一、论文
《Image Super-Resolution Using Very Deep Residual Channel Attention Networks》
卷积神经网络(CNN)的深度对于图像超分辨率(SR)至关重要。 但是,我们观察到更深层次的图像SR网络更难训练。 低分辨率输入和特征包含丰富的低频信息,这些信息在各个通道之间均被平等对待,因此阻碍了CNN的表示能力。 为了解决这些问题,我们提出了非常深的残留频道关注网络(RCAN)。 具体来说,我们提出了残差残差(RIR)结构以形成非常深的网络,该网络由几个具有较长跳过连接的残差组组成。 每个残差组包含一些残差块,它们具有短的跳过连接。 同时,RIR允许通过多个跳过连接来绕过大量的低频信息,从而使主网络专注于学习高频信息。 此外,我们提出了一种通道注意机制,通过考虑通道之间的相互依赖性来自适应地重新缩放通道方式的特征。 大量的实验表明,相对于最新方法,我们的RCAN具有更好的准确性和视觉效果。
总的来说,我们的贡献有三方面:(1)我们提出了非常深的残留通道注意网络(RCAN),以实现高精度的图像SR。 (2)我们提出了残差残差(RIR)结构来构建非常深的可训练网络。 (3)我们提出了通道注意(CA)机制,通过考虑特征通道之间的相互依赖性来自适应地重新缩放特征。
二、网络结构


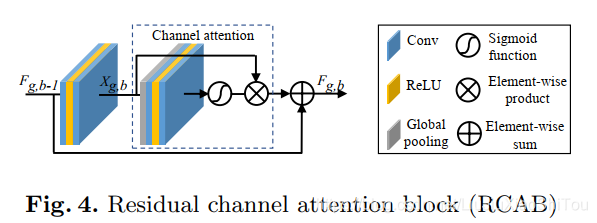
三、代码
下载:https://github.com/yulunzhang/RCAN
from model import common
import torch.nn as nn
def make_model(args, parent=False):
return RCAN(args)
## Channel Attention (CA) Layer
class CALayer(nn.Module):
def __init__(self, channel, reduction=16):
super(CALayer, self).__init__()
# global average pooling: feature --> point
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# feature channel downscale and upscale --> channel weight
self.conv_du = nn.Sequential(
nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=True),
nn.Sigmoid()
)
def forward(self, x):
y = self.avg_pool(x)
y = self.conv_du(y)
return x * y
## Residual Channel Attention Block (RCAB)
class RCAB(nn.Module):
def __init__(
self, conv, n_feat, kernel_size, reduction,
bias=True, bn=False, act=nn.ReLU(True), res_scale=1):
super(RCAB, self).__init__()
modules_body = []
for i in range(2):
modules_body.append(conv(n_feat, n_feat, kernel_size, bias=bias))
if bn: modules_body.append(nn.BatchNorm2d(n_feat))
if i == 0: modules_body.append(act)
modules_body.append(CALayer(n_feat, reduction))
self.body = nn.Sequential(*modules_body)
self.res_scale = res_scale
def forward(self, x):
res = self.body(x)
#res = self.body(x).mul(self.res_scale)
res += x
return res
## Residual Group (RG)
class ResidualGroup(nn.Module):
def __init__(self, conv, n_feat, kernel_size, reduction, act, res_scale, n_resblocks):
super(ResidualGroup, self).__init__()
modules_body = []
modules_body = [
RCAB(
conv, n_feat, kernel_size, reduction, bias=True, bn=False, act=nn.ReLU(True), res_scale=1) \
for _ in range(n_resblocks)]
modules_body.append(conv(n_feat, n_feat, kernel_size))
self.body = nn.Sequential(*modules_body)
def forward(self, x):
res = self.body(x)
res += x
return res
## Residual Channel Attention Network (RCAN)
class RCAN(nn.Module):
def __init__(self, args, conv=common.default_conv):
super(RCAN, self).__init__()
n_resgroups = args.n_resgroups
n_resblocks = args.n_resblocks
n_feats = args.n_feats
kernel_size = 3
reduction = args.reduction
scale = args.scale[0]
act = nn.ReLU(True)
# RGB mean for DIV2K
rgb_mean = (0.4488, 0.4371, 0.4040)
rgb_std = (1.0, 1.0, 1.0)
self.sub_mean = common.MeanShift(args.rgb_range, rgb_mean, rgb_std)
# define head module
modules_head = [conv(args.n_colors, n_feats, kernel_size)]
# define body module
modules_body = [
ResidualGroup(
conv, n_feats, kernel_size, reduction, act=act, res_scale=args.res_scale, n_resblocks=n_resblocks) \
for _ in range(n_resgroups)]
modules_body.append(conv(n_feats, n_feats, kernel_size))
# define tail module
modules_tail = [
common.Upsampler(conv, scale, n_feats, act=False),
conv(n_feats, args.n_colors, kernel_size)]
self.add_mean = common.MeanShift(args.rgb_range, rgb_mean, rgb_std, 1)
self.head = nn.Sequential(*modules_head)
self.body = nn.Sequential(*modules_body)
self.tail = nn.Sequential(*modules_tail)
def forward(self, x):
x = self.sub_mean(x)
x = self.head(x)
res = self.body(x)
res += x
x = self.tail(res)
x = self.add_mean(x)
return x
def load_state_dict(self, state_dict, strict=False):
own_state = self.state_dict()
for name, param in state_dict.items():
if name in own_state:
if isinstance(param, nn.Parameter):
param = param.data
try:
own_state[name].copy_(param)
except Exception:
if name.find('tail') >= 0:
print('Replace pre-trained upsampler to new one...')
else:
raise RuntimeError('While copying the parameter named {}, '
'whose dimensions in the model are {} and '
'whose dimensions in the checkpoint are {}.'
.format(name, own_state[name].size(), param.size()))
elif strict:
if name.find('tail') == -1:
raise KeyError('unexpected key "{}" in state_dict'
.format(name))
if strict:
missing = set(own_state.keys()) - set(state_dict.keys())
if len(missing) > 0:
raise KeyError('missing keys in state_dict: "{}"'.format(missing))四、相关资料
RCAN Image Super-Resolution Using Very Deep Residual Channel Attention Networks-ECCV2018