2018 CVPR Image Super-Resolution Using Very Deep Residual Channel Attention Networks
Code https://github.com/yulunzhang/RCAN 亲测效果不错
1 EDSR和MDSR表明,对于图像SR来说,深度的表达是至关重要的。但是作者认为简单地将残差模块拼接在一起来构建更深层的网络,几乎不能获得更好的改进。更深层次的网络是否能进一步促进效果以及如何构建非常深厚的可训练网络还需要探索。
2 作者主要针对EDSR提出改进 第一点认为EDSR将特征不同通道平等对待,这样丧失通道判别能力,损失了深度学习的伟大。第二点超分的目的就是恢复上采样后图像的细节,而LR图像包含大量细节信息,可以直接传递给最后的输出图像。EDSR没必要去提取特征然后学习,浪费计算。
因此作者提出了一个非常深(400多层)的网络RCAN并且可以自适应学习有用的通道判别能力(基于注意力机制)。
3 作者认为高频通道特征对超分图像重建很有用,因此通过注意力机制实现不同通道特征得到不同的权重。
解答:
1 提出了一个residual in residual (RIR)使得非常深的网络可训练。
2 提出了通道注意(CA)机制,通过对跨特性通道的相互依赖进行建模来自适应地重新扩展每个通道的特性。
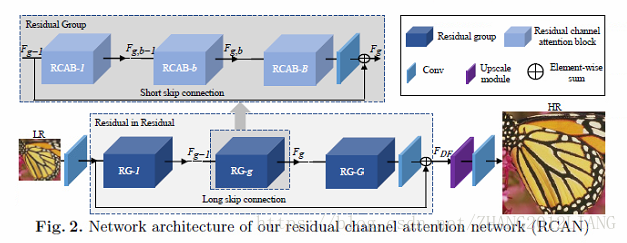
整个网络大结构
LR –> 低级特征提取 –> RIR(深度特征提取)》->(低级特征*深度特征)->上采样模块-》重建模块-》HR
RIR:基于残差模块结构获得了深度特征,这些特征对应非常大的感受野。
上采样模块:选择很多(反转积,邻近插值+卷积,ESPCN)都可以。
重建模块:通过一个 卷积层。
损失函数:L1。
RIR模块简介:图2
RIR包含多个残差组(RG)模块和一个长跳连接。
RG:每一个RG又包含多个RCAB和一个短跳连接。
这种结构使得网络可以非常深。残差块和连接线能够实现非常深的网络已经被证实了的。
其中长连接线是有利于网络训练的和学习的。另外文章强调过属于图像包含很多有用的信息,尤其低频信息,这些信息可以直接通过长连接线传输到后面。其中为了进一步学习残差,每一个RG中包含多个RCAB,以及一个短跳连接,理由同大的残差和长跳连接差不多。
RCAB:
MDSR and EDSR 里面的RBs 模块可以看作RCAB的特例,主要是作者添加了一个通道注意力,使得每一个通道的特征权重是不一样的。正如上面所讨论的,残差组和长跳连接允许网络的主要部分集中在更丰富的LR特征。通道注意力提取通道特性,以进一步提高网络的判别能力。这部分主要来自“Enhanced deep residual networks for single image super-resolution”的RB模块启发。作者在RB模块融于通道注意力机制提出了RCAB。
作者也通过实验证实了提出的RIR模块和RCAB模块的有效性。通过作者公开的代码,亲测效果不错。
ps:
Channel-wise Attention机制可以看作是一个选择语义属性的过程,联想到semantic attention。
为什么要引入channel wise attention?channel wise atentiontion的本质是什么呢?举个例子:当你要预测cake时,那么channel wise attention就会使得提取到cake特征的卷积核生成的feature map的权重加大。因此作者在文中将channel wise attention总结为semantic attention,semantic attention的内容可以参看CVPR2016的论文:Image captioning with semantic attention。
多个特征图对应的同一个通道的均值,即为通道特征。每一个通道会得到不一样的权重