导读
韩国首尔大学的研究团队提出用于图像超分辨率任务的新方法,分别是增强深度超分辨率网络 EDSR 和一种新的多尺度深度超分辨率 MDSR,在减小模型大小的同时实现了比当前其他方法更好的性能,分别赢得NTIRE2017超分辨率挑战赛的第一名和第二名。
论文阅读点击这里EDSR
文章翻译来自:https://mp.weixin.qq.com/s/xpvGz1HVo9eLNDMv9v7vqg
http://www.sohu.com/a/157810550_473283
Enhanced Deep Residual Networks for Single Image Super-Resolution
简介
图像超分辨率(SR)问题,尤其是单一图像超分辨率(SISR)问题,在近几十年中已经受到了广泛的研究关注。SISR 问题旨在从一个单一低分辨率图像中重构出一个高分辨率图像。通常情况下,低分辨率图像和原始的高分辨率图像可根据情境而产生变化。很多研究都假设低分辨率图像是高分辨率图像的降采样结果。最近,深度神经网络在 SR 问题中的峰值信噪比(PSNR)方面带来了很大的性能提升。然而,这种网络也在结构最优化原则(architecture optimality)中暴露了其局限性。EDSR是NTIRE2017超分辨率挑战赛上获得冠军的方案。如论文中所说,EDSR最有意义的模型性能提升是去除掉了SRResNet多余的模块,从而可以扩大模型的尺寸来提升结果质量。EDSR的网络结构如下图所示。
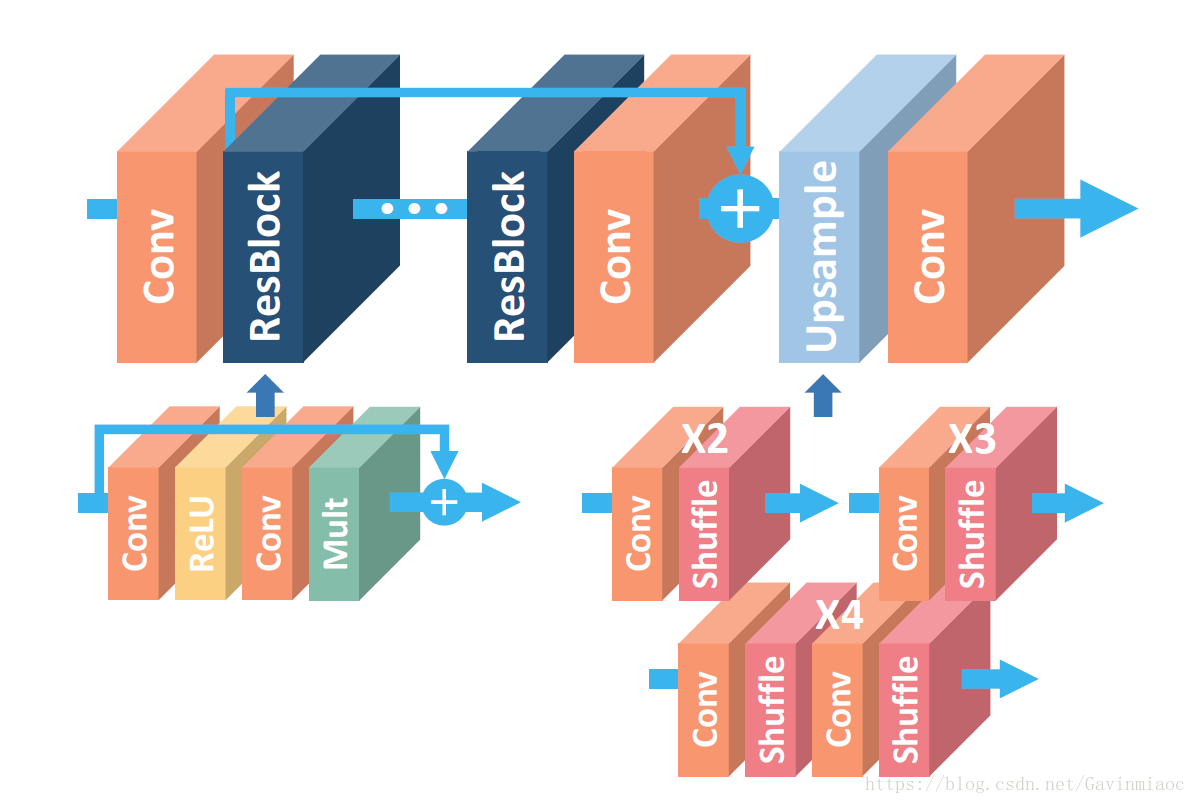

