ 1 , δ 2 , ⋯ , δ r
S
T
=
∑
i
=
1
r
∑
j
=
1
n
i
(
X
i
j
−
X
ˉ
)
2
\displaystyle S_T=\sum_{i=1}^{r}\sum_{j=1}^{n_i}(X_{ij}-\bar X)^2
S T = i = 1 ∑ r j = 1 ∑ n i ( X i j − X ˉ ) 2 总离差平方和 (total sum of deviation square)。其中
X
ˉ
=
1
n
∑
i
=
1
r
∑
j
=
1
n
i
X
i
j
\displaystyle\bar X=\frac{1}{n}\sum_{i=1}^{r}\sum_{j=1}^{n_i}X_{ij}
X ˉ = n 1 i = 1 ∑ r j = 1 ∑ n i X i j
S
T
S_T
S T
A
A
A 效应平方和 (sum of squares of effects)
S
A
=
∑
i
=
1
r
(
X
i
∙
−
X
ˉ
)
2
S_A=\displaystyle\sum_{i=1}^{r}(X_{i\bullet}-\bar X)^2
S A = i = 1 ∑ r ( X i ∙ − X ˉ ) 2 误差平方和 (sum of squares of errors)
S
E
=
∑
i
=
1
r
∑
j
=
1
n
i
(
X
i
j
−
X
i
∙
)
2
S_E=\displaystyle\sum_{i=1}^{r}\sum_{j=1}^{n_i}(X_{ij}-X_{i\bullet})^2
S E = i = 1 ∑ r j = 1 ∑ n i ( X i j − X i ∙ ) 2
A
i
A_i
A i
X
ˉ
i
∙
=
1
n
i
∑
j
=
1
n
i
X
i
j
\bar X_{i\bullet}=\displaystyle\frac{1}{n_i}\sum_{j=1}^{n_i}X_{ij}
X ˉ i ∙ = n i 1 j = 1 ∑ n i X i j
S
T
=
S
A
+
S
E
S_T=S_A+S_E
S T = S A + S E
S
E
/
σ
2
∼
χ
2
(
n
−
r
)
S_E/σ^2∼ χ^2(n-r)
S E / σ 2 ∼ χ 2 ( n − r )
S
A
S_A
S A
S
E
S_E
S E
H
0
H_0
H 0
S
A
/
σ
2
∼
χ
2
(
r
−
1
)
,
S
A
/
(
r
−
1
)
S
E
/
(
n
−
r
)
∼
F
(
r
−
1
,
n
−
r
)
S_A/σ^2∼ χ^2(r-1),\dfrac{S_A/(r-1)}{S_E/(n-r)}∼ F(r-1,n-r)
S A / σ 2 ∼ χ 2 ( r − 1 ) , S E / ( n − r ) S A / ( r − 1 ) ∼ F ( r − 1 , n − r ) 单因素试验方差分析表
方差来源
平方和(SumSquare)
自由度(df)
均方(MS)
F
因素A(组间)
S
A
S_A
S A
r
−
1
r-1
r − 1
M
S
A
=
S
A
/
(
r
−
1
)
MS_A=S_A/(r-1)
M S A = S A / ( r − 1 )
M
S
A
/
M
S
E
MS_A/MS_E
M S A / M S E
误差(组内)
S
E
S_E
S E
n
−
r
n-r
n − r
M
S
E
=
S
E
/
(
n
−
r
)
MS_E=S_E/(n-r)
M S E = S E / ( n − r )
总和
S
T
S_T
S T
n
−
1
n-1
n − 1
当
F
⩾
F
α
(
r
−
1
,
n
−
r
)
F⩾ F_α(r-1,n-r)
F ⩾ F α ( r − 1 , n − r )
(4) 未知参数估计
H
0
H_0
H 0
E
(
S
E
n
−
r
)
=
σ
2
E(\dfrac{S_E}{n-r})=σ^2
E ( n − r S E ) = σ 2
σ
2
σ^2
σ 2
σ
^
2
=
S
E
/
(
n
−
r
)
=
M
S
E
\hat σ^2=S_E/(n-r)=MS_E
σ ^ 2 = S E / ( n − r ) = M S E
μ
i
μ_i
μ i
μ
^
i
=
X
ˉ
i
∙
(
i
=
1
,
2
,
⋯
,
r
)
\hat μ_i=\bar X_{i\bullet}\ (i=1,2,\cdots,r)
μ ^ i = X ˉ i ∙ ( i = 1 , 2 , ⋯ , r )
(5) 当拒绝
H
0
H_0
H 0
N
(
μ
i
,
σ
2
)
,
N
(
μ
j
,
σ
2
)
(
i
≠
j
)
N(μ_i,σ^2),N(μ_j,σ^2)\ (i\neq j)
N ( μ i , σ 2 ) , N ( μ j , σ 2 ) ( i = j )
μ
i
−
μ
j
μ_i-μ_j
μ i − μ j
E
(
X
ˉ
i
∙
−
X
ˉ
j
∙
)
=
μ
i
−
μ
j
,
D
(
X
ˉ
i
∙
−
X
ˉ
j
∙
)
=
σ
2
(
1
n
i
+
1
n
j
)
E(\bar X_{i\bullet}-\bar X_{j\bullet})=μ_i-μ_j,\ D(\bar X_{i\bullet}-\bar X_{j\bullet})=σ^2(\dfrac{1}{n_i}+\dfrac{1}{n_j})
E ( X ˉ i ∙ − X ˉ j ∙ ) = μ i − μ j , D ( X ˉ i ∙ − X ˉ j ∙ ) = σ 2 ( n i 1 + n j 1 )
X
ˉ
i
∙
−
X
ˉ
j
∙
\bar X_{i\bullet}-\bar X_{j\bullet}
X ˉ i ∙ − X ˉ j ∙
σ
^
2
=
S
E
/
(
n
−
r
)
=
M
S
E
\hat σ^2=S_E/(n-r)=MS_E
σ ^ 2 = S E / ( n − r ) = M S E
(
X
ˉ
i
∙
−
X
ˉ
j
∙
)
−
(
μ
i
−
μ
j
)
M
S
E
(
1
/
n
i
+
1
/
n
j
)
∼
t
(
n
−
r
)
\dfrac{(\bar X_{i\bullet}-\bar X_{j\bullet})-(μ_i-μ_j)}{\sqrt{MS_E(1/n_i+1/n_j)}}∼ t(n-r)
M S E ( 1 / n i + 1 / n j )
( X ˉ i ∙ − X ˉ j ∙ ) − ( μ i − μ j ) ∼ t ( n − r )
μ
i
−
μ
j
μ_i-μ_j
μ i − μ j
1
−
α
1-α
1 − α
(
(
X
ˉ
i
∙
−
X
ˉ
j
∙
)
±
t
α
/
2
(
n
−
r
)
M
S
E
(
1
/
n
i
+
1
/
n
j
)
)
((\bar X_{i\bullet}-\bar X_{j\bullet})± t_{α/2}(n-r)\sqrt{MS_E(1/n_i+1/n_j)})
( ( X ˉ i ∙ − X ˉ j ∙ ) ± t α / 2 ( n − r ) M S E ( 1 / n i + 1 / n j )
)
b. 检验假设
H
