文章地址: http://openaccess.thecvf.com/content_ECCV_2018/html/Seong-Jin_Park_SRFeat_Single_Image_ECCV_2018_paper.html
作者的项目地址:SRFeat-Tensorlayer
1 简单介绍
虽然已有的基于GAN的超分辨率方法能够被用来生成真实的纹理信息,但是它们都倾向于生成与输入图像无关的不太有意义的高频噪声。于是,作者增加了一个作用于特征域的判别网络,使得生成网络能够生成与图像结构相关的高频特征。
作者的创新:
- 在SR框架下提出了二种判别器,分别是图像域,还有特征域,产生高频的信息而不是噪声。
- 生成器中使用了长范围的跳跃连接,让相距较远的层信息更容易流动。
2 网络
生成器的网络和之前的SRResNet很类似,只是多了长范围的跳跃连接,作者认为之前的SRResNet对待每一个layer特征是一样的,我们通过1×1的conv将不同levle的特征连接起来,然后可以动态调整它的权重,然后在最后一层相加起来,其实这其中蕴含着注意力机制的思想。作者解释这样做的好处有:
- 后向传播过程梯度更容易更新
- 充分利用中间层的特征来提高最后的特征。
生成网络的结构如下:
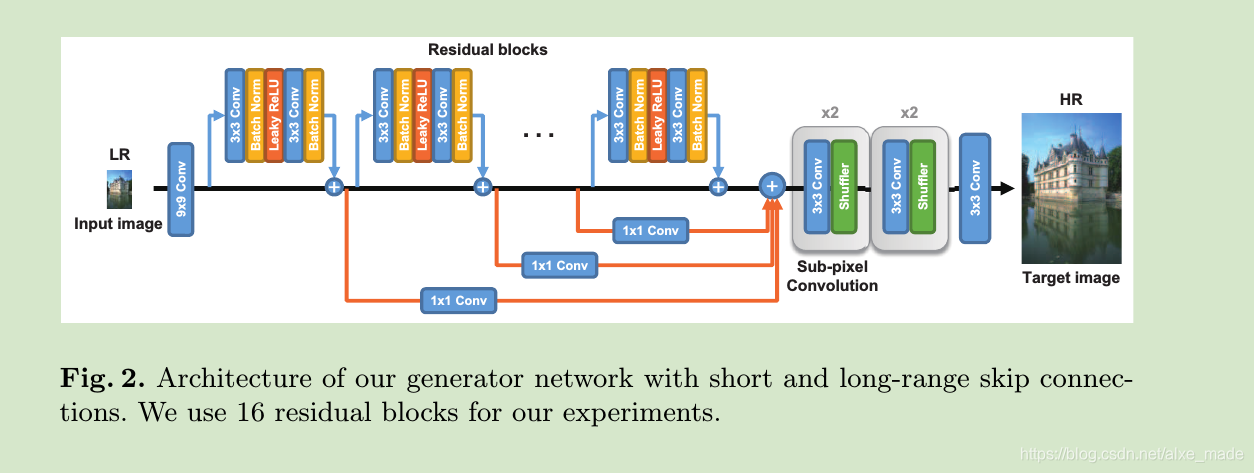
之后由亚像素卷积层完成尺寸放大的操作。判别网络结构是普通的网络,和SRResNet是一样的。判别网络如下:
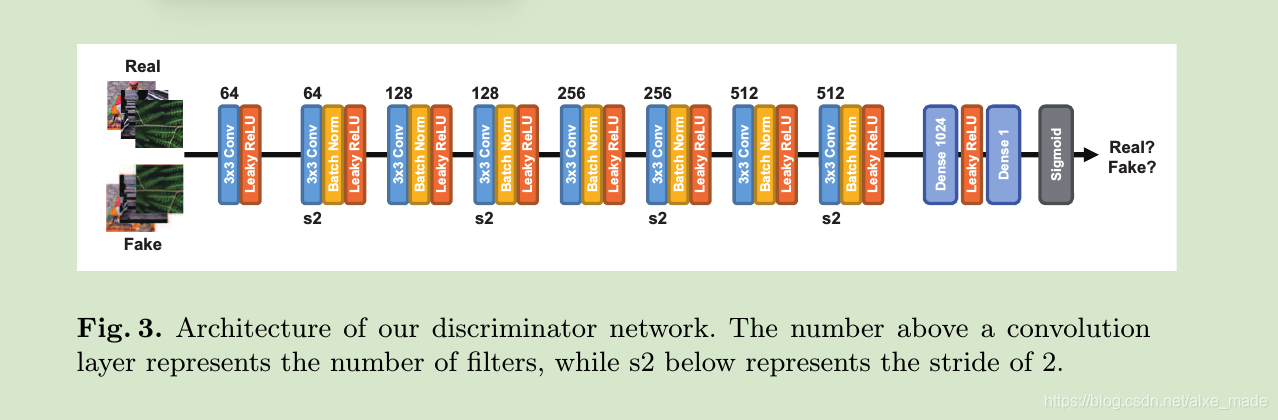
在训练网络时,作者总共有两步。第一步就是先用均方误差预训练生成网络,这个是用ImageNet进行训练的。然而,此时得到的结果并不能得到视觉上让人满意的结果。第二步再用感知损失和两个对抗损失来训练网络。其中感知损失的方法就是让HR和重建图像通过一个VGG19的网络,然后计算MSE。其中一个对抗损失对应的是图像判别网络,也就是和原有方法一样,对图像的像素值进行评判。另外一个对抗损失则对应的是特征判别网络,是对图像的特征图进行评判,即将感知损失中计算的对象交由判别网路进行判断。感知损失目的是让HR和SR图像在感觉上具有一致性,而特征GAN损失是能够产生感受上高频信息而不是高频噪声,通过添加这个特征判别网络,生成网络被训练得能够合成更多有意义的高频细节。作者提到,他们尝试了多种特征判别网络的结构,但是得到的结果都很接近。
3 实验
作者实现证明了长范围的跳跃连接的有效性。 w/o Conv是没有1*1的conv操作, w/o Skip是没有长范围的跳跃连接。
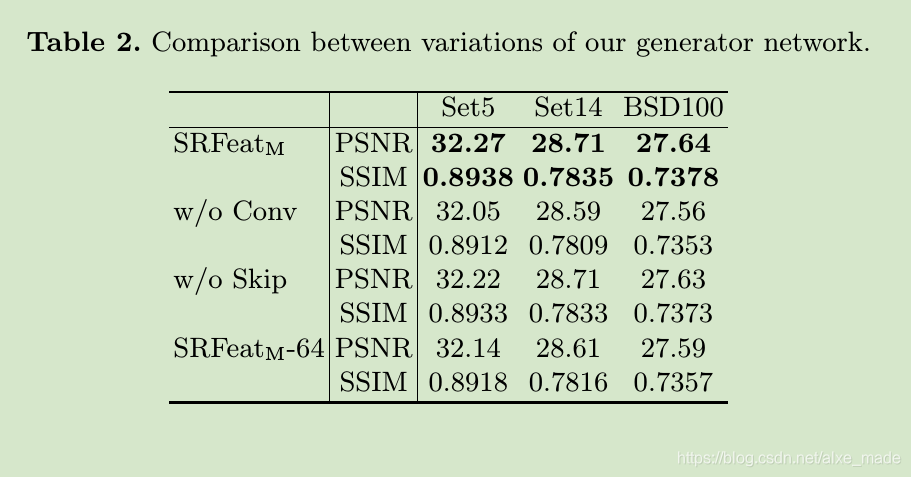
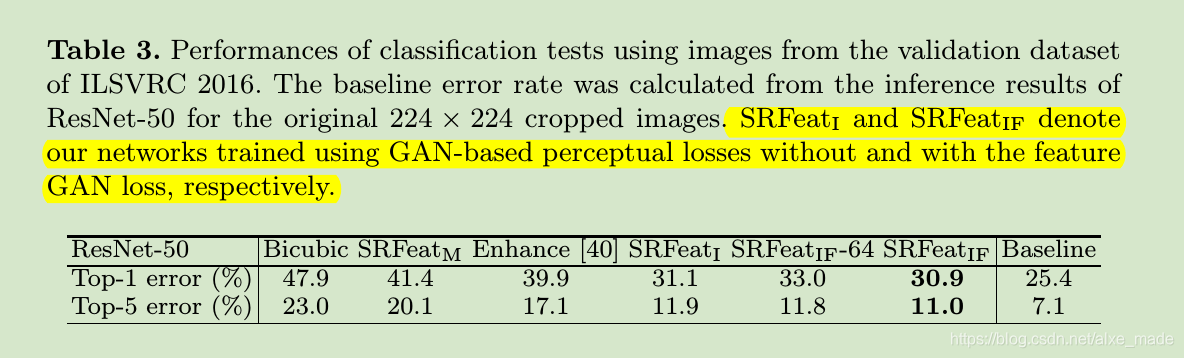
作者然后验证了特征域的gan损失有效性。重建是将sr和hr图像送到分类网络,计算top1和top5错误率。其中SRFeatI是不含特征域的gan损失,而SRFeatIF是包含特征域的gan损失。
最后是从视觉角度上来看。

4 感想
最近在利用GAN进行SR过程中,虽然加入感受损失可以很好的产生视觉上令人满意的效果,但是这往往也会产生高配的噪声,而这HR是没有的。在这篇文章中最大的创新就是引入了特征域的gan损失,让网络更好的产生高频的细节而不是噪声。其他方面就是在生成器引入了DenseNet和注意力机制的思想。在作者的展望中提到了这里的引入vgg-19中某一固定成,比如conv-5,在以后工作看能不能自适应的学习到最佳层。