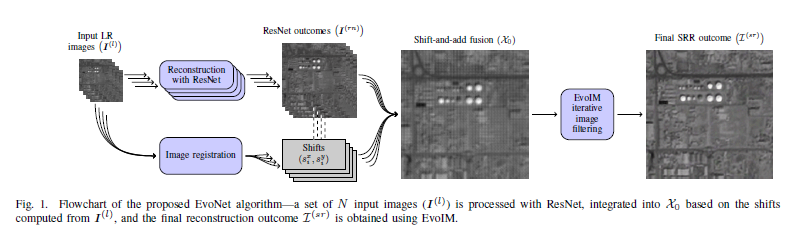
Mutiple-Image SSR 关键的技术imformation fusion
1. 将单一场景的多图像经过Resnet, 其中每张图片的维度变为了输入的两倍。同时,这些输入的单一场景的多图像进行图像配准(image registration)来确定图像之间的
子像素的位移(位移值乘以2以适配于Resnet的输出)
2. 经过Resnet的结果与子像素移位一起使用中值移位和加法方法组成初始的高分率图像,这时候维度再次增加,为原来的4倍。
3. 初始的高分辨率图像再经过迭代的EvoIM过程得到最后的高分辨图像。
主要应用点:
1. Resnet的引入, 每一张单独的图像都经过Resnet来提高图像质量为了更进一步的多图像的融合。(这个残差网络是用的别人的SRGAN 在最后一层将
图像增倍因素变为了两倍)
2. 多图像的融合,旨的是EvoIM过程,包括初始的高分辨率图像的迭代滤波,由配准的低分辨率输入组成
EvoIM过程类似于FRSR过程,只不过将高斯模糊核替代为了卷积核,用于解决图像进一步优化问题。
3. 整体架构 Resnet和EvoIM两个独立训练,再合并为EvoNet, 梯度更新公式:

加入了正则化约束和一个阶跃函数(value>0 =>1, value=0 =>0, value<0 => -1)
A 是一个对角矩阵表示低分辨率测试的对X0的贡献。
整体流程: