【文章阅读】【超解像】–Enhanced Deep Residual Networks for Single Image Super-Resolution
论文链接:https://arxiv.org/abs/1707.02921
code:https://github.com/thstkdgus35/EDSR-PyTorch
本文是韩国首尔大学的研究团队出的用于SR任务的新方法(之前方法的修正),分别为增强深度超分辨网络EDSR和一种多尺度深度超分辨率MDSR,在减少模型大小的同时也提高了图像性能,并赢得到了NTIRE2017超分辨挑战赛的第一名和第二名。
1.主要贡献
1). 在残差网络结构的基础上做了修改,残差网络结构适用于图像分类等任务上,不适合直接套用在SR应用任务上。
2). 作者提出了一种多尺度模型,进行了不同放大倍数模型参数共享,并在处理每一个模型时都能取得较好的结果。
2.论文分析
1). 模型基本结构
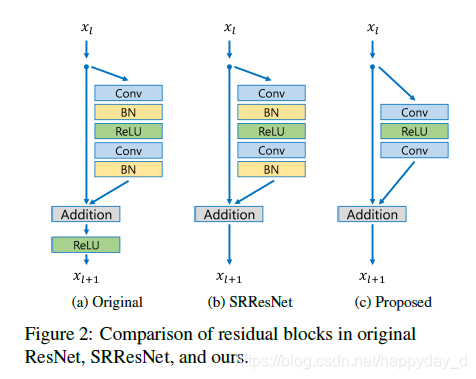
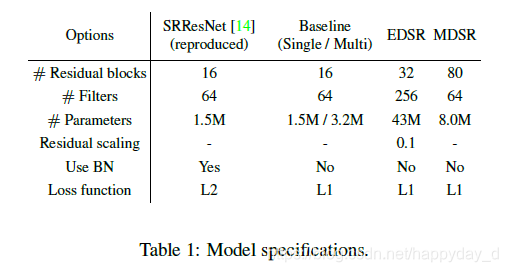
在SRResNet结构基础上将BN成去掉,主要是由于BN层对特征进行了批量归一化,使网络结构的灵活性降低(使网络能表现的特征减少)。训练过程中,BN层占用了大量的GPU存储资源,去掉BN层后能降低40%的GPU存储资源,可用于训练更深的网络结构。
2). Single-scale model
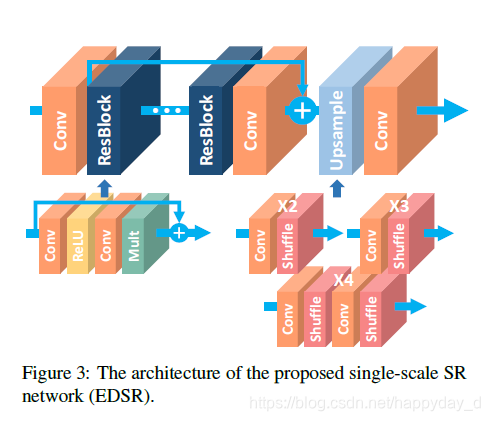
单模型网络结构如上图所示,文中提出太多的残差块导致训练不稳定,文中提出了residual scaling 方法,即残差块在相加前,经过卷积处理的数据乘以一个小数(0.1),这样可以保证训练更加稳定。最终模型使用B=32,F=256,B表示残差块,F表示feature channels.