可以看到,EDSR在结构上与SRResNet相比,就是把批规范化处理(batch normalization, BN)操作给去掉了。文章中说,原始的ResNet最一开始是被提出来解决高层的计算机视觉问题,比如分类和检测,直接把ResNet的结构应用到像超分辨率这样的低层计算机视觉问题,显然不是最优的。由于批规范化层消耗了与它前面的卷积层相同大小的内存,在去掉这一步操作后,相同的计算资源下,EDSR就可以堆叠更多的网络层或者使每层提取更多的特征,从而得到更好的性能表现。EDSR用L1范数样式的损失函数来优化网络模型。在训练时先训练低倍数的上采样模型,接着用训练低倍数上采样模型得到的参数来初始化高倍数的上采样模型,这样能减少高倍数上采样模型的训练时间,同时训练结果也更好。
这篇文章还提出了一个能同时不同上采样倍数的网络结构MDSR,如下图。
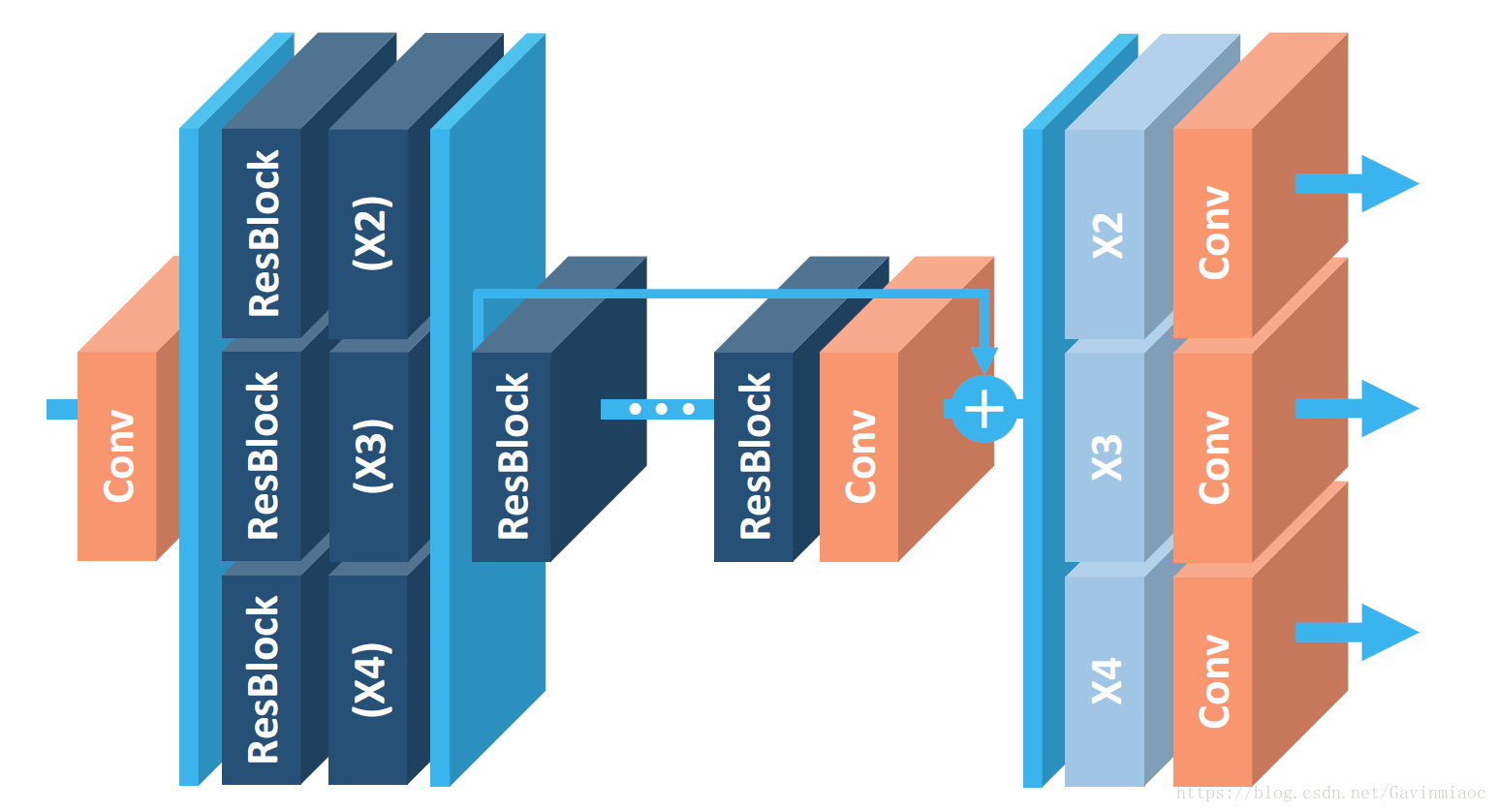
MDSR的中间部分还是和EDSR一样,只是在网络前面添加了不同的预训练好的模型来减少不同倍数的输入图片的差异。在网络最后,不同倍数上采样的结构平行排列来获得不同倍数的输出结果。
- 作者提出的模型主要是提高了图像超分辨的效果,并赢得了NTIRE2017 Super-Resolution Challenge。
