【文章阅读】【超解像】–Image Super-Resolution via Deep Recursive Residual Network
论文链接:http://cvlab.cse.msu.edu/pdfs/Tai_Yang_Liu_CVPR2017.pdf
caffe code:https://github.com/tyshiwo/DRRN_CVPR17
TensorFlow code: https://github.com/LoSealL/VideoSuperResolution
pytorch code: https://github.com/jt827859032/DRRN-pytorch
1.主要贡献
提出一种递归残差网络结构,在增加网络层数的基础上,可使网络参数少,网络性能优。
a) 多通路残差网络结构
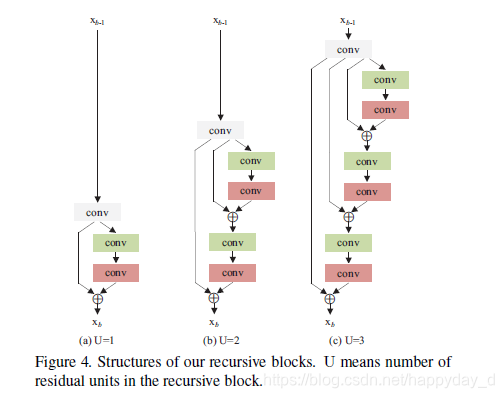
b)递归网络结构
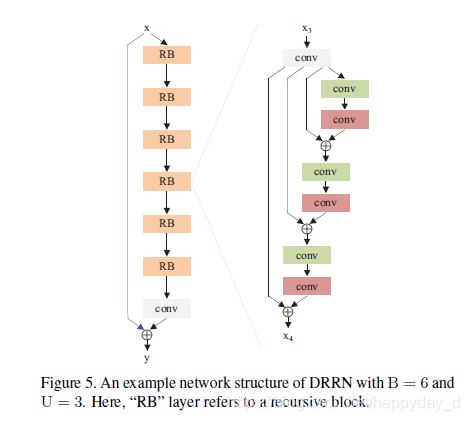
网络结构:
说明:B表示递归网络网络结构个数,U表示递归网络结构中残差单元个数(后续有讲解)总的网络层数为:
2.论文分析
a) 网络结构
该结构在Resnet,VDSR,DRCN的结构基础之上改进而来。

下图d中,红色虚线框表示递归单元,包含两个残差单元
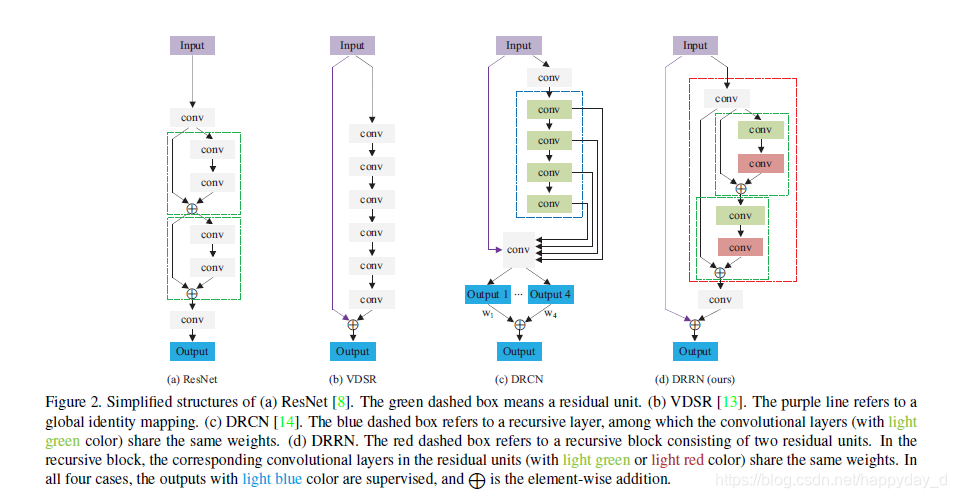
不同的残差单网络结构:
b) 不同模型的网络数学策略(具体公式含义参考论文)

c) 损失函数
d) 实验细节
数据增强:图像翻转,旋转(90°、180°、270°),旋转后的图像水平翻转,数据量增加7倍,运用不同的放大倍数图像进行同一个模型训练,训练图像大小为31x31。
训练策略:SGD min-batch 128, momentum 0.9,初始学习率为0.1,每10轮学习率下降一半,同时使用梯度自动裁切技术。
卷积核相关:卷积核大小为3x3,个数为128
3.结果分析
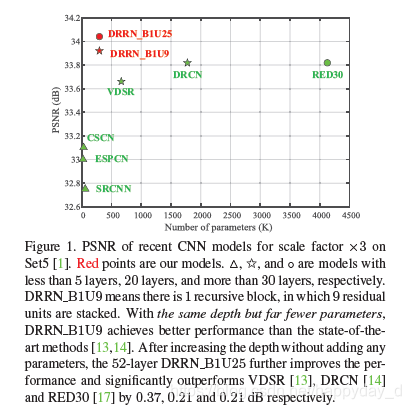
利用52层的网络结构,利用递残差网络结构有两种实现方式:B1U25(k=297K), B17U1(k=7375K)(k表示参数数量),与其他模型的比较结果如下PSNR和SSIM:
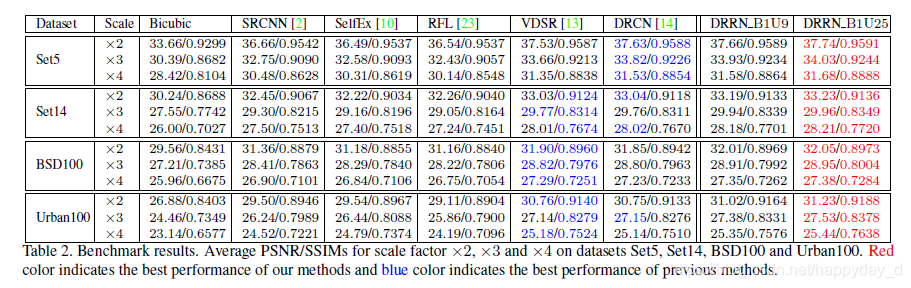
本文还利用了一种信息保真度(Information Fidelity Criterion IFC )的评价指标(后续研究):
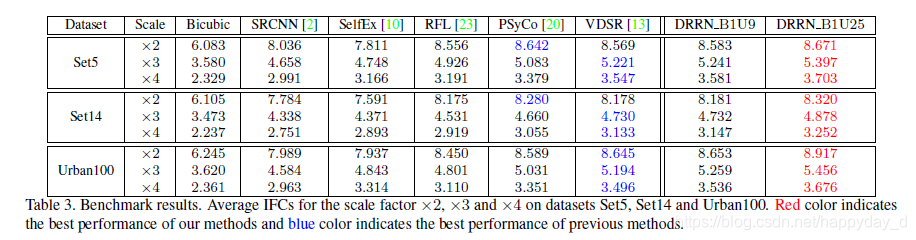
还有一些主观的评价:

最后作者比较了传统方法,非传统方法,浅层网络结构和深层网络结构的特性,目的为说明本模型好。
论文个人理解,如有问题,烦请指正,谢谢!