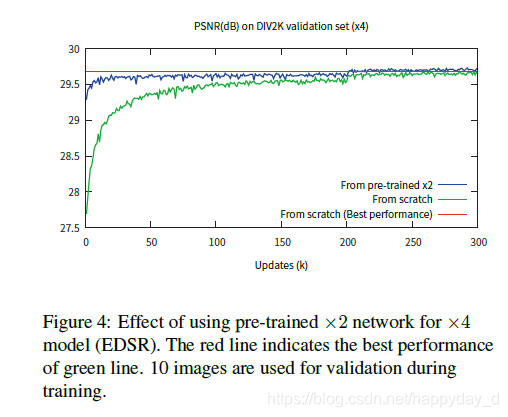
利用训练过的放大2倍的模型作为初始模型训练放大4倍的模型,可以加速模型的训练速度,如下:
3). Multi-scale model
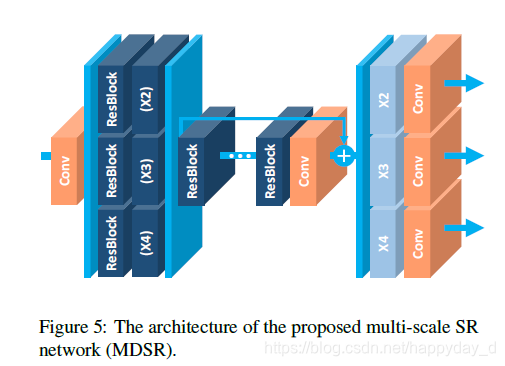
多尺度模型开始每个放大倍数都有两个独立的残差块,后面经过相同的残差块,最后再使用独自的升采样模块来提高分辨率。模型的B=80 F=64。
4)训练细节
数据:用的是DIV2K数据集,800张训练图片,100张验证图像,100张测试图像,每张图像的分辨率为2K;
MDSR训练过程中,将放大2倍,3倍,4倍三种尺度随机混合作为训练集,在梯度更新的时候,只对相应的尺寸的那部分参数进行更新。
几何自融合:测试时将图像90度旋转以及翻转,共形成8种不同的图像,分别送入网络进行处理,处理后变换到原来的位置,然后8张图像取平均,该方法可以使测试结果又稍微的提升。
训练优化:利用ADAM优化器,minibatch size为16,初始学习率为0.0001,训练输入图像为48x48的RGB图像。
模型结构参数如下:
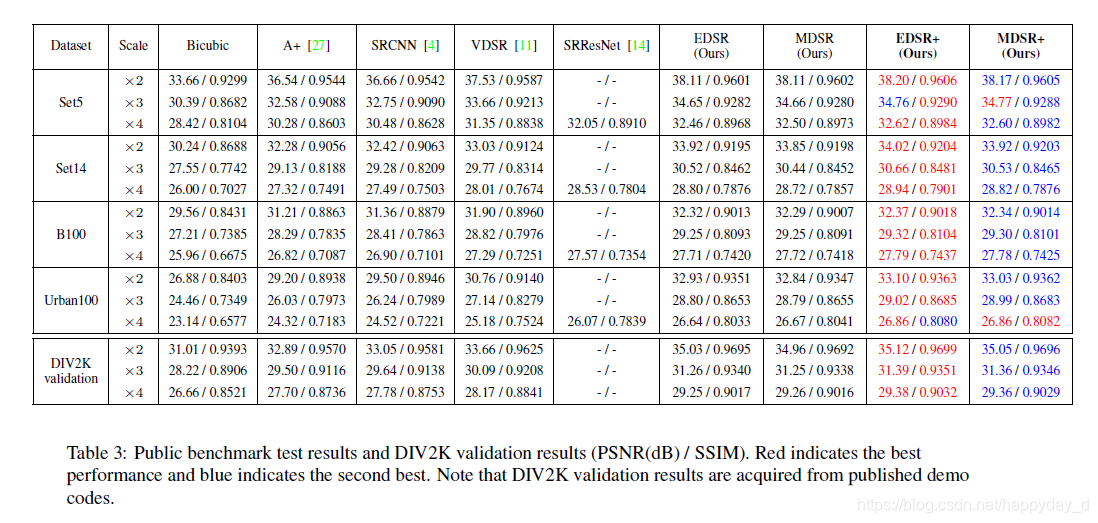
3.结果分析

4.参考
感谢网上的各种资源,在阅读原文和相关参考资源的基础上进行了总结,如有问题,烦请指正,谢谢!