- 做出的修改主要是在残差网络上。残差结构的提出是为了解决high-level问题,而不能直接套用到超分辨这种low-level视觉问题上。因此作者移除了残差结构中一些不必要的模块,结果证明这样确实有效果。
- 另外,作者还设置了一种多尺度模型,不同的尺度下有绝大部分参数都是共用的。这样的模型在处理每一个单尺度超分辨下都能有很好的效果。
模型
Residual blocks
- 作者的原话是:Since batch normalization layers normalize the features, they get rid of range flexibility from networks by normalizing the features。因此有必要把batch norm层移除掉。另外,和SRResnet相似,相加后不经过relu层。最终的结构图如下:
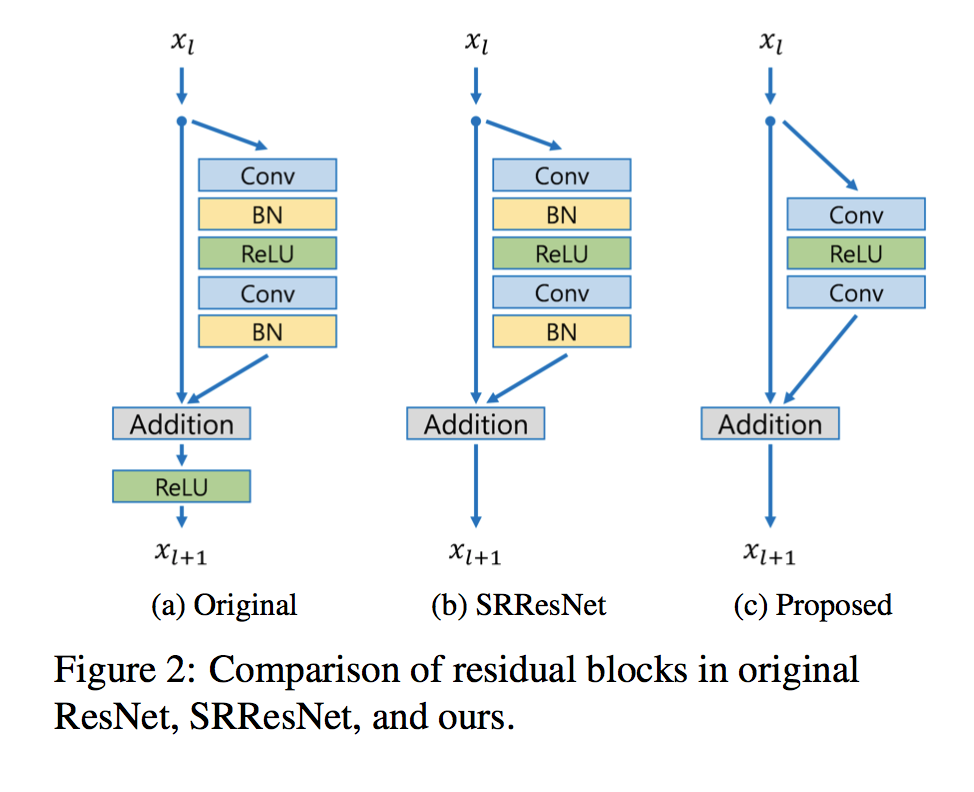
- 值得注意的是,bn层的计算量和一个卷积层几乎持平,移除bn层后训练时可以节约大概40%的空间。
- 太多的残差块会导致训练不稳定,因此作者采取了residual scaling的方法,即残差块在相加前,经过卷积处理的一路乘以一个小数(比如作者用了0.1)。这样可以保证训练更加稳定。
Single scale model

