《Deep Adaptive Inference Networks for Single Image Super-Resolution》

摘要
近年来,由于深度卷积神经网络的部署,单图像超分辨率(SISR)取得了巨大的进展。 对于大多数现有的方法,每个SISR模型的计算成本与局部图像内容、硬件平台和应用场景无关。 尽管如此,内容和资源自适应模型更受欢迎,并鼓励将更简单和高效的网络应用于更容易的区域,细节较少,以及效率限制有限的场景。 在本文中,我们采取了一个步骤来解决这个问题,利用自适应推理网络的深度SISR(AdaDSR)。 特别是,我们的AdaDSR涉及一个SISR模型作为骨干和一个轻量级适配器模块,它以图像特征和资源约束作为输入,并预测本地网络深度的映射图。 然后在有效的稀疏卷积的支持下进行自适应推理,其中只有一小部分骨干中的层根据其预测深度在给定位置执行。 网络学习可以制定为重建和网络深度损失的联合优化。 在推理阶段,平均深度可以灵活调整,以满足一系列的效率约束。 实验表明,我们的AdaDSR与其同行(例如EDSR和RCAN)相比,具有有效性和适应性。
我们提出了用于深度sisr的自适应推理网络,即adadsr,它添加了一个轻量级适配器模块的主干,以用于空间自适应推理的局部深度映射。
将图像特征和期望深度作为适配器的输入,将重构损耗与深度损耗结合起来进行网络学习,从而使ADADSR配备稀疏卷积,以适应各种效率约束
实验表明,我们的adadsr在精度和效率之间比it对应物(即EDSR和RCA N)实现了更好的权衡,并且可以在没有从头开始训练的情况下适应不同的效率约束。
网络结构
本节介绍了我们的AdaDSR单图像超分辨率模型.. 首先,我们为主干配备了一个网络深度图,以方便空间变异推断。 然后,引入稀疏卷积,通过省略不必要的计算来加快推理。此外,还部署了一个轻量级适配器模块来预测网络深度图。 最后,总体网络结构(见图)。
一、具有空间变异网络深度的AdaDSR

单图像超分辨率的目的是学习一种映射,从其低分辨率(LR)观测x中重建高分辨率图像,其中F表示具有网络参数θ的SISR网络。在本工作中,我们考虑了由三个主要模块组成的深度SISR网络的代表性类别,即特征提取Fe、残差块和HR重建Fr。以EDSR为例,我们给出了Zo=Fe(X)。 然后,剩余块的输出可以表示为:
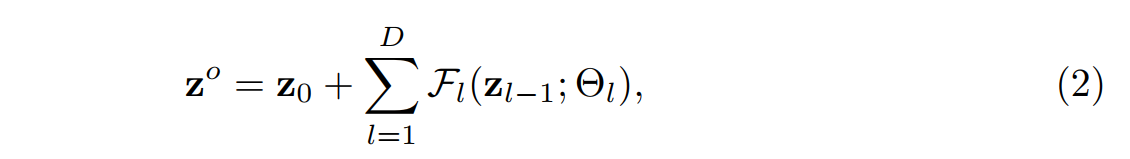
其中![]() 表示第l个残差块的网络参数。给出第(l-1)个残差块的输出,第l个残差块可以被写成
表示第l个残差块的网络参数。给出第(l-1)个残差块的输出,第l个残差块可以被写成![]() 。最后重建高分辨率图像可以被表示为
。最后重建高分辨率图像可以被表示为![]() 。
。

如图所示。 1.超分辨率的困难是空间上的不同。例如,它不需要经过公式2中所有的残差块来重建平滑区域, 对于纹理丰富细致的区域,为了实现高质量的重建,通常需要更多的残差块。因此,我们引入了一个2D网络深度图![]() ,它与
,它与![]() 有相同的尺寸大小。直观的来说就是,处理光滑区域时,
有相同的尺寸大小。直观的来说就是,处理光滑区域时,![]() 较小;处理具有丰富细节的区域时
较小;处理具有丰富细节的区域时![]() 较大。为了便于空间自适应推理,我们修改公式2
较大。为了便于空间自适应推理,我们修改公式2

其中![]() 表示矩阵对应元素相乘,
表示矩阵对应元素相乘,![]() 被定义为:
被定义为:

最后的![]() 剩余块是不需要计算具有网络深度
剩余块是不需要计算具有网络深度![]() 的位置。给定二维网络深度图d,我们可以利用公式3进行空间自适应推理。
的位置。给定二维网络深度图d,我们可以利用公式3进行空间自适应推理。
2、用于有效推理的稀疏卷积
m(![]() 第l个残差块)作为掩码指示应保持卷积激活的位置。
第l个残差块)作为掩码指示应保持卷积激活的位置。

