论文:Deep Wavelet Prediction for Image Super-resolution
github:https://github.com/tT0NG/DWSRx4
摘要
图像超分辨率(Image Super-Resolution ,SR)指的是从低分辨率(Low-Resolution,LR)图像中重建出其对应的高分辨率(High-Resolution,HR)图像。
SR可视为 恢复低分辨率图像的细节信息这一问题。
考虑到小波变换可得到图像的粗糙特征以及细节特征,这篇论文设计了一个Deep Wavelet Super-Resolution(DWSR)网络来预测低分辨率图像的小波系数中丢失的细节信息,从而得到高分辨的图像。
DWSR将小波变换和卷积网络相结合,SR问题变为小波系数预测问题。
Haar(db1)小波

LL(average)为低频信息,LH(horizontal)为水平高频信息,HL(vertical)为垂直高频信息,HH(diagonal)为对角高频信息。

网络结构

DWSR结构如上图,输入层和输出层的宽高深度均相同且channels=4;
卷积层使用zero padding + Relu激活函数,
输入层:
中间层:
输出层:
tenorflow实现:
def model(input_tensor):
with tf.device("/gpu:0"):
weights = []
activations_cl = []
conv_00_w = tf.get_variable("conv_00_w", [5, 5, 4, 64],
initializer=tf.random_normal_initializer(stddev=np.sqrt(2.0/9)))
conv_00_b = tf.get_variable("conv_00_b", [64], initializer=tf.constant_initializer(0))
weights.append(conv_00_w)
weights.append(conv_00_b)
activations = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(input_tensor, conv_00_w,
strides=[1, 1, 1, 1], padding='SAME'), conv_00_b),
"conv_00_a")
activations_cl.append(activations)
for i in range(10):
conv_w = tf.get_variable("conv_%02d_w" % (i+1), [3, 3, 64, 64],
initializer=tf.random_normal_initializer(stddev=np.sqrt(2.0/9/64)))
conv_b = tf.get_variable("conv_%02d_b" % (i+1), [64], initializer=tf.constant_initializer(0))
weights.append(conv_w)
weights.append(conv_b)
activations = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(activations, conv_w,
strides=[1, 1, 1, 1], padding='SAME'), conv_b),
"conv_%02d_a" % (i + 1))
activations_cl.append(activations)
conv_w = tf.get_variable("conv_20_w", [3, 3, 64, 4],
initializer=tf.random_normal_initializer(stddev=np.sqrt(2.0/9/64)))
conv_b = tf.get_variable("conv_20_b", [4], initializer=tf.constant_initializer(0))
weights.append(conv_w)
weights.append(conv_b)
activations = tf.nn.bias_add(value=tf.nn.conv2d(activations, conv_w,
strides=[1, 1, 1, 1], padding='SAME'), bias=conv_b,
name="conv_20_a")
activations_cl.append(activations)
return activations, weights, activations_cl
训练过程
LRSB是输入图像(LR images)经过Haar 2dDWT后的4张子图:LA(average)为低频信息,LV(vertical)为垂直高频信息,LH(horizontal)为水平高频信息,LD(diagonal)为对角高频信息。
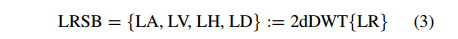
HRSB是HR images经过Haar 2dDWT后的4张子图
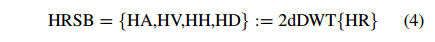
△SB是LRSB和HRSB之差,也是网络的output目标。

LRSB + f(LRSB) = SRSB,得到SRSB之后再通过小波逆变换即可得到低分辨率图像对应的最终结果SR

DWSR训练过程:

总结
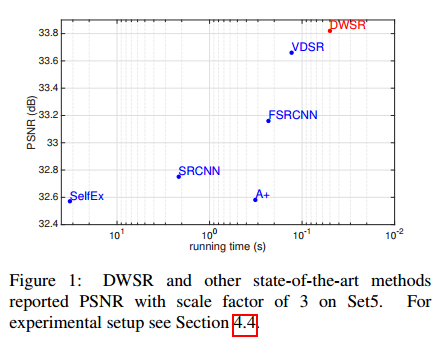
DWSR 计算简单,收敛速度快,模型参数少,运行时间短。

(红色为最好的结果,蓝色次之)