0
:
μ
i
=
μ
j
,
H
1
:
μ
i
≠
μ
j
H_0:μ_i=μ_j,\quad H_1:μ_i\neqμ_j
H 0 : μ i = μ j , H 1 : μ i = μ j
t
=
X
ˉ
i
∙
−
X
ˉ
j
∙
M
S
E
(
1
/
n
i
+
1
/
n
j
)
t=\dfrac{\bar X_{i\bullet}-\bar X_{j\bullet}}{\sqrt{MS_E(1/n_i+1/n_j)}}
t = M S E ( 1 / n i + 1 / n j )
X ˉ i ∙ − X ˉ j ∙
H
0
H_0
H 0
t
∼
t
(
n
−
r
)
t∼ t(n-r)
t ∼ t ( n − r )
W
=
{
∣
t
∣
⩾
t
α
/
2
(
n
−
r
)
}
W=\{|t|⩾ t_{α/2}(n-r)\}
W = { ∣ t ∣ ⩾ t α / 2 ( n − r ) }
方差分析的前提
双因素等重复试验的方差分析
A
A
A
r
r
r
A
1
,
A
2
,
⋯
,
A
r
A_1,A_2,\cdots,A_r
A 1 , A 2 , ⋯ , A r
B
B
B
s
s
s
B
1
,
B
2
,
⋯
,
B
s
B_1,B_2,\cdots,B_s
B 1 , B 2 , ⋯ , B s
(
A
i
,
B
j
)
(A_i,B_j)
( A i , B j )
t
(
t
⩾
2
)
t(t ⩾ 2)
t ( t ⩾ 2 )
因素A / 因素B
B
1
B_1
B 1
B
2
B_2
B 2
⋯
\cdots
⋯
B
s
B_s
B s
A
1
A_1
A 1
X
111
,
X
112
,
⋯
,
X
11
t
X_{111},X_{112},\cdots,X_{11t}
X 1 1 1 , X 1 1 2 , ⋯ , X 1 1 t
X
121
,
X
122
,
⋯
,
X
12
t
X_{121},X_{122},\cdots,X_{12t}
X 1 2 1 , X 1 2 2 , ⋯ , X 1 2 t
⋯
\cdots
⋯
X
1
s
1
,
X
1
s
2
,
⋯
,
X
1
s
t
X_{1s1},X_{1s2},\cdots,X_{1st}
X 1 s 1 , X 1 s 2 , ⋯ , X 1 s t
A
2
A_2
A 2
X
211
,
X
212
,
⋯
,
X
21
t
X_{211},X_{212},\cdots,X_{21t}
X 2 1 1 , X 2 1 2 , ⋯ , X 2 1 t
X
221
,
X
222
,
⋯
,
X
22
t
X_{221},X_{222},\cdots,X_{22t}
X 2 2 1 , X 2 2 2 , ⋯ , X 2 2 t
⋯
\cdots
⋯
X
2
s
1
,
X
2
s
2
,
⋯
,
X
2
s
t
X_{2s1},X_{2s2},\cdots,X_{2st}
X 2 s 1 , X 2 s 2 , ⋯ , X 2 s t
⋮
\vdots
⋮
⋮
\vdots
⋮
⋮
\vdots
⋮
⋮
\vdots
⋮
A
r
A_r
A r
X
r
11
,
X
r
12
,
⋯
,
X
r
1
t
X_{r11},X_{r12},\cdots,X_{r1t}
X r 1 1 , X r 1 2 , ⋯ , X r 1 t
X
r
21
,
X
r
22
,
⋯
,
X
r
2
t
X_{r21},X_{r22},\cdots,X_{r2t}
X r 2 1 , X r 2 2 , ⋯ , X r 2 t
⋯
\cdots
⋯
X
r
s
1
,
X
r
s
2
,
⋯
,
X
r
s
t
X_{rs1},X_{rs2},\cdots,X_{rst}
X r s 1 , X r s 2 , ⋯ , X r s t
并设
X
i
j
k
∼
N
(
μ
i
j
,
σ
2
)
X_{ijk}∼ N(μ_{ij},σ^2)
X i j k ∼ N ( μ i j , σ 2 )
{
X
i
j
k
=
μ
i
j
+
ϵ
i
j
k
ϵ
i
j
k
∼
N
(
0
,
σ
2
)
,
各
ϵ
i
j
k
独
立
i
=
1
,
2
,
⋯
,
r
;
j
=
1
,
2
,
⋯
,
s
;
k
=
1
,
2
,
⋯
,
t
\begin{cases} X_{ijk}=μ_{ij}+ϵ_{ijk} \\ ϵ_{ijk}∼ N(0,σ^2),\quad 各ϵ_{ijk}独立 \\ i=1,2,\cdots,r ;\quad j=1,2,\cdots,s ;\quad k=1,2,\cdots,t \\ \end{cases}
⎩ ⎪ ⎨ ⎪ ⎧ X i j k = μ i j + ϵ i j k ϵ i j k ∼ N ( 0 , σ 2 ) , 各 ϵ i j k 独 立 i = 1 , 2 , ⋯ , r ; j = 1 , 2 , ⋯ , s ; k = 1 , 2 , ⋯ , t
μ
=
1
r
s
∑
i
=
1
r
∑
j
=
1
s
μ
i
j
μ
i
∙
=
1
s
∑
j
=
1
s
μ
i
j
(
i
=
1
,
2
,
⋯
,
r
)
μ
∙
j
=
1
r
∑
i
=
1
r
μ
i
j
(
j
=
1
,
2
,
⋯
,
s
)
α
i
=
μ
i
∙
−
μ
(
i
=
1
,
2
,
⋯
,
r
)
β
j
=
μ
∙
j
−
μ
(
j
=
1
,
2
,
⋯
,
s
)
\displaystyle μ=\frac{1}{rs}\sum_{i=1}^{r}\sum_{j=1}^{s}μ_{ij} \\ μ_{i\bullet}=\frac{1}{s}\sum_{j=1}^{s}μ_{ij} \quad(i=1,2,\cdots,r)\\ μ_{\bullet j}=\frac{1}{r}\sum_{i=1}^{r}μ_{ij} \quad(j=1,2,\cdots,s)\\ α_i=μ_{i\bullet}-μ \quad(i=1,2,\cdots,r)\\ β_j=μ_{\bullet j}-μ \quad(j=1,2,\cdots,s)
μ = r s 1 i = 1 ∑ r j = 1 ∑ s μ i j μ i ∙ = s 1 j = 1 ∑ s μ i j ( i = 1 , 2 , ⋯ , r ) μ ∙ j = r 1 i = 1 ∑ r μ i j ( j = 1 , 2 , ⋯ , s ) α i = μ i ∙ − μ ( i = 1 , 2 , ⋯ , r ) β j = μ ∙ j − μ ( j = 1 , 2 , ⋯ , s )
∑
i
=
1
r
α
i
=
0
,
∑
j
=
1
s
β
j
=
0
\displaystyle\sum_{i=1}^{r}α_i=0,\quad\sum_{j=1}^{s}β_j=0
i = 1 ∑ r α i = 0 , j = 1 ∑ s β j = 0
μ
μ
μ 总平均 ,
α
i
α_i
α i
A
i
A_i
A i 效应 ,
β
j
β_j
β j
B
j
B_j
B j 效应 ,这样可将
μ
i
j
μ_{ij}
μ i j
μ
i
j
=
μ
+
α
i
+
β
j
+
γ
i
j