+ 作者采用的结构和SRResnet非常相似,但移除了bn和大多数relu(只在残差块里才有)。最终的训练版本有B=32个残差块,F=256个通道。并且在训练*3,*4模型时,采用*2的预训练参数。此模型称之为EDSR。
multi-scale model
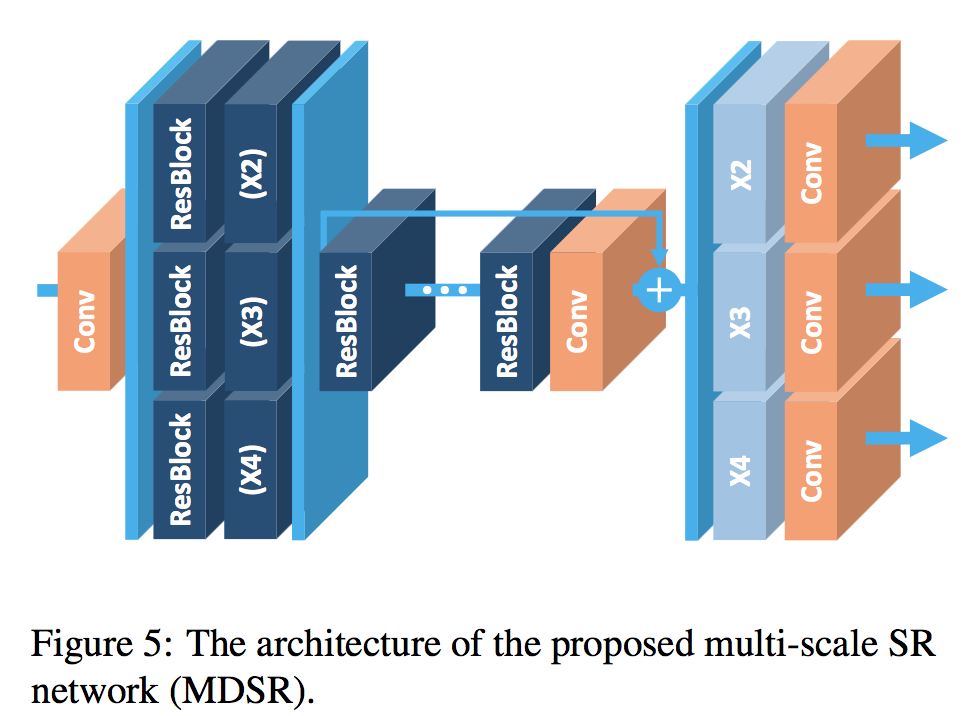
+ 多尺度模型很简单,一开始每个尺度都有两个独自的残差块,之后经过若干个残差块,最后再用独自的升采样模块来提高分辨率。此模型称之为MDSR。
+ 作者的版本B=80,F=64。
实验
准备
- 实验数据用的是比赛提供的DIV2K,它有800张训练图像,100张验证图像,100张测试图像。每张都是2k分辨率。
- 预处理是,每张图像减去DIV2K的总平均值。另外在训练时,损失函数用L1而不是L2,源码用torch7封装。
- 提一下MDSR的训练,是*2 *3 *4三中的尺度随机混合作为训练集,在更新梯度时,只有对应尺度的那部分参数更新。
Geometric Self-ensemble
- 这是一个很神奇的方法,测试时,把图像90度旋转以及翻转,总共有8种不同的图像,分别进网络然后变换回原始位置,8张图像再取平均。这个方法可以使测试结果有略微提高。Note that geometric self-ensemble is valid only for symmetric downsampling methods such as bicubic downsampling.
结果
- 测试的时候只在y通道上评估。
从文章给出的结果可以看到,EDSR能够得到很好的结果。增大模型参数数量以后,结果又有了进一步的提升。因此如果能够解决训练困难的问题,网络越深,参数越多,对提升结果确实是有帮助吧。
最后,送上部分源码:
github(torch): https://github.com/LimBee/NTIRE2017https://2017
github(tensorflow): https://github.com/jmiller656/EDSR-Tensorflowhttps://
github(pytorch): https://github.com/thstkdgus35/EDSR-PyTorchhttps://
通过阅读有关深度学习超分辨率方法的论文,可以看到通过网络结构、损失函数以及训练方式的演变,深度学习超分辨率方法在结果、速度以及应用性上都有了不断的提高。这里再放上一篇深度学习超分辨率方法综述的链接(Super-Resolution via Deep Learning)以及github上一个超分辨率方法的总结(https://github.com/YapengTian/Single-Image-Super-Resolutionhttps://ingle-Image-Super-Resolution)。
非常感谢许多知乎和博客上的文章,由于比较多,这里列出参考得比较多的几个资源:
https://zhuanlan.zhihu.com/p/25532538?utm_source=tuicool&utm_medium=referral
https://blog.csdn.net/abluemouse/article/details/78710553原文翻译:
摘要