对于一些卷积实现,如快速傅里叶变换(FFT)[和基于Winograd的算法,首先要执行标准卷积才能获得![]() 的整个输出特征映射。
的整个输出特征映射。![]() 分别表示输入特征映射、卷积核和卷积运算。然后,稀疏结果可以表示
分别表示输入特征映射、卷积核和卷积运算。然后,稀疏结果可以表示![]()
![]() 。这些实现满足了空间自适应推理的要求,同时与标准卷积保持相同的计算复杂度。
。这些实现满足了空间自适应推理的要求,同时与标准卷积保持相同的计算复杂度。
我们采用基于im2col的稀疏卷积进行有效的自适应推理。如图所示,将与![]() 中点相关的f的补丁组织为矩阵
中点相关的f的补丁组织为矩阵![]() 中的一行,卷积核
中的一行,卷积核![]() 也转换为向量
也转换为向量![]() 。然后将卷积运算转化为矩阵乘法问题,在许多基本线性代数子程序(BLAS)库中得到了高度优化。然后,结果
。然后将卷积运算转化为矩阵乘法问题,在许多基本线性代数子程序(BLAS)库中得到了高度优化。然后,结果![]() 可以组织回输出特征映射。给定掩码
可以组织回输出特征映射。给定掩码![]() ,如果重组输入特征
,如果重组输入特征![]() 具有零掩值,则在构造重组输入特征
具有零掩值,则在构造重组输入特征![]() 时可以简单地跳过相应的行(参见图中
时可以简单地跳过相应的行(参见图中![]() 的阴影行),计算也被跳过。因此,公式3中的空间自适应推理可以通过im2col和col2im程序有效地实现。 此外,当更多的行被屏蔽时,即当d的平均深度较小时,效率可以进一步提高。
的阴影行),计算也被跳过。因此,公式3中的空间自适应推理可以通过im2col和col2im程序有效地实现。 此外,当更多的行被屏蔽时,即当d的平均深度较小时,效率可以进一步提高。
值得注意的是,稀疏卷积在图像分类、目标检测、模型剪枝和三维语义分割任务中得到了广泛的应用。据我们所知,这是第一次尝试在SISR任务上部署像素级稀疏卷积,实现图像内容以及资源自适应推理。
3、轻量级适配器模块
在这一小节中,我们引入了一个轻量级适配器模块p来预测2d网络深度图D,为了适应局部图像内容,需要适配器模块p来产生较低的网络深度,以实现平滑区域和较高的深度去处理丰富细节。 设![]() 是d的平均值,d是所需的网络深度。 为了使模型适应效率约束,我们还考虑了所需的网络深度d,并要求d的减小可以导致较小的
是d的平均值,d是所需的网络深度。 为了使模型适应效率约束,我们还考虑了所需的网络深度d,并要求d的减小可以导致较小的![]() ,即更好的推理效率。
,即更好的推理效率。
适配器模块p以特征映射![]() 为输入,由四个具有PReLU非线性激活函数的卷积层和另一个具有Relu非线性激活函数的卷积层组成。 设
为输入,由四个具有PReLU非线性激活函数的卷积层和另一个具有Relu非线性激活函数的卷积层组成。 设![]() 。 然后我们使用公式4为每个残差块生成掩码
。 然后我们使用公式4为每个残差块生成掩码![]() 。请注意,
。请注意,![]() 可能不是二进制掩码,但包含许多零。 因此,我们可以构造一个稀疏残差块,它可以省略具有零掩值的区域的计算,以便于有效的自适应推理。为了满足效率约束,我们还将所需的网络深度
可能不是二进制掩码,但包含许多零。 因此,我们可以构造一个稀疏残差块,它可以省略具有零掩值的区域的计算,以便于有效的自适应推理。为了满足效率约束,我们还将所需的网络深度![]() 作为适配器的输入,并通过
作为适配器的输入,并通过

其中![]() 表示适配器模块的网络参数。具体来说,将适配器中第一个卷积层的权重表示为
表示适配器模块的网络参数。具体来说,将适配器中第一个卷积层的权重表示为![]() ,当所需深度为
,当所需深度为![]() 时,我们通过将
时,我们通过将![]() 替换成
替换成![]() 来使卷积可调,因此适配器能够满足上述d导向约束。
来使卷积可调,因此适配器能够满足上述d导向约束。
4、网络体系结构和学习目标
如图所示。 我们提出的AdaDSR由一个骨干SISR网络和一个轻量级适配器模块组成,以方便图像内容和效率自适应推理。在不失去通用性的情况下,在本节中,我们以EDSR为主干来说明网络体系结构,并将我们的AdaDSR应用于其他具有代表性的SISR模型,并有一些残差块[9]。主链涉及32个残差块,每个块有两个3×3个卷积层,步长为1,填充1和256个ReLU非线性的通道。 另一个3×3卷积层部署在残差块后面。特征提取模块![]() 是卷积层,重构模块
是卷积层,重构模块![]() 由上采样单元组成,以扩大特征,然后是重构输出图像的卷积层。 上采样单元是由一系列卷积PixelShuffle根据超分辨率尺度组成的。 此外,轻量级适配器模块以特征映射
由上采样单元组成,以扩大特征,然后是重构输出图像的卷积层。 上采样单元是由一系列卷积PixelShuffle根据超分辨率尺度组成的。 此外,轻量级适配器模块以特征映射![]() 和所需的网络深度
和所需的网络深度![]() 作为输入,由五个卷积层组成,生成一个单通道网络深度图。
作为输入,由五个卷积层组成,生成一个单通道网络深度图。
值得注意的是,我们实现了两个版本的AdaDSR。 第一种是以EDSR为主干,由AdaEDSR表示。 为了进一步展示所提出的AdaDSR的通用性,并与最先进的方法进行比较,我们还将RCAN作为骨干,并实现了AdaRCAN模型。 主要区别是,RCAN用10个残差组代替32个残差块,每个残差组由20个带有通道注意的残差块组成。 因此,我们修改适配器以同时生成10个深度映射,每个映射被部署到一个残差组。
我们的AdaDSR的学习目标包括重建损失项和网络深度损失项,以实现SISR性能和效率之间的适当权衡。 在SISR性能方面,我们采用了在超分辨率输出和地面真实高分辨率图像上定义的“![]() 重建损耗,
重建损耗,

其中y和y^分别表示我们的AdaDSR的高分辨率地面真相和超分辨率图像。 考虑到效率约束,我们要求预测的网络深度图的平均d¯近似于期望的深度d,然后引入以下网络深度损失,
总之,我们的AdaDSR的总体学习目标是:

其中λ是一个折衷的超参数,在我们所有的实验中都设置为0.01。