μ_{ij}=μ+α_i+β_j+γ_{ij}
μ i j = μ + α i + β j + γ i j
γ
i
j
=
μ
i
j
−
μ
i
∙
−
μ
∙
j
+
μ
γ_{ij}=μ_{ij}-μ_{i\bullet}-μ_{\bullet j}+μ
γ i j = μ i j − μ i ∙ − μ ∙ j + μ
A
i
A_i
A i
β
j
β_j
β j 交互效应 (interaction)。这是有两个因素联合起来搭配作用而引起的。
∑
i
=
1
r
γ
i
j
=
0
,
∑
j
=
1
s
γ
i
j
=
0
\displaystyle\sum_{i=1}^{r}γ_{ij}=0,\quad\sum_{j=1}^{s}γ_{ij}=0
i = 1 ∑ r γ i j = 0 , j = 1 ∑ s γ i j = 0
{
X
i
j
=
μ
+
α
i
+
β
j
+
γ
i
j
+
ϵ
i
j
k
ϵ
i
j
∼
N
(
0
,
σ
2
)
,
各
ϵ
i
j
独
立
i
=
1
,
2
,
⋯
,
r
;
j
=
1
,
2
,
⋯
,
s
;
k
=
1
,
2
,
⋯
,
t
∑
i
=
1
r
α
i
=
0
,
∑
j
=
1
s
β
j
=
0
,
∑
i
=
1
r
γ
i
j
=
0
,
∑
j
=
1
s
γ
i
j
=
0
\begin{cases} X_{ij}=μ+α_i+β_j+γ_{ij}+ϵ_{ijk} \\ ϵ_{ij}∼ N(0,σ^2),\quad 各ϵ_{ij}独立 \\ i=1,2,\cdots,r ;\quad j=1,2,\cdots,s ;\quad k=1,2,\cdots,t \\ \displaystyle\sum_{i=1}^{r}α_i=0,\quad\sum_{j=1}^{s}β_j=0 ,\quad\sum_{i=1}^{r}γ_{ij}=0,\quad\sum_{j=1}^{s}γ_{ij}=0 \end{cases}
⎩ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎧ X i j = μ + α i + β j + γ i j + ϵ i j k ϵ i j ∼ N ( 0 , σ 2 ) , 各 ϵ i j 独 立 i = 1 , 2 , ⋯ , r ; j = 1 , 2 , ⋯ , s ; k = 1 , 2 , ⋯ , t i = 1 ∑ r α i = 0 , j = 1 ∑ s β j = 0 , i = 1 ∑ r γ i j = 0 , j = 1 ∑ s γ i j = 0
μ
,
α
i
,
β
j
,
γ
i
j
μ,α_i,β_j,γ_{ij}
μ , α i , β j , γ i j
H
01
:
α
1
=
α
2
=
⋯
=
α
r
=
0
,
H
11
:
α
1
,
α
2
,
⋯
,
α
r
H_{01}:α_1=α_2=\cdots=α_r=0,\quad H_{11}:α_1,α_2,\cdots,α_r
H 0 1 : α 1 = α 2 = ⋯ = α r = 0 , H 1 1 : α 1 , α 2 , ⋯ , α r
H
02
:
β
1
=
β
2
=
⋯
=
β
s
=
0
,
H
12
:
β
1
,
β
2
,
⋯
,
β
s
H_{02}:β_1=β_2=\cdots=β_s=0,\quad H_{12}:β_1,β_2,\cdots,β_s
H 0 2 : β 1 = β 2 = ⋯ = β s = 0 , H 1 2 : β 1 , β 2 , ⋯ , β s
H
03
:
γ
i
j
=
0
,
H
13
:
γ
i
j
H_{03}:γ_{ij}=0,\quad H_{13}:γ_{ij}
H 0 3 : γ i j = 0 , H 1 3 : γ i j
与单因素类似,这些问题也建立在平方和分解上,先引入
X
ˉ
=
1
r
s
t
∑
i
=
1
r
∑
j
=
1
s
∑
k
=
1
t
X
i
j
k
X
ˉ
i
j
∙
=
1
t
∑
k
=
1
t
X
i
j
k
(
i
=
1
,
2
,
⋯
,
r
;
j
=
1
,
2
,
⋯
,
s
)
X
ˉ
i
∙
∙
=
1
s
t
∑
j
=
1
s
∑
k
=
1
t
X
i
j
k
(
i
=
1
,
2
,
⋯
,
r
)
X
ˉ
∙
j
∙
=
1
r
t
∑
i
=
1
r
∑
k
=
1
t
X
i
j
k
(
j
=
1
,
2
,
⋯
,
s
)
\displaystyle \bar X=\frac{1}{rst}\sum_{i=1}^{r}\sum_{j=1}^{s}\sum_{k=1}^{t}X_{ijk} \\ \bar X_{ij\bullet}=\frac{1}{t}\sum_{k=1}^{t}X_{ijk} \quad(i=1,2,\cdots,r ;\quad j=1,2,\cdots,s)\\ \bar X_{i\bullet\bullet}=\frac{1}{st}\sum_{j=1}^{s}\sum_{k=1}^{t}X_{ijk} \quad(i=1,2,\cdots,r)\\ \bar X_{\bullet j\bullet}=\frac{1}{rt}\sum_{i=1}^{r}\sum_{k=1}^{t}X_{ijk} \quad(j=1,2,\cdots,s)
X ˉ = r s t 1 i = 1 ∑ r j = 1 ∑ s k = 1 ∑ t X i j k X ˉ i j ∙ = t 1 k = 1 ∑ t X i j k ( i = 1 , 2 , ⋯ , r ; j = 1 , 2 , ⋯ , s ) X ˉ i ∙ ∙ = s t 1 j = 1 ∑ s k = 1 ∑ t X i j k ( i = 1 , 2 , ⋯ , r ) X ˉ ∙ j ∙ = r t 1 i = 1 ∑ r k = 1 ∑ t X i j k ( j = 1 , 2 , ⋯ , s )
总偏差平方和
S
T
=
∑
i
=
1
r
∑
j
=
1
s
∑
k
=
1
t
(
X
i
j
k
−
X
ˉ
)
2
\displaystyle S_T=\sum_{i=1}^{r}\sum_{j=1}^{s}\sum_{k=1}^{t}(X_{ijk}-\bar X)^2
S T = i = 1 ∑ r j = 1 ∑ s k = 1 ∑ t ( X i j k − X ˉ ) 2
S
T
=
S
E
+
S
A
+
S
B
+
S
A
×
B
S_T=S_E+S_A+S_B+S_{A× B}
S T = S E + S A + S B + S A × B
S
E
=
∑
i
=
1
r
∑
j
=
1
s
∑
k
=
1
t
(
X
i
j
k
−
X
ˉ
i
j
∙
)
2
S
A
=
s
t
∑
i
=
1
r
(
X
ˉ
i
∙
∙
−
X
ˉ
)
2
S
B
=
r
t
∑
j
=
1
s
(
X
ˉ
∙
j
∙
−
X
ˉ
)
2
S
A
×
B
=
t
∑
i
=
1
r
∑
j
=
1
s
(
X
ˉ
i
j
∙
−
X
ˉ
i
∙
∙
−
X
ˉ
∙
j
∙
+
X
ˉ
)
2
\displaystyle S_E=\displaystyle\sum_{i=1}^{r}\sum_{j=1}^{s}\sum_{k=1}^{t}( X_{ijk}-\bar X_{ij\bullet})^2 \\ S_A=st\sum_{i=1}^{r}(\bar X_{i\bullet\bullet}-\bar X)^2 \\ S_B=rt\sum_{j=1}^{s}(\bar X_{\bullet j\bullet}-\bar X)^2 \\ S_{A× B}=t\sum_{i=1}^{r}\sum_{j=1}^{s}(\bar X_{ij\bullet}-\bar X_{i\bullet\bullet}-\bar X_{\bullet j\bullet}+\bar X)^2
S E = i = 1 ∑ r j = 1 ∑ s k = 1 ∑ t ( X i j k − X ˉ i j ∙ ) 2 S A = s t i = 1 ∑ r ( X ˉ i ∙ ∙ − X ˉ ) 2 S B = r t j = 1 ∑ s ( X ˉ ∙ j ∙ − X ˉ ) 2 S A × B = t i = 1 ∑ r j = 1 ∑ s ( X ˉ i j ∙ − X ˉ i ∙ ∙ − X ˉ ∙ j ∙ + X ˉ ) 2
S
E
S_E
S E 误差平方和 ,
S
A
,
S
B
S_A,S_B
S A , S B
A
,
B
A,B
A , B 效应平方和 ,
S
A
×
B
S_{A× B}
S A × B
A
,
B
A,B
A , B 交互效应平方和 。
且可以证明下列
E
(
S
E
r
s
(
t
−
1
)
)
=
σ
2
E
(
S
A
r
−
1
)
=
σ
2
+
s
t
r
−
1
∑
i
=
1
r
α
i
2
E
(
S
B
s
−
1
)
=
σ
2
+
r
t
s
−
1
∑
j
=
1
s
β
j
2
E
(
S
A
×
B
(
r
−
1
)
(
s
−
1
)
)
=
σ
2
+
t
(
r
−
1
)
(
s
−
1
)
∑
i
=
1
r
∑
j
=
1
s
γ
i
j
2
\displaystyle E\left(\dfrac{S_E}{rs(t-1)}\right)=σ^2\\ E\left(\dfrac{S_A}{r-1}\right)=σ^2+\dfrac{st}{r-1}\sum_{i=1}^{r}α_i^2 \\ E\left(\dfrac{S_B}{s-1}\right)=σ^2+\dfrac{rt}{s-1}\sum_{j=1}^{s}β_j^2 \\ E\left(\dfrac{S_{A× B}}{(r-1)(s-1)}\right)=σ^2+\dfrac{t}{(r-1)(s-1)}\sum_{i=1}^{r}\sum_{j=1}^{s}γ_{ij}^2
E ( r s ( t − 1 ) S E ) = σ 2 E ( r − 1 S A ) = σ 2 + r − 1 s t i = 1 ∑ r α i 2 E ( s − 1 S B ) = σ 2 + s − 1 r t j = 1 ∑ s β j 2 E ( ( r − 1 ) ( s − 1 ) S A × B ) = σ 2 + ( r − 1 ) ( s − 1 ) t i = 1 ∑ r j = 1 ∑ s γ i j 2
双因素试验方差分析表
方差来源
平方和 SumSquare
自由度 df
均方 MS
F
因素A(组间)
S
A
S_A
S A
r
−
1
r-1
r − 1
M
S
A
=
S
A
(
r
−
1
)
MS_A=\dfrac{S_A}{(r-1)}
M S A = ( r − 1 ) S A
F
A
=
M
S
A
/
M
S
E
F_A=MS_A/MS_E
F A = M S A / M S E
因素B(组间)
S
B
S_B
S B
s
−
1
s-1
s − 1
M
S
B
=
S
B
(
s
−
1
)
MS_B=\dfrac{S_B}{(s-1)}
M S B = ( s − 1 ) S B
F
B
=
M
S
B
/
M
S
E
F_B=MS_B/MS_E
F B = M S B / M S E
交互作用
S
A
×
B
S_{A× B}
S A × B
(
r
−
1
)
(
s
−
1
)
(r-1)(s-1)
( r − 1 ) ( s − 1 )
M
S
A
×
B
=
S
A
(
r
−
1
)
(
s
−
1
)
MS_{A× B}=\dfrac{S_A}{(r-1)(s-1)}
M S A × B = ( r − 1 ) ( s − 1 ) S A
F
A
×
B
=
M
S
A
×
B
/
M
S
E
F_{A× B}=MS_{A× B}/MS_E
F A × B = M S A × B / M S E
误差 (组内)
S
E
S_E
S E
r
s
(
t
−
1
)
rs(t-1)
r s ( t − 1 )
M
S
E
=
S
E
r
s
(
t
−
1
)
MS_E=\dfrac{S_E}{rs(t-1)}
M S E = r s ( t − 1 ) S E
总和
S
T
S_T
S T
r
s
t
−
1
rst-1
r s t − 1
当
H
01
H_{01}
H 0 1
F
A
∼
F
(
r
−
1
,
r
s
(
t
−
1
)
)
F
B
∼
F
(
s
−
1
,
r
s
(
t
−
1
)
)
F
A
×
B
∼
F
(
(
r
−
1
)
(
s
−
1
)
,
r
s
(
t
−
1
)
)
F_A∼ F(r-1,rs(t-1)) \\ F_B∼ F(s-1,rs(t-1)) \\ F_{A× B}∼ F((r-1)(s-1),rs(t-1))
F A ∼ F ( r − 1 , r s ( t − 1 ) ) F B ∼ F ( s − 1 , r s ( t − 1 ) ) F A × B ∼ F ( ( r − 1 ) ( s − 1 ) , r s ( t − 1 ) )
假设
H
01
H_{01}
H 0 1
F
A
⩾
F
α
(
r
−
1
,
r
s
(
t
−
1
)
)
F_A ⩾ F_α(r-1,rs(t-1))
F A ⩾ F α ( r − 1 , r s ( t − 1 ) )
H
02
H_{02}
H 0 2
F
B
⩾
F
α
(
s
−
1
,
r
s
(
t
−
1
)
)
F_B ⩾ F_α(s-1,rs(t-1))
F B ⩾ F α ( s − 1 , r s ( t − 1 ) )
H
03
H_{03}
H 0 3
F
A
×
B
⩾
F
α
(
(
r
−
1
)
(
s
−
1
)
,
r
s
(
t
−
1
)
)
F_{A× B} ⩾ F_α((r-1)(s-1),rs(t-1))
F A × B ⩾ F α ( ( r − 1 ) ( s − 1 ) , r s ( t − 1 ) )
双因素无重复试验的方差分析
(
A
i
,
B
j
)
(A_i,B_j)
( A i , B j )
k
=
1
k=1
k = 1
A
,
B
A,B
A , B
在客观世界中,普遍存在着变量之间的额关系。变量之间的关系一般可分为确定性关系和相关性关系。
确定性关系 (deterministic):