随着深度卷积神经网络(DCNN)的发展,最近在图像超分辨率方面的研究也取得了进展。尤其,残差学习技术表现出很好的性能。本研究中,我们提出一种增强的深度超分辨率网络(enhanced deep super-resolution,简称 EDSR),其性能超过当前最先进的超分辨率(SR)方法。我们的模型通过删除常规残差网络中不必要的模块进行优化,实现了显著的性能提高。在稳定训练过程的同时,我们通过扩大模型的规模,进一步提高了模型性能。我们还提出一种新的多尺度深度超分辨率系统(multi-scale deep super-resolution,简称MDSR)和训练方法,可以将单个模型中不同的放大因子(upscaling factors)重建为高分辨率图像。我们提出的方法在基准数据集上比当前最先进的方法性能更好,并赢得了NTIRE2017超分辨率挑战赛。
引言
图像超分辨率(SR)问题,特别是单图像超分辨率(single image super-resolution,SISR)问题,最近十年来受到越来越多的研究关注。SISR的目的是从单个低分辨率图像I(LR)重建高分辨率图像I(SR)。通常,I(LR)与原始的高分辨率图像I(HR)之间的关系根据不同的情况是不同的。许多研究假设I(LR)是I(HR)的双三次降采样版本,但是其他降质因素,例如模糊,抽取或噪声在实际应用中也可以考虑。
最近,深度神经网络为SR问题中的峰值信噪比(PSNR)提供了显着的性能改进。但是,这样的网络在架构最优性方面有所限制。首先,神经网络模型的重建性能对架构的微小变化很敏感。同样的模型在不同的初始化和训练技术之下实现的性能水平不同。因此,精心设计的模型架构和复杂的优化方法对于训练神经网络至关重要。
其次,大多数现有的SR算法将不同缩放因子的超分辨率问题作为独立的问题,没有考虑并利用SR中不同缩放之间的相互关系。 因此,这些算法需要许多scale-specific的网络,需要各自进行训练来处理各种scale。例外的是,VDSR [11]可以在单个网络中同时处理多个scale的超分辨率。使用多个尺度训练VDSR模型可以大幅提升性能,超过scale-specific的训练,这意味着scale-specific的模型中存在冗余。尽管如此,VDSR型的架构需要双三次插值图像作为输入,这与scale-specific的上采样方法的架构相比,需要更多计算时间和存储空间。
SRResNet [14]成功地解决了计算时间和内存的问题,并且有很好的性能,但它只是采用了He et al. [9] 的ResNet架构,没有提出太多修改。但是,原始的ResNet目的是解决更高层次的计算机视觉问题,例如图像分类和检测。因此,将ResNet架构直接应用于超分辨率这类低级视觉问题可能不是最佳的。
为了解决这些问题,基于SRResNet架构,我们首先通过分析和删除不必要的模块进行优化,以简化这一架构。当模型非常复杂时,就不容易训练。因此,我们以适当的损失函数训练网络,并进行仔细的模型修改。我们的实验表明,修改的方案能产生更好的结果。
其次,我们调查了从其他尺度训练的模型迁移知识的模型训练方法。在训练期间利用与尺度无关(scale-independent)的信息,从预训练的low-scale模型中训练high-scale模型。此外,我们提出一个新的多尺度架构,它们分享不同尺度的大部分参数。与多个单尺度模型相比,这个多尺度模型使用的参数少得多,但性能相当。
我们在标准基准数据集和新的DIV2K数据集上评估我们的模型。评估显示,我们提出的单尺度和多尺度超分辨率网络在所有数据集上,PSNR和SSIM均显示出最优性能。我们的方法分别在NTIRE 2017超分辨率挑战赛中分别获得第一名和第二名。