h
h
h
t
t
t
h
=
1
2
g
t
2
h=\frac{1}{2}gt^2
h = 2 1 g t 2
相关性关系 (correlation):
x
x
x
Y
Y
Y
x
x
x
Y
Y
Y
Y
Y
Y
x
x
x
设随机变量
Y
Y
Y
x
x
x
x
x
x
Y
Y
Y
C
1
,
C
2
C_1,C_2
C 1 , C 2
x
1
,
x
2
x_1,x_2
x 1 , x 2
Y
Y
Y
F
(
y
∣
x
)
F(y|x)
F ( y ∣ x )
Y
Y
Y
E
(
Y
)
=
μ
(
x
)
E(Y)=μ(x)
E ( Y ) = μ ( x )
x
x
x
Y
Y
Y
x
x
x 回归函数 (regression function)。同时以回归函数作为
Y
Y
Y
E
[
Y
−
μ
(
x
)
]
2
E[Y-μ(x)]^2
E [ Y − μ ( x ) ] 2
对从整体
(
x
,
Y
)
(x,Y)
( x , Y )
(
x
1
,
Y
1
)
,
(
x
2
,
Y
2
)
,
⋯
,
(
x
n
,
Y
n
)
(x_1,Y_1),(x_2,Y_2),\cdots,(x_n,Y_n)
( x 1 , Y 1 ) , ( x 2 , Y 2 ) , ⋯ , ( x n , Y n )
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
⋯
,
(
x
n
,
y
n
)
(x_1,y_1),(x_2,y_2),\cdots,(x_n,y_n)
( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x n , y n )
μ
(
x
)
μ(x)
μ ( x )
μ
(
x
)
=
a
+
b
x
μ(x)=a+bx
μ ( x ) = a + b x
Y
∼
N
(
a
+
b
x
,
σ
2
)
Y∼ N(a+bx,σ^2)
Y ∼ N ( a + b x , σ 2 )
ϵ
=
Y
−
(
a
+
b
x
)
ϵ=Y-(a+bx)
ϵ = Y − ( a + b x )
Y
=
a
+
b
x
+
ϵ
,
ϵ
∼
N
(
0
,
σ
2
)
Y=a+bx+ϵ,\quad ϵ∼ N(0,σ^2)
Y = a + b x + ϵ , ϵ ∼ N ( 0 , σ 2 )
a
,
b
,
σ
2
a,b,σ^2
a , b , σ 2
x
x
x
Y
Y
Y
ϵ
ϵ
ϵ
{
a
,
b
的
估
计
σ
2
的
估
计
\begin{cases} a,b 的估计 \\ σ^2 的估计 \end{cases}
{ a , b 的 估 计 σ 2 的 估 计
{
线
性
假
设
的
显
著
性
检
验
回
归
系
数
b
的
置
信
区
间
Y
的
点
预
测
\begin{cases} 线性假设的显著性检验 \\ 回归系数b的置信区间 \\ Y 的点预测 \end{cases}
⎩ ⎪ ⎨ ⎪ ⎧ 线 性 假 设 的 显 著 性 检 验 回 归 系 数 b 的 置 信 区 间 Y 的 点 预 测
(1)
a
,
b
a,b
a , b
Y
i
=
a
+
b
x
i
+
ϵ
,
ϵ
i
∼
N
(
0
,
σ
2
)
Y_i=a+bx_i+ϵ,\quad ϵ_i∼ N(0,σ^2)
Y i = a + b x i + ϵ , ϵ i ∼ N ( 0 , σ 2 )
Q
(
a
,
b
)
=
∑
i
=
1
n
(
y
i
−
a
−
b
x
i
)
2
Q(a,b)=\displaystyle\sum_{i=1}^{n}(y_i-a-bx_i)^2
Q ( a , b ) = i = 1 ∑ n ( y i − a − b x i ) 2
Y
Y
Y
Y
Y
Y
y
i
y_i
y i
a
+
b
x
i
a+bx_i
a + b x i 最小二乘法 (least square method)。
a
^
,
b
^
\hat a,\hat b
a ^ , b ^
Q
(
a
^
,
b
^
)
=
min
a
,
b
Q
(
a
,
b
)
\displaystyle Q(\hat a,\hat b)=\min_{a,b}Q(a,b)
Q ( a ^ , b ^ ) = a , b min Q ( a , b )
∂
Q
∂
a
=
0
,
∂
Q
∂
b
=
0
\dfrac{∂ Q}{∂ a}=0,\dfrac{∂ Q}{∂ b}=0
∂ a ∂ Q = 0 , ∂ b ∂ Q = 0
{
n
a
+
(
∑
i
=
1
n
x
i
)
b
=
∑
i
=
1
n
y
i
(
∑
i
=
1
n
x
i
)
a
+
(
∑
i
=
1
n
x
i
2
)
b
=
∑
i
=
1
n
x
i
y
i
\begin{cases} \displaystyle na+(\sum_{i=1}^{n}x_i)b=\sum_{i=1}^{n}y_i \\ \displaystyle (\sum_{i=1}^{n}x_i)a+(\sum_{i=1}^{n}x_i^2)b=\sum_{i=1}^{n}x_iy_i \end{cases}
⎩ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎧ n a + ( i = 1 ∑ n x i ) b = i = 1 ∑ n y i ( i = 1 ∑ n x i ) a + ( i = 1 ∑ n x i 2 ) b = i = 1 ∑ n x i y i 正规方程组 (normal system of equations)。由于
x
i
x_i
x i
{
b
^
=
S
x
y
S
x
x
a
^
=
y
ˉ
−
b
^
x
ˉ
\begin{cases} \hat b=\dfrac{S_{xy}}{S_{xx}} \\ \hat a=\bar y-\hat b\bar x \end{cases}
⎩ ⎨ ⎧ b ^ = S x x S x y a ^ = y ˉ − b ^ x ˉ
S
x
x
=
∑
i
=
1
n
(
x
i
−
x
ˉ
)
2
S
y
y
=
∑
i
=
1
n
(
y
i
−
y
ˉ
)
2
S
x
y
=
∑
i
=
1
n
(
x
i
−
x
ˉ
)
(
y
i
−
y
ˉ
)
x
ˉ
=
1
n
∑
i
=
1
n
x
i
,
y
ˉ
=
1
n
∑
i
=
1
n
y
i
\displaystyle S_{xx}=\sum_{i=1}^{n}(x_i-\bar x)^2 \\ S_{yy}=\sum_{i=1}^{n}(y_i-\bar y)^2 \\ S_{xy}=\sum_{i=1}^{n}(x_i-\bar x)(y_i-\bar y) \\ \bar x=\dfrac{1}{n}\sum_{i=1}^{n}x_i,\quad\bar y=\dfrac{1}{n}\sum_{i=1}^{n}y_i
S x x = i = 1 ∑ n ( x i − x ˉ ) 2 S y y = i = 1 ∑ n ( y i − y ˉ ) 2 S x y = i = 1 ∑ n ( x i − x ˉ ) ( y i − y ˉ ) x ˉ = n 1 i = 1 ∑ n x i , y ˉ = n 1 i = 1 ∑ n y i 经验回归方程 (Empirical regression equation)
y
^
=
a
^
+
b
^
x
\hat y=\hat a+\hat bx
y ^ = a ^ + b ^ x
(2)
σ
2
σ^2
σ 2
e
i
=
y
i
−
y
^
e_i=y_i-\hat y
e i = y i − y ^ 残差 (residual),注意到
σ
2
=
D
(
ϵ
)
+
E
(
ϵ
2
)
=
E
(
ϵ
2
)
σ^2=D(ϵ)+E(ϵ^2)=E(ϵ^2)
σ 2 = D ( ϵ ) + E ( ϵ 2 ) = E ( ϵ 2 ) 残差平方和 (residual sum of squares)
Q
e
=
∑
i
=
1
n
(
y
i
−
y
^
i
)
2
\displaystyle Q_e=\sum_{i=1}^{n}(y_i-\hat y_i)^2
Q e = i = 1 ∑ n ( y i − y ^ i ) 2
σ
2
σ^2
σ 2
Q
e
/
σ
2
∼
χ
2
(
n
−
2
)
Q_e/σ^2∼ χ^2(n-2)
Q e / σ 2 ∼ χ 2 ( n − 2 )
E
(
Q
e
)
=
(
n
−
2
)
σ
2
E(Q_e)=(n-2)σ^2
E ( Q e ) = ( n − 2 ) σ 2
σ
^
2
=
Q
e
/
(
n
−
2
)
\hat σ^2=Q_e/(n-2)
σ ^ 2 = Q e / ( n − 2 )
σ
2
σ^2
σ 2
(3) 线性假设的显著性检验
H
0
:
b
=
0
,
H
1
:
b
≠
0
H_0:b=0,\quad H_1:b\neq0
H 0 : b = 0 , H 1 : b = 0
若原假设被拒绝,说明回归效果是显著的。否则,若接受原假设,说明 Y与x不是线性关系,回归方程无意义。回归效果不显著的原因可能有以下几种:
我们用 t 检验法来检验,可证明
b
^
∼
N
(
b
,
σ
2
/
S
x
x
)
⟹
(
n
−
2
)
σ
^
2
/
σ
2
=
Q
e
/
σ
2
∼
χ
2
(
n
−
2
)
\hat b∼ N(b,σ^2/S_{xx}) \implies (n-2)\hat σ^2/σ^2=Q_e/σ^2∼ χ^2(n-2)
b ^ ∼ N ( b , σ 2 / S x x ) ⟹ ( n − 2 ) σ ^ 2 / σ 2 = Q e / σ 2 ∼ χ 2 ( n − 2 )
b
^
\hat b
b ^
Q
e
Q_e
Q e
(
b
^
−
b
)
S
x
x
/
σ
^
∼
t
(
n
−
2
)
(\hat b-b)\sqrt{S_{xx}}/\hat σ∼ t(n-2)
( b ^ − b ) S x x
/ σ ^ ∼ t ( n − 2 )
H
0
H_0
H 0
t
=
b
^
S
x
x
/
σ
^
∼
t
(
n
−
2
)
t=\hat b\sqrt{S_{xx}}/\hat σ∼ t(n-2)
t = b ^ S x x
/ σ ^ ∼ t ( n − 2 )
E
(
b
^
)
=
b
=
0
E(\hat b)=b=0
E ( b ^ ) = b = 0
H
0
H_0
H 0
∣
t
∣
⩾
t
α
/
2
(
n
−
2
)
|t|⩾ t_{α/2}(n-2)
∣ t ∣ ⩾ t α / 2 ( n − 2 )
(4) 回归系数(coefficient)
b
b
b
b
b
b
1
−
α
1-α
1 − α
b
^
±
t
α
/
2
(
n
−
2
)
σ
^
/
S
x
x
\hat b± t_{α/2}(n-2)\hat σ/\sqrt{S_{xx}}
b ^ ± t α / 2 ( n − 2 ) σ ^ / S x x
(5) 回归函数
Y
=
a
+
b
x
Y=a+bx
Y = a + b x
Y
^
0
=
a
^
+
b
^
x
0
\hat Y_0=\hat a+\hat bx_0
Y ^ 0 = a ^ + b ^ x 0
E
(
Y
^
0
)
=
a
+
b
x
0
E(\hat Y_0)=a+bx_0
E ( Y ^ 0 ) = a + b x 0
Y
^
0
−
(
a
+
b
x
0
)
σ
^
1
/
n
+
(
x
0
−
x
ˉ
)
2
/
S
x
x
∼
t
(
n
−
2
)
\dfrac{\hat Y_0-(a+bx_0)}{\hat σ\sqrt{1/n+(x_0-\bar x)^2/S_{xx}}}∼ t(n-2)
σ ^ 1 / n + ( x 0 − x ˉ ) 2 / S x x
Y ^ 0 − ( a + b x 0 ) ∼ t ( n − 2 )
a
+
b
x
0
a+bx_0
a + b x 0
(
Y
^
0
±
t
α
/
2
(
n
−
2
)
σ
^
1
n
+
(
x
0
−
x
ˉ
)
2
S
x
x
)
\left(\hat Y_0± t_{α/2}(n-2)\hat σ\sqrt{\dfrac{1}{n}+\dfrac{(x_0-\bar x)^2}{S_{xx}}}\right)
( Y ^ 0 ± t α / 2 ( n − 2 ) σ ^ n 1 + S x x ( x 0 − x ˉ ) 2
)
x
0
x_0
x 0
∣
x
0
−
x
ˉ
∣
|x_0-\bar x|
∣ x 0 − x ˉ ∣
(6)
Y
Y
Y
Y
0
Y_0
Y 0
Y
0
=
a
+
b
x
0
+
ϵ
0
,
ϵ
0
∼
N
(
0
,
σ
2
)
Y_0=a+bx_0+ϵ_0,\quad ϵ_0∼ N(0,σ^2)
Y 0 = a + b x 0 + ϵ 0 , ϵ 0 ∼ N ( 0 , σ 2 )
⟹
Y
^
0
=
Y
ˉ
+
b
^
(
x
0
−
x
ˉ
)
\implies \hat Y_0=\bar Y+\hat b(x_0-\bar x)
⟹ Y ^ 0 = Y ˉ + b ^ ( x 0 − x ˉ )
⟹
Y
^
0
−
(
a
+
b
x
0
)
σ
^
1
+
1
/
n
+
(
x
0
−
x
ˉ
)
2
/
S
x
x
∼
t
(
n
−
2
)
\implies\dfrac{\hat Y_0-(a+bx_0)}{\hat σ\sqrt{1+1/n+(x_0-\bar x)^2/S_{xx}}}∼ t(n-2)
⟹ σ ^ 1 + 1 / n + ( x 0 − x ˉ ) 2 / S x x
Y ^ 0 − ( a + b x 0 ) ∼ t ( n − 2 )
Y
0
Y_0
Y 0 预测区间 (prediction interval)
(
Y
^
0
±
t
α
/
2
(
n
−
2
)
σ
^
1
+
1
n
+
(
x
0
−
x
ˉ
)
2
S
x
x
)
\left(\hat Y_0± t_{α/2}(n-2)\hat σ\sqrt{1+\dfrac{1}{n}+\dfrac{(x_0-\bar x)^2}{S_{xx}}}\right)
( Y ^ 0 ± t α / 2 ( n − 2 ) σ ^ 1 + n 1 + S x x ( x 0 − x ˉ ) 2
)
回归分析表
Coef.