单尺度SR方法(EDSR)与其他方法的比较,放大4倍。
方法
我们先分析了最近发表的超分辨率网络,并提出残差网络架构的一个增强版本,它具有更简单的结构,并且在计算效率上优于原始网络。接着我们提出一个处理特定超分辨率尺度的单尺度架构EDSR,以及一个在单模型中重建各种尺度高分辨率图像的多尺度架构MDSR。

原始 ResNet,SRResNet,以及我们提出的增强办残差网络中 residual blocks 的对比。

单尺度SR网络(EDSR)的架构

为×4模型(EDSR)使用预训练的×2网络的效果。红线表示绿线(从头开始训练)的最佳表现。训练期间使用10张图像进行验证。

多尺度SR网络(MDSR)的架构
实验
数据集
DIV2K数据集[26]是一种新发布的用于图像复原任务的高质量(2K分辨率)图像数据集。DIV2K数据集包含800张训练图像,100张验证图像和100张测试图像。由于测试数据集资料尚未发布,因此我们在验证数据集上比较了模型性能。我们还在另外4个标准基准数据集上比较了性能:Set5 [2],Set14 [33],B100 [17]和Urban100 [10]。
(训练细节请阅读原论文,论文下载:https://arxiv.org/abs/1707.02921v1)
评估模型
我们在DIV2K数据集上测试我们提出的网络。从SRResNet开始,我们逐步改变各个设置。SRResNet [14]是我们自己训练的。首先,我们将损失函数从L2改为L1,然后根据前面部分的描述对网络架构进行修改,如表1所示。

模型设定

表2:在DIV2K验证集上的架构性能比较(PSNR(dB)/ SSIM))。红色表示最优的性能,蓝色表示其次。EDSR +和MDSR +分别表示EDSR和MDSR的自组合版本。



我们的模型与其他模型放大4倍(×4)超分辨率的定性比较
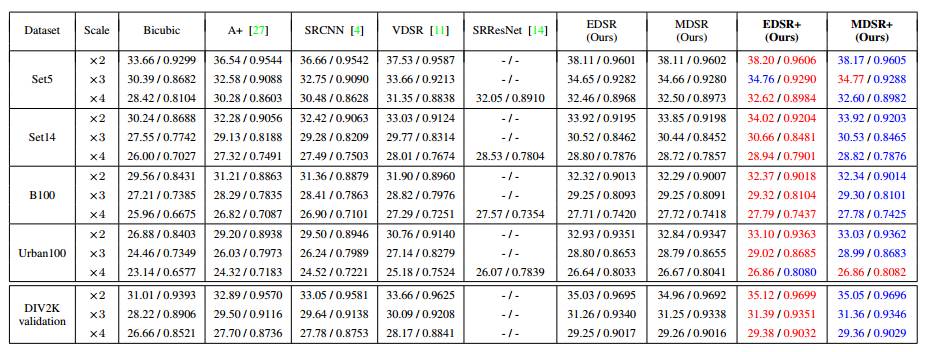
表3:公共基准测试结果和DIV2K验证结果(PSNR(dB)/ SSIM))。红色表示最优性能,蓝色表示其次。需要注意的是,DIV2K验证结果是从已发布的演示代码中获取的。


我们的方法在NTIRE2017超分辨率挑战赛的结果。

表4:我们的方法在NTIRE 2017超分辨率挑战赛测试数据集上的表现。红色表示最优性能,蓝色表示其次。
结论
在本文中,我们提出一种增强的超分辨率算法。通过从常规ResNet架构中删除不必要的模块,我们在使模型紧凑的同时实现了更好的结果。我们还采用残差缩放技术来稳定地训练大型模型。我们提出的单尺度模型超越了已有模型,取得了state-of-the-art的性能。
此外,我们还提出一个多尺度超分辨率网络,以减小模型规模并缩短训练时间。具有规模依赖性模块和共享主网络的多尺度模型可以在统一的框架中有效处理各种超分辨率尺度。虽然多尺度模型与一组单尺度模型相比保持了紧凑,但它显示出与单尺度SR模型相当的性能。我们提出的单尺度和多尺度模型在标准基准数据集和DIV2K数据集中均实现了最佳结果。