Std. error
t Stat
P value
Lower 95%
Upper 95%
I
n
t
e
r
c
e
p
t
\rm Intercept
I n t e r c e p t
a
^
\hat a
a ^
X
\rm X
X
b
^
\hat b
b ^
可化为一元线性回归的例子
方程
条件
转化
Y
=
a
e
b
x
⋅
ϵ
Y=ae^{bx}\cdot ϵ
Y = a e b x ⋅ ϵ
ln
ϵ
∼
N
(
0
,
σ
2
)
\ln ϵ∼ N(0,σ^2)
ln ϵ ∼ N ( 0 , σ 2 )
ln
Y
=
ln
a
+
ln
b
x
+
ln
ϵ
\ln Y=\ln a+ \ln bx+\ln ϵ
ln Y = ln a + ln b x + ln ϵ
Y
=
a
x
b
⋅
ϵ
Y=ax^{b}\cdot ϵ
Y = a x b ⋅ ϵ
ln
ϵ
∼
N
(
0
,
σ
2
)
\ln ϵ∼ N(0,σ^2)
ln ϵ ∼ N ( 0 , σ 2 )
ln
Y
=
ln
a
+
b
ln
x
+
ln
ϵ
\ln Y=\ln a+ b\ln x+\ln ϵ
ln Y = ln a + b ln x + ln ϵ
Y
=
a
+
b
h
(
x
)
+
ϵ
Y=a+bh(x)+ ϵ
Y = a + b h ( x ) + ϵ
ϵ
∼
N
(
0
,
σ
2
)
ϵ∼ N(0,σ^2)
ϵ ∼ N ( 0 , σ 2 )
Y
=
a
+
b
x
′
+
ϵ
,
x
′
=
h
(
x
)
Y=a+bx'+ ϵ,\quad x'=h(x)
Y = a + b x ′ + ϵ , x ′ = h ( x )
如果回归函数
μ
(
x
;
θ
1
,
θ
2
,
⋯
,
θ
p
)
μ(x;θ_1,θ_2,\cdots,θ_p)
μ ( x ; θ 1 , θ 2 , ⋯ , θ p )
θ
1
,
θ
2
,
⋯
,
θ
p
θ_1,θ_2,\cdots,θ_p
θ 1 , θ 2 , ⋯ , θ p
x
x
x 线性回归模型 (linear regressive model),若为非线性函数则称非线性回归模型 (non-linear regressive model),但是他们都能转化为线性回归模型。
Y
=
θ
1
e
θ
1
x
⋅
ϵ
,
ϵ
∼
N
(
0
,
σ
2
)
Y=θ_1e^{θ_1x}\cdot ϵ,\quad ϵ∼ N(0,σ^2)
Y = θ 1 e θ 1 x ⋅ ϵ , ϵ ∼ N ( 0 , σ 2 ) 本质的非线性回归模型 。又如
Y
=
(
θ
1
+
θ
2
x
+
θ
3
x
2
)
−
1
+
ϵ
(
H
o
l
i
d
a
y
模
型
)
Y
=
θ
1
1
+
e
x
p
(
θ
2
+
θ
3
x
)
+
ϵ
(
L
o
g
i
s
t
i
c
模
型
)
Y=(θ_1+θ_2x+θ_3x^2)^{-1}+ϵ\quad(Holiday 模型)\\ Y=\dfrac{θ_1}{1+exp(θ_2+θ_3^x)}+ϵ\quad(Logistic 模型)
Y = ( θ 1 + θ 2 x + θ 3 x 2 ) − 1 + ϵ ( H o l i d a y 模 型 ) Y = 1 + e x p ( θ 2 + θ 3 x ) θ 1 + ϵ ( L o g i s t i c 模 型 )
在实际问题中,随机变量
Y
Y
Y
x
1
,
x
2
,
⋯
,
x
p
(
p
>
1
)
x_1,x_2,\cdots,x_p(p>1)
x 1 , x 2 , ⋯ , x p ( p > 1 )
Y
Y
Y
μ
(
x
1
,
x
2
,
⋯
,
x
p
)
μ(x_1,x_2,\cdots,x_p)
μ ( x 1 , x 2 , ⋯ , x p )
Y
Y
Y
x
x
x
Y
=
b
0
+
b
1
x
1
+
b
2
x
2
=
⋯
+
b
p
x
p
+
ϵ
,
ϵ
∼
N
(
0
,
σ
2
)
Y=b_0+b_1x_1+b_2x_2=\cdots+b_px_p+ϵ,\quad ϵ∼ N(0,σ^2)
Y = b 0 + b 1 x 1 + b 2 x 2 = ⋯ + b p x p + ϵ , ϵ ∼ N ( 0 , σ 2 )
b
0
,
b
1
,
b
2
,
⋯
,
b
p
b_0,b_1,b_2,\cdots,b_p
b 0 , b 1 , b 2 , ⋯ , b p
x
1
,
x
2
,
⋯
,
x
p
x_1,x_2,\cdots,x_p
x 1 , x 2 , ⋯ , x p
(
x
11
,
x
12
,
⋯
,
x
1
p
)
,
⋯
,
(
x
n
1
,
x
n
2
,
⋯
,
x
n
p
)
(x_{11},x_{12},\cdots,x_{1p}),\cdots,(x_{n1},x_{n2},\cdots,x_{np})
( x 1 1 , x 1 2 , ⋯ , x 1 p ) , ⋯ , ( x n 1 , x n 2 , ⋯ , x n p )
Q
(
b
0
,
b
1
,
b
2
,
⋯
,
b
p
)
=
∑
i
=
1
n
[
y
i
−
(
b
0
+
b
1
x
1
+
b
2
x
2
=
⋯
+
b
p
x
p
)
]
2
Q(b_0,b_1,b_2,\cdots,b_p)=\displaystyle\sum_{i=1}^{n}[y_i-(b_0+b_1x_1+b_2x_2=\cdots+b_px_p)]^2
Q ( b 0 , b 1 , b 2 , ⋯ , b p ) = i = 1 ∑ n [ y i − ( b 0 + b 1 x 1 + b 2 x 2 = ⋯ + b p x p ) ] 2
Q
(
b
^
0
,
b
^
1
,
b
^
2
,
⋯
,
b
^
p
)
=
min
Q
(
b
0
,
b
1
,
b
2
,
⋯
,
b
p
)
\displaystyle Q(\hat b_0,\hat b_1,\hat b_2,\cdots,\hat b_p)=\min Q(b_0,b_1,b_2,\cdots,b_p )
Q ( b ^ 0 , b ^ 1 , b ^ 2 , ⋯ , b ^ p ) = min Q ( b 0 , b 1 , b 2 , ⋯ , b p )
∂
Q
∂
b
0
=
0
,
∂
Q
∂
b
j
=
0
(
j
=
1
,
2
,
⋯
,
p
)
\dfrac{∂ Q}{∂ b_0}=0,\dfrac{∂ Q}{∂ b_j}=0(j=1,2,\cdots,p)
∂ b 0 ∂ Q = 0 , ∂ b j ∂ Q = 0 ( j = 1 , 2 , ⋯ , p )
{
b
0
n
+
b
1
∑
i
=
1
n
x
i
1
+
b
2
∑
i
=
1
n
x
i
2
+
⋯
+
b
p
∑
i
=
1
n
x
i
p
=
∑
i
=
1
n
y
i
b
0
∑
i
=
1
n
x
i
1
+
b
1
∑
i
=
1
n
x
i
1
2
+
b
2
∑
i
=
1
n
x
i
1
∑
i
=
1
n
x
i
2
+
⋯
+
b
p
∑
i
=
1
n
x
i
1
∑
i
=
1
n
x
i
p
=
∑
i
=
1
n
x
i
1
y
i
⋯
b
0
∑
i
=
1
n
x
i
p
+
b
1
∑
i
=
1
n
x
i
1
∑
i
=
1
n
x
i
p
+
b
2
∑
i
=
1
n
x
i
p
∑
i
=
1
n
x
i
2
+
⋯
+
b
p
∑
i
=
1
n
x
i
p
2
=
∑
i
=
1
n
x
i
p
y
i
\begin{cases} \displaystyle b_0n+b_1\sum_{i=1}^{n}x_{i1}+b_2\sum_{i=1}^{n}x_{i2}+\cdots+b_p\sum_{i=1}^{n}x_{ip}=\sum_{i=1}^{n}y_i \\ \displaystyle b_0\sum_{i=1}^{n}x_{i1}+b_1\sum_{i=1}^{n}x_{i1}^2+b_2\sum_{i=1}^{n}x_{i1}\sum_{i=1}^{n}x_{i2}+\cdots+b_p\sum_{i=1}^{n}x_{i1}\sum_{i=1}^{n}x_{ip}=\sum_{i=1}^{n}x_{i1}y_i \\ \cdots \\ \displaystyle b_0\sum_{i=1}^{n}x_{ip}+b_1\sum_{i=1}^{n}x_{i1}\sum_{i=1}^{n}x_{ip}+b_2\sum_{i=1}^{n}x_{ip}\sum_{i=1}^{n}x_{i2}+\cdots+b_p\sum_{i=1}^{n}x_{ip}^2=\sum_{i=1}^{n}x_{ip}y_i \end{cases}
⎩ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎧ b 0 n + b 1 i = 1 ∑ n x i 1 + b 2 i = 1 ∑ n x i 2 + ⋯ + b p i = 1 ∑ n x i p = i = 1 ∑ n y i b 0 i = 1 ∑ n x i 1 + b 1 i = 1 ∑ n x i 1 2 + b 2 i = 1 ∑ n x i 1 i = 1 ∑ n x i 2 + ⋯ + b p i = 1 ∑ n x i 1 i = 1 ∑ n x i p = i = 1 ∑ n x i 1 y i ⋯ b 0 i = 1 ∑ n x i p + b 1 i = 1 ∑ n x i 1 i = 1 ∑ n x i p + b 2 i = 1 ∑ n x i p i = 1 ∑ n x i 2 + ⋯ + b p i = 1 ∑ n x i p 2 = i = 1 ∑ n x i p y i 正规方程组 ,引入矩阵
X
=
(
1
x
11
x
12
⋯
x
1
p
1
x
21
x
22
⋯
x
2
p
⋮
⋮
⋱
⋮
1
x
n
1
x
n
2
⋯
x
n
p
)
,
Y
=
(
y
1
y
2
⋮
y
p
)
,
B
=
(
b
0
b
1
⋮
b
p
)
,
\bf{X}=\begin{pmatrix} 1&x_{11}&x_{12}&\cdots&x_{1p} \\ 1&x_{21}&x_{22}&\cdots&x_{2p} \\ \vdots&\vdots&\ddots&\vdots \\ 1&x_{n1}&x_{n2}&\cdots&x_{np} \\ \end{pmatrix}, \bf{Y}=\begin{pmatrix} y_1 \\ y_2 \\ \vdots \\ y_p \\ \end{pmatrix}, \bf{B}=\begin{pmatrix} b_0 \\ b_1 \\ \vdots \\ b_p \\ \end{pmatrix},
X = ⎝ ⎜ ⎜ ⎜ ⎛ 1 1 ⋮ 1 x 1 1 x 2 1 ⋮ x n 1 x 1 2 x 2 2 ⋱ x n 2 ⋯ ⋯ ⋮ ⋯ x 1 p x 2 p x n p ⎠ ⎟ ⎟ ⎟ ⎞ , Y = ⎝ ⎜ ⎜ ⎜ ⎛ y 1 y 2 ⋮ y p ⎠ ⎟ ⎟ ⎟ ⎞ , B = ⎝ ⎜ ⎜ ⎜ ⎛ b 0 b 1 ⋮ b p ⎠ ⎟ ⎟ ⎟ ⎞ ,
X
T
X
=
(
n
∑
i
=
1
n
x
i
1
⋯
∑
i
=
1
n
x
i
p
∑
i
=
1
n
x
i
1
∑
i
=
1
n
x
i
1
2
⋯
∑
i
=
1
n
x
i
1
x
i
p
⋮
⋮
⋱
⋮
∑
i
=
1
n
x
i
p
∑
i
=
1
n
x
i
1
x
i
p
⋯
∑
i
=
1
n
x
i
p
2
)
,
X
T
Y
=
(
∑
i
=
1
n
y
i
⋮
∑
i
=
1
n
x
i
1
y
i
∑
i
=
1
n
x
i
p
y
i
)
\bf{X^TX}=\begin{pmatrix} n&\displaystyle \sum_{i=1}^{n}x_{i1}&\cdots&\displaystyle \sum_{i=1}^{n}x_{ip} \\ \displaystyle \sum_{i=1}^{n}x_{i1} &\displaystyle \sum_{i=1}^{n}x_{i1}^2&\cdots&\displaystyle \sum_{i=1}^{n}x_{i1}x_{ip} \\ \vdots&\vdots&\ddots&\vdots \\ \displaystyle \sum_{i=1}^{n}x_{ip} &\displaystyle \sum_{i=1}^{n}x_{i1}x_{ip}&\cdots&\displaystyle \sum_{i=1}^{n}x_{ip}^2 \\ \end{pmatrix}, \bf{X^TY}=\begin{pmatrix} \displaystyle\sum_{i=1}^{n}y_i \\ \vdots \\ \displaystyle\sum_{i=1}^{n}x_{i1}y_i \\ \displaystyle\sum_{i=1}^{n}x_{ip}y_i \end{pmatrix}
X T X = ⎝ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎛ n i = 1 ∑ n x i 1 ⋮ i = 1 ∑ n x i p i = 1 ∑ n x i 1 i = 1 ∑ n x i 1 2 ⋮ i = 1 ∑ n x i 1 x i p ⋯ ⋯ ⋱ ⋯ i = 1 ∑ n x i p i = 1 ∑ n x i 1 x i p ⋮ i = 1 ∑ n x i p 2 ⎠ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎞ , X T Y = ⎝ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎛ i = 1 ∑ n y i ⋮ i = 1 ∑ n x i 1 y i i = 1 ∑ n x i p y i ⎠ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎞
X
T
X
B
=
X
T
Y
\bf{X^TXB=X^TY}
X T X B = X T Y
B
^
=
(
b
^
0
b
^
1
⋮
b
^
p
)
=
(
X
T
X
)
−
1
X
T
Y
\bf{\hat B}=\begin{pmatrix} \hat b_0 \\ \hat b_1 \\ \vdots \\ \hat b_p \\ \end{pmatrix}=\bf{(X^TX)^{-1}X^TY}
B ^ = ⎝ ⎜ ⎜ ⎜ ⎛ b ^ 0 b ^ 1 ⋮ b ^ p ⎠ ⎟ ⎟ ⎟ ⎞ = ( X T X ) − 1 X T Y
y
^
=
b
^
0
+
b
^
1
x
1
+
b
^
2
x
2
=
⋯
+
b
^
p
x
p
\hat y=\hat b_0+\hat b_1x_1+\hat b_2x_2=\cdots+\hat b_px_p
y ^ = b ^ 0 + b ^ 1 x 1 + b ^ 2 x 2 = ⋯ + b ^ p x p